
Изучив справочник API Sklearn, я понял, что наиболее часто используемые модели и функции — это лишь малая часть того, что может делать библиотека. Конечно, встречаются чрезвычайно узконаправленные функции, которые используются в редких случаях. Но все же мне удалось обнаружить множество оценщиков, преобразователей и полезных фич, которые являются более элегантными эквивалентами обычных операций, выполняемых человеком вручную.
Поэтому я решил составить список самых важных из них и кратко рассказать об их особенностях, чтобы вы смогли значительно расширить свой набор инструментов Sklearn. Поехали!
1️⃣. covariance.EllipticEnvelope
Распределения часто имеют выбросы. Многие алгоритмы работают с выбросами, и EllipticalEnvelope— это пример такого алгоритма, который непосредственно встроен в Sklearn. Его преимущество в том, что он отлично справляется с обнаружением выбросов в нормально распределенных (Гауссовых) функциях:
import numpy as np
from sklearn.covariance import EllipticEnvelope
# Создание образца нормального распределения
X = np.random.normal(loc=5, scale=2, size=50).reshape(-1, 1)
# Подгонка оценщика
ee = EllipticEnvelope(random_state=0)
_ = ee.fit(X)
# Тест
test = np.array([6, 8, 20, 4, 5, 6, 10, 13]).reshape(-1, 1)
# predict возвращает 1 для не-выброса и -1 для выброса.
>>> ee.predict(test)
array([ 1, 1, -1, 1, 1, 1, -1, -1])
Для тестирования оценщика мы создаем нормальное распределение со средним значением 5 и стандартным отклонением 2. После его обучения мы передадим несколько случайных чисел его методу predict. Метод вернет -1 для выбросов в test, а это 20, 10, 13.
2️⃣. feature_selection.RFECV
Выбор признаков, которые больше всего помогают в прогнозировании, является обязательным шагом для борьбы с чрезмерным обучением и снижения сложности модели. Одним из наиболее надежных алгоритмов, предлагаемых Sklearn, является рекурсивное удаление признаков (RFE). Он автоматически находит наиболее важные признаки с помощью перекрестной валидации и отбрасывает остальные.
Преимущество этого оценщика в том, что он является оберткой — его можно использовать вокруг любого алгоритма Sklearn, который возвращает оценки важности признаков или коэффициентов. Вот пример на синтетическом наборе данных:
from sklearn.datasets import make_regression
from sklearn.feature_selection import RFECV
from sklearn.linear_model import Ridge
# Создание синтетического набора данных
X, y = make_regression(n_samples=10000, n_features=15, n_informative=10)
# Инициализация/настройка селектора
rfecv = RFECV(estimator=Ridge(), cv=5)
_ = rfecv.fit(X, y)
# Преобразование массива признаков
>>> rfecv.transform(X).shape
(10000, 10)
Фейковый набор данных содержит 15 признаков, 10 из которых являются информативными, а остальные — избыточными. Мы применяем 5-кратный RFECV с Ridge-регрессией в качестве оценщика. После обучения можно использовать метод transform, чтобы отбросить избыточные признаки. Вызов .shapeпоказывает нам, что оценщику удалось отбросить все 5 ненужных признаков.
3️⃣. ensemble.ExtraTrees
Несмотря на всю силу алгоритма случайного леса, риск чрезмерного обучения в случае его использования очень высок. Поэтому Sklearn предлагает альтернативу под названием ExtraTrees (как классификатор, так и регрессор).
Приставка “Extra” означает не больше деревьев, а больше случайности. Алгоритм использует другой тип деревьев, который очень похож на деревья решений. Единственное отличие заключается в том, что вместо вычисления порогов разделения при построении каждого дерева, эти пороги берутся случайным образом для каждого признака, и лучший порог выбирается в качестве правила разделения. Это позволяет немного уменьшить дисперсию ценой небольшого увеличения погрешности:
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressor
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
X, y = make_regression(n_samples=10000, n_features=20)
# Деревья решений
clf = DecisionTreeRegressor(max_depth=None, min_samples_split=2, random_state=0)
scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.6376080094392635
# Случайный лес
clf = RandomForestRegressor(
n_estimators=10, max_depth=None, min_samples_split=2, random_state=0
)
scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.8446103607404536
# ExtraTrees
clf = ExtraTreesRegressor(
n_estimators=10, max_depth=None, min_samples_split=2, random_state=0
)
scores = cross_val_score(clf, X, y, cv=5)
>>> scores.mean()
0.8737373931608834
Как видите, ExtraTreesRegressor показал лучшие результаты, чем алгоритм случайного леса, на синтетическом наборе данных.
