
Категориальные признаки необходимо преобразовывать, прежде чем использовать их в модели. Зачастую это делается с помощью прямого кодирования — в итоге получаем бинарную переменную для каждой категории.
Проблемы не возникают до попытки понять модель с помощью метода SHAP. Каждая бинарная переменная будет иметь свое собственное значение SHAP. Это затрудняет понимание общего вклада исходного категориального признака.
Для решения этой проблемы используется простой подход — сложение значений SHAP для каждой бинарной переменной. Получаем то, что можно интерпретировать как значение SHAP для исходного категориального признака.
Поговорим о том, как это сделать с помощью кода Python. Вы увидите, что можно использовать агрегированные графические представления SHAP. Однако их возможности ограничены, когда речь идет о понимании природы взаимосвязей категориальных признаков. Поэтому в завершение будет показано, как для визуализации значений SHAP можно использовать диаграммы размаха.
Набор данных
Для демонстрации решения проблемы с категориальными признаками мы будем использовать набор данных по классификации грибов. Снэпшот этого набора данных представлен на изображении 1. Целевой переменной является класс гриба, определенный на основе того, является ли гриб ядовитым (p) или съедобным (e).
Этот набор данных можно найти в МО-репозитории UCI.
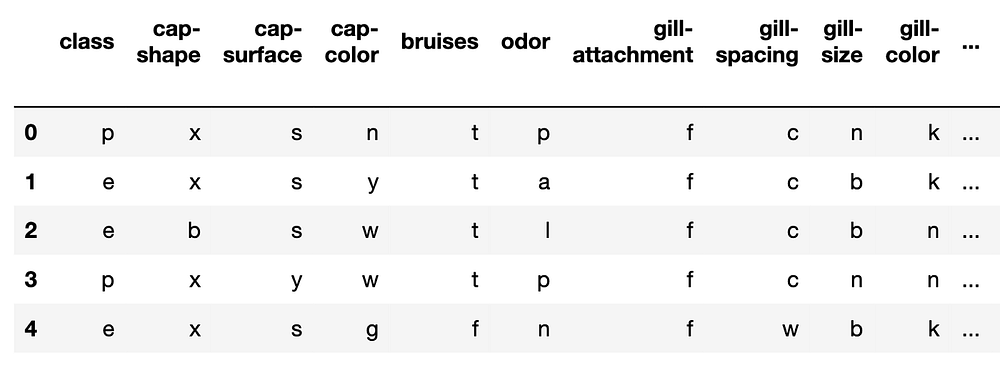
Этот набор содержит 22 категориальных признака. По каждому признаку категория представлена буквенным обозначением. Например, запах (odor) имеет 9 уникальных категорий — миндальный (a), анисовый (l), креозотовый (c), рыбный (y), гнилостный (f), затхлый (m), нейтральный (n), резкий (p), острый (s). Эта палитра передает все грибные запахи.
Моделирование
Ниже приведен код для анализа этого набора данных (полную версию можно найти на GitHub). Нам понадобятся несколько общих пакетов Python для обработки и визуализации данных (строки 2-4). Для преобразования категориальных признаков (строка 6) воспользуемся OneHotEncoder. Для моделирования (строка 8) применим xgboost. А SHAP позволит понять, как работает модель (строка 10).
#импорт
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder
import xgboost as xgb
import shap
shap.initjs()
Импортируем набор данных (строка 2). Нам нужна числовая целевая переменная, поэтому проведем преобразование, установив ядовитость = 1 и съедобность = 0 (строка 6). Получим также категориальные признаки (строка 7). Набор данных X_cat не будет использован для моделирования, но он пригодится позже.
#загрузка данных
data = pd.read_csv("../data/mushrooms.csv")
#получение признаков
y = data['class']
y = y.astype('category').cat.codes
X_cat = data.drop('class', axis=1)
Для использования категориальных признаков их также необходимо преобразовать. Начнем с подгонки кодировщика (строки 2-3). Используем его для преобразования категориальных признаков (строка 6). Для каждой категории каждого категориального признака предусмотрим бинарный признак. Создадим имена для каждого из бинарных признаков (строки 9-10). И в конце объединим их в матрице признаков (строка 12).
