
Мы полагаемся на данные не только в принятии решений, но также и при ведении бизнеса в целом. Их потеря может привести к серьезным финансовым последствиям и падению репутации.
В этой статье вы познакомитесь с десятком действенных рекомендаций по защите наиболее ценных ресурсов.
1. Делайте резервные копии
Это самое очевидное действие. Нам необходима стратегия резервного сохранения информации и автоматизированный способ выполнения регулярных снимков баз данных.
Тем не менее при сегодняшних огромных объемах становится проблематичным реализовать надежный план резервного копирования, который позволит оперативно восстановить информационный ресурс. Следовательно важно разработать такую стратегию RPO и RTO, которая позволит бизнесу продолжать функционировать бесперебойно.
RPO и RTO
Целевая точка восстановления (RPO) описывает, сколько часов неработоспособности БД мы можем допустить. RPO со значением, например, 10 означала бы, что согласно плану бесперебойной работы бизнес может позволить не более 10 часов ???утраты данных???. RPO можно рассматривать как “устаревание” резервной копии плюс время на восстановление. При RPO = 10 мы допускам для данных устаревание на 10 часов до момента восстановления системы. Иначе говоря, они не будут содержать изменения, произошедшие за последние 10 часов.
В противоположность этому целевое время восстановления (RTO) описывает продолжительность, в течение которой база данных должна быть возвращена в строй. RTO со значением 3 означала бы, что независимо от свежести резервной копии работа базы данных должна быть восстановлена в течение трех часов после падения.
2. Тестируйте сценарий восстановления
Я приведу, пожалуй, наихудший сценарий: вы разработали стратегию резервного копирования и регулярно делаете снимки БД, но, когда происходит сбой, замечаете, что резервные копии не работают должным образом или вам просто не удается их найти. Поэтому очень важно тестировать сценарии восстановления.
Разработчики Netflix первыми применили “хаос-инжиниринг” — дисциплину тестирования сценариев сбоев в производственных системах, гарантируя таким образом устойчивость всей инфраструктуры.
Не рассчитывайте на резервные копии и планы по восстановлению, которые не тестировали. В противном случае вы можете попасть в ситуацию, когда вашей единственной стратегией будет скрести пальцы и уповать на лучшее.
Обратите внимание, если вы полагаетесь на копии, сделанные сторонним сервисом, в котором у вас нет реального доступа к снимкам, то есть риск, что восстановление БД выйдет за рамки критериев RTO и RPO. Возможно, что из-за разных часовых поясов и необходимости передачи объемного количества данных на большое расстояние восстановление продлится дольше, чем вы ожидали.
Чтобы этого избежать, рекомендуется делать снимки самостоятельно, а не просто полагаться на резервные копии стороннего провайдера.
3. Документируйте процессы, зависящие от этих данных (БД)
Если ваша БД упадет, на какие процессы это повлияет? Будет правильным решением держать эту информацию в задокументированном виде, чтобы компенсировать последствия сбоя и быстро восстановить работоспособность путем перезапуска соответствующих процессов.
4. Применяйте принцип “минимум привилегий”
Мы все хотим доверять людям, но предоставление чрезмерного доступа разработчикам без дополнительного инструктажа относительно правильного использования продакшн-ресурсов может сыграть во вред. Только несколько доверенных людей (из отдела DevOps или старших инженеров) должны иметь прямой доступ к изменению или удалению этих ресурсов. При создании ИТ-решений лучше всего работать в базе данных разработки, а для продакшн-ресурсов разрешать только чтение.
В добавок к этому, рекомендуется регулярно перепроверять эти разрешения. Может случиться, что кто-то из недавно покинувших компанию сотрудников по-прежнему имеет доступ к ресурсам продакшн-среды.
5. Называйте базы данных в продакшн среде соответственно
Что если ваша БД не проименована как ресурс prod, и кто-нибудь спутает ее с чем-либо еще? Лучше всего будет обозначить продакшн-ресурсы соответствующими именами. Так люди будут видеть, что к этим ресурсам нужно обращаться очень осторожно.
Для вас это может казаться очевидным, но без должного инструктажа и обучения пользователей, кто-нибудь может легко принять неточно проименованную производственную БД за простой временный ресурс (например, кластер песочницы), который можно отключить.