Подробнее о сверхслучайных деревьях (Extremely Randomized Trees) читайте в официальном руководстве пользователя.
4️⃣. impute.IterativeImputer и KNNImputer
Если вы ищете более надежные и продвинутые методы импутации, чем SimpleImputer, Sklearn поможет вам. Подпакет imputeвключает два алгоритма импутации на основе моделей — KNNImputerи IterativeImputer.
Как следует из названия, KNNImputerиспользует алгоритм k-Nearest-Neighbors для поиска наилучшей замены отсутствующих значений:
from sklearn.impute import KNNImputer
# Код взят из руководства пользователя Sklearn
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
>>> imputer.fit_transform(X)
array([[1. , 2. , 4. ],
[3. , 4. , 3. ],
[5.5, 6. , 5. ],
[8. , 8. , 7. ]])
Более надежным алгоритмом является IterativeImputer. Он находит недостающие значения путем моделирования каждого признака с недостающими значениями в виде функции других значений.
Этот процесс выполняется пошагово подобно алгоритму round-robin. На каждом шаге один признак с отсутствующими значениями выбирается в качестве цели (y), а остальные — в качестве массива признаков (X). Затем используется регрессор для прогнозирования отсутствующих значений в y, и этот процесс продолжается для каждого признака до количества max_iter(параметр IterativeImputer).
В результате для одного отсутствующего значения генерируется несколько прогнозов. Преимущество такого подхода заключается в том, что каждое отсутствующее значение рассматривается как случайная переменная и ассоциируется с присущей ей неопределенностью:
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.linear_model import BayesianRidge
imp_mean = IterativeImputer(estimator=BayesianRidge())
imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]])
X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]]
>>> imp_mean.transform(X)
array([[ 6.95847623, 2. , 3. ],
[ 4. , 2.6000004 , 6. ],
[10. , 4.99999933, 9. ]])
BayesianRidge и ExtraTree работают лучше с IterativeImputer.
5️⃣. linear_model.HuberRegressor
Наличие выбросов может сильно испортить прогнозы любой модели. Многие алгоритмы обнаружения выбросов отсеивают выбросы и помечают их как отсутствующие. Это помогает функции обучения модели, но полностью устраняет влияние выбросов на распределение.
Альтернативным алгоритмом является HuberRegressor. Вместо того чтобы полностью удалять выбросы, он придает им меньший вес во время подгонки. Он снабжен гиперпараметром epsilon, контролирующим количество образцов, которые должны быть классифицированы как выбросы. Чем меньше этот параметр, тем более он устойчив к выбросам. Его API такой же, как и у других линейных регрессоров. Ниже показано его сравнение с регрессором Bayesian Ridge на наборе данных с сильными выбросами:
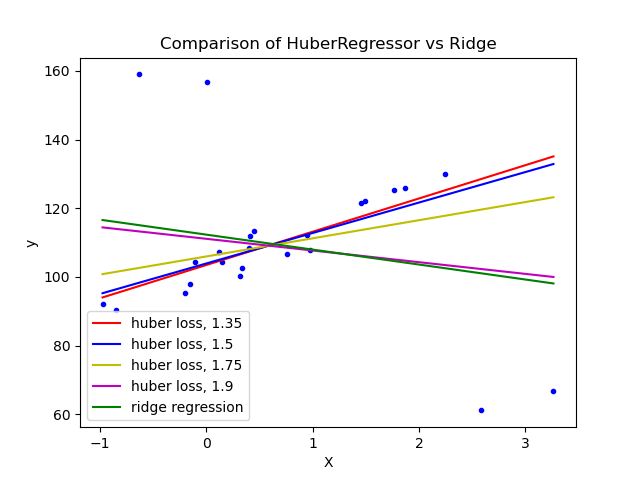
Как видим, алгоритму HuberRegressor с параметрами epsilon 1.35 1.5, 1.75 удалось захватить линию наилучшего соответствия, на которую не влияют выбросы.
