
JavaScript становится все более популярным. “Написанное однажды выполняется в любом месте” — это про JavaScript (не только про Java)! Но что лежит в основе этого процесса? V8, SpiderMonkey, JavaScriptCore и многие другие движки. Хорошим примером “выполнения в любом месте” были движки Nashorn и Rhino, основанные на Java Virtual Machine, но слышали ли вы когда-нибудь о них?
Рассмотрим подробно движки JavaScript и их механизм работы.
После долгих и изнурительных браузерных войн осталось 3 основных движка JavaScript.
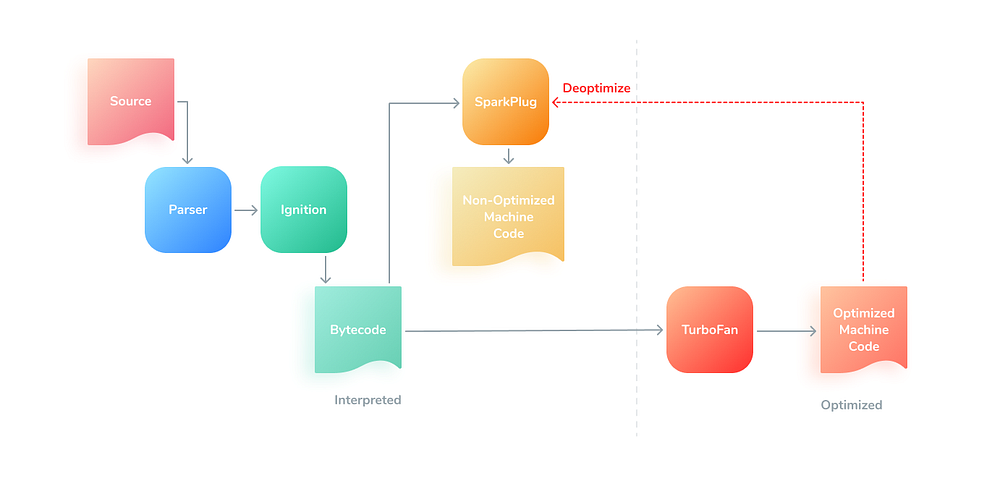
V8
V8, поддерживаемый компанией Google, используется в Chrome и среде Node.js. V8 поддерживает современный EcmaScript, имеет довольно новый базовый компилятор для более быстрого запуска JavaScript (Sparkplug), выполняет сборку мусора, поддерживает WebAssembly и реализует широкий спектр оптимизаций кода.
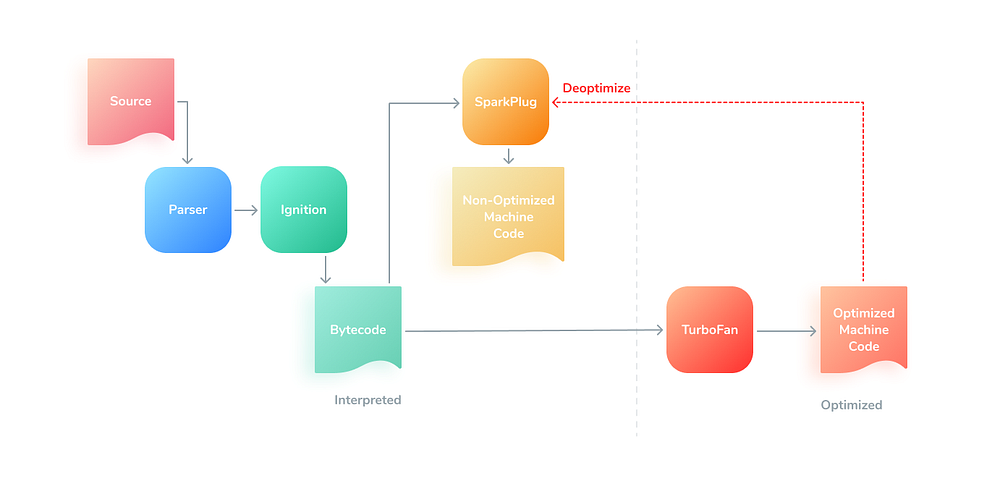
Конвейер компиляции V8 включает в себя 3 компилятора (позже появится еще один — маломощный TurboProp).
