
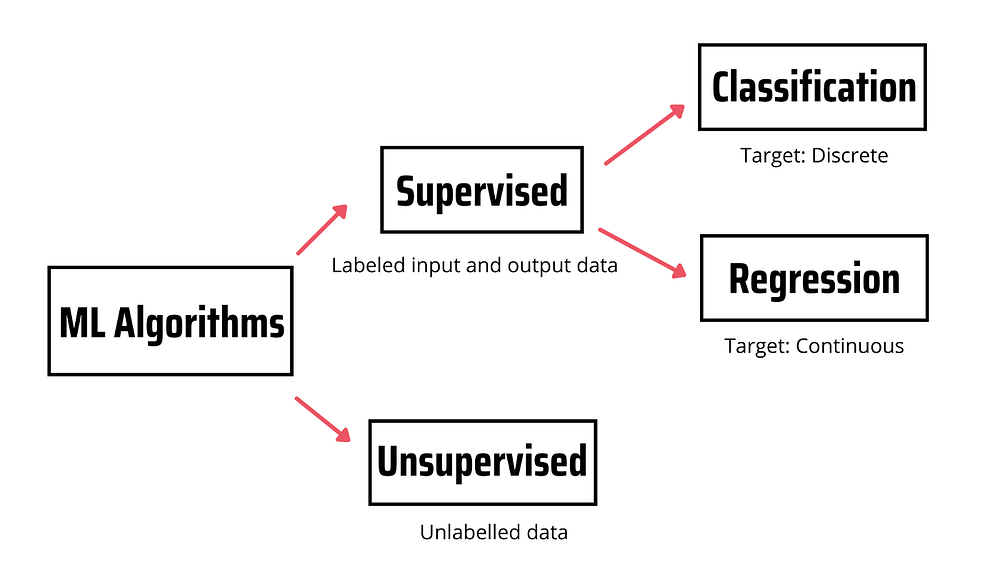
Алгоритмы машинного обучения делятся на контролируемые и неконтролируемые.
Алгоритмы контролируемого обучения моделируют отношения между помеченными входными и выходными данными (также известными как целевые данные). Впоследствии такая модель используется для предсказания метки новых наблюдений с помощью новых помеченных входных данных. Если целевая переменная дискретная, алгоритм решает задачи классификации, а если целевая переменная непрерывная — алгоритм используется для задач регрессии.
В отличие от контролируемого, неконтролируемое обучение не опирается на помеченные входные/выходные данные, а обрабатывает непомеченные данные.
Вот 6 алгоритмов контролируемого обучения, которые должен знать каждый, кто изучает науку о данных.
1. Линейная регрессия
Линейная регрессия — самый простой алгоритм, применяемый в машинном обучении. Он используется для моделирования взаимосвязи между двумя (или более) переменными. Различают два типа линейной регрессии — простую и множественную.
В простой линейной регрессии есть одна независимая переменная и одна зависимая переменная, в то время как во множественной линейной регрессии есть несколько независимых переменных и одна зависимая.
Вот уравнение множественной линейной регрессии:
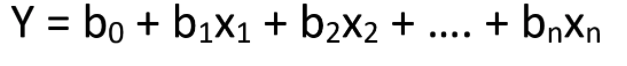
Здесь y — зависимая переменная (целевое значение), x1, x2, … xn — независимые переменные (предикторы), b0 — свободный член, b1, b2, ... bn — коэффициенты и n — количество наблюдений.
На изображении ниже представлена упрощенная версия уравнения линейной регрессии.
