
Предыдущая часть: Движки JavaScript. Часть 1: парсинг
Как уже говорилось в первой части, работа традиционного компилятора состоит из двух этапов: анализа и синтеза.
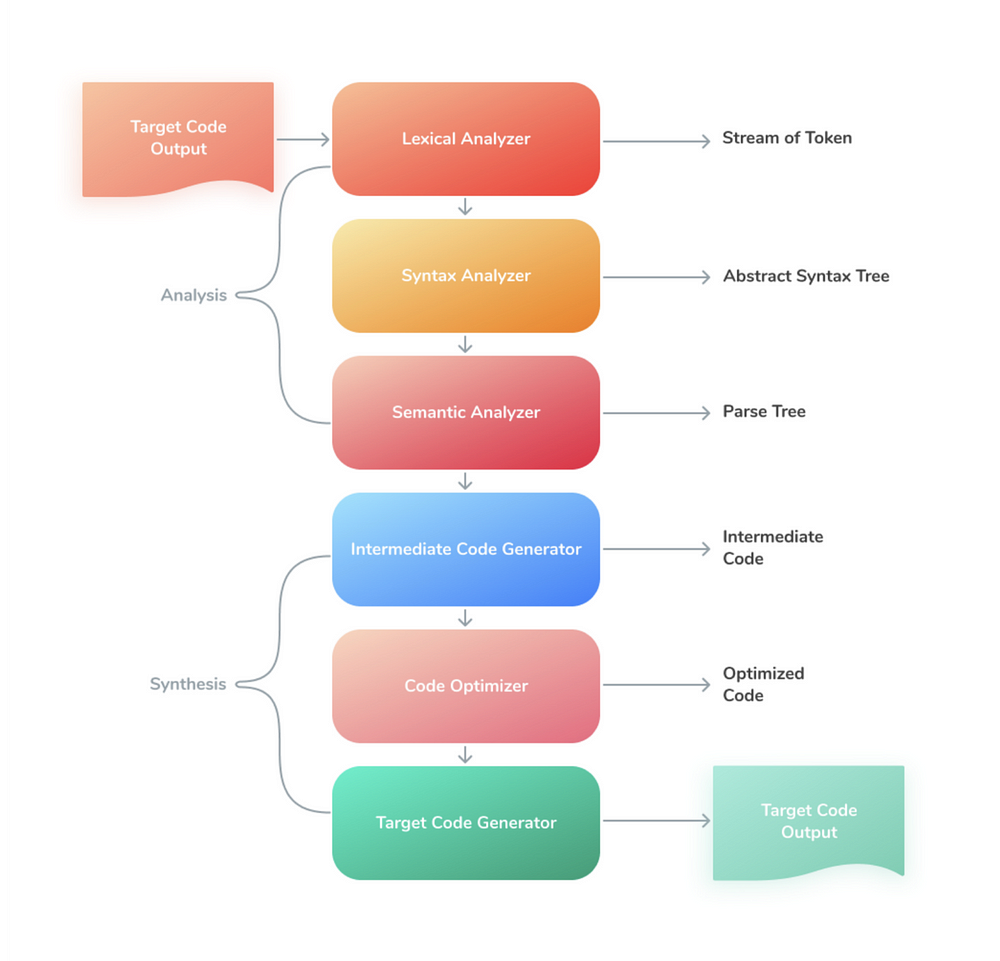
Сегодня подробно разберем второй этап — синтез.
Этап синтеза обычно заканчивается низкоуровневой программой-результатом, которую можно запустить. Она состоит из 3 компонентов.
- Генератор промежуточного кода. Генерирует промежуточный код, который может быть переведен в машинный. Промежуточное представление может иметь различные формы, такие как трехадресный код (не зависит от языка), байт-код или стековый код.
- Оптимизатор кода. Делает потенциальный целевой код более быстрым и эффективным.
- Генератор кода. Производит целевой код, который может быть запущен на конкретной машине.
Генераторы промежуточного кода
Движок V8 снабжен Ignition — быстрым низкоуровневым интерпретатором на основе регистров.
Вот что говорится о нем в блоге V8.
Интерпретатор Ignition использует низкоуровневые, независимые от архитектуры инструкции макроассемблера TurboFan для генерации байт-кодовых обработчиков для каждого операционного кода. TurboFan компилирует эти инструкции под целевую архитектуру, выполняя при этом выбор низкоуровневых инструкций и распределение машинных регистров.
