
Я составил пошаговое описание решения задачи, как работать с Python и Selenium для сбора данных о координатах (широты и долготы) с карт Google, зная только адреса.
В ходе разбора примера я буду работать с официальным датасетом, в котором содержатся адреса всех благотворительных и некоммерческих организаций (БиНО) Австралии. В конце я обработаю карту всех благотворительных и некоммерческих организаций Мельбурна в Folium, и вы увидите, что ещё можно сделать со свежесобранными данными о координатах.
Чтобы точно следовать моему описанию, вы можете скачать Jupyter Notebook из моего репозитория на GitHub.
Пакеты и установка

Для сбора данных нам понадобится пакет для Seleniumв Python. Если у вас такого ещё нет, установите его с помощью pip: pip install selenium.
Еще нам нужен WebDriver для того, чтобы взаимодействовать с браузером. Так что сходите по ссылке и загрузите его на свой компьютер. Убедитесь, что он совместим с вашей текущей версией Chrome. А теперь проведём импортирование:
from selenium import webdriver
Также загрузим tqdm, базовый пакет с индикатором прогресса. Это очень удобно — видеть, сколько времени займёт сбор информации. Я пользуюсь tqdm_notebook, потому что работаю в Jupyter Notebook.
from tqdm import tqdm_notebook as tqdmn
Вдобавок к этому, для считывания информации и манипуляций с датасетом нам понадобится Pandas:
import pandas as pd
Теперь импортируем Folium. Он нужен для распределения координат на карте (можно установить вот такой командой pip install folium):
import folium
Я буду работать в Jupyter Notebook (можете загрузить его здесь). Даже если вы работаете с IDE, шаги работы с датасетом будут такими же, как и у меня.
Датасет: список благотворительных организаций ACNC

Австралия занимает 4 место в мире согласно CAF World Giving Index (Всемирный индекс благотворительности КАФ) в его 10 версии. Данные приведены за последние десять лет. Если вы зайдёте на сайт ACNC, то удивитесь, насколько просто получить доступ к данным о БиНО в Австралии.
Датасет (вместе с другими полезными пользовательскими заметками с пояснениями о переменных), который мы будем обрабатывать, можно скачать по следующей ссылке:
- ACNC Charity Register dataset [файл XLSX | 7.7 Mb | 74155 строчек и 60 столбцов на дату 23/01/2020]
В датасете собраны разные интересные характеристики БиНО в Австралии: уникальный идентификатор, официальное название, адрес для корреспонденции, дата регистрации, размер организации, цель, бенефициары и прочее. Остальные подробности ищите в пользовательских заметках.
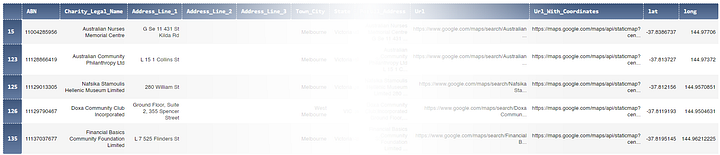
Нам в первую очередь нужны параметры адресов, которые разбросаны по нескольким столбцам: Адресная_строка_1, Адресная_строка_2, Адресная_строка_3, Город, Регион, Индекс и Страна. Чтобы упростить процесс, будем обращать внимание только на нужные нам организации в Мельбурне, а не по всей Австралии.
Очистка и подготовка данных

Во-первых, давайте прочитаем набор данных, который мы загрузили ранее с сайта ACNC при помощи Pandas:
# мы установили этот параметр Pandas, чтобы сделать все 60 столбцов видимыми:
pd.set_option('display.max_columns', 60)
acnc = pd.read_excel('data/datadotgov_main.xlsx', keep_default_na=False)
acnc.head()Убедитесь, что ваша машина может обратиться по адресу расположения экселевского файла. Значение параметра keep_default_na установлено в положение False, так что мы получим пустые значения вместо NaN, когда конкретные значения будут отсутствовать. Это пригодится, когда мы скомбинируем все переменные адресов в одну переменную.