- Ignition — интерпретатор V8 из парсера в байт-код.
- Sparkplug — неоптимизирующий компилятор из байт-кода в машинный код.
- TurboFan — оптимизирующий компилятор из байт-кода в машинный код, который сейчас выполняет деоптимизацию непосредственно в Sparkplug.
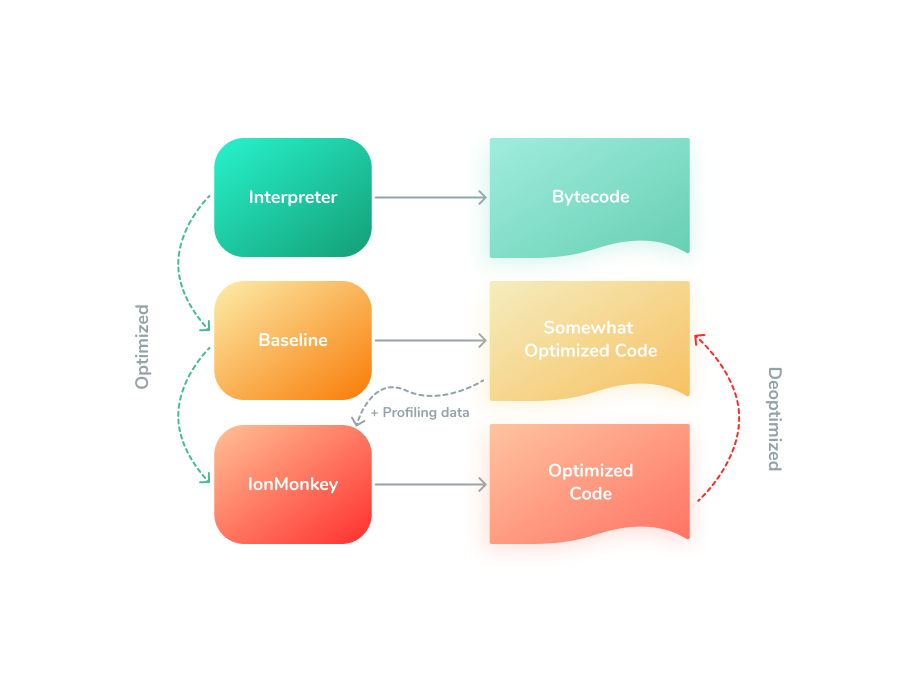
SpiderMonkey
SpiderMonkey, поддерживаемый Firefox, используется в Mozilla Firefox, MongoDB, CouchDB и Gnome (еще до появления V8). Этот движок JavaScript имеет хороший конвейер, который позволяет быстро запускать JavaScript.
SpiderMonkey включает в себя быстрый интерпретатор Baseline с компилятором, который может производить неоптимизированный код. Пока он работает, оптимизирующий компилятор выполняет собственную работу по оптимизации активных участков. Кроме того, SpiderMonkey обладает сборщиком мусора и может работать с WebAssembly.