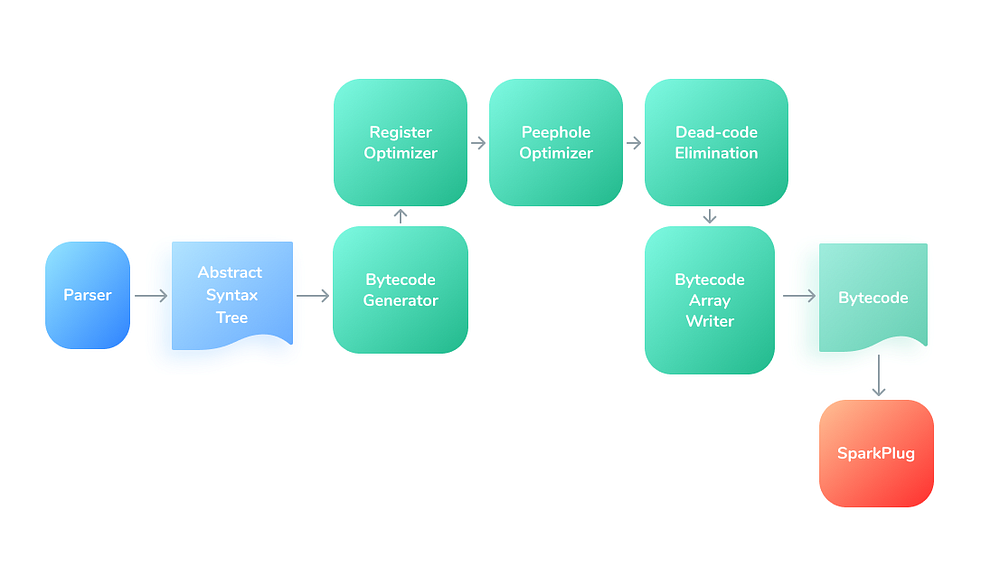
А вот что гласит документация Ignition.
Сам интерпретатор состоит из набора фрагментов кода обработчика байт-кода, каждый из которых обрабатывает определенный байт-код и передает его обработчику следующего байт-кода. Эти обработчики байт-кода написаны в форме ассемблерного кода высокого уровня, не зависящего от архитектуры машины, который реализуется классом
CodeStubAssemblerи компилируется Sparkplug.
Чтобы скомпилировать функцию в байт-код, код JavaScript парсится для генерации AST (абстрактного синтаксического дерева). BytecodeGenerator просматривает это AST и генерирует байт-код для каждого из узлов AST по мере необходимости.
Движок SpiderMonkey снабжен интерпретатором C++, который производит промежуточный код вместе с базовым интерпретатором. Базовый интерпретатор выполняет неоптимизированный код почти сразу.
JSC: LLInt (Low-Level Interpreter, низкоуровневый интерпретатор) выполняет байт-код, произведенный парсером. Однако его нельзя назвать генератором промежуточного кода, поскольку он производит машинный код.
Неоптимизирующая компиляция
В чем основная идея неоптимизирующей компиляции в конвейере движка? Оптимизированный код работает лучше и быстрее, требует меньших объемов памяти и т. д.
Оптимизация — это процесс, требующий времени и вычислительной мощности. Поэтому нецелесообразно тратить на нее усилия для коротких сессий JavaScript, таких как загрузка сайтов и использование инструментов командной строки. Кроме того, деоптимизация оптимизированного кода — это масштабная операция, которая может занять дополнительное время.
В V8 есть Sparkplug, который представляет собой транспилятор/компилятор, преобразующий байт-код Ignition в машинный код и переводящий JS-код из функционирования в виртуальной машине/эмуляторе в работу в нативном режиме.
SpiderMonkey снабжен базовым интерпретатором для компиляции JS среднего уровня. Этот базовый интерпретатор хорошо работает с интерпретатором C++ и базовым JIT.
JavaScriptCore имеет 4 различных компилятора. Первый из них, LLInt, является неоптимизирующим и сочетает в себе генератор базового кода и неоптимизирующий интерпретатор. Кодовая база низкоуровневого интерпретатора находится в папке /llint. LLInt написан на переносимом ассемблере под названием offlineasm.
