
Что такое кэширование?
В вычислительной технике кэш — это высокоскоростной уровень хранения данных, где хранится подмножество данных, обычно временных. Благодаря этому будущие запросы на эти данные обрабатываются быстрее, чем при запросе доступа к основному хранилищу. Кэширование позволяет эффективно переиспользовать ранее полученную или вычисленную информацию.
Системы кэширования хранятся на оборудовании с более быстрым доступом, таким как оперативная память (RAM). Оперативная память обеспечивает более быструю работу ввода-вывода и уменьшает задержку. Кэширование задействовано на всех уровнях технологий, например в операционных системах, CDN, DNS, во многих приложениях, таких как поиск, а также используется для повышения производительности медиаконтента в играх.
При реализации уровня кэша важно понимать, какое значение имеет достоверность кэшированных данных. Успешное кэширование приводит к повышению частоты обращений, а значит, данные присутствуют при запросе к ним. Промах кэша возникает, когда информации в кэше не оказалось. Для управления истечением срока действия данных могут применяться такие элементы управления, как TTL (Time to live).
Требования к функциональности
- Нужно сохранить огромное количество данных — около терабайта.
- Кэш должен выдерживать от 50 до 1 млн запросов в секунду.
- Ожидаемая задержка — около 1 мс.
- LRU (Least Recently Used) — алгоритм, при котором вытесняются значения, которые дольше всего не запрашивались.
- 100% доступность.
- Масштабируемость.
Шаблоны доступа к кэшу
- Кэш сквозной записи. Всякий раз, когда приходит какой-либо запрос на “запись”, он будет поступать в БД через кэш. Запись считается успешной только в том случае, если данные успешно записаны и в кэш, и в БД.
- Кэш прямой записи. Запрос на запись идет напрямую в БД, минуя кэш, и подтверждение отправляется обратно. Данные не уходят в кэш, а записываются туда только при первом промахе кэша.
- Кэш обратной записи. Обновленная запись отправляется в кэш, данные сохраняются в кэше, и подтверждение отправляется немедленно. Затем другой сервис передает данные в БД.
Структура данных для реализации кэша называется “хеш-таблицей”. Все, что нам нужно, — это функция хеширования, ключ и значение.
Работа с хеш-таблицей
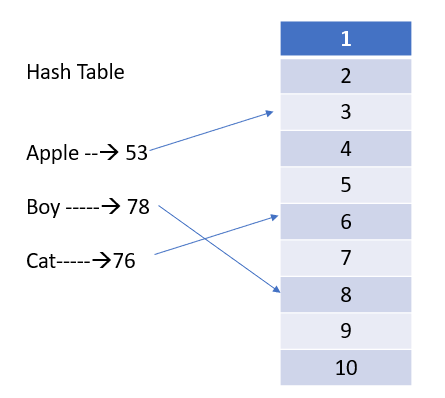
Как показано изображении, у нас есть три набора данных: “яблоко”, “мальчик” и “кот”, которые необходимо сохранить в хеш-таблице. Эти значения задаются в качестве входных параметров для функции хеширования (hashCode()), откуда мы получаем хешированные значения, в данном случае 53, 78 и 76. Затем эти значения делятся на количество ячеек в корзине, т.е. в данном случае на 10, и сохраняются в ячейке, номер которой совпадает со значением остатка: 53 в ячейке №3, 78 в ячейке №8 и так далее.
Допустим, у нас есть еще одни данные “гусеница”, хешированное значение которых равно 66, и они должны сохраниться в ячейке № 6, как и “кот”. Когда два разных ключа выдают одно и то же значение ячейки, происходит коллизия. По очевидной причине нельзя сохранить оба значения в одном и том же месте.
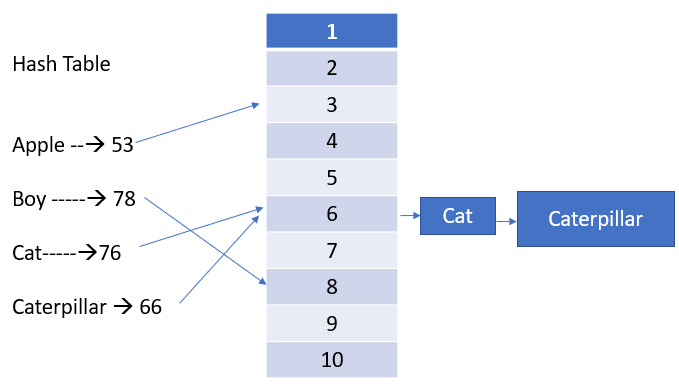
Существует несколько стратегий разрешения коллизий, такие как метод раздельных цепочек, открытая адресация, хеширование Робин Гуда. Простая стратегия — вместо сохранения в ячейке конкретного значения создавать связанный список, где и будут храниться пары ключ-значение. Это называется раздельными цепочками с использованием связанного списка.
Чтобы получить значение, дайте ключ хеш-функции, например “яблоко”, получите хешированное значение, рассчитанное по количеству ячеек, и посмотрите на конкретное положение.