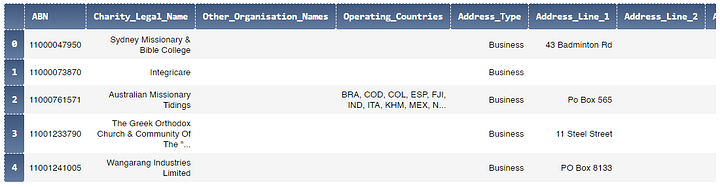
Ну а теперь давайте создадим новый датафрейм mel, как копию acnc после фильтрации его по переменной Town_City, чтобы выбрать только нужные нам БиНО в Мельбурне:
mel = acnc[acnc.Town_City.str.contains('melbourne', case=False)][['ABN', 'Charity_Legal_Name', 'Address_Line_1', 'Address_Line_2', 'Address_Line_3', 'Town_City', 'State', 'Postcode', 'Country', 'Date_Organisation_Established', 'Charity_Size']].copy()Тут я сделал две вещи: отфильтровал датафрейм acnc по переменной Town_City, а потом выделил только 11 полезных столбцов из 60, которые у нас были изначально. А copy() говорит о том, что мы сделали копию отфильтрованного датафрейма acnc правильно.
Я не использовал здесь acnc[acnc.Town_City == 'Melbourne'], потому что название города могут написать разными способами. Вот пример:
mel.Town_City.value_counts()
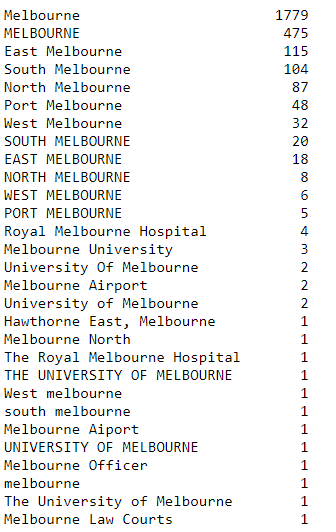
Как вы видите выше, в столбце есть разная запись того, что организация действительно находится в Мельбурне. Во многих из вариантов кроме названия самого города, так же указаны районы или более конкретные точки, как университет Мельбурна. С помощью acnc.Town_City.str.contains('melbourne', case=False), мы гарантируем, что будут учитанны все организации, иначе мы получим только 1779 корректно маркированных записей, хотя организаций больше. И теперь давайте посмотрим на наш новый датафрейм mel:
mel.head()
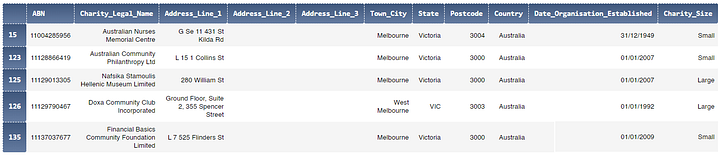
А сейчас добавим новый столбец с полным адресом Full_Address:
mel['Full_Address'] = mel['Address_Line_1'].str.cat( mel[['Address_Line_2', 'Address_Line_3', 'Town_City']], sep=' ')
str.cat() подходит сюда, потому что тип у всех столбцов “объект” или “строка”. Вот пример самого первого полного адреса из mel:
mel.Full_Address.iloc[0]
Output:
'G Se 11 431 St Kilda Rd Melbourne'Еще одна штука: некоторые из этих полных адресов содержат только индекс (указан как GPO Box или Po Box). Такие адреса абсолютно бесполезны для нас, потому что они не относятся к существующим местам. Вот вам пример:
mel[mel.Full_Address.str.contains('po box', case=False)].Full_Address.iloc[0]
Output:
'GPO Box 2307 Melbourne VIC 3001 AUSTRALIA'Перед обработкой нам нужно удалить эти строчки:
mel = mel[~mel.Full_Address.str.contains('po box', case=False)].copy()
И последний пункт: в некоторых адресах есть символ / и он может сделать любой URL нечитаемым, поэтому нам нужно заменить каждый слэш пробелом. Делаем это так:
mel.Full_Address = mel.Full_Address.str.replace('/', ' ')
Изучая Google Maps

Перед любым процессом сбора информации в сети полезно изучить веб-сайт, с которого вы будете извлекать данные. Для нашего случая это Google Maps.