LLInt используется, чтобы свести к нулю начальные затраты, помимо лексирования и парсинга. При этом он подчиняется принципам, по которым работают вызовы, стеки и регистры, используемые JIT-компиляторами. Например, вызов функции LLInt работает, “как если бы” функция была скомпилирована в нативный код, за исключением того, что точка входа машинного кода является общей вводной частью LLInt. LLInt включает в себя базовые оптимизации, такие как встроенное кэширование для обеспечения быстрого доступа к свойствам.
Оптимизирующая компиляция с низким эффектом
Некоторые функции выполняются так быстро, что запуск любого компилятора для них будет стоить дороже, чем их интерпретация. Некоторые функции вызываются так часто или имеют такие длинные циклы, что общее время их выполнения намного превышает время компиляции их агрессивным оптимизирующим компилятором. Но есть также множество функций, находящихся в “серой зоне” между этими вариантами. Они выполняются недостаточно долго, чтобы использование агрессивного компилятора можно было назвать выгодным в этом случае, но достаточно долго, чтобы некоторые промежуточные проектные решения компиляторов могли обеспечить ускорение процесса.
Только JavaScriptCore имеет в своем производственном конвейере оптимизирующие компиляторы с низким эффектом: базовый JIT и DFG JIT, или JIT информационного потокового графа.
Базовый JIT выполняет несколько базовых оптимизаций. Он начинает работать при вызове функций не менее 6 раз или при повторении цикла не менее 100 раз (или при некоторой комбинации, например 3 вызова с 50 итерациями цикла). LLInt будет замещать в стеке (OSR) базовый JIT, если тот застрянет в цикле.
Базовый JIT выдает шаблон машинного кода для каждой инструкции байт-кода, не пытаясь понять связь между несколькими инструкциями в функции. Он компилирует целые функции, что делает его JIT-методом. Базовый JIT не выполняет функцию OSR, но снабжен целым рядом ромбовидных спекуляций, основанных на LLInt-профилировании.
Ромбовидная спекуляция означает, что при каждом выполнении операции у нас есть быстрый путь, специализированный под требования профилировщика, и медленный путь для обработки общего случая.
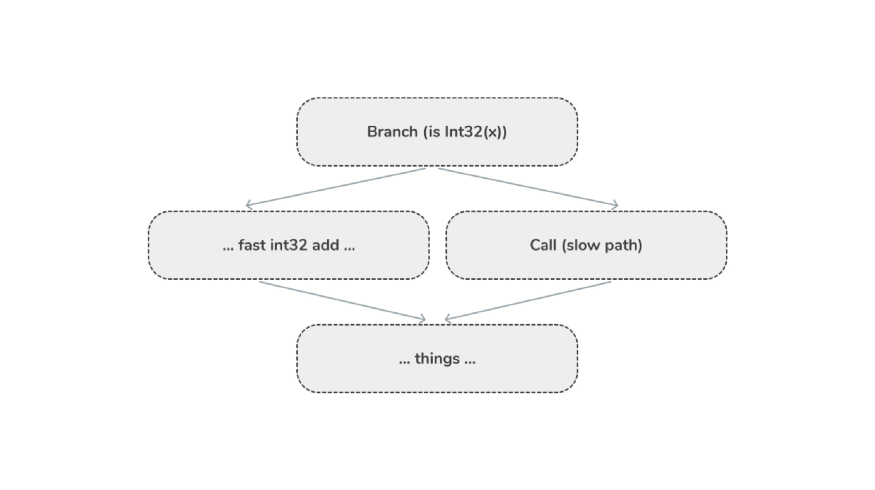
Или в виде псевдокода:
if (is int)
int add
else
Call(slow path)
DFG более агрессивен. Он начинает работать с функциями, которые вызываются не менее 60 раз или выполнили цикл не менее 1000 раз. DFG выполняет спекуляцию агрессивного типа на основе информации профилирования, собранной нижними уровнями.
DFG может выполнять OSR-спекуляцию на основе профилирования LLInt и базового интерпретатора, а в некоторых редких случаях даже используя данные профилирования, собранные DFG JIT и FTL JIT. Он может выйти из OSR либо на базовый интерпретатор, либо на LLInt.
DFG избегает дорогостоящих оптимизаций и идет на многие компромиссы, чтобы обеспечить быструю генерацию кода.