6. Не доверяйте ресурсам, настроенным вручную
Если ваши ресурсы настраиваются вручную, то в случае сбоя будет сложнее воспроизвести их конфигурацию. Современная культура DevOps и GitOps ввела очень полезную парадигму “Инфраструктура как код”, которая помогает создавать точную копию конкретного ресурса для сценариев разработки или восстановления.
7. Не позволяйте одному человеку управлять всей инфраструктурой
Может быть сложно восстановить любую конкретную систему, если единственный, кто знает, как ее настраивать и использовать, окажется на момент сбоя недоступен. Наличие “концентраторов знаний” очень рисково в подобных сценариях. Будет правильным предоставлять столь ответственную компетенцию как минимум еще одному сотруднику.
Зачастую даже различие в часовых поясах между локациями сотрудников может сыграть на руку для своевременного исправления сбоя продакшн-системы в соответствии с требованиями RTO.
8. Не предоставляйте сотрудникам доступ к ресурсам без предварительного обучения
Этот пункт имеет отношение к концентраторам знаний, но все же больше направлен на обучение разработчиков. Как только мы собираемся предоставить сотруднику доступ к ресурсу с возможностью записи, необходимо также научить его этот ресурс использовать, пояснив при этом возможные последствия выхода из строя даже одной таблицы.
Как обычно, лучше всего нам в этом поможет навык грамотной коммуникации.
9. Используйте бессерверные структуры и мониторьте свои ресурсы
Будет здорово использовать хранилища данных вроде AWS RDS, но есть в этом и свой минус. В конечном счете мы все равно должны обеспечить уверенную работоспособность нашей БД. При использовании бессерверных хранилищ, таких как DynamoDB, можно полагаться на экспертов AWS DevOps, которые будут вести мониторинг и поддерживать внутренние сервера.