Для начала давайте изучим, как поиск полного адреса при помощи поисковой панели в Google Maps влияет на URL страницы результата. Сначала я введу выдуманный адрес Grinch house mount crumpit whoville , чтобы Google Maps вернули пустые результаты:
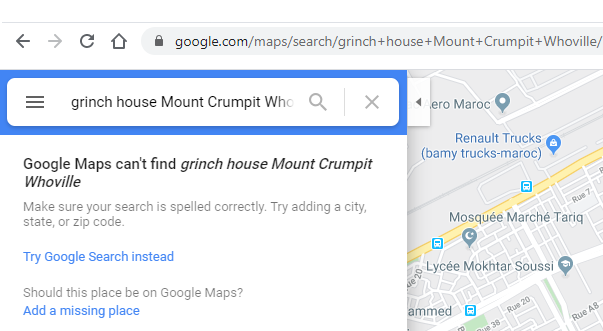
И, как вы видите выше, мы получаем www.google.com/maps/search/, вместе с адресом, который нам и был нужен. Проще говоря, если мы хотим искать адрес XYZ внутри Google Maps, всё, что нам нужно для этого сделать, — использовать URL www.google.com/maps/search/XYZ. При этом не нужно даже взаимодействовать с самой поисковой панелью.
Идея в том, чтобы сгенерировать новый столбец внутри mel. А в нём будет комбинация www.google.com/maps/search/ и каждого Full_Address из нашего датафрейма mel. Затем мы прогоним всё это через Selenium, заходя по очереди в каждый URL.
Вот как мы создадим новый столбец Url:
mel['Url'] = ['https://www.google.com/maps/search/' + i for i in mel['Full_Address'] ]
И теперь у нас есть столбец со всеми URL, по которым мы собрались пройтись. Так, давайте посмотрим для примера на адрес G Se 11 431 St Kilda Rd Melbourne:
www.google.com/maps/search/G Se 11 431 St Kilda Rd Melbourne
По этому линку будет следующий результат:
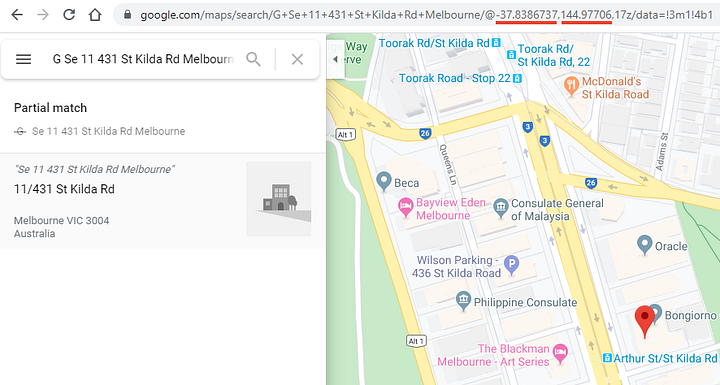
Этот адрес относится к Australian Nurses Memorial Centre. Давайте найдём его по названию на Google Maps:
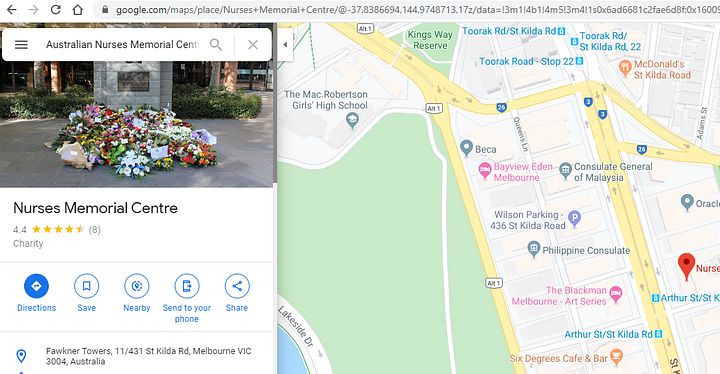
Мы получаем точно ту же точку, но вот координаты отличаются по URL. Это потому, что координаты в URL зависят от того, как отцентрирована карта, а не от положения маркера (оно меняется при увеличении или уменьшении масштаба). Поэтому мы будем извлекать координаты прямо из исходного кода самой страницы.