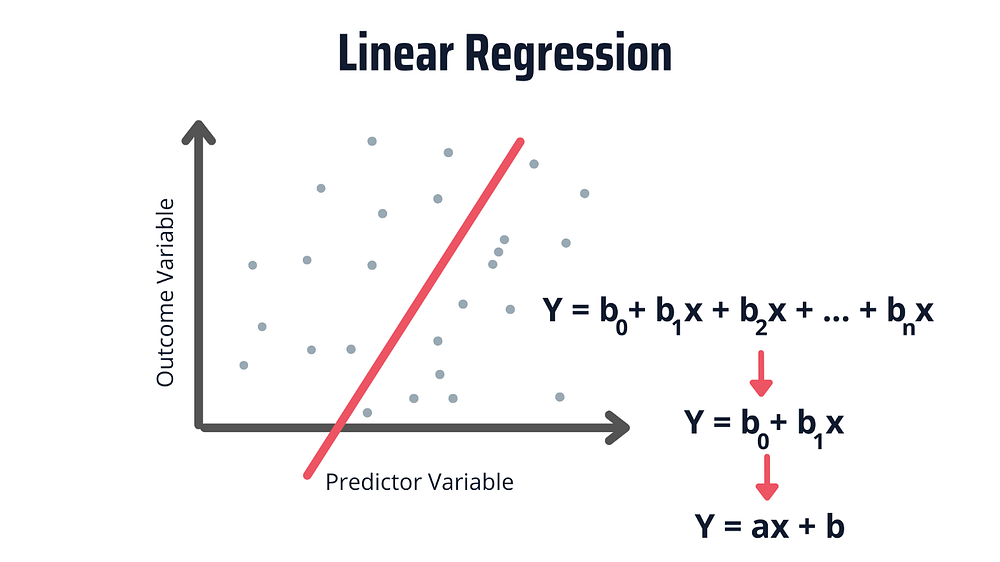
Представленная выше линейная зависимость проявляется в следующем: если одна переменная увеличивается или уменьшается, другая переменная также будет увеличиваться или уменьшаться.
Линейную регрессию используют для прогнозирования оценок, зарплат, цен на жилье и т. д. При этом точность прогнозирования не так высока, как при использовании других алгоритмов.
2. SVM
SVM (Support Vector Machine, машина опорных векторов) — это алгоритм контролируемого обучения, который в основном используется в задачах классификации. Обычно на SVM-модель подаются помеченные обучающие данные, чтобы классифицировать новый текст.
SVM является хорошим выбором, если имеется ограниченное количество образцов, а скорость является приоритетом. Именно поэтому SVM используется при работе с набором данных, содержащим несколько тысяч помеченных образцов.
Чтобы лучше понять, как работает SVM, рассмотрим пример.
На изображении ниже две метки (зеленая и желтая) и два признака (x и y). Допустим, надо создать классификатор, который определит, являются ли текстовые данные зелеными или желтыми. В таком случае строится граф каждого наблюдения (другими словами, точки данных) в n-мерном пространстве, где “n” — количество используемых признаков.
При наличии двух признаков наблюдения отображаются в двумерном пространстве, как показано на изображении ниже.
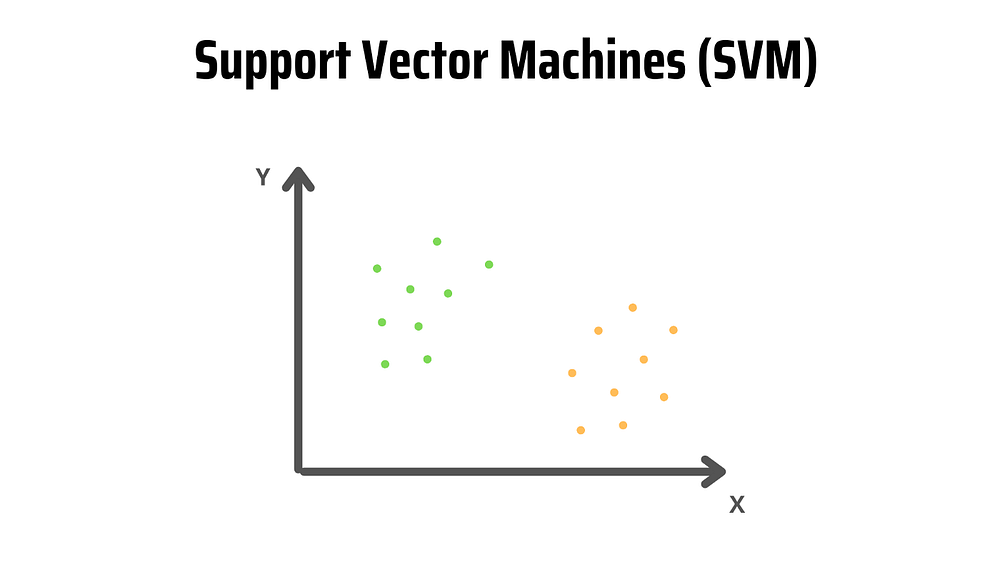
Для сопоставления точек данных SVM строит гиперплоскость, которая оптимальным образом разделяет их на классы. Поскольку наблюдения построены в двумерном пространстве, гиперплоскость представляет собой линию.

Эта красная линия также известна как граница решений. Она определяет, к какой из категорий принадлежит точка данных. В нашем примере, если точка данных попадает в левую часть, она классифицируется как зеленая, если в правую — как желтая.
