
Признаюсь, что сейчас на работе я занимаюсь разработкой на Python, в связи с чем вы можете счесть мое мнение предвзятым. И все же мне хочется развенчать некоторую критику в отношении Python и прояснить, стоит ли опасаться проблем со скоростью при повседневном использовании этого языка для обработки, исследования и анализа данных.
Реально ли Python слишком медленный?
С моей точки зрения подобные вопросы стоит задавать в рамках определенного контекста или случая применения. Действительно ли Python медленнее справляется с вычислением чисел, чем компилируемые языки вроде C? Да, так и есть. Причем данный факт известен давно, и именно поэтому библиотеки Python, для которых важна скорость, например NumPy, внутренне задействуют C.
Но во всех ли случаях Python медленнее других языков, которые, к слову, сложнее осваивать и использовать. Если рассмотреть бенчмарки производительности многих библиотек Python, оптимизированных под решение конкретной задачи, то по сравнению с компилируемыми языками справляются они вполне достойно. К примеру, взгляните на тест производительности FastAPI: очевидно, что Go, будучи компилируемым языком, оказывается намного быстрее Python. И все же FastAPI превосходит некоторые из библиотек Go при сборке REST API:
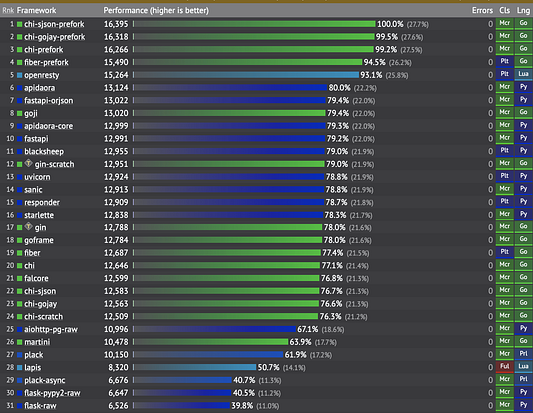
Сноска: в приведенный список не включены C++ и Java, которые демонстрируют еще большую производительность.
Аналогичным образом при сравнении Dask (написана на Python) со Spark (написана на Scala) для конвейеров нейровизуализации, работающих с большими данными, авторы сделали такой вывод.
В целом результаты не показывают существенной разницы производительности между этими движками.
По сути, нужно просто поставить вопрос: “Какая именно скорость нас фактически интересует?”. Если вы выполняете задачу ETL, которая запускается всего раз в день, то вас может вообще не волновать, выполнится ли она за 20 или 200 секунд. В таком случае вы можете предпочесть сделать код простым для понимания, упаковывания и обслуживания с учетом того, что вычислительные ресурсы становятся все более доступными по отношению к дорогостоящему времени разработки.
Вам быстрый или практичный код?
С практической точки зрения есть множество вопросов, которые стоит задать при выборе языка программирования для повседневной работы.
Можно ли с его помощью уверенно решать несколько бизнес-задач?
Если вас интересует лишь скорость, тогда не используйте Python и точка. Есть куда более производительные альтернативы для всевозможных случаев применения. Основные преимущества Python лежат в его читаемости, простоте использования и широком спектре решаемых с его помощью задач. Этот язык можно задействовать в качестве связующего компонента для огромного множества различных систем, сервисов и случаев использования.
Легко ли будет найти достаточное число знакомых с ним сотрудников?
Поскольку Python прост в освоении и применении, количество его пользователей постоянно растет. Бизнес-пользователи, которые ранее работали с числами в Excel, теперь могут быстро освоить программирование на Pandas и стать самодостаточными, избавившись от необходимости постоянно полагаться на ИТ-структуру компании. Это, в свою очередь, снизит нагрузку на департаменты ИТ и аналитики. Помимо прочего, таким образом сокращается время разработки и вывода продукта на рынок.
Сегодня гораздо проще найти инженеров знакомых с Python и способных обслуживать Spark-приложение по обработке данных на этом языке, чем тех, кто мог бы проделать то же самое на Java или Scala. Множество организаций постепенно переходят к реализации различных задач с помощью Python, просто потому что гораздо проще найти сотрудников, “говорящих” на этом языке.
В противоположность этому мне известны компании, которые отчаянно нуждаются в Java или C#-разработчиках, которые бы обслуживали существующие приложения. Однако на освоение этих языков уходят годы, в связи с чем они выглядят менее привлекательными для начинающих программистов, которые потенциально могут заработать больше на должностях, где требуется знание менее сложных языков, таких как Go или Python.