#подгонка кодировщика
enc = OneHotEncoder()
enc.fit(X_cat)
#преобразование категориальных признаков
X_encoded = enc.transform(X_cat).toarray()
#создание матрицы признаков
feature_names = X_cat.columns
new_feature_names = enc.get_feature_names(feature_names)
X = pd.DataFrame(X_encoded, columns= new_feature_names)
В итоге получилось 117 признаков. Снапшот матрицы признаков представлен на изображении 2. Как видите, признак cap-shape (форма шляпки) преобразован в 6 бинарных переменных. Буквы в конце названий признаков относятся к категориям исходных признаков.
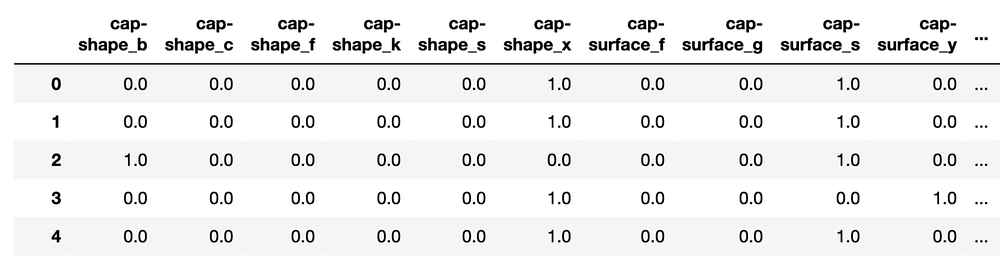
Обучаем модель, используя эту матрицу признаков (строки 2-5). Применяем XGBClassifier. Модель XGBoost состоит из 10 деревьев, каждое из которых имеет максимальную глубину 2. Точность модели на обучающем наборе данных составила 97,7%.
#Обучение модели
model = xgb.XGBClassifier(objective="binary:logistic",
max_depth=2,
n_estimators=10)
model.fit(X, y)
Стандартные SHAP-значения
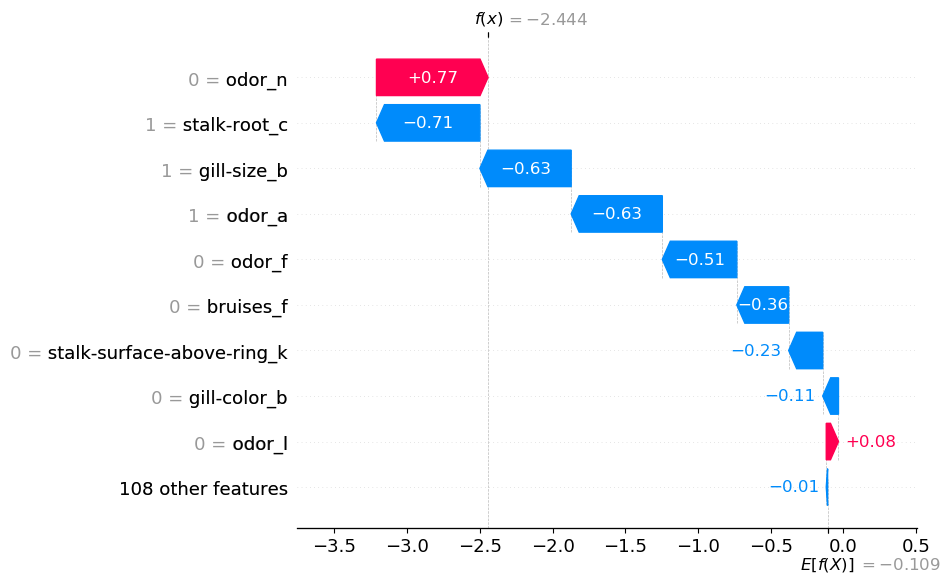
На данном этапе необходимо понять, как модель делает прогнозы. Начинаем с расчета SHAP-значений (строки 2-3). Затем визуализируем SHAP-значения для первого прогноза с помощью диаграммы “водопад” (строка 6). Эта диаграмма представлена на изображении 3.