Чтобы посмотреть исходный код, надо кликнуть правой кнопкой мышки на пустом пространстве внутри страницы (снаружи карты) и выбрать View Page Source (CTRL+U или Command+U в MacOS). А теперь ищите -37.8 или 144.9 внутри исходной страницы:
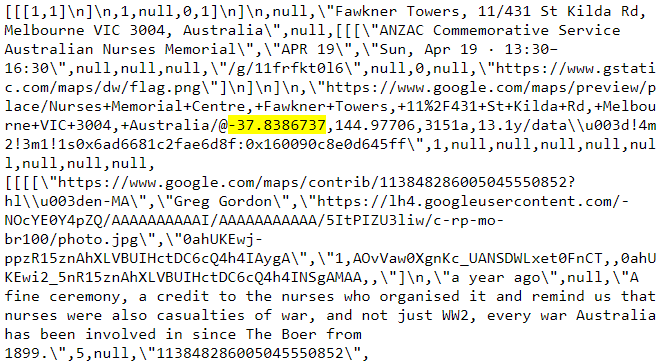
Нужные координаты есть в разных местах этого хаоса исходного кода. Если эти данные находятся внутри тега HTML, к которому мы можем обратиться, то они нам очень пригодятся. К счастью, есть один мета-тег, который может нам понадобиться:
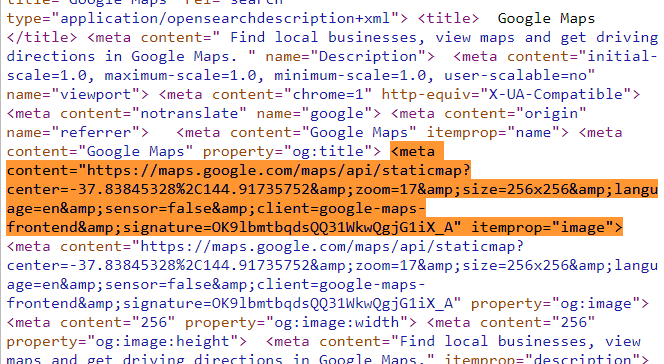
А теперь важно то, что в теге meta с атрибутом content находится URL, который мы хотим извлечь. Ещё можно взять атрибут itemprop со значением image, чтобы идентифицировать его и обратиться точно к этому тегу meta.
И всё, что нам осталось сделать, — запустить прохождение Selenium по каждому из URL и таргетировать этот тег meta, чтобы извлечь значение его атрибута content.
Вместе с Selenium

Вот какой код мы напишем, чтобы извлекать URL с координатами из Google Maps:
Url_With_Coordinates = []
option = webdriver.ChromeOptions()
prefs = {'profile.default_content_setting_values': {'images':2, 'javascript':2}}
option.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome("C:\\chromedriver.exe", options=option)
for url in tqdmn(mel.Url, leave=False):
driver.get(url)
Url_With_Coordinates.append(driver.find_element_by_css_selector('meta[itemprop=image]').get_attribute('content'))
driver.close()- Строчка 1: создаём пустой список
Url_With_Coordinates. Его мы заполним позже URL-адресами, которые хотим извлечь, как вы уже, наверное, догадались. - Строчки с 3 по 5: в приоритете запуск Webdriver без JavaScript и изображений. Таким способом процесс сэкономит время на загрузку веб-страниц. Конечно, этот метод не подойдет, если вы хотите извлечь то, что связано с JavaScript. Веб-страницы будут загружать изображения и JavaScript нормально, если убрать
'images':2, 'javascript':2. - Строчка 7: уточните для себя, куда вы разместили файл
chromedriver.exeна компьютере. У меня он лежит на диске С для простоты. Помните, что обратные слэши\в адресе должны быть двойными — только так адрес распознается. - Строчка 9: тут место для цикла итераций по наборам
mel.Url. Контейнерtqdmn()для содержимого итераций добавляет индикатор прямо за выполняемым элементом. Его параметрleave=Falseгарантирует, что индикатор исчезнет после завершения операции. - Строчка 10: WebDriver открывает тот URL для каждого URL из
mel.Url. Вы увидите, как открывается окно Chrome для первого URL, а после этого в адресной строке проходят один за другим остальные URL, пока проход поmel.Urlне закончится. - Строчка 11: сначала мы ищем наш тег
metaпри помощиdriver.find_element_by_css_selectorи идентифицируем его черезmeta[itemprop=image]. Затем извлекаем значение атрибутаcontentс.get_attribute('content'). Результат этой операции (URL с координатами) добавляется к спискуUrl_With_Coordinatesчерез командуappend(). - Строчка 13: после того как скрипт завершится, закрываем Webdriver. Так делать правильно.
