
Индустрия вредоносного программного обеспечения по-прежнему остается отлично организованным, хорошо финансируемым рынком, нацеленным на обход традиционных мер безопасности. Заражая компьютеры вредоносными программами, преступники тем или иным способом могут нанести ущерб как потребителям, так и предприятиям.
В этой статье я расскажу:
- как решал проблему вредоносного ПО с датасетом, содержащем около 200 ГБ данных;
- как создал функции изображения;
- как использовал дополнительные возможности для достижения логистической функции потерь 0.01.
1. Бизнес-проблема
1.1. Что такое малварь?
Английский термин “malware” (“малварь”) — это сложносокращенное слово от “malicious software” (вредоносное программное обеспечение). Если коротко, вредоносное ПО — это любая часть программного обеспечения, написанная с намерением нанести вред данным, устройствам или людям.
Источник: https://www.avg.com/en/signal/what-is-malware
1.2. Постановка проблемы
В последние несколько лет индустрия вредоносных программ развивалась очень быстро. Преступные синдикаты вкладывают значительные средства в технологии, позволяющие избежать традиционных мер безопасности. Это вынуждает группы/сообщества по защите от вредоносных программ создавать более надежное программное обеспечение для обнаружения и предотвращения хакерских атак. Основная часть защиты компьютерной системы от малварь заключается в определении того, является ли данный файл/программное обеспечение вредоносным ПО.
1.3 Источник/полезные ссылки
Корпорация Майкрософт уже много лет активно занимается созданием антивирусных продуктов. Ее утилиты для защиты от вредоносных программ запущены на более чем 150 миллионах компьютеров по всему миру. Это генерирует десятки миллионов ежедневных точек данных, которые необходимо анализировать как потенциально вредоносные программы. Чтобы эффективно анализировать и классифицировать такие большие объемы данных, необходимо научиться группировать вредоносы и идентифицировать каждую группу.
Набор данных, собранный корпорацией Майкрософт, содержит около 9 классов вредоносных программ.
Источник: https://www.kaggle.com/c/malware-classification
1.4. Реальные/бизнес-цели и ограничения
- Минимизация ошибок при анализе многоклассовых данных.
- Вероятностная оценка многоклассовых данных.
- Ограничение времени обнаружения вредоносных программ несколькими секундами/минутами во избежание блокировки компьютера пользователя.
2. Проблема датасета/машинного обучения
2.1. Данные
2.1.1. Обзор данных
- Источник : https://www.kaggle.com/c/malware-classification/data
- Два типа файла для каждой вредоносной программы:
- .asm-файл (подробнее: https://www.reviversoft.com/file-extensions/asm).
- .bytes-файл (необработанные данные содержат шестнадцатеричное представление двоичного содержимого файла без заголовка PE).
- Общий объем датасета для машинного обучения составляет 200 ГБ данных, из которых 50 ГБ данных — .bytes-файлы, а 150 ГБ данных — .asm-файлы.
- Много данных для одного модуля/компьютера.
- Имеется 10 868 .bytes-файлов и 10 868 .asm-файлов, всего 21 736 файлов.
- 9 типов вредоносных программ (9 классов) в имеющихся данных.
Типы вредоносных программ:
- Ramnit;
- Lollipop;
- Kelihos_ver3;
- Vundo;
- Simda;
- Tracur;
- Kelihos_ver1;
- Obfuscator.ACY;
- Gatak.
2.1.2. Пример точки данных
asm-файл
.text:00401000 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothing
.text:00401000 56 push esi
.text:00401001 8D 44 24 08 lea eax, [esp+8]
.text:00401005 50 push eax
.text:00401006 8B F1 mov esi, ecx
.text:00401008 E8 1C 1B 00 00 call ??0exception@std@@QAE@ABQBD@Z ; std::exception::exception(char const * const &)
.text:0040100D C7 06 08 BB 42 00 mov dword ptr [esi], offset off_42BB08
.text:00401013 8B C6 mov eax, esi
.text:00401015 5E pop esi
.text:00401016 C2 04 00 retn 4
.text:00401016 ; ---------------------------------------------------------------------------
.text:00401019 CC CC CC CC CC CC CC align 10h
.text:00401020 C7 01 08 BB 42 00 mov dword ptr [ecx], offset off_42BB08
.text:00401026 E9 26 1C 00 00 jmp sub_402C51
.text:00401026 ; ---------------------------------------------------------------------------
.text:0040102B CC CC CC CC CC align 10h
.text:00401030 56 push esi
.text:00401031 8B F1 mov esi, ecx
.text:00401033 C7 06 08 BB 42 00 mov dword ptr [esi], offset off_42BB08
.text:00401039 E8 13 1C 00 00 call sub_402C51
.text:0040103E F6 44 24 08 01 test byte ptr [esp+8], 1