Синергия между экспертами из разных областей
Если ваша компания использует Python, то велики шансы, что тот же язык смогут применять бизнес-пользователи, аналитики/инженеры данных, бэкенд и фронтенд-разработчики, инженеры DevOps и даже системные администраторы. Это ведет к эффекту синергии в проектах, где люди из разных областей могут работать сообща и задействовать одни и те же инструменты.
Каковы истинные слабые места в обработке данных?
В своей работе я обычно сталкиваюсь с проблемными местами не в самом языке, а скорее во внешних ресурсах. Для пущей точности я просто приведу ряд примеров.
Запись в реляционные базы данных
При ETL-обработке данных в конечном итоге требуется загружать их в некое централизованное хранилище. И хотя можно задействовать многопоточность Python для ускорения записи данных в реляционную БД, скорее всего это приведет к тому, что увеличение числа параллельных процессов записи превысит ЦПУ-возможности этой базы данных.
На деле я сталкивалась с этим однажды, когда применяла многопоточность для ускорения записи в БД RDS Aurora на AWS. Тогда я заметила, что использование ЦПУ для узла записи настолько возросло, что мне пришлось намеренно замедлить код уменьшением числа потоков, чтобы не нарушить работу экземпляра БД.
Это означает, что в Python есть механизмы для распараллеливания и ускорения многих операций, но реляционная база данных (ограниченная по числу ядер ЦПУ) имеет предел возможностей, который не удастся преодолеть за счет более скоростного языка программирования.
Совершение вызовов к внешним API
Работа с внешними REST API, из которых вам может потребоваться извлечь данные для аналитики, является еще одним примером, где сам по себе язык не оказывается слабым местом. Мы, конечно, можем ускорить извлечение данных, задействовав параллелизм, но иногда это будет напрасным, так как многие внешние API ограничивают количество запросов, которые можно совершать за определенный промежуток времени.
Таким образом, вы зачастую будете оказываться в ситуации, когда приходится намеренно замедлять скрипт, обеспечивая тем самым соответствие установленному для API максимальному числу запросов:
time.sleep(10)
Работа с большими данными
Из своего опыта работы с огромными датасетами могу сказать, что, независимо от используемого языка, загружать действительно “большие данные” в память ноутбука не получится. Для подобных случаев вам скорее понадобится применять фреймворки распределенной обработки, такие как Dask, Spark, Ray и т.д. Существует лимит на количество данных, которые можно обработать при использовании одного экземпляра сервера на ноутбуке.
Если вы хотите распределить фактическую обработку данных на кластер вычислительных узлов, возможно даже задействовав инстансы GPU, которые могут дополнительно ускорить вычисления, то в Python есть обширная экосистема фреймворков, которые эту задачу упростят.
- Хотите ускорить вычисления при обработке данных, задействовав GPU? Используйте Pytorch, Tensorflow, Ray или Rapids (даже с SQL — BlazingSQL).
- Хотите ускорить код Python для обработки больших данных? Используйте Spark (или Databricks), Dask либо Prefect (который внутренне абстрагируется от Dask).
- Хотите ускорить обработку данных при аналитике? Используйте быстрые специализированные резидентные столбчатые базы данных, которые обеспечат высокую скорость обработки при простом использовании SQL-запросов.
Если же вам нужно оркестрировать и отслеживать обработку данных, происходящую в кластере вычислительных узлов, то есть несколько платформ управления рабочим потоком, написанных на Python, которые ускорят разработку и повысят обслуживаемость конвейеров обработки данных. В их число входят Apache Airflow, Perfect и Dagster.
Дополнительно отмечу, что многие, кто жалуются на Python, просто не задействуют все его возможности или применяют для решаемой задачи не самые подходящие структуры данных.
Обобщим. Если вы хотите быстро обрабатывать большие объемы данных, то вам скорее потребуется больше вычислительных ресурсов, чем более скоростной язык программирования. Причем существуют библиотеки Python, которые упрощают процесс распределения работы по сотням узлов.
Заключение
В этой статье мы ответили на вопрос “Действительно ли Python является слабым местом в текущем ландшафте обработки данных?”. Несмотря на то, что он реально медленнее многих компилируемых языков программирования, Python легок в использовании и очень разносторонен. Мы также отметили, что для многих практическая сторона языка берет верх над его производительностью.
В завершении было сказано о том, что как минимум при работе с данными слабым местом скорее явится не сам язык, а внешние системы и большой объем данных, который препятствует их обработке на одной машине, независимо от используемого языка программирования.
Читайте также:
- Как установить несколько версий Python в WSL2 и управлять ими
- Thonny - идеальная IDE для новичков Python
- 4 пайтонические техники для краткого кода
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Anna Geller: Is Python Really a Bottleneck?