Здесь найдёте скрипт и индикатор tqdm в действии (или же tqdmn, т.к. я пользуюсь подмодулем tqdm_notebook):
NB 1: когда вы в следующий раз запустите файл notebook, вам уже не понадобится запускать заново код, который скрапит веб-страницы. Мы ведь сохранили результат в CSV-файле под названием Url_With_Coordinates.csv. Давайте прочитаем этот файл:
import csvwith open('Url_With_Coordinates.csv', 'r') as f:
reader = csv.reader(f, delimiter=',')
for i in reader:
Url_With_Coordinates = i
breakNB 2: неприятно было бы делать итерации по тысячам адресов только для того, чтобы получить в конце ошибку. Вам нужно протестировать скрипт на паре значений до его полноценного запуска. В нашем случае тестовый код будет таким только для прохождения первых 10-ти значений из mel.Url:
for url in tqdmn(mel.Url[:10], leave=False):
driver.get(url)
......А вот как выглядит список Url_With_Coordinates:
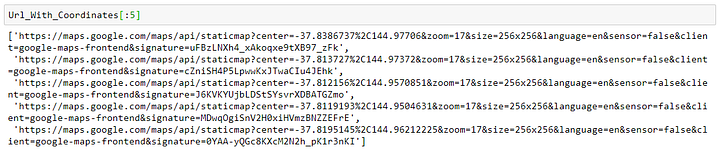
Добавляем этот список столбцом в датафрейм mel:
mel['Url_With_Coordinates'] = Url_With_Coordinates
Теперь такой вопрос: как нам получить координаты отдельно из этих URL? Привожу визуальное объяснение, как использовать метод split() в Python для ответа на этот вопрос:
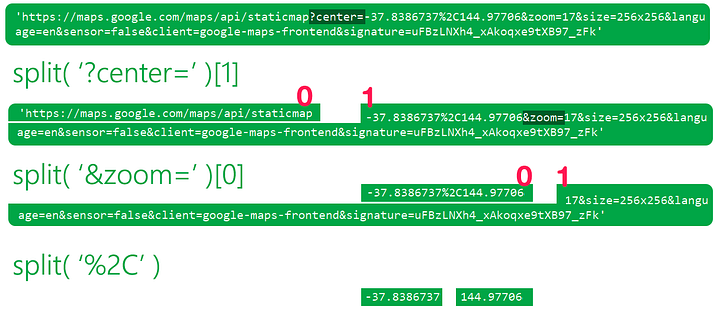
В коде то же самое будет выглядеть следующим образом (он нерабочий, потому что не определён url, привожу его, чтобы показать как будет работать решение с картинки выше):
url.split('?center=')[1].split('&zoom=')[0].split('%2C')Output:[-37.8386737, 144.97706]
А сейчас, зная это, мы добавим два новых столбца в датафрейм mel: lat для широты и long для долготы:
mel['lat'] = [ url.split('?center=')[1].split('&zoom=')[0].split('%2C')[0] for url in mel['Url_With_Coordinates'] ]mel['long'] = [url.split('?center=')[1].split('&zoom=')[0].split('%2C')[1] for url in mel['Url_With_Coordinates'] ]Скорее всего, этот код выдаст вам ошибку list index out of range:
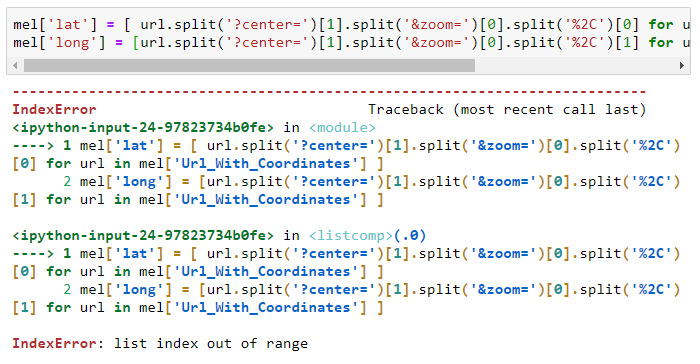
Эта ошибка говорит о том, что метод split() не сработал так, как ожидалось, на некоторых URL в колонке Url_With_Coordinates. Возможно, в некоторых URL не было ключевых слов, которые мы задавали для метода split(). Посмотрим-ка для примера на URL, в которых нет &zoom=:
mel[~mel.Url_With_Coordinates.str.contains('&zoom=')]