.text:00401043 74 09 jz short loc_40104E
.text:00401045 56 push esi
.text:00401046 E8 6C 1E 00 00 call ??3@YAXPAX@Z ; operator delete(void *)
.text:0040104B 83 C4 04 add esp, 4
.text:0040104E
.text:0040104E loc_40104E: ; CODE XREF: .text:00401043j
.text:0040104E 8B C6 mov eax, esi
.text:00401050 5E pop esi
.text:00401051 C2 04 00 retn 4
.text:00401051 ; ---------------------------------------------------------------------------
bytes-файл
00401000 00 00 80 40 40 28 00 1C 02 42 00 C4 00 20 04 20
00401010 00 00 20 09 2A 02 00 00 00 00 8E 10 41 0A 21 01
00401020 40 00 02 01 00 90 21 00 32 40 00 1C 01 40 C8 18
00401030 40 82 02 63 20 00 00 09 10 01 02 21 00 82 00 04
00401040 82 20 08 83 00 08 00 00 00 00 02 00 60 80 10 80
00401050 18 00 00 20 A9 00 00 00 00 04 04 78 01 02 70 90
00401060 00 02 00 08 20 12 00 00 00 40 10 00 80 00 40 19
00401070 00 00 00 00 11 20 80 04 80 10 00 20 00 00 25 00
00401080 00 00 01 00 00 04 00 10 02 C1 80 80 00 20 20 00
00401090 08 A0 01 01 44 28 00 00 08 10 20 00 02 08 00 00
004010A0 00 40 00 00 00 34 40 40 00 04 00 08 80 08 00 08
004010B0 10 00 40 00 68 02 40 04 E1 00 28 14 00 08 20 0A
004010C0 06 01 02 00 40 00 00 00 00 00 00 20 00 02 00 04
004010D0 80 18 90 00 00 10 A0 00 45 09 00 10 04 40 44 82
004010E0 90 00 26 10 00 00 04 00 82 00 00 00 20 40 00 00
004010F0 B4 00 00 40 00 02 20 25 08 00 00 00 00 00 00 00
00401100 08 00 00 50 00 08 40 50 00 02 06 22 08 85 30 00
00401110 00 80 00 80 60 00 09 00 04 20 00 00 00 00 00 00
00401120 00 82 40 02 00 11 46 01 4A 01 8C 01 E6 00 86 10
00401130 4C 01 22 00 64 00 AE 01 EA 01 2A 11 E8 10 26 11
00401140 4E 11 8E 11 C2 00 6C 00 0C 11 60 01 CA 00 62 10
00401150 6C 01 A0 11 CE 10 2C 11 4E 10 8C 00 CE 01 AE 01
00401160 6C 10 6C 11 A2 01 AE 00 46 11 EE 10 22 00 A8 00
00401170 EC 01 08 11 A2 01 AE 10 6C 00 6E 00 AC 11 8C 00
00401180 EC 01 2A 10 2A 01 AE 00 40 00 C8 10 48 01 4E 11
00401190 0E 00 EC 11 24 10 4A 10 04 01 C8 11 E6 01 C2 00
2.2. Сопоставление реальной проблемы с проблемой МО
2.2.1. Тип проблемы машинного обучения
Существует 9 различных классов вредоносных программ, которые нам необходимо классифицировать по заданной точке данных => Проблема многоклассовой классификации
2.2.2. Показатели эффективности
Источник: https://www.kaggle.com/c/malware-classification#evaluation
Метрики:
- Многоклассовая логистическая функция потерь
- Матрица неточностей
2.2.3. Цели и ограничения машинного обучения
Цель: Установить вероятность принадлежности каждой точки данных к одному из 9 классов.
Ограничения: * Нужна вероятностная оценка классов. * Исключить ошибки в вероятностной оценке классов =>Метрика — логистическая функция потерь. *Определенные ограничения по времени.
2.3. Датасет для машинного обучения и тестирования
Рандомное разделение датасета на три части:
- 64% — для машинного обучения;
- 16% — для перекрестной проверки;
- 20% — для тестирования.
2.4. Полезные блоги, видео и справочные материалы
Решение, занявшее первое место на конкурсе Kaggle: https://www.youtube.com/watch?v=VLQTRlLGz5Y
https://github.com/dchad/malware-detection
http://vizsec.org/files/2011/Nataraj.pdf
https://www.dropbox.com/sh/gfqzv0ckgs4l1bf/AAB6EelnEjvvuQg2nu_pIB6ua?dl=0
“Перекрестная проверка более надежна, чем знание предметной области”.
3. Использование облачной платформы Google (GCP)
Я создал экземпляр GCP с хранилищем 500 ГБ и 8-ядерными VCPU с 32 ГБ оперативной памяти. Использование SSH оболочки экземпляра напрямую может привести к исчерпанию хранилища при выполнении определенного количества операций с файлами. Поскольку данное тематическое исследование требовало операций с файлами, я воспользовался механизмом переадресации портов.
Шаг -1
Создаем экземпляр, указанный ниже. Перед этим обязательно создаем брандмауэр. Как только и то, и другое будет сделано, можно создать внешний IP-адрес со статическим типом и назначить экземпляр.
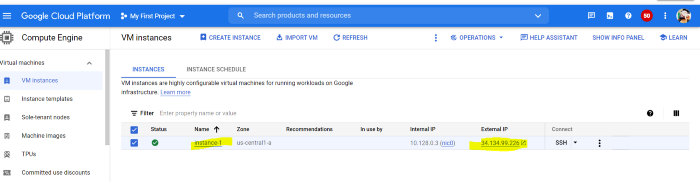
Созданный экземпляр Google Cloud
Шаг -2
Устанавливаем Google Cloud SDK по указанному ниже URL-адресу. https://cloud.google.com/sdk/docs/quickstart
Шаг -3
На этом решающем этапе используем переадресацию портов, как показано ниже.
Формат:
gcloud compute ssh --ssh-flag="-L <tcp port>:localhost:<tcp port>" --zone "<zone>" "<instance name>"
Пример:
gcloud compute ssh --ssh-flag="-L 8888:localhost:8888" --zone "us-central1-a" "instance-1"
Шаг -4
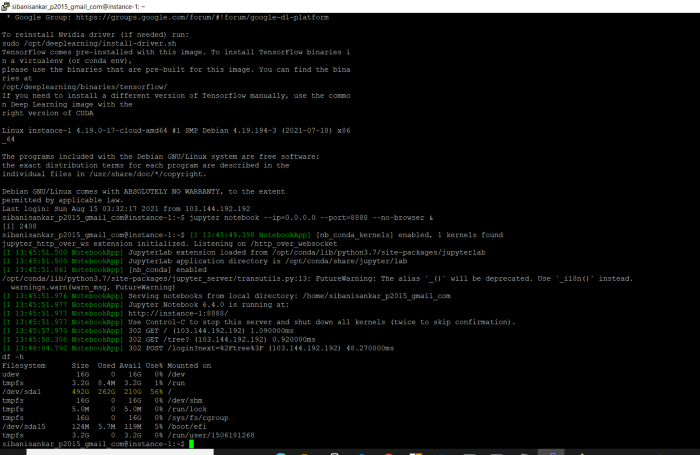
Теперь используем приведенную ниже команду, чтобы открыть jupyter notebook.