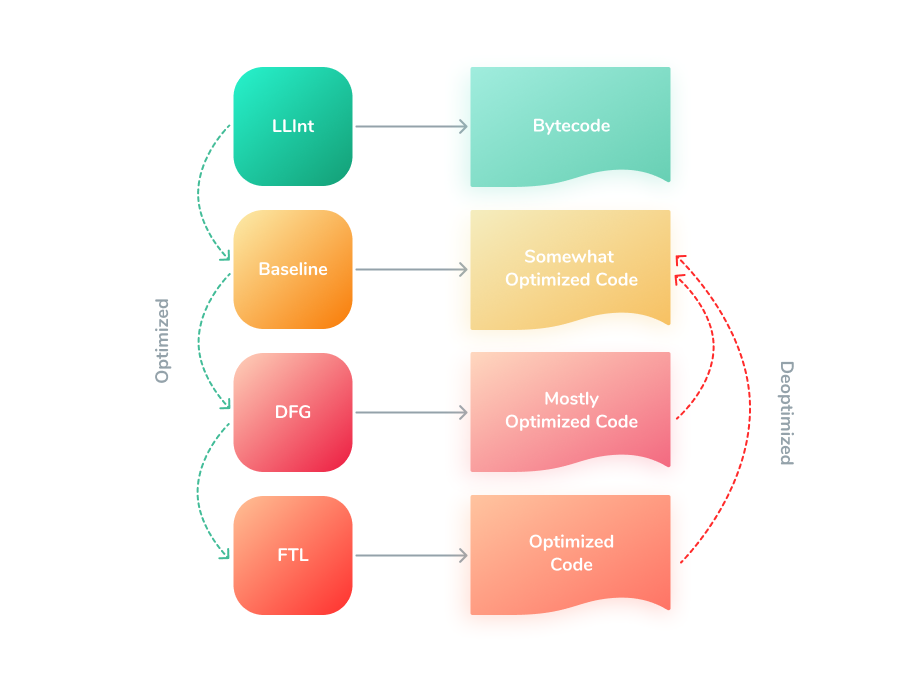
JavaScriptCore
JavaScriptCore (JSC) — встроенный JavaScript-движок для Webkit. Он используется в Safari и во всех браузерах iOS. Последние версии JSC поддерживают EcmaScript 2021. Это оптимизирующая виртуальная машина, включающая в себя несколько строительных блоков: лексер, парсер, стартовый интерпретатор (LLInt), базовый JIT, оптимизирующий JIT с низкой задержкой (DFG) и оптимизирующий JIT с высокой пропускной способностью (FTL).
Таким образом, JSC имеет 4-уровневую компиляцию. Возможно, в V8 она появится позже, когда будет выпущен оптимизирующий компилятор TurboProp с низкой задержкой. Кроме того, JSC выполняет сборку мусора.
Другие движки, достойные упоминания
Hermes — движок, созданный для оптимизации функций React Native. Он отличается низким потреблением памяти, а также обеспечивает опережающую статическую оптимизацию и компактный байт-код.
JerryScript — суперлегкий движок, используемый для интернета вещей. Он способен работать на устройствах с небольшим объемом оперативной памяти и весит менее 200 КБ.
Теоретическая часть
Что такое компилятор и интерпретатор?
Компилятор — это компьютерная программа, которая преобразует код с одного языка программирования (например, Python, Java и JavaScript) в другой (например, низкоуровневые машинные инструкции или VM-код). Существует несколько типов компиляторов. Например, транспилятор, который преобразует код с языка высокого уровня на другой язык высокого уровня. Так, TSC, транспилятор TypeScript, компилирует код TypeScript в JavaScript.
Основное различие между компилятором и интерпретатором заключается в том, что интерпретатор просматривает код построчно и выполняет его, а компилятор сначала готовит код к выполнению.
Промежуточное положение занимает компилятор Just-In-Time (JIT), который чрезвычайно популярен в движках динамических языков, таких как JavaScript. Для эффективной работы JIT-компилятор должен получать информацию о профиле, чтобы знать, насколько интенсивно ему нужно оптимизировать код.
Вот что говорится о JIT-компиляции в Википедии.
В вычислительной технике JIT-компиляция (just-in-time, “точно в нужное время”), также известная как динамическая трансляция или компиляция во время выполнения, — это способ выполнения компьютерного кода, который предполагает компиляцию во время выполнения программы, а не перед выполнением.
JIT-компиляция представляет собой комбинацию двух традиционных подходов к переводу в машинный код — опережающей компиляции (ahead-of-time compilation, AOT) и интерпретации — и сочетает в себе некоторые преимущества и недостатки обоих подходов. Грубо говоря, JIT-компиляция сочетает скорость компилированного кода с гибкостью интерпретации, с расходами интерпретатора и дополнительными расходами на компиляцию и компоновку (не только интерпретацию). JIT-компиляция является разновидностью динамической компиляции и предполагает адаптивную оптимизацию, такую как динамическая перекомпиляция, и ускорение, специфичное для микроархитектуры.
Традиционный процесс компиляции включает в себя 2 этапа:
- анализ;
- синтез.
Рассмотрим подробно этап анализа.