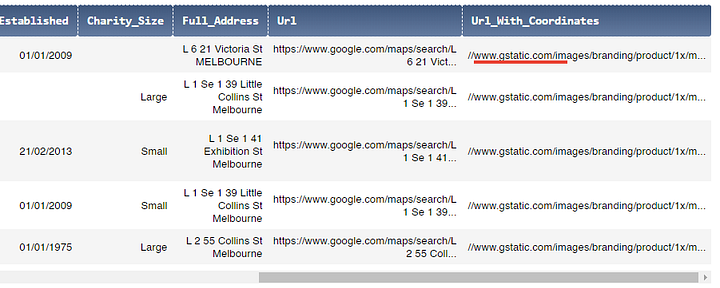
Видите, что у нас есть 5 инстансов, где полученные URL начинаются с //www.gstatic.com/images ...? Отсюда и ошибка:
list(mel[~mel.Url_With_Coordinates.str.contains('&zoom=')].Url_With_Coordinates)
Output:
['//www.gstatic.com/images/branding/product/1x/maps_round_512dp.png',
'//www.gstatic.com/images/branding/product/1x/maps_round_512dp.png', '//www.gstatic.com/images/branding/product/1x/maps_round_512dp.png', '//www.gstatic.com/images/branding/product/1x/maps_round_512dp.png', '//www.gstatic.com/images/branding/product/1x/maps_round_512dp.png']Чтобы было проще, да и 5 это не такое большое число, уберём эти инстансы из mel:
mel = mel[mel.Url_With_Coordinates.str.contains('&zoom=')].copy()
Теперь вернём код, который добавляет столбцы lat и long в наш датафрейм mel:
mel['lat'] = [ url.split('?center=')[1].split('&zoom=')[0].split('%2C')[0] for url in mel['Url_With_Coordinates'] ]mel['long'] = [url.split('?center=')[1].split('&zoom=')[0].split('%2C')[1] for url in mel['Url_With_Coordinates'] ]Сработало! Вот как выглядит датафрейм mel. В нём каждая организация получает свои значения долготы и широты (некоторые столбцы спрятаны):
mel.head()
Давайте нанесём координаты на карту, чтобы увидеть насколько они совпадают с точными.
Отмечаем координаты в Folium
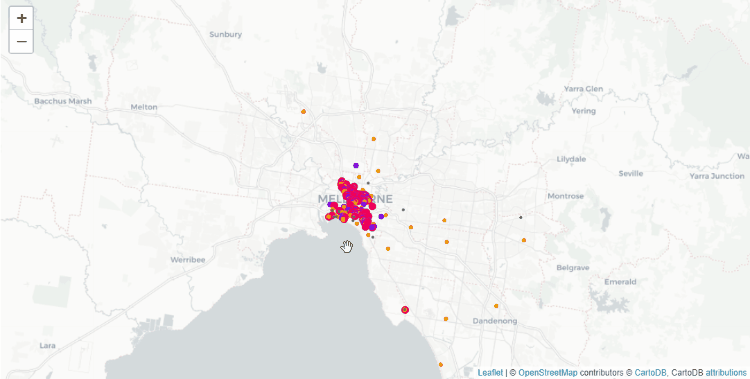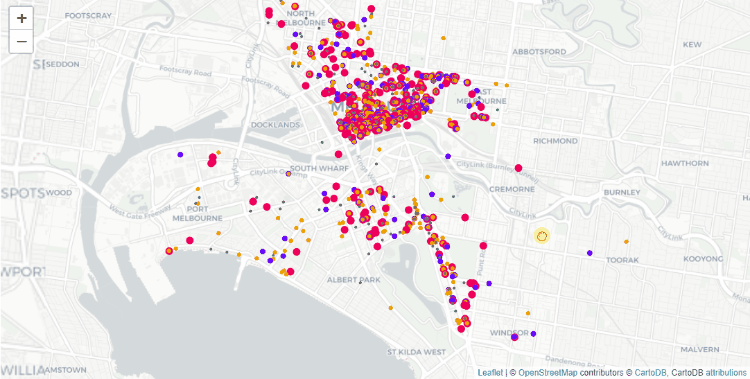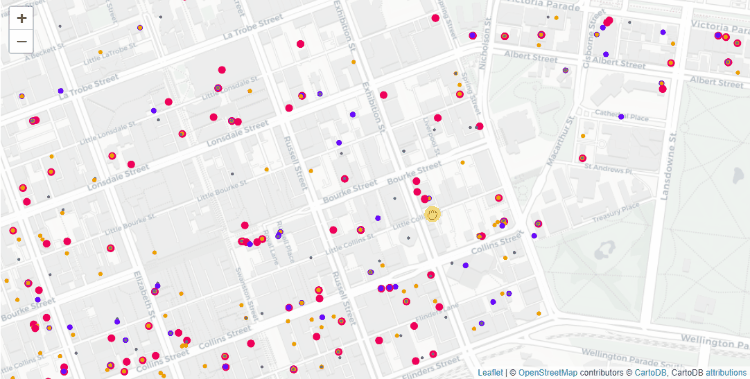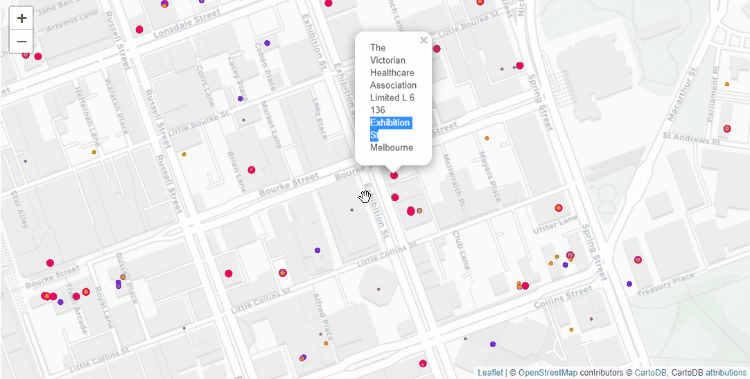
Цветовое кодирование (размер организации связан с годовой прибылью):
- Красный: большие организации (1 млн AUD (австралийский доллар) или более);
- Пурпурный: средние организации (от 250.000 AUD до 1 млн AUD);
- Оранжевый: маленькие организации (менее 250.000 AUD);
- Серый: нет данных.
Вот код, который нужен, чтобы нанести координаты на карту:
from IPython.display import IFrame
mel_large = mel[mel.Charity_Size == 'Large']
mel_medium = mel[mel.Charity_Size == 'Medium']
mel_small = mel[mel.Charity_Size == 'Small']
mel_other = mel[mel.Charity_Size == '']
mel_map = folium.Map( [-37.8, 145], tiles='CartoDB positron' )
for lat, long, name, full_address in zip(mel_large.lat, mel_large.long, mel_large.Charity_Legal_Name, mel_large.Full_Address):