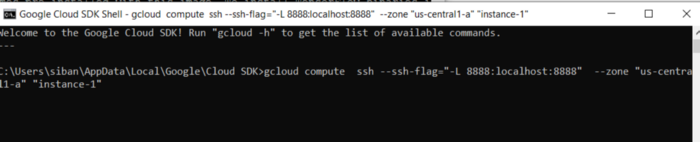
jupyter notebook --ip=0.0.0.0 --port=8888 --no-browser &
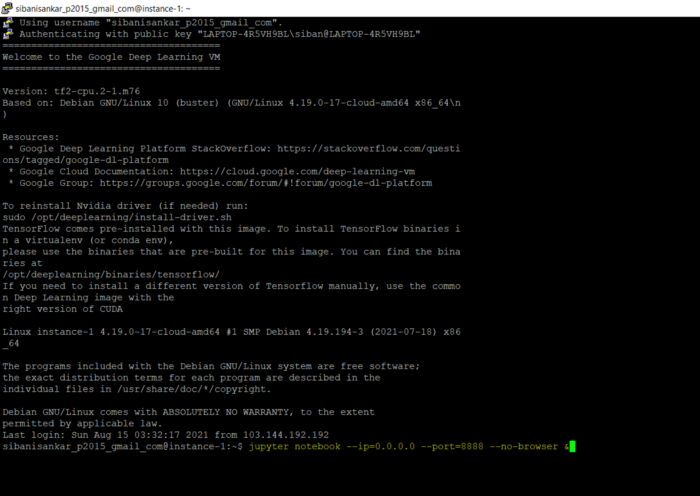
Теперь открываем браузер Chrome и вводим IP экземпляра: TCP Port
После введения команды Jupyter notebook вы получите токен в консоли (можете использовать то же самое для постоянной установки пароля). Когда все шаги будут выполнены, jupyter notebook отобразится на Google Compute Engine, как показано ниже.
Как видно на рисунке ниже, я использовал 56% из назначенных 492 ГБ. Все в облачном хранилище!!! Разве это не здорово?
4. Загрузка и извлечение файлов
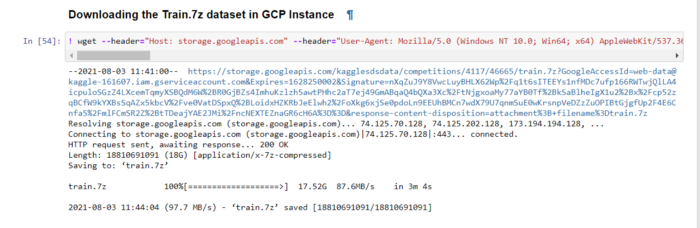
4.1 Загружаем датасет из Kaggle
Я использовал расширение CurlWget, которое доступно в магазине Google Chrome. Он поможет загрузить датасет из Kaggle и его Cancel.
Открываем CurlWget, копируем ссылку и открываем jupyter notebook.
В ячейке напечатайте то, что указано ниже.
! <link>
Запустив ячейку, вы будете поражены тому, как быстро она загружается. При этом хранилище в вашей локальной среде не используется.
4.2 Распаковываем/извлекаем сжатый файл
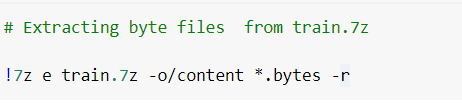
Устанавливаем 7zip с помощью команды PIP в ячейке jupyter notebook и извлекаем файлы определенных типов с помощью вышеуказанной команды. В приведенном выше коде извлекаем .bytes-файлы из сжатого файла train.7z.
5. Поисковый анализ данных
Наконец все необходимые библиотеки импортированы. Теперь нужно графически отобразить распределение классов вредоносных программ. Поскольку это многоклассовая классификация из 9 классов, я использовал приведенный ниже код.
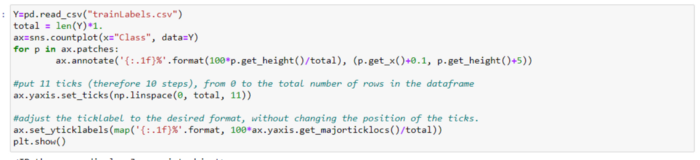
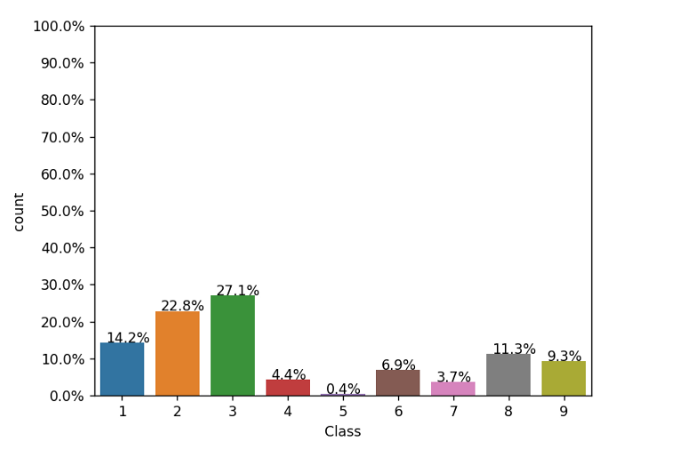
Как видим, самая высокая метка у класса 3, а самая низкая — у класса 5.
