
Классификация — это тип контролируемой задачи машинного обучения. Цель классификации — предсказание признаков одного или нескольких наблюдаемых объектов или класса, к которому они принадлежат.
Важным элементом любого рабочего процесса машинного обучения является оценка эффективности модели. Это процесс, при котором обученную модель используют для прогнозирования на материале ранее не отображенных, помеченных данных. При классификации оценивают количество правильных прогнозов, сделанных моделью.
В реальных задачах классификации обычно невозможно достичь 100% верных прогнозов, поэтому при оценке модели полезно знать не только то, насколько она была неверна, но в чем.
К примеру, вам нужно спрогнозировать, является ли опухоль доброкачественной или раковой. Вы скорее согласитесь с тем, чтобы модель в небольшом количестве случаев неверно предсказывала злокачественную опухоль, чем иметь серьезные последствия пропуска диагноза рака.
С другой стороны, если бы вы были розничным продавцом, пытающимся выявить мошеннические транзакции, то предпочли бы пропустить небольшое количество нечестных транзакций, нежели рисковать отказать порядочным клиентам.
В обоих случаях нужно оптимизировать модель, чтобы она выдавала более верные результаты. Для этого используется ряд показателей. С их помощью, на основе компромиссных решений, делается окончательный выбор в пользу классификатора, наиболее подходящего для конкретного случая.
Далее приводятся доступные описания 8 показателей эффективности и методов оценки классификатора.
1. Правильность
Общая правильность модели — это количество правильных предсказаний, деленное на общее количество предсказаний. Оценка правильности дает значение от 0 до 1, где 1 — идеальная модель.
Правильность = количество правильных прогнозов / общее количество прогнозов
Этот показатель редко следует использовать отдельно, поскольку на материале несбалансированных данных, где один класс значительно превосходит другой, правильность может быть очень обманчивой.
Вернемся к примеру с раком. Представьте, что у вас есть набор данных, в котором только 1% образцов являются раковыми. Классификатор, который предскажет все результаты как доброкачественные, достигнет 99% правильности. Однако на практике такая модель была бы не просто неполезной, но и опасной, поскольку она никогда не обнаружила бы раковые образцы.
2. Матрица ошибок
Матрица ошибок (неточностей) — чрезвычайно полезный инструмент, позволяющий определить, в чем модель ошибается (или права!). Эта матрица сравнивает количество правильных и неправильных предсказаний для каждого класса.
В матрицу ошибок записывают 4 вида результатов, на которые следует обратить внимание:
- Истинно положительные (ИП/TP): количество положительных наблюдений, которые модель правильно предсказала как положительные.
- Ложноположительные (ЛП/FP): количество отрицательных наблюдений, которые модель неверно предсказала как положительные.
- Истинно отрицательные (ИО/TN): количество отрицательных наблюдений, которые модель правильно предсказала как отрицательные.
- Ложноотрицательные (ЛО/FN): количество положительных наблюдений, которые модель неверно предсказала как отрицательные.
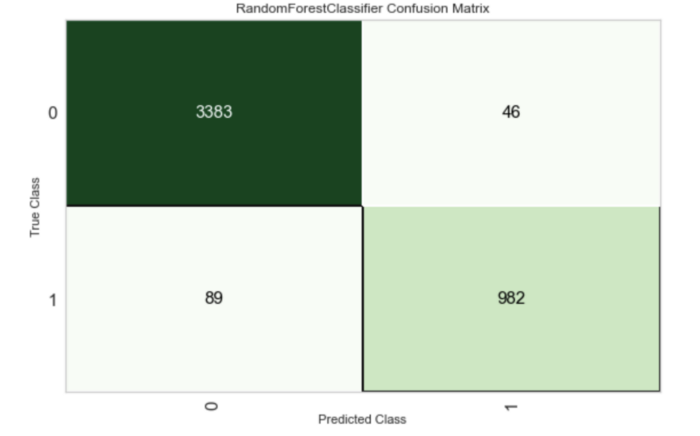
На изображении ниже показана матрица ошибок для классификатора. Используя ее, мы можем понять следующее:
- модель правильно предсказала 3 383 отрицательных образца, но неправильно предсказала 46 как положительные;
- модель правильно предсказала 962 положительных образца, но неправильно предсказала 89 отрицательных;
- выборка данных не сбалансирована, причем отрицательный класс имеет большее количество образцов.