В результате прохождения этого этапа создается промежуточное представление. В данном случае это абстрактное синтаксическое дерево.
Его создание также включает в себя несколько этапов:
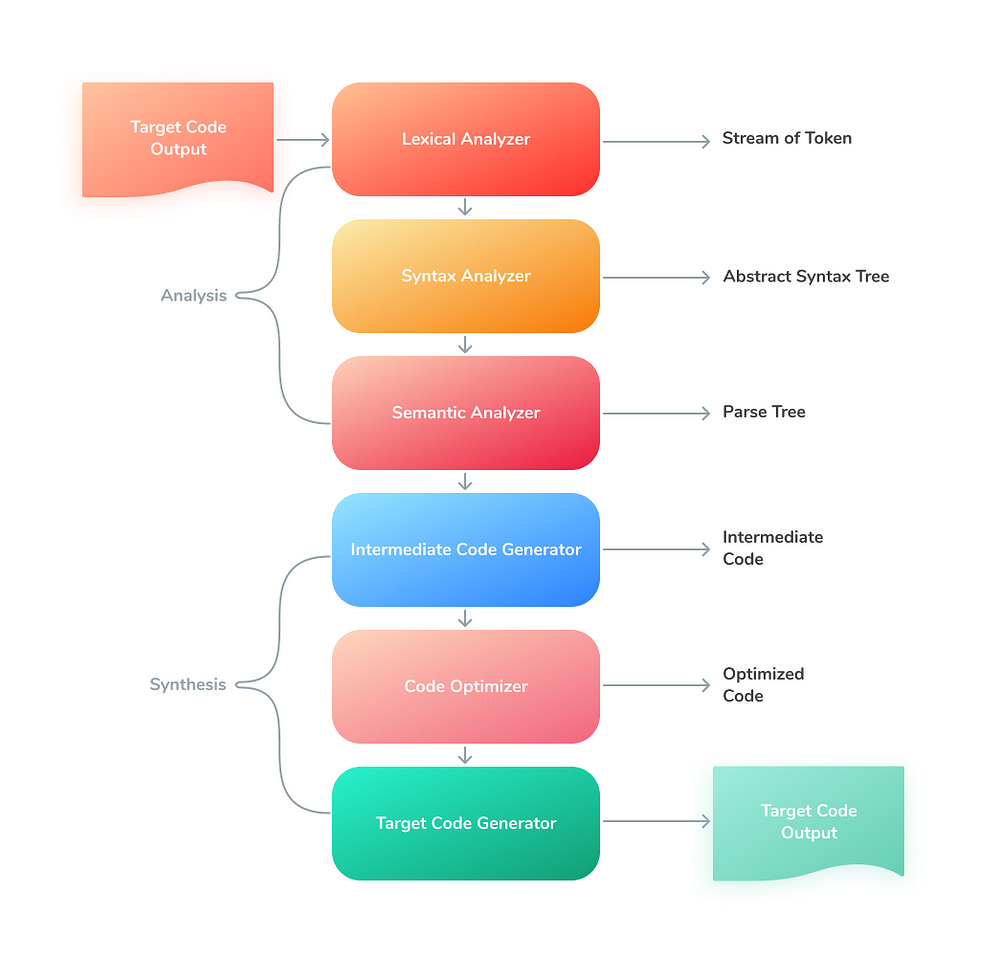
- Лексический анализатор. Также называется сканером. Он берет символы из исходного кода и группирует их в лексемы, которые соответствуют токенам. Также удаляет комментарии и пробелы. Обычно использует вывод препроцессора (который выполняет включение файлов и макрорасширение).
- Синтаксический анализатор. Также называется парсером. Он строит парсинговое дерево (или синтаксическое дерево).
- Семантический анализатор. Проверяет парсинговое дерево, подтверждает его и создает верифицированное парсинговое дерево. Он также выполняет различные проверки, такие как проверка типов, проверка потока управления и проверка меток.
Этап синтеза обычно заканчивается созданием программы-результата — какого-нибудь низкоуровневого продукта, готового к запуску.