У V8 тоже есть некоторые секреты. Он снабжен оптимизирующим компилятором среднего уровня TurboProp, который отключен. Это более быстрая и легкая версия TurboFan с отключенными “тяжелыми” оптимизациями. Его можно включить для локальной сборки V8.
Поскольку в данном случае он отключен, мы не будем углубляться дальше в эту тему.
DEFINE_BOOL(turboprop, false, "enable experimental turboprop mid-tier compiler")
Здесь можно найти больше флагов V8.
Оптимизирующие компиляторы с высоким эффектом
Все три движка снабжены высокоэффективными оптимизирующими компиляторами.
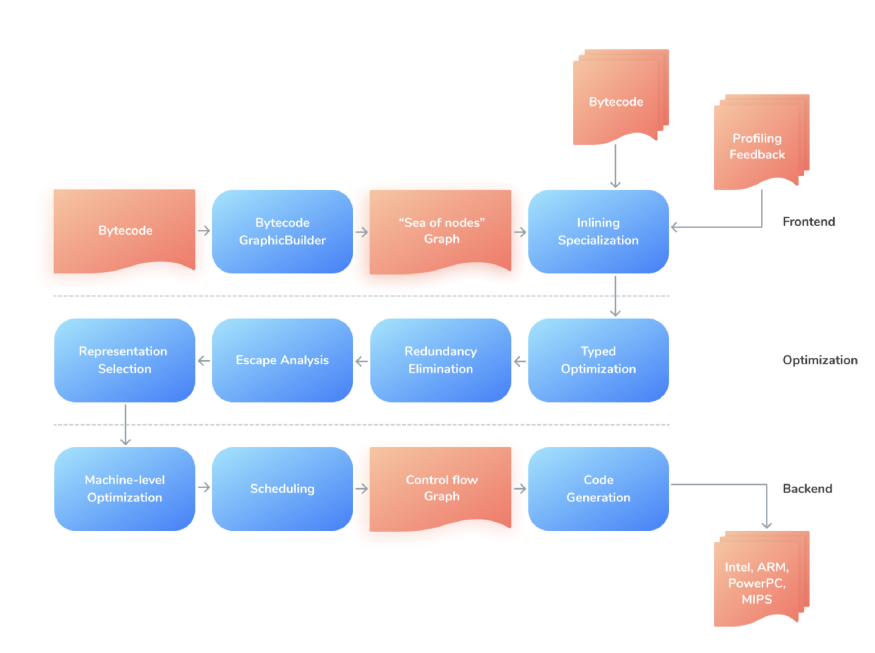
В V8 есть оптимизирующий компилятор TurboFan, который читает байт-код из Ignition. Он стал заменой Full-Codegen из старых версий V8.
TurboFan имеет многоуровневую архитектуру. Она гораздо более общая и имеет меньшую кодовую базу со слоями абстракции и без спагетти-кода. В нее легко вносить улучшения (для новых стандартов ES) и проще добавлять генераторы кода, специфичные для отдельных машинных систем (например, код для архитектур IBM, ARM и Intel).
Основная идея TurboFan — промежуточное представление (intermediate representation, IR) в виде моря узлов. TurboFan берет инструкции из Ignition, оптимизирует их и создает специфичный для платформы машинный код.
SpiderMonkey располагает компилятором IonMonkey, который преследует две основные цели.
- Опирается на продуманное проектное решение, которое позволяет без проблем поддерживать добавление новых оптимизаций.
- Поддерживает специальные возможности, необходимые для создания чрезвычайно быстрого кода.
Первую цель IonMonkey успешно реализует с помощью многоуровневой высоко абстрактной архитектуры.
Чтобы реализовать вторую цель, IonMonkey идет по следам базового JIT. Он поддерживает оптимистичные предположения об эффектах и результатах операций и дает этим предположениям распространяться по всему генерируемому коду. Как и в случае трассировщика, для этого процесса требуется защита. Защитную функцию выполняют проверки, расположенные в стратегически важных местах. Если проверка “проваливается”, происходит деоптимизация. Когда защита не срабатывает, наступает аварийное реагирование.
Компиляция IonMonkey характеризуется четырьмя основными общими фазами.
- Генерация MIR (внутреннего представления среднего уровня). Во время этой фазы байт-код SpiderMonkey преобразуется в граф потоков управления и независимую от архитектуры статическую форму внутреннего представления с одноразовым присваиванием.