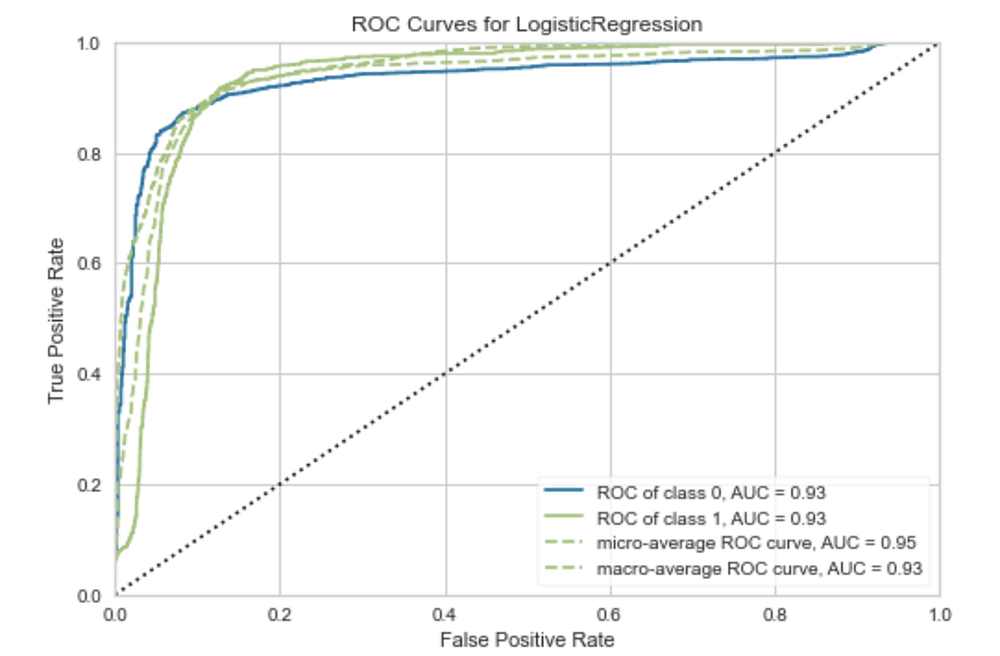
3. AUC/ROC
Классификатор, такой как логистическая регрессия, в качестве результата предсказания выдает вероятность того, что образец принадлежит к определенному классу. Чтобы модель была полезной, это значение обычно преобразуется в двоичное, например: либо образец принадлежит к классу, либо нет. Для этого используется порог классификации. Например, мы можем сказать, что если вероятность выше 0,5, то образец принадлежит к классу 1.
Кривая ROC (Receiver Operating Characteristics — операционные характеристики приемного объекта) — это график эффективности модели (график частоты истинных и ложных положительных результатов) при всех порогах классификации. AUC — это измерение всей двумерной площади под кривой и, следовательно, показатель эффективности модели при всех возможных порогах классификации.
ROC-кривые отображают точность моделей и поэтому лучше всего подходят для диагностики эффективности моделей, в которых данные не являются несбалансированными.
4. Точность
Точность позволяет выяснить, насколько хороша модель в правильном определении положительного класса. Другими словами, точность показывает, сколько из всех предсказаний для положительного класса были верны. При использовании только этой метрики для оптимизации модели минимизируется количество ложных срабатываний. Это может быть желательным в нашем примере обнаружения мошенничества, но менее полезно для диагностики рака, поскольку результаты не дадут полного представления о пропущенных положительных образцах.
Точность = ИП / ИП + ЛП
5. Отклик модели
Эта метрика показывает, насколько хорошо модель правильно предсказывает все положительные образцы в наборе данных. Однако отклик модели не включает информацию о ложных срабатываниях, поэтому она была бы более полезна для диагностики рака.
Отклик модели = ИП / ИП + ЛО
Обычно точность и отклик модели наблюдаются вместе путем построения кривой “точность — отклик”. Это позволяет визуализировать компромисс между двумя метриками при различных пороговых значениях.