Если вы задействуете платформу наблюдения, например Dashbird, то можете быстро выявлять в своей бессерверной инфраструктуре неверно настроенные ресурсы или сбои. В Dashbird недавно появилась функция Well-Architected-Lens, которая непрерывно сканирует ресурсы на предмет отклонений. К примеру, она сообщит о любой таблице DynamoDB, у которой не включено непрерывное резервное копирование и PTR. Это один из простейших способов обеспечить устойчивость и жизнеспособность БД, потому что:
- AWS берет на себе заботу о бессерверных вычислениях и хранилище сервиса, обеспечивая высокую доступность и устойчивость к сбоям.
- Dashbird предупредит вас, если архитектура отклонится от стандартов, определенных во фреймворке Well-Architected, например, когда ваши ресурсы окажутся неверно настроены, или в них будет отключено резервное копирование.
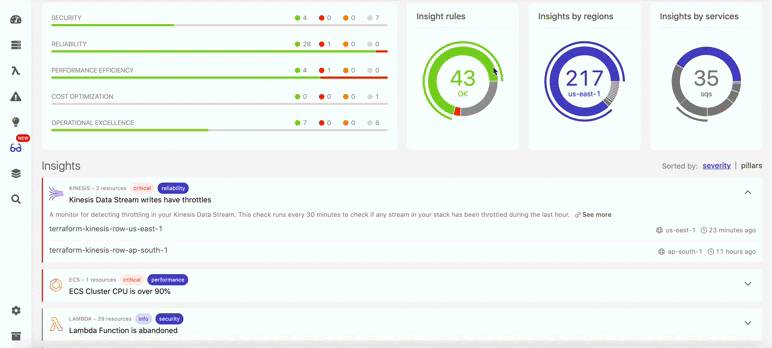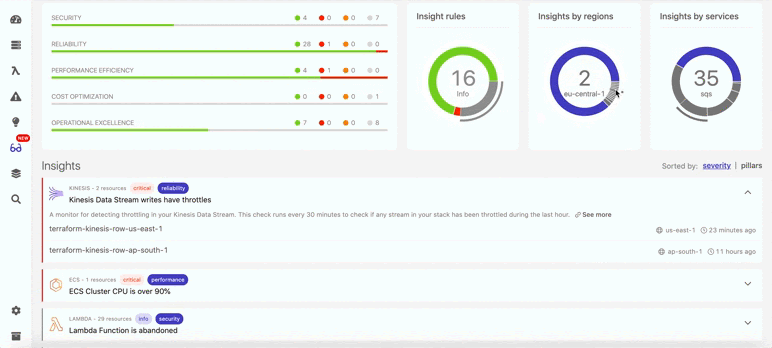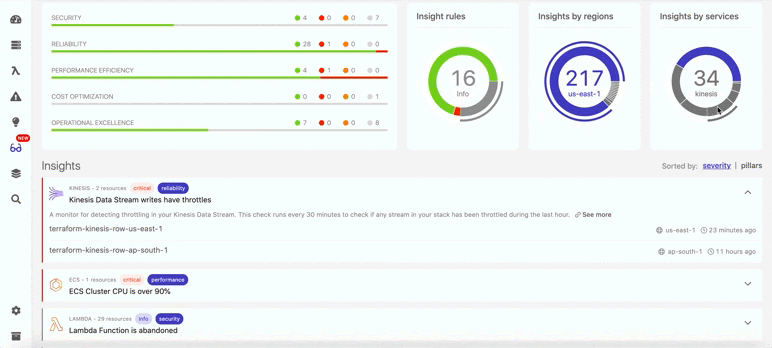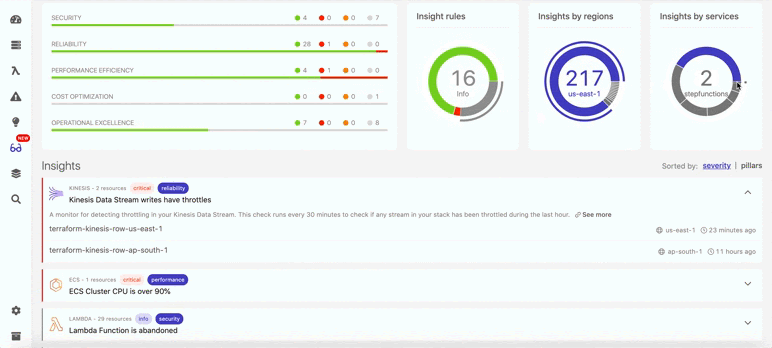
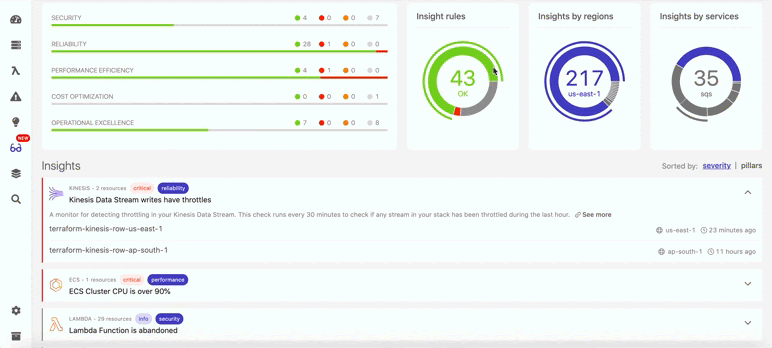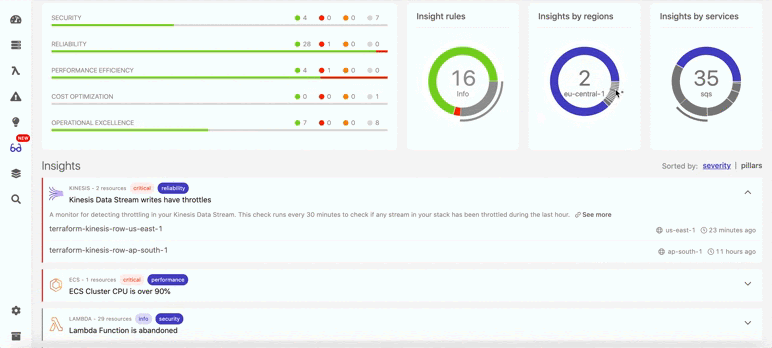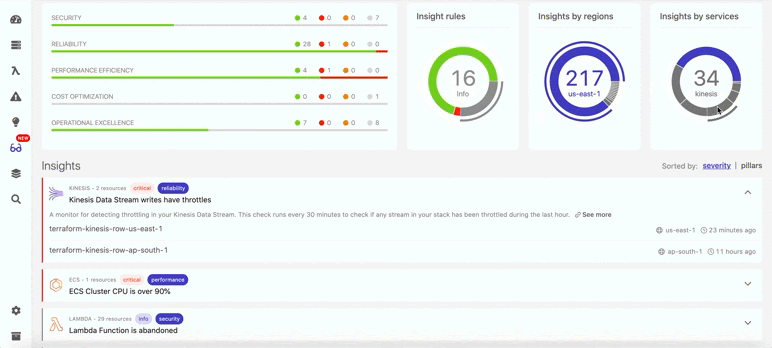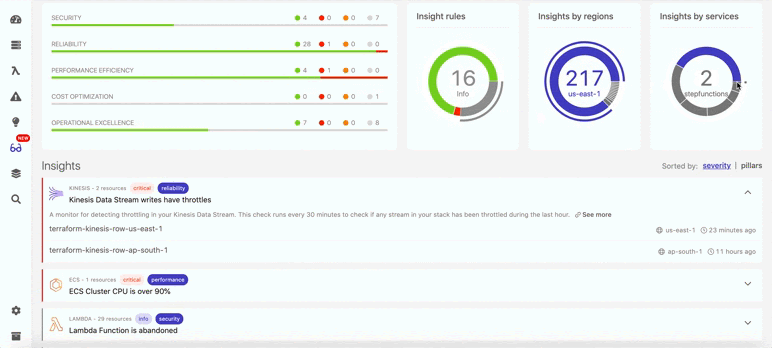
Так в Dashbird выглядит обнаружение отключенного резервного копирования:
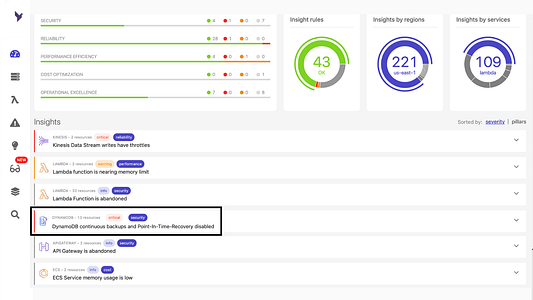
Ниже показано, что помимо восстановления данных, в Dashbird можно также найти и много другой информации о бессерверных ресурсах (см. ниже). Например, вы непременно получите уведомление, если в потоках данных возникнут задержки. В итоге система показывает общий балл, отражающий, насколько ваша архитектура соответствует фреймворку Well-Architected.
И если вы все еще не хотите переходить на DynamoDB, потому что предпочитаете использовать именно SQL, то можете рассмотреть PatriQL. Это язык запросов, разработанный AWS, который позволяет обращаться к таблицам DynamoDB (и многим другим хранилищам данных) прямо из консоли управления AWS:
10. По возможности отделите хранилище от вычислительной системы