3. Дерево решений
Даже если вы ничего не знаете о машинном обучении, наверняка вы слышали о деревьях решений.
Дерево решений — это модель, применяемая в планировании, статистике и машинном обучении. Она использует древовидную структуру решений/последствий для оценки возможных событий, связанных с определенной проблемой.
Вот дерево решений, которое оценивает сценарии, в которых люди хотят играть в футбол.
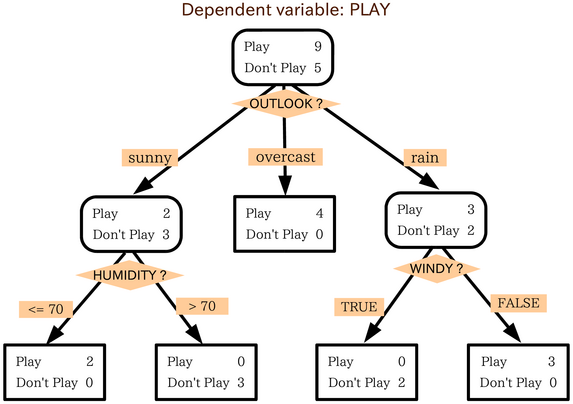
Каждый квадрат называется узлом. Последние узлы дерева решений называются листьями дерева. Прогнозы делают, оценивая каждый узел, начиная с корня дерева (первого узла). Затем следуют по ветке, которая согласуется с оценкой, и переходят к следующему узлу.
Алгоритм дерева решений можно использовать для решения задач как регрессии, так и классификации. В МО дерево решений часто применяют для построения модели, которая может предсказать класс или значение целевой переменной путем изучения правил дерева решений, выведенных из обучающих данных.
4. Случайный лес
Случайный лес — это ансамбль из множества деревьев решений. Он сочетает в себе простоту дерева решений и гибкость, что приводит к повышению точности.
Чтобы создать случайный лес, сначала нужно создать “бутстрапный” набор данных. Бутстрап — это случайный выбор образцов из исходных данных (можно даже выбрать один и тот же образец несколько раз). Затем такой бутстрапный набор данных используется для создания дерева решений.
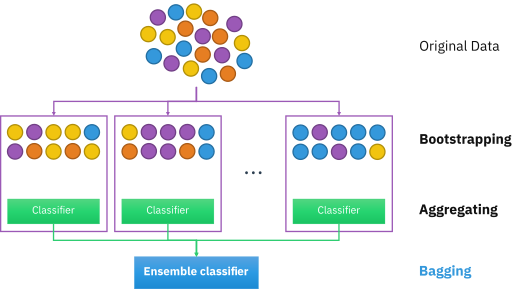
Этот метод также известен как “бэггинг”. Если повторить предыдущие шаги несколько раз, получим большое количество деревьев. Именно это разнообразие деревьев делает случайные леса более эффективными, чем одно дерево решений.
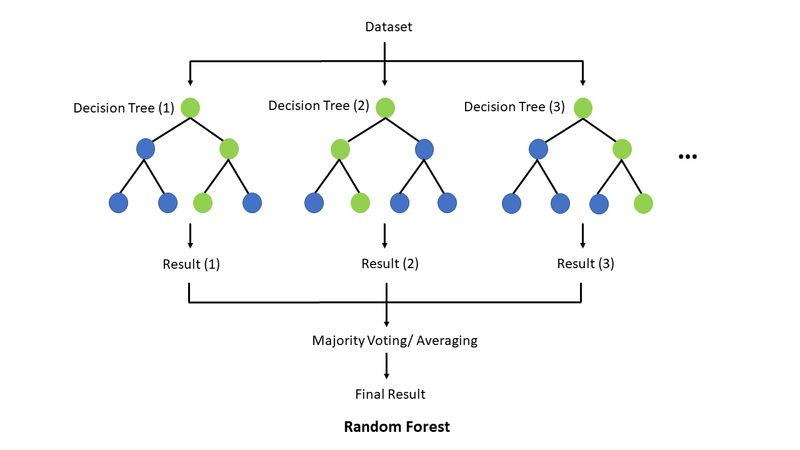
Если случайный лес используется для задачи классификации, модель выбирает режим предсказаний каждого дерева решений. Для задачи регрессии модель выбирает среднее значение результатов деревьев решений.
5. Наивный байесовский классификатор
Наивный байесовский классификатор — это алгоритм контролируемого обучения, который использует условную вероятность для прогнозирования класса.