6. Оценка F1
Оценка F1 — это среднее гармоническое значение показателей точности и отклика модели. Если оценка F1 равна 1,0, это означает, что точность и отклик модели идеальны. Если оценка F1 равна 0, это означает, что либо точность, либо отклик модели равны 0.
F1 = 2 х точность х отклик модели / точность + отклик модели
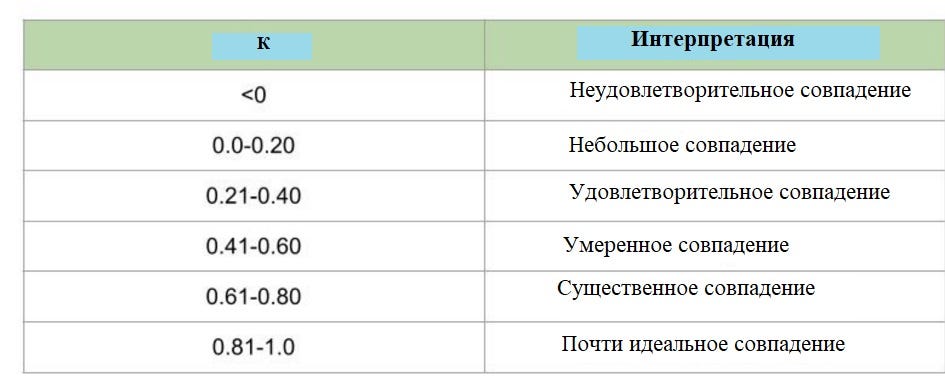
7. Каппа
Каппа-статистика сравнивает наблюдаемую правильность с ожидаемой правильностью или правильностью, ожидаемой от вероятностного случая (нечетко-случайного события). Один из недостатков чистой правильности заключается в том, что если класс не сбалансирован, то предсказания, сделанные наугад, могут дать высокий балл правильности. Каппа учитывает это, сравнивая правильность модели с ожидаемой правильностью, основанной на количестве экземпляров в каждом классе.
По сути, каппа дает представление о том, как работает модель по сравнению с моделью, которая рандомно классифицирует наблюдаемые образцы в соответствии с частотой встречаемости каждого класса.
Каппа = (наблюдаемая правильность — ожидаемая правильность) / (1 — ожидаемая правильность)
Каппа возвращает значение на уровне или ниже 1. Возможны отрицательные значения. Недостатком каппа-статистики является то, что не существует согласованного стандарта для интерпретации ее значений. Хотя общая интерпретация этой метрики была дана Лэндисом и Кохом в 1977 году.
8. ККМ
ККМ (коэффициент корреляции Мэтьюса) обычно считается одним из лучших показателей эффективности модели классификации. Это объясняется в основном тем, что, в отличие от любой из ранее упомянутых метрик, ККМ учитывает все возможные результаты прогнозирования. Если в классах существует дисбаланс, это будет учтено.
ККМ — это, по сути, коэффициент корреляции между наблюдаемой и предсказанной классификациями. Как и любой коэффициент корреляции, его значение лежит в диапазоне от -1,0 до +1,0. Значение +1 указывает на идеальную модель.
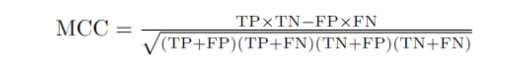
Теперь вы знаете 8 показателей эффективности моделей-классификаторов. На практике редко какой-либо из них используется отдельно. Чаще всего при оптимизации модели специалист по анализу данных оценивает несколько этих показателей и взвешивает компромиссы, которые они выявляют.
Оценка эффективности классификатора — непростая задача. Ее решение сильно зависит от конкретного случая использования и имеющегося набора данных. Чтобы создать действительно полезную модель, очень важно учитывать риск ошибок в той или иной сфере применения.
Читайте также:
- Важные аспекты математики в науке о данных - «что» и «почему»
- Алгоритм машинного обучения t-SNE - отличный инструмент для снижения размерности в Python
- Алгоритмы машинного обучения простым языком.
Читайте нас в Telegram, VK и Дзен
Перевод статьи Rebecca Vickery, 8 Metrics to Measure Classification Performance