Подробнее об этом алгоритме можно узнать из руководства пользователя.
6️⃣. tree.plot_tree
Sklearn позволяет построить график структуры одного дерева решений с помощью функции plot_tree. Эта функция удобна для новичков, которые только начали изучать модели на основе деревьев и ансамбли моделей:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
iris = load_iris()
X, y = iris.data, iris.target
clf = DecisionTreeClassifier()
clf = clf.fit(X, y)
plt.figure(figsize=(15, 10), dpi=200)
plot_tree(clf, feature_names=iris.feature_names,
class_names=iris.target_names);
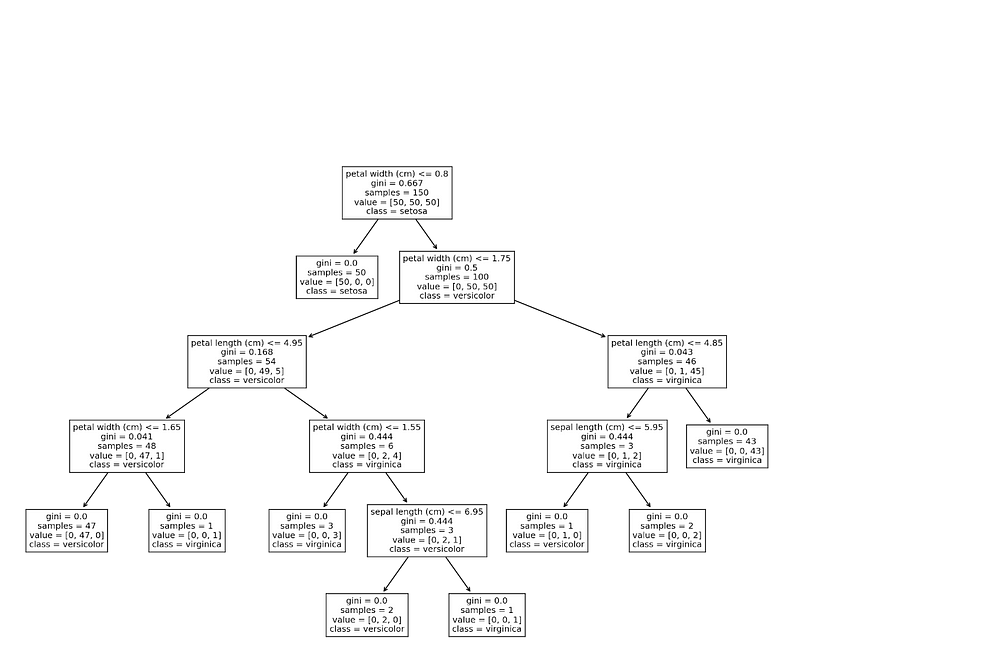
Есть и другие методы построения графиков деревьев, например, в формате Graphviz. Узнайте о них из руководства пользователя.
7️⃣. linear_model.Perceptron
Самое крутое название в этом списке достается №7 — Perceptron. Тем не менее, это простой линейный бинарный классификатор. Определяющей особенностью алгоритма является то, что он подходит для крупномасштабного обучения, а также обладает обладает следующими свойствами по умолчанию:
- не требует скорости обучения;
- не применяет регуляризацию;
- обновляет модель только при ошибках.