folium.Marker( [lat, long],
icon=folium.CustomIcon( icon_image='https://i.imgur.com/CYx04oC.png', icon_size=(10,10) ), popup=name+'\n\n'+full_address ).add_to(mel_map)
for lat, long, name, full_address in zip(mel_medium.lat, mel_medium.long, mel_medium.Charity_Legal_Name, mel_medium.Full_Address):
folium.Marker( [lat, long],
icon=folium.CustomIcon( icon_image='https://imgur.com/Rzs4Zpa.png', icon_size=(8,8) ), popup=name+'\n\n'+full_address ).add_to(mel_map)
for lat, long, name, full_address in zip(mel_small.lat, mel_small.long, mel_small.Charity_Legal_Name, mel_small.Full_Address):
folium.Marker( [lat, long],
icon=folium.CustomIcon( icon_image='https://imgur.com/6TWrNOY.png', icon_size=(6,6) ), popup=name+'\n\n'+full_address ).add_to(mel_map)
for lat, long, name, full_address in zip(mel_other.lat, mel_other.long, mel_other.Charity_Legal_Name, mel_other.Full_Address):
folium.Marker( [lat, long],
icon=folium.CustomIcon( icon_image='https://imgur.com/C1MXk3r.png', icon_size=(4,4) ), popup=name+'\n\n'+full_address ).add_to(mel_map)
mel_map.save('mel_map.html')
IFrame(src='mel_map.html', width='100%', height=500)У меня нет в планах подробно рассказывать о работе с Folium, но вот некоторые важные моменты вам в помощь:
- Для этой карты я взял
CartoDB positron, потому что он обеспечивает низкий контраст по сравнению с цветными маркерами (он делает их более заметными). А вот применение плитки по умолчаниюOpenStreetMapприводит к тому, что увидеть маркеры становится сложно. - Размер маркера связан с размером организации. Я поменял его при помощи параметра
icon_size=(..,..)вfolium.CustomIcon. Причина следующая: нужно предотвратить наложение организаций друг на друга, когда их адреса относятся к одному и тому же зданию. Сначала прорисовываются большие маркеры, а мелкие накладываются поверх них. Таким образом, даже перекрывающие друг друга маркеры всё еще можно будет распознать. - Я взял кастомные маркеры (находятся на imgur). Решил так, потому что навигация между маркерами по умолчанию замедляется, когда их количество подходит к 2000 на одной карте. А вот для кастомных маркеров вы можете прикрепить URL к изображению, которое вы хотите использовать. Также подойдёт путь к изображению на вашем компьютере.
