
Не сомневаюсь, что заголовок статьи привлек ваше внимание! А теперь позвольте мне аргументировать свою точку зрения, поскольку процентов на 50%, а то и больше, вы со мной не согласитесь. В программировании есть один момент, в отношении которого мы, несомненно, можем достичь абсолютного единодушия — нам не избежать использования null или исключений. И причин тому несметное множество: что-то пошло не так, обрушились серверы, отсутствуют нужные данные, да вы и сами можете продолжить этот список.
Я не великий Мерлин, и у меня нет заклинания, гарантирующего 100% работу сервера, или волшебной палочки, по мановению которой потерянные данные будут всегда чудесным образом находиться. Но зато в моих силах поделиться с вами подходом, который, на мой взгляд, позволит оптимизировать код, сделать его более удобным в обслуживании и готовым к обработке null или исключений. Честно вам признаюсь, что предлагаемое решение состоит в использовании разработанных мною пакетов NuGet, которые активно применяются и в личных, и рабочих проектах вашего покорного слуги. Правда, этот подход легко воспроизвести, но зачем изобретать колесо?
Null— это зло
Итак, почему же я считаю null злом? Пожалуй, будет лучше, если на этот вопрос ответит сам изобретатель нулевого указателя Энтони Хоар:
“Я называю его (нулевой указатель) ошибкой на миллиард долларов”.
Разве неубедительно?
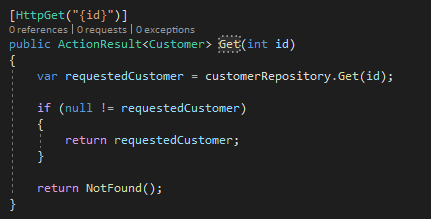
Сколько раз вы писали нечто похожее на вышеуказанный пример? 10 раз? Сто? Несметное количество? И я не исключение! Каждый раз при написании кода вы тратите время, которому можно было бы найти лучшее применение. А так как время — это весьма ценный ресурс, то и тратить его нужно на что-нибудь стоящее. В этом фрагменте кода мы не только проводим проверку на null и возвращаем результат NotFound в случае его обнаружения, но и обманываем клиента. Ладно, может и не обманываем, но мы допускаем, что null означает тот факт, что Customer не найден. В данном фрагменте у нас нет никакой возможности узнать, действительно это так или нет. Все, что нам известно — customerRepository не вернул Customer, а вот определить, произошло ли это в результате ошибки или потому что Customer действительно был не найден, мы уже не сможем.
Конечно, сейчас мы имеем дело с придуманным кодом, поскольку он не выполняет проверку входящего “id”, как того требуют принципы безопасного программирования, и не предполагает обработку ошибок, но я не раз встречал подобные вариации в коде производственной среды.
Вот тут-то мы и переходим к пониманию сути утверждения “Null — это зло”. Если взять вышеприведенный пример, то, во-первых, мы не гарантируем предоставление получателю правдивых данных— представьте, что вы запрашиваете в банке баланс счета, а он возвращает not found (не найден). Во-вторых, данный код находится в контроллере, а что если бы он состоял из двух, трех или более слоев? Сможете ли вы на основе имеющейся информации с уверенностью сказать, найден ли Customer или произошла ошибка?
Итак, что же нам делать с нулевыми указателями и нашей тягой к правде? Постараемся их не возвращать. Вместо них, по возможности, вернем значимый и ожидаемый объект Result, свидетельствующий о том, насколько успешен был вызов.
Звучит просто, не правда ли? Так и есть. В функциональном программировании эта практика существует уже долгое время, и хотя C# не принадлежит к разряду функциональных языков, LINQ не в счет, мы можем позаимствовать принципы таких языков, как F#, Haskell и Python, что выгодно отразится и на коде!
Вернемся к примеру — на этот раз скорректируем действие контроллера.
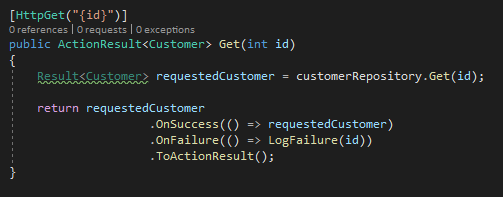
Первое, что вы должны были заметить, так это отсутствие выполняемых проверок. Кроме этого, посмотрите, каким понятным (иначе говоря, чистым) стал код. 3 метода расширения абстрагируют проверки и позволяют нам сосредоточиться на самом важном — на том что, а не как делает код.
Магия начинается с нового объекта Result — обычно я предпочитаю использовать var вместо явного объявления типа, показанного в примере (вследствие чего Visual Studio подчеркивает строку зеленой волнистой линией), но в данном случае это бы скрыло изменение в типе ответаcustomerRepository.Get. Объект Result выполняет 2 главные функции:
- имеет свойство IsSuccess. При этом обратный вариант этого свойства представлен как isFailure, а не !isSuccess, что более удобно для восприятия и грамматически вернее;
- имеет свойство Value, которое будет содержать запрашиваемый объект — только при условии успешных вызовов.
Есть еще и третья функция, о которой мы поговорим в разделе “Исключения — не меньшее зло”.
В вышеуказанном примере я решил использовать 2 метода расширения, OnSuccess и OnFailure, чтобы показать, насколько легко можно внедрить поток, аналогичный конвейеру, известному нам из LINQ (если же вы с ним до сих пор не знакомы, то нужно срочно исправить эту оплошность, так как LINQ позволит вам тратить меньше времени на ввод данных и писать более чистый код).