Теперь рассчитаем размер byte-файла и построим диаграмму размаха для краткого обзора максимальных размеров классов.
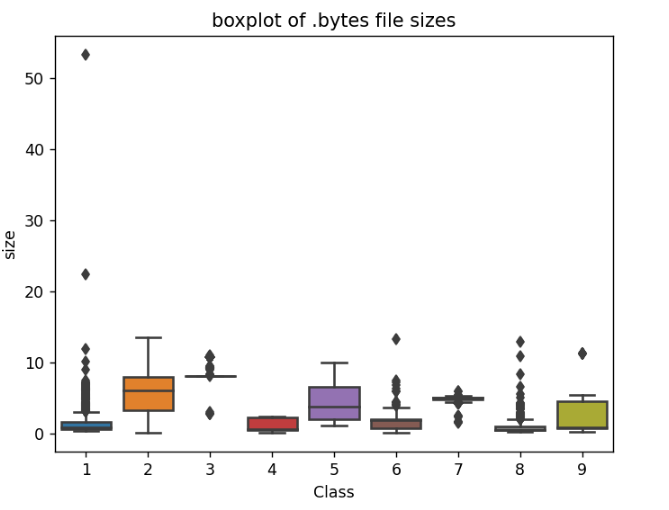
Как видно из приведенного выше графика, byte-файлы класса 2 имеют максимальные размеры файлов, т. е. приблизительно 8 МБ.
6. Разработка функциональных возможностей
Я произвел следующие вычисления и сохранил датасет в Google Cloud:
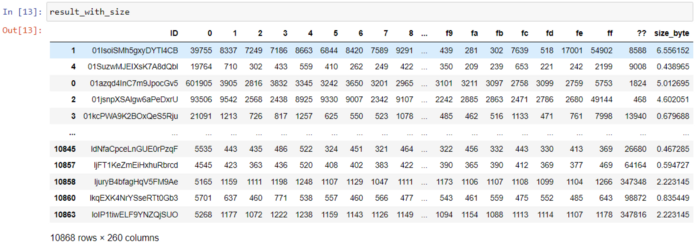
6.1 Униграмма byte-файлов с размерами
byte-униграммы приведены в датасете, который можно сохранить в файле CSV и прочитать позже, как показано ниже.
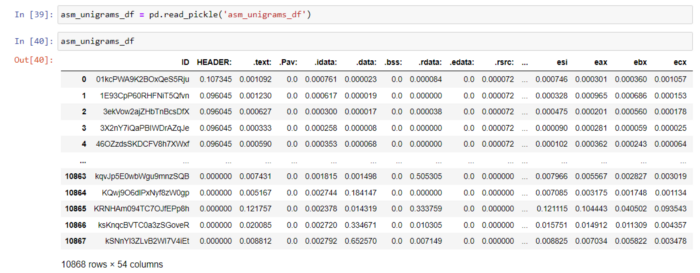
6.2 Униграмма asm-файлов с размерами
asm-униграммы приведены в датасете, который можно сохранить в файле pickle и прочитать позже, как показано ниже.
6.3 Биграмма byte-файлов (выбрано 2000 лучших из 66308 функций)
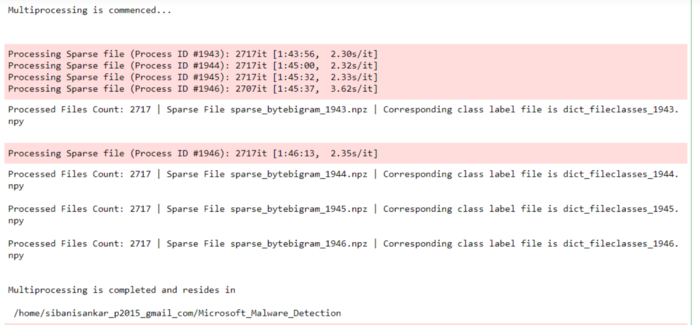
Приступая к созданию биграмм byte-файлов, я понимал, что подобная задача может время от времени убивать ядро python, потому что датасет требует вычислений почти 66,5 тыс. функций. Поэтому я использовал многопроцессорную обработку и вычислил разреженные матрицы, как показано ниже.
import scipy
from scipy.sparse import csr_matrix
from sklearn.feature_extraction.text import CountVectorizer
from tqdm import tqdm
import os
import numpy as np
import warnings
warnings.filterwarnings("ignore")
from datetime import datetime
def generate_sparse_matrices(files):
'''
Использование многопроцессорной обработки для вычисления 4 разреженных матриц и их файлов. Поскольку количество столбцов огромно, ядро jupyter "умирает" при использовании фрейма данных pandas.