- Оптимизация. MIR анализируется и оптимизируется. На этом этапе происходит нумерация глобальных значений (GVN) и вынос инвариантного кода за цикл (LICM).
- Понижение. MIR преобразуется в специфическое для архитектуры IR (все еще в форме SSA — промежуточного представления с одноразовым присвоением), называемое LIR или низкоуровневое IR. На LIR происходит распределение регистров. LIR специфично для платформы и необходимо для генерации кода.
- Генерация кода. LIR преобразуется в нативный ассемблер для x86, x64 или ARM (в зависимости от конкретного случая).
JavaScriptCore располагает FTL JIT (Faster Than Light JIT, JIT-компилятор, который “быстрее, чем свет”). Он разработан для обеспечения максимальной пропускной способности. FTL никогда не идет на компромисс в отношении производительности ради ускорения времени компиляции. Этот JIT-компилятор повторно использует большинство оптимизаций DFG JIT и добавляет к ним множество других. FTL JIT задействует несколько промежуточных представлений (DFG IR, DFG SSA IR, B3 IR и Assembly IR). Он снабжен оптимизатором Bare Bones Backend.
Компилятор B3 включает в себя два промежуточных представления: представление более высокого уровня на основе SSA, называемое B3 IR, и представление более низкого уровня, которое фокусируется на таких деталях машины, как регистры. Эта низкоуровневая форма называется Air (Assembly Intermediate Representation).
Проектные решения B3 IR и Air дают подходящую основу для создания продвинутых оптимизаций. Оптимизатор B3 уже включает в себя множество путей оптимизации (перечислены ниже).
Упрощение выражений, которое охватывает:
- упрощение графа потока управления;
- агрессивное устранение мертвого кода;
- устранение проверки целочисленного переполнения;
- множество различных правил упрощения.
Свертка констант, чувствительных к потоку.
Устранение глобальных общих подвыражений.
Дублирование хвостов.
Исправление SSA.
Оптимальное размещение материализаций констант.
FTL также выполняет оптимизацию в Air, например устранение мертвого кода, упрощение графа потока управления, исправление частичных замедлений регистров и проблем со spill-кодом. Наиболее значительной оптимизацией, проводимой в Air, является распределение регистров.
Оптимизации
Как JS-движки могут оптимизировать код? Поговорим об этом подробнее!
Инлайнинг (встраивание функций)
Популярный способ оптимизации активных участков.
Скрытые классы
Все основные движки реализуют эту функцию одинаково.
В спецификации ECMAScript все объекты определены как словари.
- В программах JavaScript обычно имеется несколько объектов с одинаковыми ключами.
- Движки создают скрытые классы, которые присоединяются к каждому объекту для отслеживания его формы.
- Это несколько сокращает время доступа к свойствам.
Когда к объекту добавляется свойство, старый скрытый класс переключается на новый скрытый класс с новым свойством в нем. При наличии двух разных классов движок не может быстро получить доступ к свойствам, так как не способен выполнять встроенное кэширование.
Помните об аварийном реагировании!
- Добавьте свойство к существующему объекту. Старый скрытый класс переключится на новый с новым свойством.
- При наличии двух разных классов движок не может быстро получить доступ к свойствам, так как не способен выполнять встроенное кэширование.
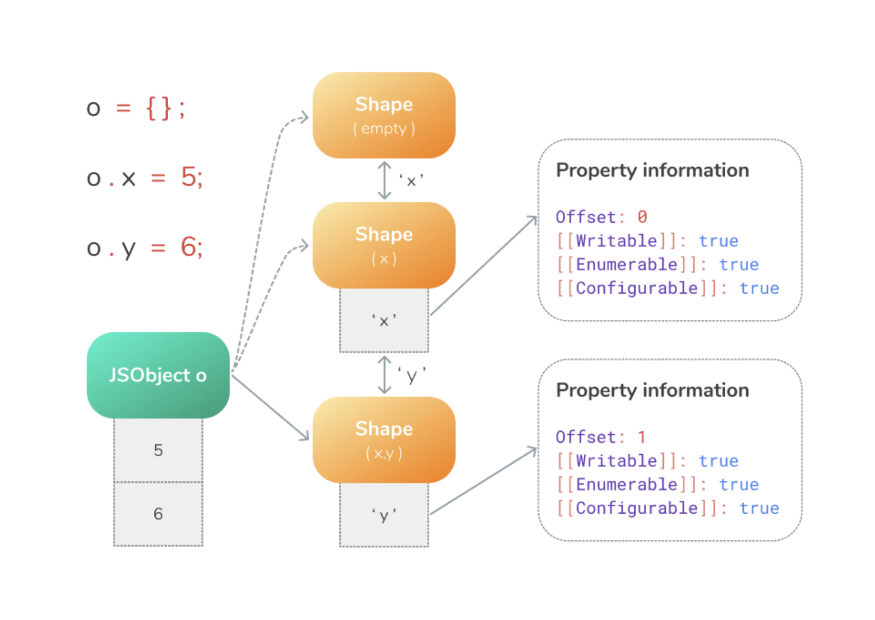
- У
JsObject oесть собственный пустой скрытый класс. - Добавление к нему ключа
o.xсоздает новый скрытый класс с ключомx. - Добавление ключа
o.yсоздает новый скрытый класс с ключамиxиy.