Он эквивалентен SGDClassifier с loss='perceptron', eta0=1, learning_rate="constant", penalty=None, но работает немного быстрее:
from sklearn.datasets import make_classification
from sklearn.linear_model import Perceptron
# Создание большого набора данных
X, y = make_classification(n_samples=100000, n_features=20, n_classes=2)
# Инициализация/Подгонка/Оценка
clf = Perceptron()
_ = clf.fit(X, y)
>>> clf.score(X, y)
0.91928
8️⃣. feature_selection.SelectFromModel
Еще одним оценщиком отбора признаков на основе модели в Sklearn является SelectFromModel. Он не так надежен, как и RFECV, но может быть хорошим вариантом для массивных наборов данных, поскольку требует более низких вычислительных затрат. Он также является оценщиком-оберткой и работает с любой моделью, имеющей атрибуты .feature_importances_ или.coef_:
from sklearn.feature_selection import SelectFromModel
# Создание набора данных с 40 неинформативными признаками
X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=10)
# Инициализация селектора и преобразование массива признаков
selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y)
>>> selector.transform(X).shape
(10000, 8)
Как видите, алгоритму удалось отбросить все 40 избыточных признаков.
9️⃣. metrics.ConfusionMatrixDisplay
Матрицы неточностей — это святой Грааль, когда речь заходит о задачах классификации. Большинство метрик, таких как precision, recall, F1, ROC AUC и т.д., являются производными от них. Sklearn позволяет вычислить и построить матрицу неточностей по умолчанию:
from sklearn.metrics import plot_confusion_matrix
from sklearn.model_selection import train_test_split
# Постановка задачи бинарной классификации
X, y = make_classification(n_samples=200, n_features=5, n_classes=2)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=1121218
)
clf = ExtraTreeClassifier().fit(X_train, y_train)
fig, ax = plt.subplots(figsize=(5, 4), dpi=100)
plot_confusion_matrix(clf, X_test, y_test, ax=ax);
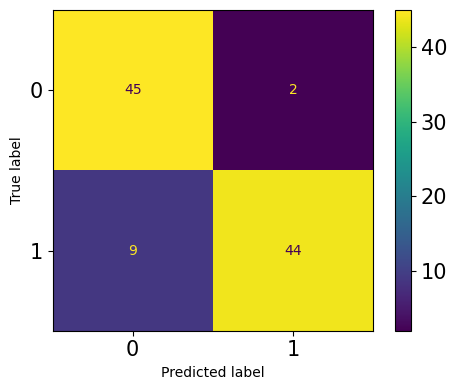
Честно говоря, я бы не сказал, что мне нравится матрица неточностей, построенная по умолчанию. Ее формат фиксирован — строки являются истинными метками, а столбцы — прогнозами. Кроме того, первая строка и столбец — это отрицательный класс, а вторая строка и столбец — положительный. Некоторые могут предпочесть матрицу в другом формате, возможно, транспонированную или перевернутую.
Например, мне больше нравится переносить положительный класс в первую строку и первый столбец, чтобы модель соответствовала формату, приведенному в Википедии. Это помогает лучше выделить 4 метрики матрицы — TP, FP, TN, FN. К счастью, вы можете построить пользовательскую матрицы с помощью другой функции — ConfusionMatrixDisplay:
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
clf = ExtraTreeClassifier().fit(X_train, y_train)
y_preds = clf.predict(X_test)
fig, ax = plt.subplots(figsize=(5, 4), dpi=100)
cm = confusion_matrix(y_test, y_preds)
cmp = ConfusionMatrixDisplay(cm, display_labels=["Positive", "Negative"])
cmp.plot(ax=ax);

Вы можете придать матрице неточностей cmлюбой формат, какой хотите, прежде чем передавать ее в ConfusionMatrixDisplay.
🔟. Обобщенные линейные модели
Нет смысла преобразовывать целевую переменную (y), чтобы сделать ее нормально распределенной, если есть альтернативы, которые могут работать с другими типами распределений.
Sklearn предлагает 3 обобщенные линейные модели для целевых переменных с распределением Пуассона, Твиди или гамма. Вместо того чтобы ожидать нормального распределения, PoissonRegressor, TweedieRegressor иGammaRegressor могут генерировать надежные результаты для целевых переменных с соответствующими распределениями.
Кроме того, их API такие же, как и у любой другой модели Sklearn. Чтобы узнать, соответствует ли распределение целевой переменной трем вышеперечисленным моделям, вы можете построить их PDF (плотность распределения вероятностей) на тех же осях, что и идеальное распределение.