'''
process_id = os.getpid()
vectorizer = CountVectorizer(lowercase = False, ngram_range = (2,2), vocabulary = features)
sparse_bigram = csr_matrix((len(files), len(features)))
count = 0
print(' ', end='', flush=True)
text = "Processing Sparse file (Process ID #{})".format(process_id)
file_classes = {}
for file in files:
for key, value in dict_files.items():
if key == file.split('.')[0]:
file_classes[key] = value
class_filename = 'dict_fileclasses_'+str(process_id)+'.npy'
np.save(class_filename, file_classes)
for i, file in tqdm(enumerate(files), desc = text):
count += 1
f = open('byteFiles/' + file)
sparse_bigram[i, :] += csr_matrix(vectorizer.fit_transform([f.read().replace('\n', ' ').lower()]))
f.close()
sparse_filename = 'sparse_bytebigram_'+str(process_id)+'.npz'
scipy.sparse.save_npz(sparse_filename, sparse_bigram)
print(f'Processed Files Count: {count} | Sparse File {sparse_filename} | Corresponding class label file is {class_filename}\n')
#Ref: https://docs.python.org/3/library/multiprocessing.html#module-multiprocessing
from multiprocessing import Pool
files = os.listdir('byteFiles')
parts = int(len(files)/4)
byte_files_part_1 = files[:parts]
byte_files_part_2 = files[parts:(2*parts)]
byte_files_part_3 = files[(2*parts):(3*parts)]
byte_files_part_4 = files[(3*parts):]
all_byte_files = [byte_files_part_1, byte_files_part_2, byte_files_part_3, byte_files_part_4]
print("Multiprocessing is commenced...\n")
p = Pool(4)
p.map(generate_sparse_matrices, all_byte_files)
print("\nMultiprocessing is completed and resides in \n\n", os.getcwd())
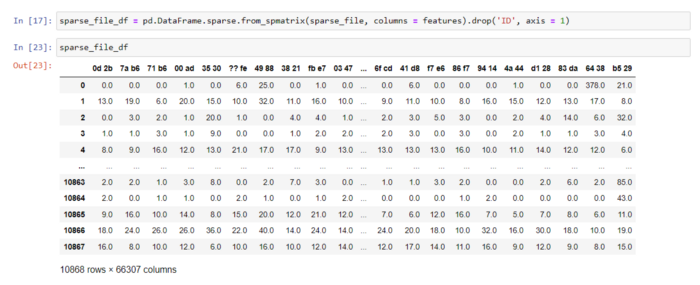
Когда разреженные матрицы были созданы, я объединил их и подготовил окончательный датасет. Аналогично, я объединил созданные метки классов, чтобы избежать неправильного присвоения классов файлам.
from scipy import sparse
sparse_file = sparse.load_npz('sparse_bytefile_bigrams.npz')
byteclass_file_1 = np.load('dict_fileclasses_1943.npy', allow_pickle = True)
dict_file_1 = dict(byteclass_file_1.item())
array_file_1 = np.array(list(dict_file_1.items()))
class_labels_1 = pd.DataFrame(array_file_1)
class_labels_1.columns = ['ID', 'Class']
byteclass_file_2 = np.load('dict_fileclasses_1944.npy', allow_pickle = True)
dict_file_2 = dict(byteclass_file_2.item())
array_file_2 = np.array(list(dict_file_2.items()))
class_labels_2 = pd.DataFrame(array_file_2)
class_labels_2.columns = ['ID', 'Class']
byteclass_file_3 = np.load('dict_fileclasses_1945.npy', allow_pickle = True)
dict_file_3 = dict(byteclass_file_3.item())
array_file_3 = np.array(list(dict_file_3.items()))
class_labels_3 = pd.DataFrame(array_file_3)
class_labels_3.columns = ['ID', 'Class']
byteclass_file_4 = np.load('dict_fileclasses_1946.npy', allow_pickle = True)
dict_file_4 = dict(byteclass_file_4.item())
array_file_4 = np.array(list(dict_file_4.items()))
class_labels_4 = pd.DataFrame(array_file_4)
class_labels_4.columns = ['ID', 'Class']
id_classes = pd.concat([class_labels_1, class_labels_2,class_labels_3, class_labels_4], axis = 0)
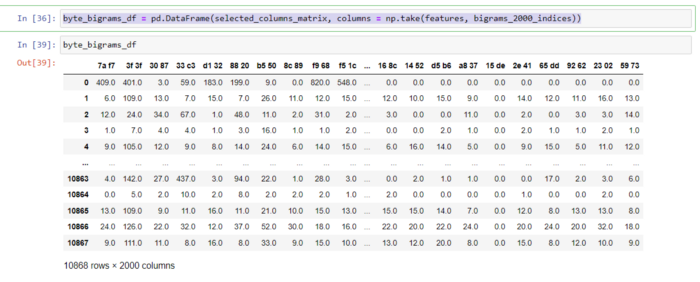
Используя тест хи-квадрат, я выбрал 2000 лучших объектов и подготовил датасет.
#Использование теста хи-квадрат для получения 2000 лучших функций из 66307
from numpy import hstack
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectPercentile, SelectKBest
clf = SelectKBest(chi2, k=2000)
bytefile_bigrams_df_new = clf.fit_transform(byte_bigrams_wo_id,y)
bytefile_bigrams_df_new.shape
bigrams_2000_indices = clf.get_support(indices = True)
selected_columns_matrix = np.zeros((10868, 0))
for i in tqdm(bigrams_2000_indices):
kept = sparse_file[:, i].todense()
selected_columns_matrix = hstack([selected_columns_matrix, kept])
byte_bigrams_df = pd.DataFrame(selected_columns_matrix, columns = np.take(features, bigrams_2000_indices))
Как видно ниже, я подготовил набор данных bigrams, содержащий 2000 функций.
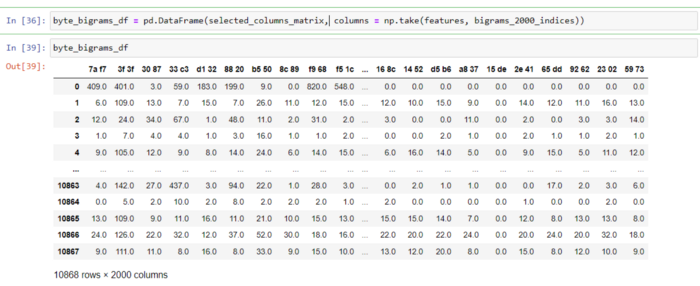
6.4 Биграмма asm-файлов (выбрано 500 лучших из 676 функций)
Ниже представлены подготовленные мной биграммы кодов операций с asm-файлами.