Этот продукт состоит из трех частей:
Генератор промежуточного кода. Генерирует промежуточный код, который можно перевести в машинный. Промежуточное представление может быть представлено в различных формах, таких как трехадресный код (3AC, TAC, независимый от языка) и байт-код.
- Трехадресный код — промежуточный код, используемый оптимизирующими компиляторами. Это высокоуровневая сборка, в которой каждая операция имеет не более трех операндов.
- Байт-код — промежуточное представление для виртуальных машин и компиляторов. Это компактный числовой код (обычно нечитаемый человеком), константы и ссылки. Байт-код обрабатывается программным, а не аппаратным обеспечением.
Оптимизатор кода. Делает потенциальный целевой код быстрее и эффективнее.
Генератор кода. Генерирует целевой код, который может быть запущен на конкретной машине.
Более подробное описание этапа анализа JavaScript (на примере V8 в Chrome)
Что нужно сделать для выполнения JavaScript?
Как говорится в блоге V8 в статье “Удивительно быстрый парсинг. Часть 1: оптимизация сканера”:
Для запуска программы на JavaScript исходный текст необходимо обработать так, чтобы V8 мог его понять. V8 начинает с парсинга исходника в абстрактное синтаксическое дерево (AST) — набор объектов, представляющих структуру программы. Затем AST компилируется в байт-код программой Ignition.
В общих чертах, выполнение JavaScript требует следующих шагов.
- Парсинг кода для генерации AST (абстрактного синтаксического дерева).
- Компиляция разобранного парсером кода (обычно выполняется базовым и оптимизирующим компилятором).
Первым шагом в выполнении кода JavaScript является парсинг кода — парсер генерирует структуры данных: AST и Scope.
- Абстрактное синтаксическое дерево (AST) — это древовидное представление синтаксической структуры кода JavaScript.
- Scope — это другая структура данных, в которой хранятся прокси переменных, помогающие управлять областью видимости и ссылками на переменные внутри функций. Парсинг напрямую влияет на стартовую производительность запуска JavaScript.
Как уже упоминалось в теоретической части о компиляции, парсинг включает в себя два этапа: лексический и синтаксический анализ.
Лексический анализ предполагает чтение потока символов из кода и объединение их в токены, а также удаление символов пробела, комментариев и т. д. В итоге вся цепочка кода будет расщеплена на список токенов.
Синтаксический анализатор, также называемый парсером, превращает простой список токенов, полученный после лексического анализа, в древовидное представление, а также проверяет синтаксис языка.
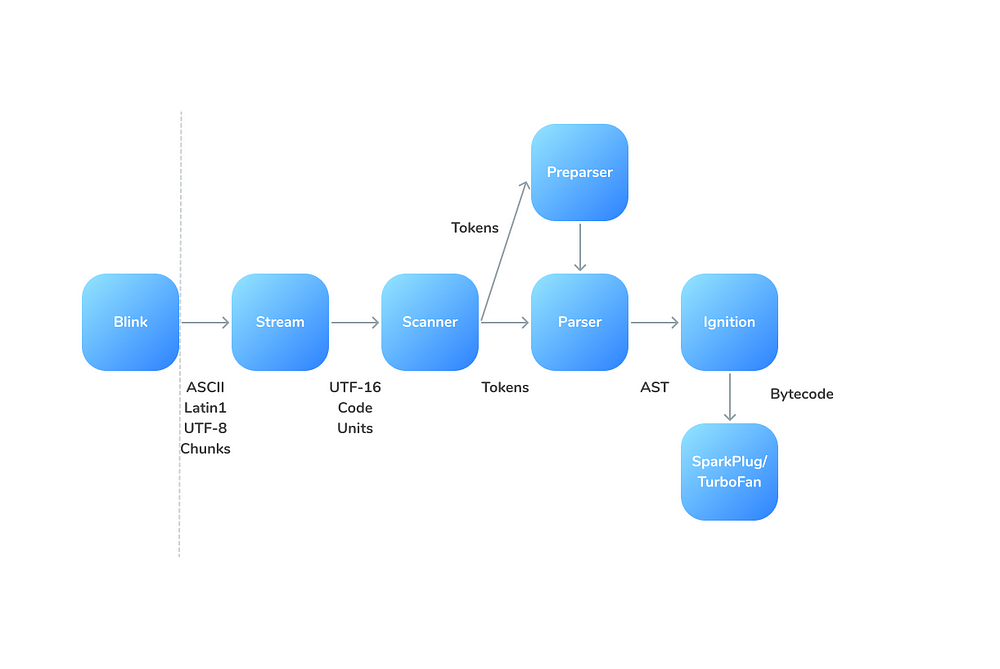
Парсер V8 использует токены, предоставляемые сканером. Токены — это блоки из одного или нескольких символов, которые имеют одно семантическое значение: строка, идентификатор, оператор типа ++. Сканер формирует эти токены путем объединения последовательных символов в базовом потоке символов.