Например, чтобы узнать, соответствует ли целевая переменная распределению Пуассона, постройте ее PDF с помощью kdeplotот Seaborn и расположите идеальное распределение Пуассона путем выборки из Numpy с помощью np.random.poisson на тех же осях.
1️⃣1️⃣. ensemble.IsolationForest
Поскольку модели на основе деревьев и ансамблевые модели обычно дают более надежные результаты, они оказались эффективными и при обнаружении выбросов.
IsolationForestв Sklearn использует лес сверхслучайных деревьев (tree.ExtraTreeRegressor) для обнаружения выбросов. Каждое дерево пытается изолировать каждый отдельный образец, выбирая один признак и случайным образом выбирая значение разделения между максимальным и минимальным значениями выбранного признака.
Такой тип случайного разбиения приводит к заметному сокращению пути между корневым и конечным узлами каждого дерева.
Следовательно, когда лес случайных деревьев в совокупности приводит к более коротким путям для определенных образцов, они с высокой вероятностью являются аномалиями — руководство пользователя Sklearn.
from sklearn.ensemble import IsolationForest
X = np.array([-1.1, 0.3, 0.5, 100]).reshape(-1, 1)
clf = IsolationForest(random_state=0).fit(X)
>>> clf.predict([[0.1], [0], [90]])
array([ 1, 1, -1])
Алгоритм правильно определил выброс (90) и пометил его как -1.
Подробнее об этом алгоритме читайте в руководстве пользователя.
1️⃣2️⃣. preprocessing.PowerTransformer
Многие линейные модели требуют преобразования числовых признаков, чтобы сделать их нормально распределенными. StandardScaler иMinMaxScalerработают довольно хорошо в случае большинства распределений. Однако, когда в данных присутствует большое искажение, основные метрики распределения, такие как среднее значение, медиана, минимальное и максимальное значения, оказываются под угрозой. Поэтому простая нормализация и стандартизация не работают для искаженных распределений.
Вместо них Sklearn реализует PowerTransformer, который использует логарифмическое преобразование для максимально возможного превращения любого искаженного признака в нормальное распределение. Рассмотрим два признака в наборе данных Diamonds:
import seaborn as sns
diamonds = sns.load_dataset("diamonds")
diamonds[["price", "carat"]].hist(figsize=(10, 5));
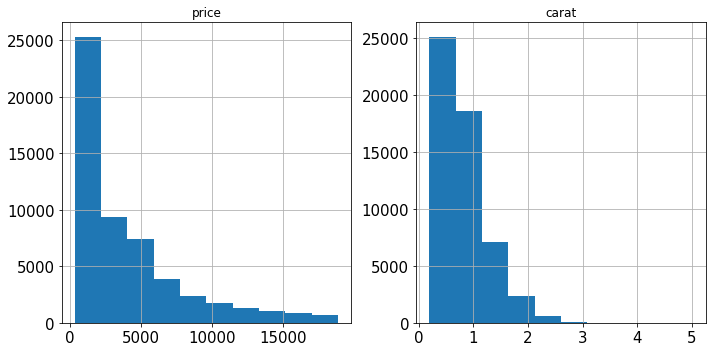
Оба признака сильно искажены. Исправим это с помощью логарифмического преобразования:
from sklearn.preprocessing import PowerTransformer
pt = PowerTransformer()
diamonds.loc[:, ["price", "carat"]] = pt.fit_transform(diamonds[["price", "carat"]])
diamonds[["price", "carat"]].hist(figsize=(10, 5));
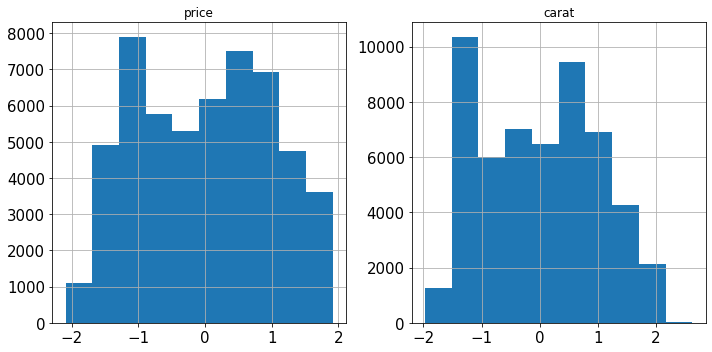
Искажение ушло!