# получение shap-значений
explainer = shap.Explainer(model)
shap_values = explainer(X)
# диаграмма “водопад” для первого наблюдения
shap.plots.waterfall(shap_values[0])
Как видите, каждый бинарный признак имеет собственное SHAP-значение. Возьмем, к примеру, запах. Он появляется 4 раза на диаграмме “водопад”. Тот факт, что odor_n = 0, увеличивает вероятность того, что гриб ядовит. В то же время показатели odor_a = 1, odor_f = 0 и odor_I = 0 уменьшают эту вероятность.
Пока неясно, какую роль играет запах гриба (odor). В следующем разделе увидим, что ситуация проясняется, если сложить все отдельные факторы.
SHAP для категориальных признаков
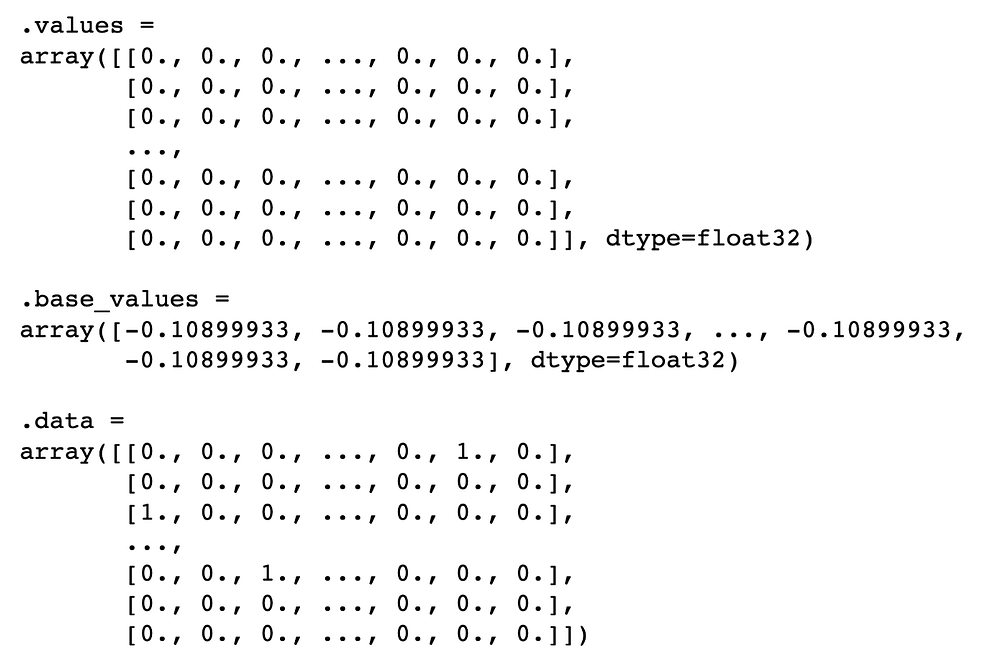
Начнем с изучения объекта shap_values. Выведем объект в приведенном ниже коде. Мы видим, что вывод состоит из 3 компонентов.
values— SHAP-значения для каждого из прогнозов.data— значения для бинарных признаков.base_values— базовое значение, одинаковое для каждого прогноза.
Это средний прогнозируемый логарифм отношения шансов.
print(shap_values)
Значения SHAP для первого предсказания можно рассмотреть более подробно, выведя их (как показано ниже). Здесь 117 значений — по одному для каждой бинарной переменной.
Значения SHAP расположены в том же порядке, что и матрица признаков X. Помните, что первый категориальный признак, cap-shape (форма шляпки), имеет 6 категорий. Это означает, что первые 6 значений SHAP соответствуют бинарным признакам этого признака. Следующие 4 соответствуют признакам cap-surface (поверхность шляпки) и так далее.
print(shap_values.values[0])

Теперь нужно сложить значения SHAP для каждого категориального признака. Для этого сначала создадим массив n_categories. Он содержит количество уникальных категорий для каждой категориальной переменной. Первое число в массиве будет 6 для cap-shape (формы шляпки), а затем 4 для cap-surface (поверхности шляпки) и так далее.