Сканер потребляет поток символов Unicode. Эти символы всегда декодируются из потока символов кода UTF-16. Поддерживается только одна кодировка, чтобы избежать работы различных версий парсера и сканера с несколькими кодировками.
Как говорится в блоге V8 в статье “Удивительно быстрый парсинг. Часть 1: оптимизация сканера”:
Токены могут быть разделены различными типами пробельных символов, например новой строкой, пробелом, табуляцией, однострочными комментариями, многострочными комментариями и т. д. За одним типом пробельных символов могут следовать другие типы. Пробел придает смысл, если он вызывает разрыв строки между двумя токенами: это может привести к автоматической вставке точки с запятой.
Сканер V8 эффективно работает с пробелами и добавляет точки с запятой. Но не забывайте минимизировать выходной код и всегда добавляйте точки с запятой, если это необходимо!
Самым сложным, но и наиболее распространенным токеном является токен идентификатора, который используется для имен переменных в JavaScript.
Чаще всего исходный код JavaScript написан с использованием ASCII. Только a-z, A-Z, $ и _ являются символами ID_Start. ID_Continue дополнительно включает 0-9. Это означает, что имя переменной JavaScript начинается с a-z, A-Z, $ и _, а далее может включать символы 0-9.
const someVariable1 = 'example1';
const some_variable$ = 'example2';
Использование более коротких идентификаторов благоприятно сказывается на производительности парсинга приложения: сканер может сканировать больше токенов в секунду. Но есть одно “но”.
Поскольку код JavaScript часто минимизируется, V8 использует простую таблицу преобразования символьных строк ASCII. Следовательно, V8 создан для минимизированного кода! Вы можете оставлять длинные имена переменных, но не забывайте минимизировать код.
Краткое заключение
Самый простой способ повысить производительность этапа сканирования — минимизировать исходный код, убрать ненужные пробелы и по возможности избегать идентификаторов, не относящихся к ASCII. В идеале эти шаги должны быть автоматизированы как часть процесса сборки.
Парсинг в V8
Парсинг — это этап, на котором исходный код преобразуется в промежуточное представление для использования компилятором (в V8 — компилятором байт-кода Ignition).
Парсинг и компиляция происходят на критическом пути запуска веб-страницы, и не все функции, передаваемые браузеру, понадобятся сразу во время запуска. Хотя разработчики могут отложить такой код с помощью асинхронных и отложенных скриптов, это не всегда возможно.
Кроме того, многие веб-страницы содержат код, который используется только определенными функциями, к которым пользователь может вообще не обращаться во время каждого отдельного запуска страницы.
Поэтому лучше обеспечить отсрочку или загрузку по требованию JS-модулей, которые не нужны для запуска приложения. Не стоит забывать и о встряске дерева вызовов функций кода. Она нужна для лучшего времени взаимодействия и для лучшего выполнения отложенного парсинга.
Нежелательная компиляция исходного кода за один раз может оказаться слишком дорогой.
- Доступность кода, необходимого для запуска приложения, будет отложена.
- Это занимает память, по крайней мере до тех пор, пока функция сброса байт-кода не решит, что код не нужен, и не позволит ему быть собранным в “мусор”.
- Это займет место на диске для кэширования кода.
В целях оптимизации современные JS-движки выполняют ленивый парсинг.
В движке V8 есть Pre-parser — копия парсера, которая выполняет необходимый минимум, чтобы в противном случае можно было пропустить функцию.