Кэширование в распределенной системе

Как показано на рисунке, все значения оранжевого цвета хранятся в узле 1, а синего — в узле 2. Если по какой-либо причине узел 2 выйдет из строя, эти два положения, т. е. ячейки под номерами 9 и 10, станут недоступны. Хеш-таблица в таком случае остается прежней, но размер корзины теперь равен 8. Теперь для того же примера “яблоко” нужно брать остаток от деления на 8 — 53/8. Вместо 3 получаем 5. В данном случае эта ячейка пуста.
Вместо пустого значения также могут быть сценарии, где образуется неправильное значение. Это неприемлемо — придется делать переназначение, а это довольно утомительная работа. Что, если у нас будет не десять ключей, а десять тысяч? Для решения этой проблемы вместо обычной хеш-таблицы воспользуемся согласованным хешированием, которое также известно как согласованное хеш-кольцо.
Работа с согласованным хеш-кольцом
В обычном сценарии нам известна доступная область памяти, поскольку мы последовательно именуем ключи в хеш-таблице с помощью чисел, например от 1 до 10. Нюанс в том, что здесь ключи назначаются совершенно случайным образом.
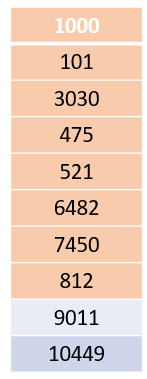
Для значения “яблоко” мы передаем его в функцию хеширования и получаем результат: 2394. Берем этот хеш-номер и сразу находим местоположение — набор ключей, который больше 2394, в данном случае это 3030. Мы сохраняем значение здесь.
Допустим, есть еще один ключ “шарик” со значением 2567 — он также будет храниться в том же месте цепочки. Если мы получили хешированное значение 11000, то, поскольку доступного значения в ячейках нет, мы возвращаемся к началу и сохраняем в 1000. Это что-то вроде закольцовки. Вот как работает согласованное хеш-кольцо.
Политика вытеснения кэша
Как вытеснять кэш и когда нужно это делать?
Вытеснение означает удаление ключа и значения из кэш-памяти. Зачем это делать? Кэш стоит дорого, а некоторые сохраненные значения остаются без дела. Поэтому нужно определить, какие записи не используется и обладает идеальным расположением, а потом удалить их, чтобы освободить место для новых. Это известно как политика вытеснения кэша.
Одна из распространенных стратегий вытеснения — Least Recently Used или LRU. Она предполагает удаление записи, к которой за последнее время обращались реже всего.
Необходимо каким-то образом выяснить, к какой ячейке происходило меньше всего обращений, и сохранить новую запись именно там. Как реализовать LRU?
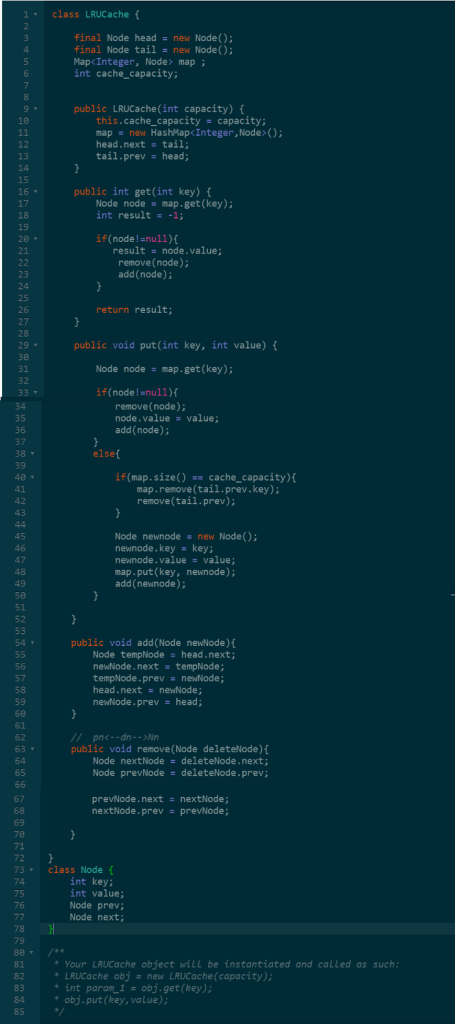
Пример кода LRU:
Внутренние части кэша
Мы разобрались с хеш-таблицами, оперативной памятью и LRU. Теперь нам нужен сервис, который обслуживает запросы на получение/размещение/удаление (get/put /delete). Несмотря на высокую скорость работу, оперативная память все равно блокирует вызовы. Поэтому нужен эффективный способ удовлетворения этих запросов.
Для этого можно создать n потоков по мере получения запросов или расширить пул для обработки потоков. Еще один возможный вариант — это логика, основанная на событиях.
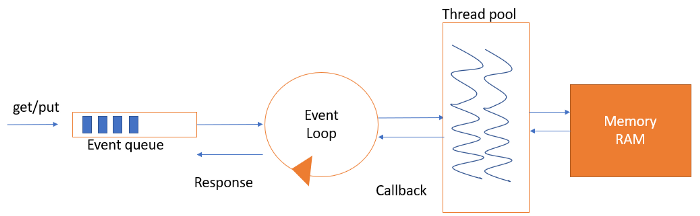
Как показано на рисунке выше, у нас есть очередь событий. Туда попадает любой запрос “get/put”. Также есть цикл событий, который выполняется бесконечно и представляет собой однопоточную операцию. Помимо этого, доступен пул потоков, который выполняет только операции ввода-вывода в оперативную память.