1️⃣3️⃣. preprocessing.RobustScaler
Еще одним числовым преобразователем в Sklearn является RobustScaler. Вы, вероятно, догадались, что он делает, по его названию. Он может преобразовывать признаки способом, устойчивым к выбросам. Если в признаке присутствуют выбросы, трудно сделать их нормально распределенными, поскольку они могут сильно исказить среднее и стандартное отклонение.
Вместо использования среднего/стандартного отклонения RobustScalerмасштабирует данные с помощью медианы и IQR (межквартильного размаха), поскольку обе эти метрики не искажаются из-за выбросов. Вы также можете прочитать об этом в руководстве пользователя.
1️⃣4️⃣. compose.make_column_transformer
В Sklearn предусмотрен сокращенный способ создания экземпляров Pipeline с помощью функции make_pipeline. Вместо того чтобы называть каждый шаг и делать код излишне длинным, функция просто принимает преобразователи и оценщики и делает свою работу:
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
pipeline = make_pipeline(SimpleImputer(), StandardScaler(), ExtraTreesRegressor())
>>> pipeline
Pipeline(steps=[('simpleimputer', SimpleImputer()),
('standardscaler', StandardScaler()),
('extratreesregressor', ExtraTreesRegressor())])
Для более сложных сценариев используется ColumnTransformer, которому присуща та же проблема — называние каждого шага предварительной обработки, что делает код длинным и нечитабельным. К счастью, Sklearn предлагает функцию, аналогичную make_pipeline:
import seaborn as sns
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import OneHotEncoder
# Загрузка датасета diamonds
diamonds = sns.load_dataset("diamonds")
X, y = diamonds.drop("price", axis=1), diamonds.price.values.reshape(-1, 1)
# Выделение числовых и категориальных столбцов
num_cols = X.select_dtypes(include=np.number).columns
cat_cols = X.select_dtypes(exclude=np.number).columns
>>> make_column_transformer((StandardScaler(), num_cols),
(OneHotEncoder(), cat_cols))
ColumnTransformer(
transformers=[('standardscaler', StandardScaler(),
Index(['carat', 'depth', 'table', 'x', 'y', 'z'], dtype='object')),
('onehotencoder', OneHotEncoder(),
Index(['cut', 'color', 'clarity'], dtype='object'))]
)
Как видите, использование make_column_transformer— это более короткий путь; функция сама позаботится об именовании каждого шага преобразования.
1️⃣5️⃣. compose.make_column_selector
Если вы обратили внимание, мы использовали функцию select_dtypesвместе с атрибутом columnsв pandas DataFrames для выделения числовых и категориальных столбцов. Конечно, это работает, но есть гораздо более гибкое и элегантное решение, предлагаемое Sklearn.
Функция make_column_selectorсоздает селектор столбцов, который можно передавать непосредственно в экземпляры ColumnTransformer. Она работает так же, как select_dtypesи даже лучше. Эта функция имеет параметры dtype_include иdtype_exclude для выбора столбцов на основе типа данных. Если вам нужен пользовательский фильтр столбцов, вы можете передать регулярное выражение в pattern, а остальные параметры установить в None. Вот как это работает:
from sklearn.compose import make_column_selector
make_column_transformer(
(StandardScaler(), make_column_selector(dtype_include=np.number)),
(OneHotEncoder(), make_column_selector(dtype_exclude=np.number)),
)
Вместо того чтобы передавать список имен столбцов, вы просто передаете экземпляр make_column_selector с соответствующими параметрами, и все готово!
1️⃣6️⃣. preprocessing.OrdinalEncoder
Распространенной ошибкой среди новичков является использование LabelEncoderдля кодирования порядковых категориальных признаков. Если вы заметили, LabelEncoder позволяет преобразовывать столбцы только по одному за раз, а не одновременно, как OneHotEncoder. Вы можете подумать, что Sklearn допустила ошибку!