Pre-Parser проверяет соответствие синтаксиса грамматике JavaScript, попутно собирая определенную информацию о программе. Проверка грамматики выполняется только для понимания программы, чтобы извлечь из нее ту информацию, которая может быть использована для ускорения последующего парсинга.
Оптимизация IIFE
IIFE (Immediately Invoked Function Expression, немедленно вызванная функция-выражение) — это функция JavaScript, которая запускается сразу же после ее определения.
(function () {
let firstVariable;
let secondVariable;
})();
Упаковщики кода оборачивают модули в IIFE. Опасность IIFE в том, что эти функции требуются на самой ранней стадии выполнения скрипта, поэтому подготовка таких функций — не идеальное решение.
В V8 есть два простых паттерна, которые он распознает как возможно вызванные функции-выражения (PIFE), после чего немедленно парсит и компилирует функцию.
- Если функция является функцией-выражением, заключенным в круглые скобки, т. е.
(function(){…}), V8 предполагает, что она будет вызвана. Он делает это предположение, как только видит начало этого шаблона, т.е.(function. - V8 также обнаруживает паттерн
!function(){…}(),function(){…}(),function(){…}(), генерируемый UglifyJS.
Поскольку V8 нетерпеливо компилирует PIFE, их можно использовать в качестве профильно-направленной обратной связи, сообщая браузеру, какие функции необходимы для запуска.
Профильно-направленная обратная связь, также известная как профильная оптимизация, — это широко используемая техника оптимизации компилятора, которая использует профилирование для повышения производительности.
Обычно она начинается со статического анализа программы (без выполнения исходного кода в противоположность динамическому анализу).
Анализ может даже выполнять разворачивание цикла — преобразование цикла, которое выполняется для увеличения скорости программы. Это делается за счет сокращения или исключения инструкций, управляющих циклом, таких как арифметика указателей и тесты “конца цикла” на каждой итерации, уменьшения штрафов за ветвления, а также скрытия задержек, включая задержку при чтении данных из памяти.
Современные профильные оптимизаторы могут использовать как статический, так и динамический анализ кода и перекомпилировать части кода динамически.
Пример парсинга кода
Рассмотрим простой фрагмент кода.
const array = [1, 2, 3, 4];
array.reduce((previousValue, currentValue) => previousValue + currentValue);
А вот результат — AST:
[generating bytecode for function: ]
--- AST ---
FUNC at 0
. KIND 0
. LITERAL ID 0
. SUSPEND COUNT 0
. NAME ""
. INFERRED NAME ""
. DECLS
. . VARIABLE (0x12385e690) (mode = CONST, assigned = false) "array"
. BLOCK NOCOMPLETIONS at -1
. . EXPRESSION STATEMENT at 14
. . . INIT at 14
. . . . VAR PROXY context[2] (0x12385e690) (mode = CONST, assigned = false) "array"
. . . . ARRAY LITERAL at 14
. . . . . VALUES at 14
. . . . . . LITERAL 1
. . . . . . LITERAL 2
. . . . . . LITERAL 3
. . . . . . LITERAL 4
. EXPRESSION STATEMENT at 29
. . ASSIGN at -1
. . . VAR PROXY local[0] (0x12385ecb0) (mode = TEMPORARY, assigned = true) ".result"
. . . CALL
. . . . PROPERTY at 35
. . . . . VAR PROXY context[2] (0x12385e690) (mode = CONST, assigned = false) "array"
. . . . . NAME reduce
. . . . FUNC LITERAL at 42
. . . . . LITERAL ID 1
. . . . . NAME
. . . . . INFERRED NAME
. RETURN at -1
. . VAR PROXY local[0] (0x12385ecb0) (mode = TEMPORARY, assigned = true) ".result"
[generating bytecode for function: ]
--- AST ---
FUNC at 42
. KIND 11
. LITERAL ID 1
. SUSPEND COUNT 0
. NAME ""
. PARAMS
. . VAR (0x12385e858) (mode = VAR, assigned = false) "previousValue"
. . VAR (0x12385e908) (mode = VAR, assigned = false) "currentValue"
. DECLS
. . VARIABLE (0x12385e858) (mode = VAR, assigned = false) "previousValue"
. . VARIABLE (0x12385e908) (mode = VAR, assigned = false) "currentValue"
. RETURN at 89
. . ADD at 89
. . . VAR PROXY parameter[0] (0x12385e858) (mode = VAR, assigned = false) "previousValue"
. . . VAR PROXY parameter[1] (0x12385e908) (mode = VAR, assigned = false) "currentValue"
Довольно длинный результат! Здесь используется локальная сборка V8 с D8, оболочкой разработчика V8:
d8 — print-ast reduce.js > reduce-ast.txt
Парсинг обычно занимает до 15–20% всего времени компиляции. А неминимизированное AST намного больше, чем минимизированный код. Не пытайтесь минимизировать код вручную — используйте минификаторы, например UglifyJS.