opcodes = ['jmp', 'mov', 'retf', 'push', 'pop', 'xor', 'retn', 'nop', 'sub', 'inc', 'dec', 'add','imul', 'xchg', 'or', 'shr', 'cmp', 'call', 'shl', 'ror', 'rol', 'jnb','jz','rtn','lea','movzx']
def asm_bigram(opcodes):
asm_bigrams = []
for i, v in enumerate(opcodes):
for j in range(0, len(opcodes)):
asm_bigrams.append(v + ' ' + opcodes[j])
return asm_bigrams
asm_bigrams = asm_bigram(opcodes)
def opcode_collect():
files = os.listdir('asmFiles')
op_file = open("opcode_file.txt", "w+")
for file in tqdm(files):
opcode_str = ""
with codecs.open('asmFiles/' + file, encoding='cp1252', errors ='replace') as fli:
for lines in fli:
line = lines.rstrip().split()
for li in line:
if li in opcodes:
opcode_str += li + ' '
op_file.write(opcode_str + "\n")
op_file.close()
opcode_collect()
from scipy.sparse import csr_matrix
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(ngram_range=(2, 2), vocabulary = asm_bigrams)
opcodebigrams_sparse = csr_matrix((10868, len(asm_bigrams)))
op = open('opcode_file.txt').read().split('\n')
for i in tqdm(range(10868)):
opcodebigrams_sparse[i, :] += csr_matrix(vectorizer.transform([op[i]]))
from scipy import sparse
sparse.save_npz('opcodebigrams_sparse.npz',opcodebigrams_sparse)
В ходе подготовки набора данных я удалил столбцы, в которых присутствует только 1 уникальное значение, и выбрал 500 лучших объектов с помощью библиотеки теста хи-квадрат.
from scipy import sparse
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectPercentile, SelectKBest
opcodebigramse = sparse.load_npz('opcodebigrams_sparse.npz')
asm_class_labels = pd.read_csv('asm_class_labels.csv').drop('Unnamed: 0', axis = 1)
asm_class_labels.columns = ['ID', 'Class']
opcodebigrams_df = pd.DataFrame.sparse.from_spmatrix(opcodebigramse, columns = asm_bigrams)
opcodebigrams_df = pd.concat([asm_class_labels['ID'], opcodebigrams_df], axis = 1)
opcodebigrams_df = opcodebigrams_df.sort_values(by = 'ID')
#удаление столбцов, в которых присутствует только 1 уникальное значение.
asm_cols = opcodebigrams_df.nunique()
to_del = [i for i,v in enumerate(asm_cols) if v == 1]
cols = opcodebigrams_df.columns[to_del]
#отбрасывание ненужных столбцов
opcodebigrams_df = opcodebigrams_df.drop(cols, axis=1)
print(opcodebigrams_df.shape)
#Выбор 500 лучших функций с помощью теста хи-квадрат
X = opcodebigrams_df.drop('ID', axis = 1)
y = class_y['Class']
clf = SelectKBest(chi2, k=500)
opcode_bigrams_500 = clf.fit_transform(X,y)
bigram_500_indices = clf.get_support(indices = True)
cols = X.columns[bigram_500_indices]
X_modified = X.loc[:,cols]
asm_opcode_bigrams_df_500 = pd.concat([opcodebigrams_df['ID'], X_modified], axis = 1)
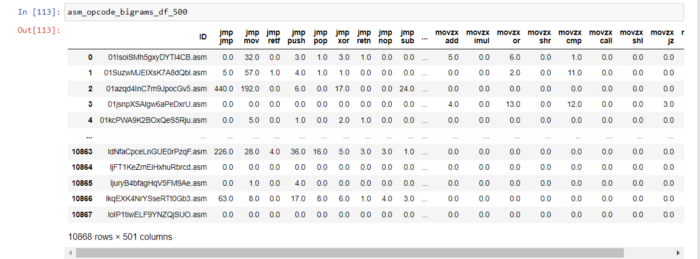
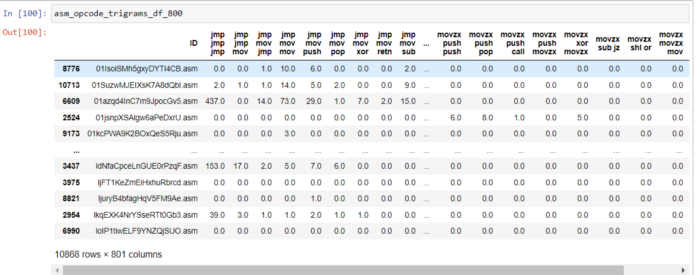
6.5 Триграмма asm-файлов (выбрано 800 лучших из 17 тысяч функций)
Я прочитал разреженную матрицу, созданную для триграмм кода операции, и подготовил набор данных с 800 лучшими функциями, используя тест хи-квадрат
opcode_trigram_sparse = sparse.load_npz('opcodetrigram.npz')
asm_class_labels = pd.read_csv('asm_class_labels.csv').drop('Unnamed: 0', axis = 1)
asm_class_labels.columns = ['ID', 'Class']
opcodetrigrams_df = pd.DataFrame.sparse.from_spmatrix(opcode_trigram_sparse, columns = asmopcodetrigram)
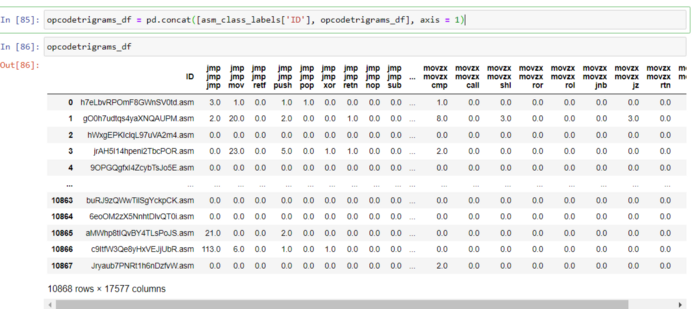
unique_cols = opcodetrigrams_df.nunique()
to_del = [i for i,v in enumerate(unique_cols) if v == 1]
cols = opcodetrigrams_df.columns[to_del]
# отбрасывание ненужных столбцов
opcodetrigrams_df = opcodetrigrams_df.drop(cols, axis=1)
print(opcodetrigrams_df.shape)
X = opcodetrigrams_df.drop('ID', axis = 1)
y = class_y['Class']
#Выбор 800 лучших функций триграммы
from sklearn.feature_selection import chi2
from sklearn.feature_selection import SelectPercentile, SelectKBest
clf = SelectKBest(chi2, k=800)
opcode_trigrams_800 = clf.fit_transform(X,y)
opcode_trigrams_800.shape
trigram_800_indices = clf.get_support(indices = True)
cols = X.columns[trigram_800_indices]
X_modified = X.loc[:,cols]
asm_opcode_trigrams_df_800 = pd.concat([opcodetrigrams_df['ID'], X_modified], axis = 1)
6.6 Особенности изображений asm-файлов (выбрано 800 лучших)
Я создал изображения каждого asm-файла и задал путь сохранения. Как только все изображения были сохранены, я вычислил 800 лучших функций.