Этот пункт касается аналитических баз данных. В их случае будет грамотным решением держать хранилище отдельно от вычислительной системы. Представьте, что ваши данные надежно хранятся в объектном хранилище, например в S3, и вы можете запрашивать их с помощью бессерверного механизма AWS Athena или Presto. Такое разделение между способом хранения данных и их обработкой упрощает обеспечение устойчивости вашей аналитической инфраструктуры.
Вы можете установить автоматическую репликацию между корзинами S3, активировать версионирование (что позволит восстанавливать удаленные ресурсы) или даже запретить перезапись и удаление чего-либо из S3 с помощью Object lock. В таком случае, даже если будет удалено определение таблицы Athena, данные сохранятся, и их можно будет легко запрашивать по определению схемы в AWS Glue.
Я всегда предпочитаю сначала сохранять свежеизвлеченные для ETL-задач данные в объектном хранилище и лишь затем загружаю их в какую-либо базу данных. Это позволяет использовать их в качестве подготовительной области или озера данных для большей устойчивости в аналитических конвейерах. Связи реляционных БД довольно хрупки. Представьте, что загружаете большой объем данных из какой-то системы прямо в хранилище, и тут незадолго до завершения ETL-процесса происходит сбой из-за принудительного закрытия соединения удаленным хостом по причине проблем с сетью. Повторение всего этапа извлечения может внести дополнительную нагрузку на систему источника или даже оказаться невозможным из-за ограничений количества запросов к API.
Заключение
В этой статье мы рассмотрели десять способов защитить жизненно важные хранилища данных. В современном мире информация является решающим ресурсом, утрата которого может очень негативно отразиться на финансовом состоянии и репутации. Старайтесь подойти к этому вопросу стратегически и тестировать реализуемые сценарии восстановления.
Читайте также:
- Почему Go прекрасно подходит для DevOps
- Kubernetes: безопасное управление секретами с GitOps
- Поиск и использование компонентов с bit.dev для создания приложений
Читайте нас в Telegram, VK и Яндекс.Дзен
Anna Anisienia: 10 Ways To Protect Your Mission-Critical Database