- Если нажать на маркер, то вы получите название организации и ее адрес, так что сможете проверить корректность позиционирования.
- В коде, который я приводил выше, я мог бы взять просто
mel_mapвместоmel_map.save('mel_map.html')и далееIFrame(src='mel_map.html', width='100%', height=500). Но когда количество маркеров большое, лучше сохранить карту в виде HTML-файла, а открывать черезIFrame(), иначе у вас будет пустая карта.
Насколько точный и надёжный этот метод?

Очень хороший вопрос. Очевидно, что лучший способ извлечь координаты из адресов — это обратиться к уже проверенным API, например Bing или Google Maps. Правда, это может стоить денег.
На точность метода очень сильно влияет достоверность и корректность предоставленного адреса. Вот, например, в нашем примере выше, вы заметили один маркер, отброшенный далеко в центр Индийского Океана. Исследование показало, что в адресе была ошибка. Было 65 Macarae Road Melbourne, а на самом деле нужно 65 Mcrae Road Melbourn.
Чтобы проверить наш метод эмпирически, мы возьмём датасет и с адресами, и с координатами тысяч бизнес-организаций в Вашингтоне. Мы сделаем так, чтобы получить случайный набор 500 бизнес-адресов и применим свой метод, чтобы сгенерировать по ним координаты. После этого, мы сравним результаты с актуальными координатами из списка датасета. Его мы будем использовать для нашего теста Загрузить можно тут:
- Basic Business License in Last 30 Days: opendata.dc.gov датасет, 6418 записей (на дату 26/01/2020), 2.64 Mb
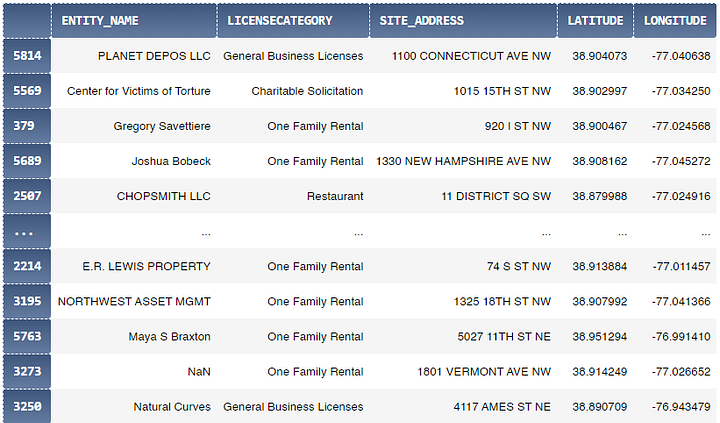
А вот здесь и результаты (тестовые детали доступны в Jupyter Notebook):
Убедитесь сами в том, что сгенерированные координаты почти такие же, как и точные координаты в этом случайном примере с 500 бизнес-организациями в Вашингтоне. Я сделал оранжевый маркер меньше, чем красный, так что вы увидите оба, когда они аккуратно наложатся друг на друга. Вот почему выглядит так, будто у оранжевых маркеров появляется красная обводка при увеличении изображения.
Читайте также:
- Продвинутые методы и техники списков в Python
- Проекты на Python с помощью Visual Studio Code
- Автоматизация работы с Python
Перевод статьи Khalid El Mouloudi: Using Python and Selenium to get coordinates from street addresses