#получение количества уникальных категорий для каждого признака
n_categories = []
for feat in feature_names[:-1]:
n = X_cat[feat].nunique()
n_categories.append(n)
Мы используем n_categories для разделения массивов значений SHAP (строка 5). В итоге получаем список подсписков. Затем суммируем значения в каждом из этих подсписков (строка 8). Таким образом, переходим от 117 значений SHAP к 22. Делаем это для каждого наблюдения в объекте shap_values (строка 2). При каждой итерации добавляем суммированные значения SHAP в массив new_shap_values (строка 10).
new_shap_values = []
for values in shap_values.values:
#разделение значений shap на список для каждого признака
values_split = np.split(values , np.cumsum(n_categories))
#суммирование значений в каждом списке
values_sum = [sum(l) for l in values_split]
new_shap_values.append(values_sum)
Теперь осталось заменить исходные значения SHAP новыми значениями (строка 2). Заменяем также данные бинарных признаков буквами категорий из исходных категориальных признаков (строки 5-6). И наконец, заменяем имена бинарных признаков на имена исходных признаков (строка 9). Важно передавать новые значения в виде массивов и списков — это типы данных, используемые объектом shap_values.
#замена shap-значений
shap_values.values = np.array(new_shap_values)
#замена данных значениями категориальных признаков
new_data = np.array(X_cat)
shap_values.data = np.array(new_data)
#обновление названий признаков
shap_values.feature_names = list(X_cat.columns)
Обновленный объект shap_values можно использовать так же, как и исходный объект. В приведенном ниже коде строим диаграмму “водопад” для первого наблюдения. Обратите внимание, что этот код точно такой же, как и предыдущий.
# диаграмма "водопад" для первого наблюдения
shap.plots.waterfall(shap_values[0])
Результат визуализирован на изображении 4. Теперь у нас есть 22 значения SHAP. Как видите, значения признаков слева были заменены на метки категорий. Мы уже обсуждали запах. Теперь можно ясно увидеть общий вклад этого признака: он уменьшил логарифм отношения шансов на 0,29.
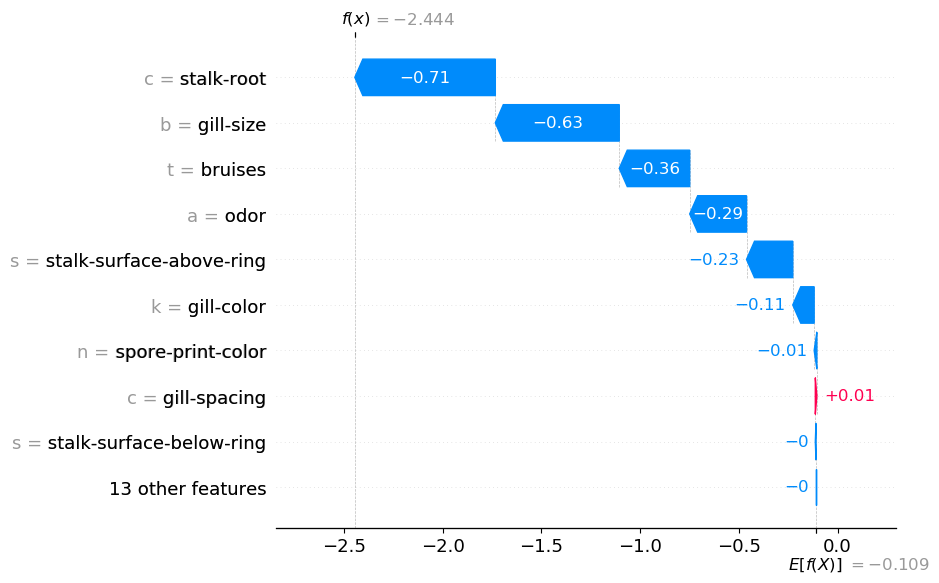
На приведенном выше диаграмме odor = a. Это говорит о том, что гриб имел “миндальный” запах. Не стоит интерпретировать это графическое представление как “миндальный запах уменьшил логарифм отношения вероятностей”. Суммирование нескольких значений SHAP позволяет интерпретировать ситуацию следующим образом: “миндальный запах и отсутствие других запахов уменьшили логарифм отношения вероятностей”. Так, если посмотреть на первую диаграмму “водопад”, отсутствие “гнилостного” запаха (odor_f = 0) также уменьшило логарифмическую вероятность.