Каждый раз, когда мы получаем запрос “get/put”, он помещается в очередь событий. Цикл событий продолжает считывать очередь событий и передает запрос, который свободно располагается в ней. Как только происходит передача в пул потоков, он выполняет обратный вызов и снова считывает очередь событий.
Таким образом, очередь событий никогда не блокируется. Поток в пуле, который получает запрос, выполняет операцию, получает данные и возвращается к запросу через ответ обратного вызова, цикл событий или какой-либо другой механизм. Именно так можно более эффективно обрабатывать запрос.
Отказоустойчивость
Как сделать систему кэширования отказоустойчивой? Мы знаем, что хеш-таблица и данные хранятся в оперативной памяти. А что, если произойдет потеря питания и все данные будут сброшены? Это означает, что система кэширования нестабильна, и это нужно исправить.
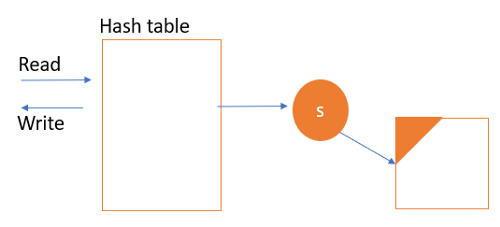
- Снимок с регулярным интервалом. Синхронный сервис “S” работает в фоновом режиме. Он берет замороженную копию хеш-таблицы и помещает ее в файл дампа, который сохраняется на жестком диске.
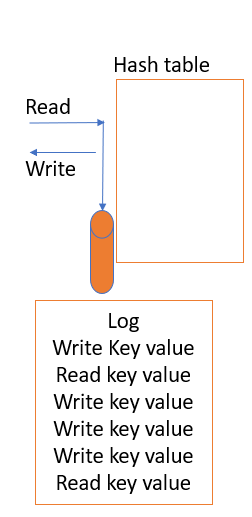
2. Восстановление журнала. Сервис, отвечающий за чтение и запись в хеш-таблице, будет непрерывно восстанавливать файлы в журнале. Все операции в журнале выполняют асинхронный вызов, который продолжает обновлять его. Эти запросы можно поместить в промежуточную очередь, чтобы не влиять на возможность чтения/записи. Каждая операция регистрируется, и если оборудование выйдет из строя и снова включится, мы сможем восстановить хеш-таблицу через операции в файле журнала.
Доступность
Как сделать систему доступной на 100%?
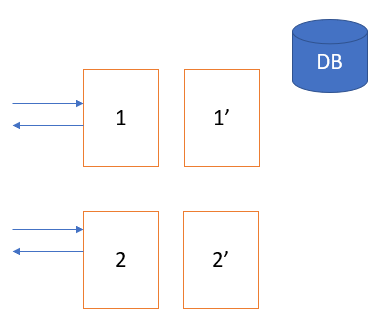
В кластере есть два узла, node1 и node2, и у обоих есть свой собственный кэш. Допустим, мы используем согласованное хеширование: узел 1 содержит ключи и значения, а узел 2 обрабатывает их. Что произойдет, если узел 1 выйдет из строя?
Все запросы, поступающие на узел 1, будут приводить к промаху кэша. Они будут попадать в БД, увеличивая нагрузку по чтению/записи. Чтобы избежать этого, можно сделать реплику узла 1, например RF = 2. Поэтому, какие бы данные ни были у узла 1, такие же будут на узле 1’.
Преимущество. Нагрузка снижается, потому что запросы, поступающие на узел 1, также будут отправляться на узел 1’ и обрабатываться им. Таким образом, запросы на чтение распределяются и обеспечивают высокую производительность с меньшей задержкой.
Недостаток. Продолжительная синхронизация этих двух узлов может привести к непоследовательности.
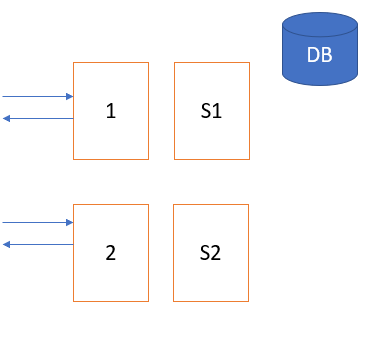
Как это исправить? Вместо копии можно создать подчиненный узел из нескольких узлов. В этом случае обновления данных также поступают на подчиненные устройства, но чтение/запись всегда происходит на главных узлах. Ведомое устройство не задействуется, пока главное не отключится.
Читайте также:
- Балансировка нагрузки и последовательное хеширование
- Основные принципы кэширования веб-приложений
- Лучший способ эффективно управлять неструктурированными данными
Читайте нас в Telegram, VK и Дзен
Перевод статьи Jolly srivastava: Distributed cache system design