def extract_images_from_text(arr_of_filenames, folder_to_save_generated_images):
for file_name in tqdm(arr_of_filenames):
if(file_name.endswith("asm")):
this_file = codecs.open(root_path + "asmFiles/" + file_name, 'rb')
size_of_current_asm_file = os.path.getsize(root_path + "asmFiles/"+file_name)
width_of_file = int(size_of_current_asm_file**0.5)
remainder = size_of_current_asm_file % width_of_file
# Создание массива из отдельных байтов с помощью передачи
кода типа "B"
# "B" - для символов без знака
array_of_image = array.array('B')
array_of_image.fromfile(this_file, size_of_current_asm_file-remainder)
this_file.close()
arr_of_generated_image = np.reshape(array_of_image[:width_of_file * width_of_file], (width_of_file, width_of_file))
arr_of_generated_image = np.uint8(arr_of_generated_image)
imageio.imwrite(folder_to_save_generated_images+'/' + file_name.split(".")[0] + '.png', arr_of_generated_image)
# Теперь вызовите вышеуказанную функцию
directory_to_save_generated_image = root_path + 'image_asm_files'
file_list_asm_files=os.listdir('image_asm_files')
with open(root_path + "asm_image_top_800_df.csv", mode='w') as top_800_image_asm_df:
#file_list_asm_files = 10868, top_800_image_asm_df=800
top_800_image_asm_df.write(','.join(map(str, ["ID"]+["pixel_asm{}".format(i) for i in range(800)])))
#top_800_image_asm_df.write(','.join(map(str, ["ID"]+["pixel_asm{}".format(i) for i in range(10)])))
top_800_image_asm_df.write('\n')
for image in tqdm(file_list_asm_files):
file_id_asm_files=image.split(".")[0]
# Создайте Матрицу 2, содержащую матрицу изображений в 2D - формате
asm_image_array=imageio.imread(root_path + "image_asm_files/"+image)
# Извлечение из сплющенного массива первых 800 пикселей
asm_image_array=asm_image_array.flatten()[:800]
# asm_image_array=asm_image_array.flatten()[:10]
top_800_image_asm_df.write(','.join(map(str, [file_id_asm_files]+list(asm_image_array))))
top_800_image_asm_df.write('\n')
Это заключительные функции, объединенные вместе. Я пробовал различные типы функций, чтобы добиться логистической функции потерь в 0,01, но не смог. Только последние функции помогли мне добиться логистической функции потерь 0,01.
Вы можете обратиться к ссылке GitHub, приведенной выше, для завершения экспериментов.
Я использовал библиотеку тестов хи-квадрат для выбора лучших функций. Это делается для уменьшения размерности набора данных, поскольку pandas не может хорошо справляться с большими наборами данных.
6.7 Объединение всех функций
Я объединил все функции, чтобы разделить наборы данных для машинного обучения и тестирования.
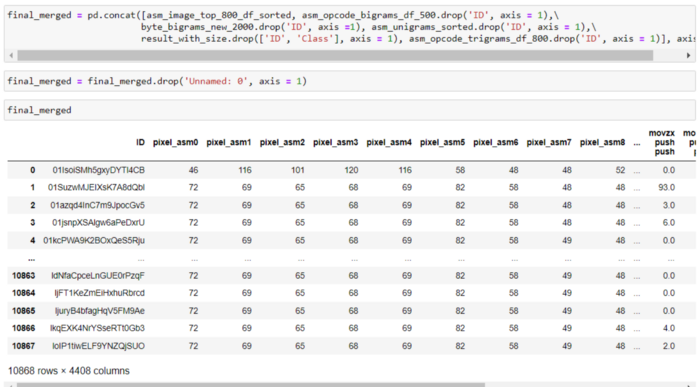
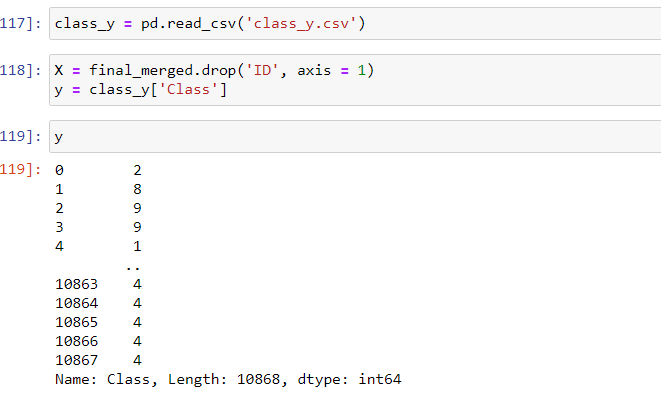
7. Пробный метод
Учитывая цель нашего тематического исследования — достичь логистической функции потерь 0,1, — лучше всего подготовить продвинутые функции с использованием N-граммы и объединить их.