Скрытые классы имеют разные названия в разных движках.
- Общее название — скрытые классы.
- V8 — Карты (Maps).
- JavaScriptCore — Структуры (Structures).
- SpiderMonkey — Формы (Shapes).
Встроенное кэширование, оптимизация дорогостоящего поиска
Основной мотивацией скрытых классов является концепция встроенного кэширования.
Матиас Байненс описал эту функцию в своей работе “Основы движка JavaScript: формы и встроенное кэширование”.
Простое описание:
JavaScript-движки используют встроенное кэширование для запоминания информации о том, где найти свойства объектов, и для уменьшения количества дорогостоящих поисков. Это своего рода ярлык для свойств объекта.
- Движок кэширует тип объектов, которые передаются в качестве параметра в вызовах методов.
- Движок использует эту информацию, чтобы предположить тип объекта, который передается в качестве параметра в будущем.
- Если это предположение верно, движок может пропустить получение доступа к реальным свойствам объекта в памяти и вернуть вместо них кэшированные значения.
Функция getX, которая принимает объект и загружает из него свойство x:
function getX(o) {
return o.x;
}
Будет сгенерирован следующий байт-код:
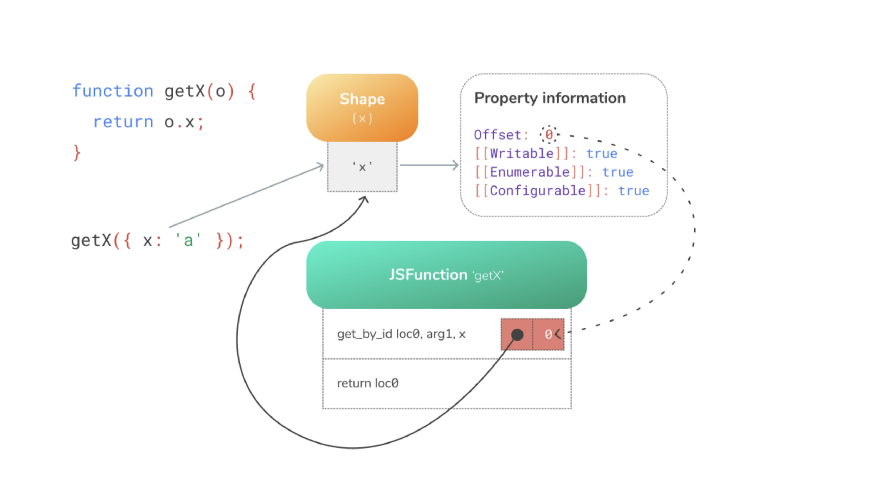
Первая инструкция get_by_id загружает свойство 'x' из первого аргумента (arg1) и сохраняет результат в loc0. Вторая инструкция возвращает то, что мы сохранили в loc0.
Когда вы выполняете функцию в первый раз, инструкция get_by_id ищет свойство 'x' и обнаруживает, что значение хранится по смещению 0.