На самом деле LabelEncoderследует использовать только для кодирования переменной отклика (y), как указано в документации. Для кодирования массива признаков (X) следует использовать OrdinalEncoder, который работает ожидаемым образом. Он преобразует порядковые категориальные столбцы в признаки с классами (0, n_категорий — 1). Энкодер проделывает то же самое со всеми указанными столбцами в одной строке кода, что разрешает включение в конвейеры.
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder()
X = [
["class_1", "rank_1"],
["class_1", "rank_3"],
["class_3", "rank_3"],
["class_2", "rank_2"],
]
>>> oe.fit_transform(X)
array([[0., 0.],
[0., 2.],
[2., 2.],
[1., 1.]])
1️⃣7️⃣. metrics.get_scorer
В Sklearn встроено более 50 метрик. Их текстовые названия можно посмотреть в sklearn.metrics.SCORERS.keys. В одном проекте вы можете использовать несколько метрик и импортировать их, если задействуете их по отдельности.
Импорт большого количества метрик из sklearn.metricsнапрямую чреват риском загрязнения вашего пространства имен и неоправданного удлинения кода. В качестве решения можете использовать функцию metrics.get_scorerдля доступа к любой метрике с ее текстовым именем без необходимости ее импорта:
from sklearn.metrics import get_scorer
>>> get_scorer("neg_mean_squared_error")
make_scorer(mean_squared_error, greater_is_better=False)
>>> get_scorer("recall_macro")
make_scorer(recall_score, pos_label=None, average=macro)
>>> get_scorer("neg_log_loss")
make_scorer(log_loss, greater_is_better=False, needs_proba=True)
1️⃣8️⃣. model_selection.HalvingGrid и HalvingRandomSearchCV
В версии 0.24 Sklearn есть два экспериментальных оптимизатора гиперпараметров: классы HalvingGridSearchCV иHalvingRandomSearchCV.
В отличие от своих комплексных родственников GridSearch и RandomizedSearch, новые классы используют технику под названием Successive Halving. Вместо того чтобы обучать все наборы претендентов на всех данных, параметры задаются только на подмножестве данных. Худшие кандидаты отфильтровываются путем их обучения на меньшем подмножестве данных. После каждой итерации число обучающих образцов увеличивается на некоторый коэффициент, а количество возможных претендентов уменьшается на столько же, что приводит к значительному ускорению времени оценки.
Насколько быстрее происходит процесс оценки? По результатам проведенных экспериментов HalvingGridSearch оказался в 11 раз быстрее обычного GridSearch, а HalvingRandomSearch работал в 10 раз быстрее HalvingGridSearch.
1️⃣9️⃣. sklearn.utils
И последняя функция, но не менее важная. Sklearn имеет целый ряд полезных и вспомогательных функций в подпакете sklearn.utils. Sklearn задействует функции этого модуля для построения всех используемых нами преобразователей и оценщиков.
Среди них много полезных фич, таких как class_weight.compute_class_weight, estimator_html_repr, shuffle, check_X_y и др. Вы можете использовать их в своем собственном рабочем процессе, чтобы придать коду большую схожесть со Sklearn. Они также могут пригодиться при создании пользовательских преобразователей и оценщиков, которые подходят для Sklearn API.
Резюме
Несмотря на то, что такие библиотеки, как CatBoost, XGBoost, LightGBM, постепенно отвоевывают у Sklearn звание ведущей МО-библиотеки, работа с ней по-прежнему остается бесценной частью набора навыков современного MО-инженера.
Понятный и предсказуемый API, исключительный дизайн кода и возможность создания надежных рабочих МО-процессов по-прежнему делают библиотеку Sklearn непревзойденной в плане функциональности и гибкости. С помощью базовых знаний можно решать многие задачи, но из этой статьи вы узнали, что Sklearn скрывает в себе гораздо больше фич, чем кажется на первый взгляд!
Читайте также:
- Библиотеки Python для машинного обучения
- Выборки. Джентльменский набор
- Руководство к использованию деревьев решений в машинном обучении и науке о данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Bex T., 19 Hidden Sklearn Features You Were Supposed to Learn The Hard Way





