
В этом видео от автора показан обученный агент, который пытается избежать встречного движения, перестраиваясь в другой ряд и меняя скорость. Обучение проводилось с помощью алгоритма DQN.
На первый взгляд обучение с подкреплением кажется невероятно сложным. Состояние, действие, среда взаимодействия, вознаграждение, функция-значение, Q-обучение и множество других терминов могут стать довольно обременительными для новичка. Но что, если я скажу вам, что эта концепция прочно вошла в нашу повседневную жизнь? Да, вы правильно прочитали! Мы используем ее практически на каждом шагу.
В этой статье я покажу вам, насколько интуитивным является обучение с подкреплением и как часто мы следуем его принципам. Возможно, такой подход поможет немного прояснить этот вид машинного обучения. Сосредоточившись на его интуитивной базе, а не применении, я постараюсь использовать математические формулы как можно реже.
Пример
Прежде чем мы коснемся терминологии, описывающей обучение с подкреплением, проанализируем несколько примеров.
Экзамен. Представьте, что у вас завтра экзамен. Из-за какой-то чрезвычайной ситуации вы не смогли подготовиться к нему, поэтому решили просмотреть ответы к прошлогодним тестам по этому курсу. Проштудировав некоторые из них, вы замечаете закономерность: более 60 % оценочных баллов приходится на вопросы из первых трех глав учебника, в то время как остальные 40 % поровну распределяются между оставшимися пятью главами. Из-за нехватки времени вы можете изучить либо первые три главы, либо последние пять. Вам нужно набрать не менее 40 % баллов, чтобы сдать экзамен.

Теперь ответьте на вопрос: каким главам вам стоит посвятить время?
Первым трем, конечно! Анализ предыдущих данных показывает: есть высокая вероятность того, что значительное количество баллов снова будет присвоено первым трем главам. Значит, у вас больше шансов набрать 40 % баллов из возможных 60 %. Даже допустив несколько ошибок, вы с большой вероятностью сдадите экзамен. Если же выберете остальные 5 глав, даже одна ошибка может осложнить вашу жизнь.
Терминология
Теперь углубимся в терминологию, предлагаемую этим алгоритмом.
Среда взаимодействия
Как следует из названия, это пространство, с которым взаимодействует агент. В нашем случае средой был экзамен. Вы, агент, взаимодействовали с экзаменационной средой. Это пространство, в котором агент должен взаимодействовать определенным образом, следуя соответствующему алгоритму. В приведенном выше видео мы видим, как агент (зеленая машина) взаимодействует со своей средой (с шоссе, заполненным синими автомобилями).
Агент
Агент представляет саму программу, которая взаимодействует с внешней средой. В нашем примере с экзаменом вы являетесь агентом. В видео про автовождение эту роль выполняет зеленый автомобиль, взаимодействующий со средой шоссе.
Действие
Это конкретная операция, которую должен выполнить агент. В случае с экзаменом вам нужно было выбрать между двумя вариантами действия — изучением первых трех или последних пяти глав. В примере с автомобилем агент выбирал операции, которые помогали ему ориентироваться в потоке машин: замедляться, перестраиваться в другой ряд или ускоряться.
Вознаграждение
Понятие максимизации вознаграждения — вот что делает эту концепцию поистине захватывающей. Вы наверняка обратили внимание на то, что в примере с экзаменом мы выбрали первые три главы самостоятельно. В отличие от контролируемого обучения, где даются строгие инструкции, указывающие, что делать в каждой ситуации, обучение с подкреплением позволяет прийти к собственному решению предложенной ситуации (в данном случае — в ситуации с прошлогодними вопросами). Стимулом, побуждающим сделать выбор, были оценочные баллы. Главная цель состояла в том, чтобы максимизировать экзаменационный результат, то есть получить достойное вознаграждение.
Именно этот стимул — максимизация вознаграждения — является главной мотивацией для агента. Именно она позволяет агенту делать выводы, и почти все алгоритмы обучения с подкреплением основаны на максимизации вознаграждения наиболее эффективным способом.