Встроенное в инструкцию get_by_id кэширование запоминает скрытый класс и смещение, по которому было найдено свойство:
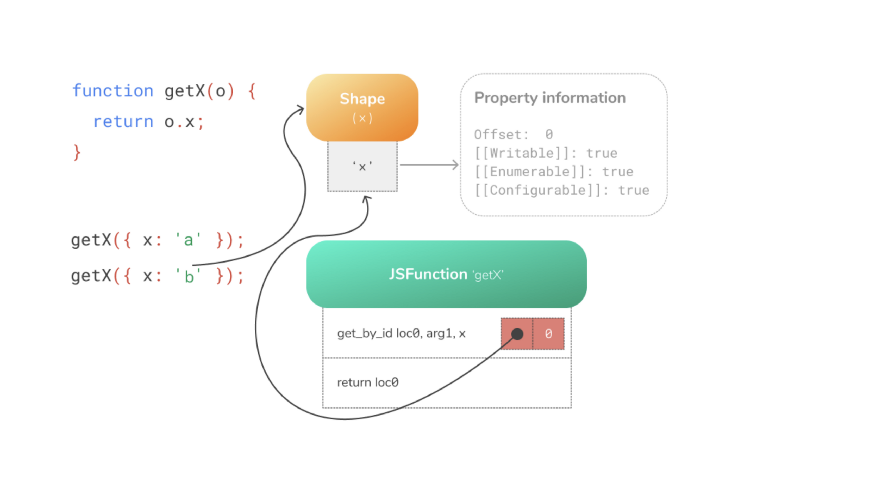
При последующих запусках встроенному кэшированию нужно только сравнивать скрытый класс. Если он оказывается тем же, что и раньше, то происходит загрузка значения из запомненного смещения.
В частности, если движок JavaScript видит объекты со скрытым классом, которые были записаны посредством встроенного кэширования ранее, больше не нужно будет обращаться к информации о свойстве. В этом случае необходимость в дорогостоящем поиске информации о свойстве полностью отпадает. Не нужно каждый раз искать свойство, поэтому JS-движки работают с молниеносной быстротой!
Как оптимально использовать скрытые классы?
- Старайтесь определять все свойства в конструкторе объекта.
- Если вы динамически добавляете новые свойства к объектам, всегда инстанцируйте их в одном и том же порядке, чтобы скрытые классы могли быть общими для этих объектов.
- Старайтесь не добавлять и не удалять свойства объектов во время выполнения.
Дополнительная информация: аварийное реагирование
Если динамическая проверка “провалилась”, деоптимизатор депонирует код.
- Удаляет оптимизированный код.
- Строит фрейм интерпретатора из оптимизированного стека.
- Переключается на компилятор с меньшим эффектом.
Простой пример аварийного реагирования:
- не Smi (малое целое число).
Вспоминаем ромбовидную спекуляцию:
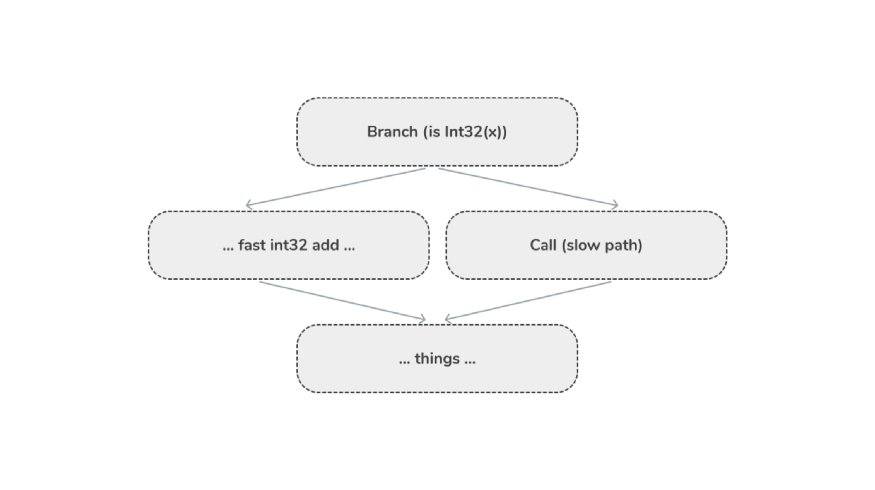
Операция fast int32 add хорошо оптимизирована и является “нативной” для платформы. В противном случае код будет выполняться медленно, без оптимизированной операции.
Читайте также:
- Поверхностное и глубокое копирование в JavaScript
- Интересные подробности об объектах JavaScript
- Фреймворк или язык программирования?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Yan Hulyi: Inside JavaScript Engines, Part 2: code generation and basic optimizations