В приведенном ниже разделе мы применили модели машинного обучения к окончательно подготовленному набору данных.
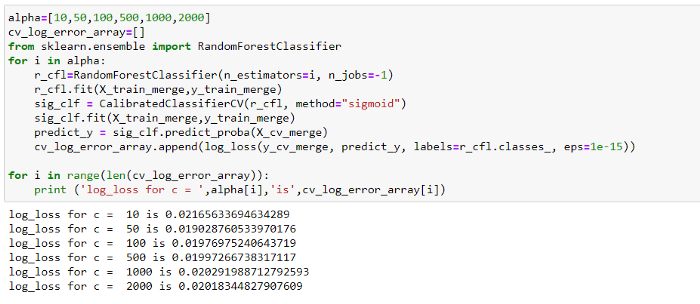
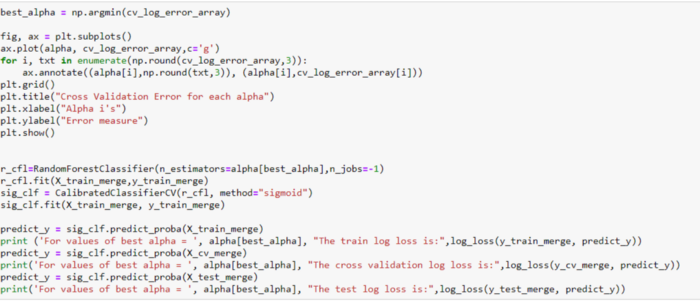
8. Классификатор Random Forest
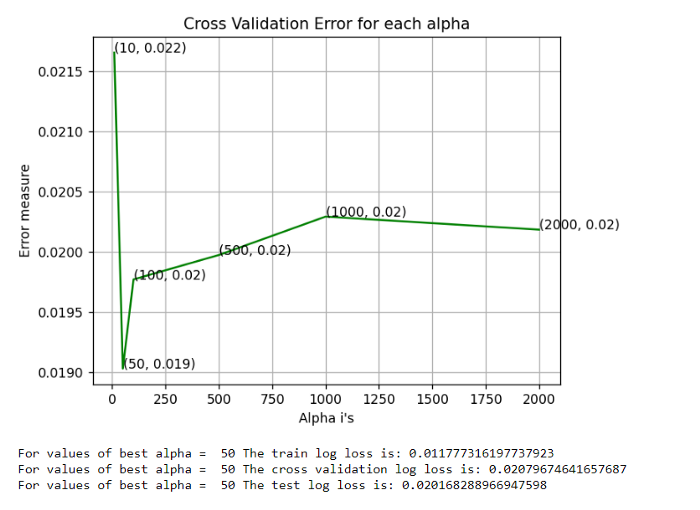
Используя классификатор Random Forest, мы добились логистической функции потерь 0,02, как показано ниже.
9. Классификатор XGBoost
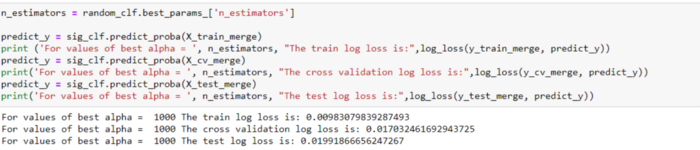
Есть!!! Мы достигли логистической функции потерь 0,01 с помощью XGBoost. Следовательно, мы можем выбрать модель XGBoost для повышения производительности и точности с наименьшим значением логистической функцией потерь.
10. Сравнение моделей
В этом разделе я сравниваю все модели, участвовавшие в эксперименте с различными типами функций, включая выбранные в конце функции.
Для знакомства с остальными моделями можете посетить мой профиль на GitHub.

11. Вывод
- Я использовал GCP из-за системы с низкой задержкой. Переадресация портов с помощью Google Cloud SDK помогла не потерять назначенное хранилище. Использование файловых операций в оболочке GCP SSH значительно увеличило бы объем хранилища Google.
- Вначале я выполнил машинное обучение byte-файлов и ASM-униграмм.
- Я использовал многопроцессорную обработку при создании byte-биграмм (66308 уникальных функций).
- С помощью многопроцессорной обработки я создал разреженные матрицы и соответствующие им метки классов (т. е. идентификаторы и классы). По завершении я объединил их и подготовил набор данных byte-биграммы.
- Прежде чем приступать к биграммам и расширенным функциям, я подумал об очистке данных.
- Поэтому я удалил столбцы, которые имеют только 1 уникальное значение, а также дедуплицировал столбцы.
- Я использовал тест хи-квадрат для вычисления наилучших характеристик. До этого я применял steop4.
- После выбора я объединил все расширенные функции и примененные модели машинного обучения, такие как Random Forest и XBGoost.
- Мы достигли логистической функции потерь 0,01 с классификатором XGBoost
- Одну вещь, с которой я столкнулся, собирая y-значения, можно спокойно проигнорировать, поскольку мы больше были сосредоточены на других функциях. Поэтому я отсортировал все наборы данных, подготовленные в порядке возрастания, и сохранил их в GCP для дальнейшего использования. Таким образом, мы можем избежать неправильного объединения (Слияние иногда приводит к ошибкам, поэтому я выбрал объединение).
Читайте также:
- Введение в Веб-безопасность
- Когда ИИ или машинное обучение неуместны
- Интуитивная основа обучения с подкреплением
Читайте нас в Telegram, VK и Дзен
Перевод статьи Sibani Sankar Panigrahi: Malware Detection using Machine Learning Algorithms performed in Google Cloud Platform (GCP)