Прежде чем перейти к агрегированию новых значений SHAP, стоит обсудить некоторые теоретические аспекты. Причина, по которой это можно делать со значениями SHAP, заключается в их аддитивном свойстве. То есть средний прогноз — E[f(x)] — плюс все значения SHAP равны фактическому прогнозу — f(x). При складывании нескольких значений SHAP это свойство не нарушается. Вот почему f(x) = -2,444 одинаково на изображениях 3 и 4.
Среднее значение SHAP
Как и в случае с диаграммой “водопад”, мы можем использовать агрегирование SHAP так же, как и в отношении исходных значений SHAP. Например, в приведенном ниже коде задается графическое представление среднего SHAP. Судя по изображению 5, можно использовать этот графическое представление для выделения важных категориальных признаков. Например, ясно видно, что запах имеет тенденцию к большим положительным/отрицательным значениям SHAP.
#Среднее значение SHAP
shap.plots.bar(shap_values)
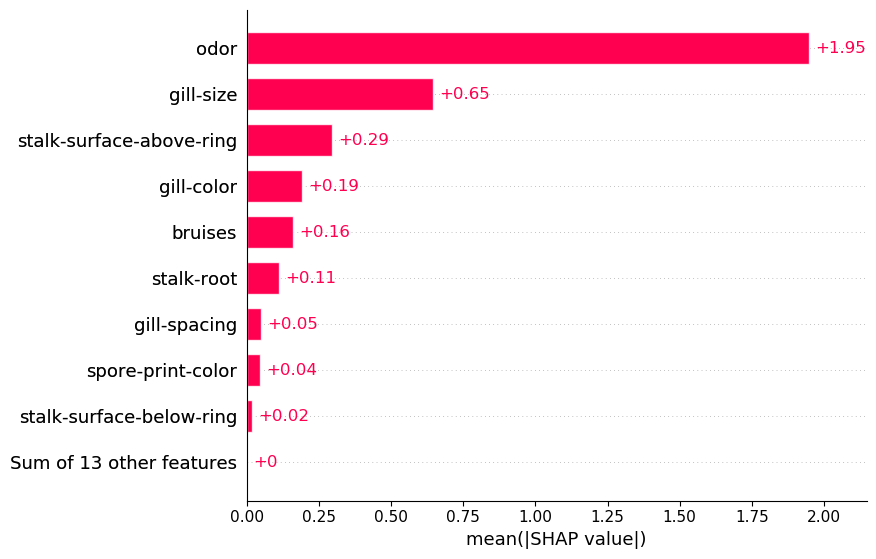
Диаграмма “пчелиный рой”
Еще одним распространенным методом агрегирования является диаграмма “пчелиный рой”. В отношении непрерывных переменных это графическое представление полезно, поскольку помогает объяснить природу взаимосвязей. Мы видим, как значения SHAP связаны со значениями признаков. Однако для категориальных признаков значения признаков были заменены метками. В результате, как видно на изображении 6, все значения SHAP выделены одним цветом. Нам нужно создать собственные диаграммы, чтобы понять природу этих взаимосвязей.
