
В этом руководстве мы познакомимся с балансировкой нагрузки. При построении систем очень важно представлять себе, что это такое.
Рассмотрим концепцию балансировки нагрузки на простом примере.
Допустим, у вас есть один компьютер, на котором работает программа (алгоритм), и кто-то приходит и говорит, что заплатит вам, если вы просто позволите ему использовать ваш алгоритм.
Также предположим, что есть человек с мобильным телефоном. Он может подключиться к вашему компьютеру и воспользоваться алгоритмом. Он просто использует алгоритм и получает результат. И каждый раз, когда он это делает, он платит вам деньги. Но отвлечемся от денег, маркетинга и прочего. У нас есть технические спецификации. Этот алгоритм должен работать — тогда клиент будет доволен.
Теперь давайте перейдем к сценарию из жизни. Упомянутый алгоритм — что-то вроде сервера. Сервер — это нечто, что обслуживает запрос. Когда человек подключается через мобильный телефон, он отправляет запрос. И тут срабатывает ваш алгоритм. Он может быть любым. Например, алгоритм распознавания лиц и отправки изображения в качестве ответа.
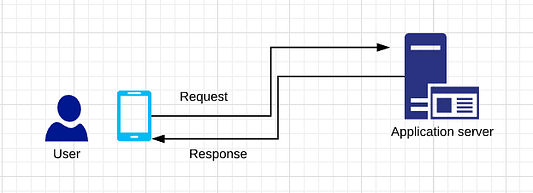
Таким образом, ваш сервер получает запросы и отправляет обратно ответ. Предположим, к вам поступают тысячи запросов (много пользователей). Теперь ваш компьютер больше не справляется с ними. Так что вам остается одно: добавить еще один компьютер. Поскольку вы получаете много денег от всех этих людей, то теперь можете позволить себе приобрести новый компьютер или сервер. Но здесь возникает другая проблема.
Куда вы отправляете запросы, если у вас несколько пользователей?
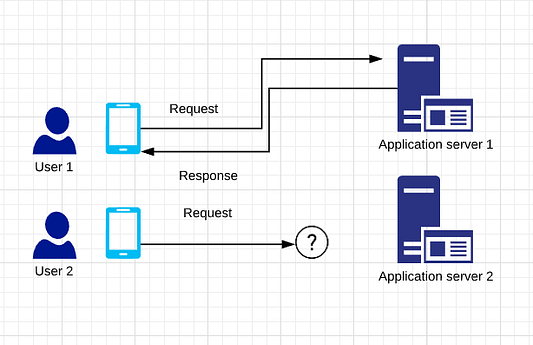
Куда будет поступать запрос пользователя-2: на сервер приложений-1 или сервер приложений-2?
Если у вас есть N серверов, вам нужно сбалансировать работу между ними. Теперь представьте, что все эти серверы несут определенную нагрузку. Запросы — вот то, что им нужно обработать. Таким образом, на сервер ложится нагрузка.
И попытка сбалансировать ее между имеющимся количеством N серверов называется балансировкой нагрузки. В ее реализации помогает концепция хеширования.
Распределение нагрузки с помощью хеширования
Итак, вы хотите равномерно распределять нагрузку по всем серверам. Предположим, что для каждого запроса существует идентификатор (RequestID). И можно ожидать, что он будет абсолютно случайным. Когда мобильный телефон (клиент) отправляет запрос на сервер, он случайным образом генерирует число (от 0 до m1). Вы можете хешировать ID запроса с помощью хеш-функции (h(r1)).
Например, хеш-функция может применяться для сопоставления случайных чисел с некоторым фиксированным числом в интервале 0…m1. Получив любое число, она всегда будет пытаться сопоставить его с любым целым числом от 0 до m1.
Предположим, что m1 равно 50. Тогда для любой хеш-функции всегда будет возвращаться значение от 0 до 50.
В результате хеширования вы получаете определенное значение (m1). Это значение/число можно сопоставить конкретному серверу после получения остатка с n серверов.

Пример
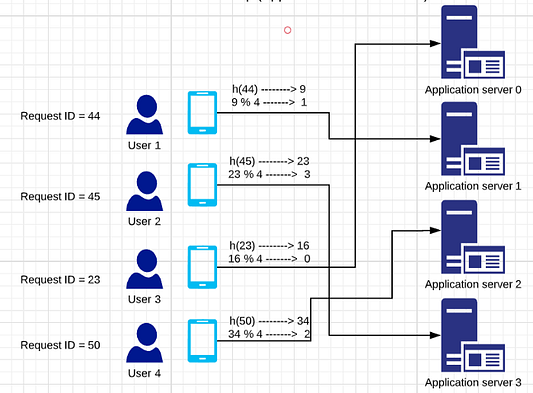
Здесь ваша хеш-функция абсолютно случайна. Вы можете ожидать, что все серверы будут нагружены равномерно. Таким образом, у каждого из серверов будет нагрузка Number of Requests)/n и коэффициент нагрузки, равный 1/n.
Здесь все идеально, и ничего добавлять не нужно. Но что произойдет, если понадобится больше серверов, а пользователи будут посылать все больше и больше запросов? Предположим, в эту систему нужно добавить еще один сервер. Теперь запросы пользователей 1, 2, 3 и 4 назначаются разным серверам. Например, идентификатор запроса пользователя-1 равен 44. Тогда хеш-значение равно 9. Поскольку теперь в наличии 5 серверов, значение остатка равно 4. Это означает, что запрос пользователя отправляется на сервер приложений-4. Таким образом, изменится весь путь запроса к серверам.