Метод OnSuccess проверяет результат предыдущего действия и запускает определенную функцию (также присутствует поддержка Action) только при условии успешного предшествующего вызова, поэтому проверка условий все еще осуществляется — просто она абстрагирована от класса и, следовательно, от нашего внимания. Метод OnFailure работает аналогичным образом за одним лишь исключением — он выполняется только в случае неудачного предыдущего вызова.
ToActionResult (из пакетаCapgemini.SerializableResult.AspNetCore NuGet) в этом сценарии можно использовать автономно — в приведенном примере он просто вернет запрашиваемый объект Customer или NotFound, при этом предварительно внутренне проверив свойство StatusCode на наличие ошибки 404 (и многих других). Он также предусматривает возможность записать результат действия в журнал, но OnSuccess и OnFailure могут эффективно использоваться для создания цепочек операций с учетом одного нюанса — оба метода требуют, чтобы в качествевозвращаемого типабыл один и тот же тип объекта или тип void.
Использование нового объекта Result (о том, где его можно найти, вы узнаете в конце статьи) в сочетании с рассмотренными методами расширения позволяет обойтись без проверки на null (технически она абстрагируется от класса и, следовательно, от нашего внимания) и в процессе создает гораздо более чистый метод. Итак, а что же насчет исключений? В нашем примере нет их обработки, можем ли мы по-прежнему их выбрасывать?
Исключения — не меньшее зло
Ранее уже упоминалось, что у объекта Result есть еще одна функция: его контракт не предусматривает генерацию исключений. Слово “контракт” выделено курсивом неслучайно, поскольку, строго говоря, его реализация зависит от вас, и, следовательно, возврат Result вместо исходного объекта не дает гарантии, что исключение не может быть выброшено.
Сколько раз вам приходилось тратить уйму времени на отладку NullReferenceException во фрагменте кода, который вы видите в первый раз или о котором уже давно забыли? Современные отладчики, бесспорно, гораздо лучше могут определить место выброса исключения, но ведь не всегда именно там оно происходит — в этом и заключается главная причина моего убеждения, что null — это зло.
Выполнение контракта, заявленного объектом Result, так же просто, как использование блока try…catch…:
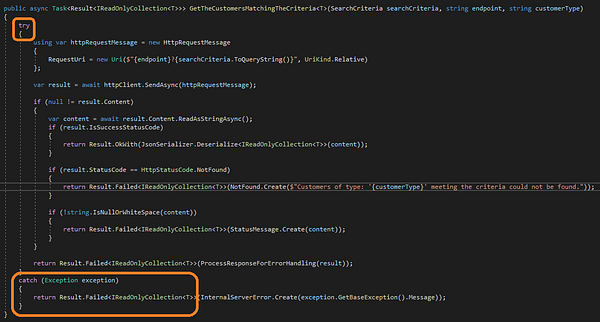
Теперь перед вами на 100% правильный вариант, но подход “поймай все” может не понравиться не только некоторым аналитикам кода, но и многим разработчикам. Хотя в примере этого и нет, но в коде можно было также реализовать повторную попытку на случай тайм-аута во время вызова метода httpClient.SendAsync (или любого другого ожидаемого исключения, т. е. ошибки десериализации) перед catch-all, но для краткости этот пример был сохранен предельно простым. Данный фрагмент кода также иллюстрирует использование NotFound.Create, InternalServerError.Create и StatusMessage.Create — методов из пакета Result NuGet, предназначенных для стандартизации структуры сообщений о результатах.
Самое главное преимущество этого подхода состоит в сжатии клиентского кода:

В данном примере отсутствует необходимость проверки на null и обработки исключений, здесь — только понятный вызов метода, выполняющий сложную задачу.В случае с UI (для веб, мобильных устройств и т. д.), где многим получателям раньше приходилось выполнять проверку на null и обрабатывать исключения, теперь все это можно сократить до одной строки. 🙂
Заключение
Я твердо убежден, что null — это зло. Да и исключения не лучше, а, возможно, даже хуже, поскольку по своей сути они являются еще одной версией оператора GoTo с оговоркой, чтов отличие от последнего, вы не имеете представления, в каком месте кода может закончиться обработка исключения. Осознавая некоторую предвзятость своей точки зрения, я тем не менее твердо убежден, что использование объекта Result поможет очистить код, сосредоточиться на том, что он делает, и оставаться предельно честным перед клиентами.
Пакеты NuGet
В настоящее время эти пакеты доступны на NuGet. В дальнейшем планируется открыть исходный код репозиториев и перейти на полностью поддерживаемую модель, но на момент написания статьи все версии были 0.n.n и должны рассматриваться как бета, несмотря на их использование мной в личных и рабочих проектах.
- Capgemini.SerializableResult
- Capgemini.SerializableResult.AspNetCore
- Capgemini.Logger.ApplicationInsights *
*В то время, как Capgemini.Logger.ApplicationInsights может использоваться независимо,упомянутая в статье запись в журнал (с помощью метода ToActionResult пакетаCapgemini.SerializableResult.AspNetCore) зависит от Capgemini.Logger.ApplicationInsights, поэтому я упомянул его здесь.
Читайте также:
- Новейшие возможности C# 9
- Игра на C# меньше 8 Кб
- 4 golang-сниппета, которые вводят в заблуждение разработчиков C#!
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Jay Barden: Nulls are Evil


")