Мы должны определить вознаграждение таким образом, чтобы сообщить агенту о намерениях. В примере с экзаменом вознаграждение определялось как баллы, полученные на экзамене, и цель состояла в том, чтобы максимизировать их. На все решения повлиял этот главный стимул. В видео с автомобилем на шоссе я определил вознаграждение таким образом, чтобы оно многократно увеличивалось всякий раз, когда машина поворачивает или ускоряется. Если же она попадает в аварию или замедляется, вознаграждение многократно уменьшается. Таким образом, задав определенные параметры, мы использовали в обучении агента фактор интуиции: чем успешнее автомобиль научится маневрировать на высоких скоростях без аварий или замедления, тем лучше (так же просто можно научить агента и безответственному вождению). Вот в чем сила понятия вознаграждения!
Состояние и история
Это еще два очень важных понятия, используемых в обучении с подкреплением. Всякий раз, взаимодействуя со средой, выполняя какую-то операцию (действие), агент наблюдает ответную реакцию этой среды, получая от нее вознаграждение. В случае экзамена, в зависимости от выбора глав для изучения, откликом среды будет определенное количество баллов. В ситуации с автомобилем, выполняющим замедление, ускорение, повороты, среда также отреагирует сигналами вознаграждения. Если же он врежется в другую машину, получит отрицательный отклик среды. Представим это, используя Ot для наблюдения в момент времени t. Теперь нужен способ отслеживать эти наблюдения, действия и вознаграждения, полученные на каждом этапе. Вот тут-то вступает в игру история — термин, обозначающий последовательность действий, вознаграждений и наблюдений до момента t.
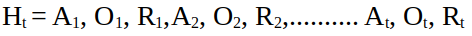
То, как агент будет взаимодействовать с окружающей средой, зависит от истории. Анализируя историю и основываясь на своих приоритетах, он принимает решение о каждом следующем действии. Очевидно, что фиксирование последовательности всех наблюдений, действий и вознаграждений — чрезвычайно трудоемкий и в принципе бесполезный процесс. Что нам нужно, так это краткое изложение истории. Она сообщит агенту все важные детали и не обременит лишними данными. Это именно то, что делает государство. Государство — это, по сути, просто функция истории.
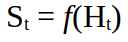
Для определения функции мы используем особое предположение, вытекающее из состояния цепи Маркова. Предположение заключается в следующем:

Это означает, что будущее состояние зависит не от прошлого, а от настоящего. Таким образом, учитывая нынешнее состояние, мы можем точно предсказать будущее, тем самым игнорируя историю. Вот насколько революционно предположение Маркова. Так, в примере с автомобилем не имеет значения, что произошло в прошлом. До тех пор, пока мы можем правильно анализировать текущую ситуацию, то есть положение и скорость синих автомобилей, мы в порядке (мы также можем рассматривать эту ситуацию как последовательную модель, но это уже другой вопрос).
Политика и значение функции
Политика функции — описание поведения агента, а значение (ценность) функции — это параметр, показывающий, насколько хорошо или плохо для агента находиться в определенном состоянии. Эти понятия помогают предсказать вознаграждение, которого агент может достичь, находясь в определенном состоянии.
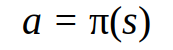
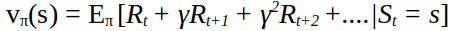
Эта формула помогает получить четкое представление о том, что такое значение функции. Она выражает ценность вознаграждений, которые мы можем получить в будущем с учетом определенной политики. Существует множество ее вариаций, которые могут использоваться различными способами. Однако основное ее назначение заключается в том, чтобы позволить оценить вознаграждения, которые мы надеемся получить в будущем. По сути, мы используем математические уравнения для предсказания будущего.
Заключение
Надеюсь, мой краткий обзор дал вам представление о роли интуиции в обучении с подкреплением. Это действительно замечательная концепция, которую можно использовать в робототехнике, играх, на фондовых рынках и многих других областях.
Читайте также:
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Anwesan De: The intuition behind Reinforcement Learning