Стоимость изменений в этом случае высока. В чем причина? На практике идентификатор запроса никогда не бывает случайным (или бывает, но крайне редко). Идентификатор запроса обычно инкапсулирует некоторую информацию от пользователя. Например, пользовательский идентификатор (UserID).
h(Encapsulate information with User ID) ----> m1
Если идентификатор запроса один и тот же, то хеш-значение раз от раза будет одинаковым, так как применяется один и тот же алгоритм хеширования.
m1%n ----> p
Если хеш-значение (m1) одно и то же, то запрос будет отправляться на один и тот же сервер снова и снова. Если его опять и опять посылают на всё тот же сервер, почему он должен продолжать заниматься все время одним и тем же? Почему бы не сохранить запрос в локальном кэше?
В зависимости от идентификатора пользователя мы можем отправлять запросы на определенный сервер (например, запрос пользователя-1 должен идти на сервер-1), и как только мы их отправим, соответствующую информацию можно хранить в кэше на этих серверах.
В приведенном выше механизме кэширования произойдет вот что: вся система изменится, все пользователи теперь должны перейти на разные серверы, и вся полезная информация, которая была в кэше, станет бесполезной, потому что номера серверов полностью изменились. Это называется перехешированием.
Решение в последовательном хешировании
Последовательное хеширование решает проблему повторного хеширования, предоставляя схему распределения, которая не зависит от количества серверов.
Последовательное хеширование — это распределенная схема хеширования, которая функционирует независимо от количества серверов или объектов в распределенной хеш-таблице, назначая им позицию на абстрактном круге или хеш-кольце. Это позволяет совершать масштабирование серверов и объектов без влияния на остальную систему.
Предположим, выходные значения хеш-функции находятся в диапазоне от нуля до 2**32 или INT_MAX, а затем этот диапазон отображается на хеш-кольцо так, что значения выстраиваются по окружности. Все ключи и серверы хешируются с помощью одной и той же хеш-функции и помещаются на окружность. Чтобы узнать, у какого сервера запрашивать данный ключ или на каком из них его хранить, нужно сначала найти этот ключ на круге и двигаться по часовой стрелке, пока сервер не будет найден.
Воспользуемся приведенным выше примером и поместим значения на хеш-кольцо. В данном случае минимальное значение на круге равно 0, а максимальное — 50.
Пример
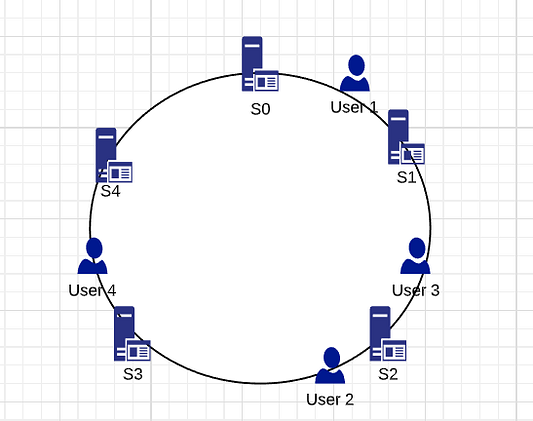
Здесь есть 5 серверов. Согласно правилу последовательного хеширования, пользователь-1 находится на сервере S1, пользователь-2 — на сервере S3, пользователь-3 — на сервере S2, а пользователь-4 — на сервере S4.
В случае несогласованного хеширования при удалении или добавлении сервера перемещается только один ключ с этого сервера. Например, если сервер S3 будет удален, то все ключи с сервера S3 будут перемещены на сервер S4, но ключи, хранящиеся на серверах S4, S0, S1 и S2, никуда не переместятся. Есть одна проблема: когда сервер S3 убран, то ключи с сервера S3 не распределяются поровну между оставшимися серверами S0, S1, S2 и S4. Они назначаются только серверу S4, что увеличивает нагрузку на него.
Чтобы равномерно распределить нагрузку между серверами при добавлении или удалении одного из них, создается фиксированное количество реплик (известных как виртуальные узлы) каждого сервера и они распределяются по кругу. Поэтому вместо ярлыков серверов S1, S2, S3, и S4, у нас будут S00, S01…S09, S10, S11…S19, S20 S21…S29, S30, S31…S39 и S40, S41…S49. Параметр для числа реплик, также известный как вес, зависит от ситуации.
Все ключи, которые сопоставляются репликам Sij, хранятся на сервере Si. Чтобы найти ключ, мы делаем то же самое: находим положение ключа на круге, а затем двигаемся вперед, пока не отыщем реплику сервера. Если реплика сервера — Sij, то ключ хранится на сервере Si.
Предположим, что сервер S3 удален, тогда все реплики S3 с метками S30, S31 … S39 должны также удалиться. Теперь ключи объектов, примыкающие к меткам S3X, будут автоматически переназначены на S4X и S2X. Все ключи, первоначально назначенные S4 и S2, не будут перемещены.
Подобное происходит при добавлении сервера. Предположим, мы хотим добавить сервер S5 в качестве замены S3. Тогда нужно добавить метки S50, S51 … S59. В идеальном случае одна треть ключей от S4 и S2 будет переназначена на S5.
В общем случае для переназначения при добавлении или удалении сервера требуется только K/N ключей, где K — количество ключей, а N — количество серверов (точнее максимальное начальное и конечное количество серверов).
Надеюсь, вы получили представление о балансировке нагрузки и последовательном хешировании.
Читайте также:
- 10 видов шаблонного кода на NextJS
- Перехват ошибок в компоненте React
- Стратегии обнаружения изменений в Angular - «onPush» и «Default»
Читайте нас в Telegram, VK и Дзен
Перевод статьи Kasun Dissanayake: Load Balancing and Consistent Hashing