Этот алгоритм основан на теореме Байеса:
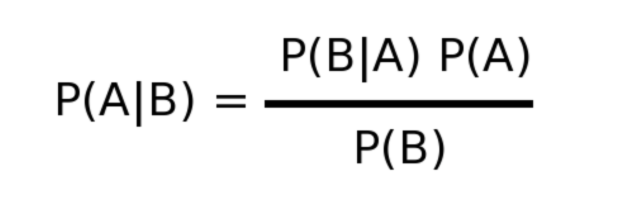
p(A|B): вероятность события A при условии, что событие B уже произошло.
p(B|A): вероятность события B с учетом того, что событие A уже произошло.
p(A): вероятность события A.
p(B): вероятность события B
Наивный байесовский классификатор предполагает, что все признаки независимы друг от друга. Поскольку это не всегда так, перед выбором такого классификатора следует изучить данные.
Благодаря предположению о независимости признаков друг от друга, наивный байесовский классификатор является более быстрым, чем другие сложные алгоритмы, но менее точным.
Наивный байесовский классификатор применяется для прогнозирования погоды, выявления мошенничества и многого другого.
6. Логистическая регрессия
Логистическая регрессия — это алгоритм контролируемого обучения, который обычно применяется для решения задач бинарной классификации. Из этого следует, что логистическую регрессию можно использовать для прогнозирования оттока клиентов, а также для определения того, является ли письмо спамом или нет.
Логистическая регрессия основана на логистической функции (она же сигмоидная функция), которая принимает значение и присваивает ему вероятность от 0 до 1.
Вот граф логистической регрессии:
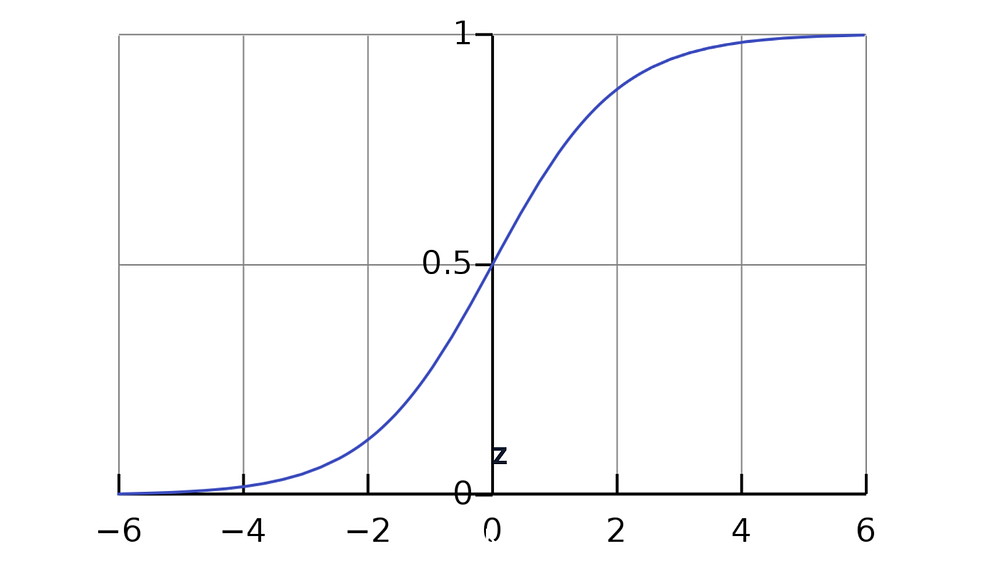
Чтобы лучше понять, как работает логистическая регрессия, рассмотрим сценарий, в котором нужно определить, является ли письмо спамом или нет.
На графе видно, что если Z перейдет в бесконечность, то Y (целевое значение) станет равным 1. Это означает, что письмо является спамом. Однако если Z перейдет в отрицательную бесконечность, Y станет 0, а значит письмо не является спамом.
Выходное значение — это вероятность. Поэтому если мы получим значение 0,64, вероятность того, что письмо окажется спамом, составляет 64%.
Читайте также:
- Переживут ли творческие профессии революцию искусственного интеллекта?
- Алгоритм XGBoost: пусть он царствует долго!
- 3 признака того, что ваш ИИ-проект обречен
Читайте нас в Telegram, VK и Дзен
Перевод статьи Frank Andrade: 6 Machine Learning Algorithms Anyone Learning Data Science Should Know