shap.plots.beeswarm(shap_values)
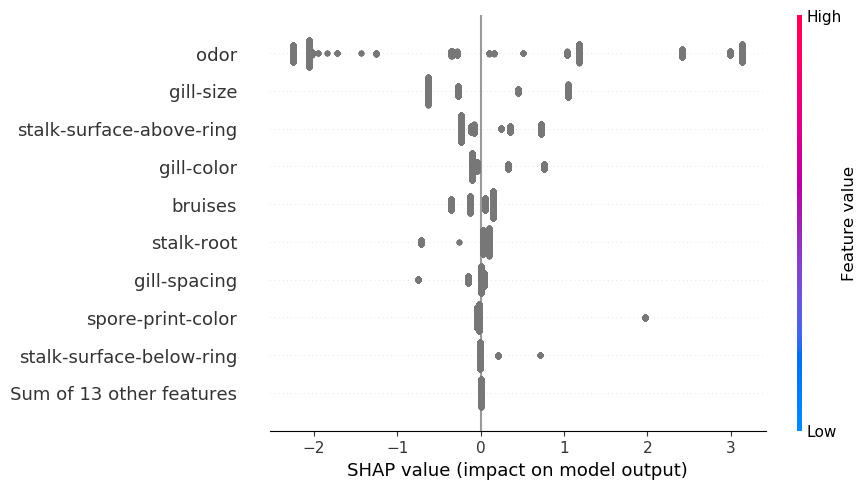
Диаграмма размаха SHAP
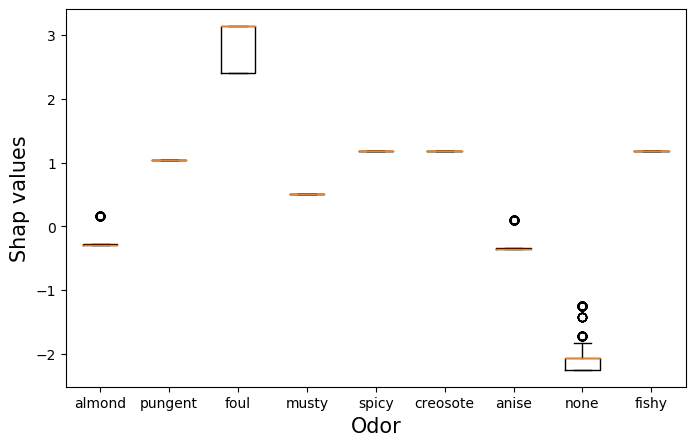
Один из способов сделать это — использовать диаграммы размаха для значений SHAP. На изображении 7 представлена такая диаграмма для характеристики запаха. Здесь сгруппированы значения SHAP для характеристики запаха на основе категории запаха. Видно, что гнилостный запах приводит к более высоким значениям SHAP. Такие грибы, скорее всего, ядовиты. Так что не стоит есть дурно пахнущие грибы! Аналогично, грибы без запаха, скорее всего, съедобны. Одиночная оранжевая линия означает, что все значения SHAP для этих грибов были одинаковыми.
Эта диаграмма создается с помощью приведенного ниже кода. Начинаем с получения значений SHAP для запаха (строка 2). Помните, что это обновленные значения. Для каждого прогноза будет только одно значение SHAP для признака запаха.
Также получаем метки категорий запахов (строка 3). Разбиваем значения SHAP на основе этих меток (строки 6-11). В дальнейшем мы будем использовать эти значения, чтобы построить диаграмму для каждой из категорий запахов (строки 27-32). Чтобы графическое представление было легче интерпретировать, заменим буквы на полные названия категорий (строки 14-24).
#получение shap-значений и данных
odor_values = shap_values[:,"odor"].values
odor_data = shap_values[:,"odor"].data
#разделение shap-значений запаха на основании категорий запаха
odor_categories = list(set(odor_data))
odor_groups = []
for o in odor_categories:
relevant_values = odor_values[odor_data == o]
odor_groups.append(relevant_values)
#замена категорий метками
odor_labels = {'a':'almond',
'l':'anise',
'c':'creosote',
'y':'fishy',
'f':'foul',
'm':'musty',
'n':'none',
'p':'pungent',
's':'spicy'}
labels = [odor_labels[u] for u in unique_odor]
#построение диаграммы размаха
plt.figure(figsize=(8, 5))
plt.boxplot(odor_groups,labels=labels)
plt.ylabel('Shap values',size=15)
plt.xlabel('Odor',size=15)
На практике, скорее всего, только несколько признаков будут категориальными. Вам нужно будет обновить описанный выше процесс, чтобы суммировать категориальные признаки. Можете также придумать свой способ визуализации взаимосвязи этих признаков.
Было бы интересно понять, как зависимости между признаками повлияют на этот анализ. По определению, преобразованные бинарные признаки будут подвержены корреляции. Это может повлиять на расчет значения SHAP. Мы используем TreeSHAP для оценки значений SHAP. Насколько я понимаю, на них зависимости влияют не так сильно, как на KernelSHAP.
Читайте также:
- Анализ автоаварий в Барселоне с использованием Pandas, Matplotlib и Folium
- Автоматическое МО (AutoML) с использованием PyCaret: основные принципы
- Python + Selenium: как получить координаты по адресам
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Conor O’Sullivan: SHAP for Categorical Features