Chrome может хранить скомпилированный код локально, чтобы сократить время компиляции при следующем запуске приложения.
Более подробное описание парсера SpiderMonkey
Да, в SpiderMonkey тоже есть отложенный (или синтаксический) парсинг. Парсер создает AST, используемое BytecodeEmitter. Результирующий формат использует Script Stencils. Ключевые структуры, создаваемые при парсинге, являются экземплярами ScriptStencil.
Затем Stencil может быть инстанцирован в серию ячеек сборщика мусора (Garbage Collector Cells), которые могут быть изменены и распознаны движками выполнения.
Stencils (трафареты) — это набор структур данных, фиксирующих результат парсинга и эмиссии байт-кода. Формат Stencil является исходным форматом, который используется для выделения из кучи GC соответствующих скриптов и их выполнения. Благодаря отделению от GC и других систем выполнения, можно построить надежные системы кэширования и прогнозирования, более гибкие и не зависящие от потоков.
Когда отложено скомпилированная внутренняя функция выполняется впервые, движок перекомпилирует только эту функцию в процессе, называемом делазификацией. Отложенный парсинг позволяет избежать выделения AST и байт-кода, что экономит как процессорное время, так и память. На практике многие функции никогда не выполняются во время загрузки веб-страницы, поэтому такой отложенный парсинг может быть весьма полезен.
Лексер и парсер JSC
Конечно, в JSC есть и лексический анализатор, и парсер.
Лексер выполняет лексический анализ, т. е. разбивает исходный текст скрипта на ряд токенов. Основные файлы: parser/Lexer.h и parser/Lexer.cpp.
Парсер выполняет синтаксический анализ, т.е. получает токены от лексического анализатора и строит соответствующее синтаксическое дерево. В JSC используется ручной парсер с рекурсивным спуском, код находится в parser/JSParser.h и parser/JSParser.cpp.
Следующий этап — низкоуровневый интерпретатор LLInt. Он может работать с кодом из парсера с нулевым временем запуска.
Заключение
Мы рассмотрели этап парсинга в процессе компиляции и то, как он выполняется в различных движках JavaScript.
Чтобы облегчить жизнь парсеру, необходимо выполнить следующие шаги.
- Отложите загрузку модулей кода, которые вам не нужны, до запуска приложения.
- Проверьте
node_modulesи удалите все ненужные зависимости. - Используйте Devtools для поиска сдерживающих факторов.
- Минимизируйте код.
- Меньше транспилируйте.
Важно понимать, что делает Babel и TSC (компилятор TypeScript), и избегать слишком частой проверки на значение null и синтаксического сахара. Это может привести к созданию дополнительного кода. Время от времени проверяйте сгенерированный код. И используйте самую новую целевую платформу для компиляции.
Даже при оптимизации IIFE следует избегать ненужного обертывания функций в круглые скобки. Это приводит к тому, что больше кода компилируется в нетерпении, ухудшая производительность при запуске и увеличивая использование памяти.
Читайте также:
- Связь между микро-фронтендами
- Основы разработки приложений: уровень клиента
- Рендеринг на стороне сервера против статической генерации сайта
Читайте нас в Telegram, VK и Дзен
Перевод статьи Yan Hulyi: JavaScript Engines, Parsing | Yan Hulyi | Medium





