
В данной статье мы вспомним основы, чтобы прояснить суть ряда операций при работе с узлами кластера.
Тестовый кластер
Рассмотрим только что созданный кластер kubeadm, состоящий из одного мастера (ведущего узла) и двух рабочих узлов:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-1 Ready control-plane,master 18m v1.20.0
k8s-2 Ready <none> 18m v1.20.0
k8s-3 Ready <none> 18m v1.20.0Сначала установим панель-наблюдатель за пространством кластеров Kubernetes Operational View (иначе kube-ops-view). Это приложение позволяет просматривать сразу все выполняющиеся в кластере поды. На текущий момент у нас их 14:
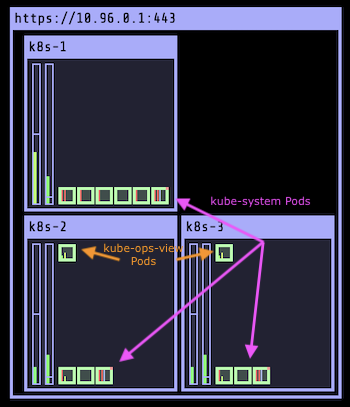
- Два из них расположены в пространстве имен
defaultи связаны с kube-ops-view. На нижеприведенном скриншоте они отображены в верхних левых углах k8s-2 и k8s-3. - 12 других — в пространствах имен
kube-system: kube-api-server, etcd, kube-controller-manager, kube-scheduler, kube-proxy (x3), weave-net (x3), core-dns (x2).
Создадим развертывание 4 реплик с помощью образа ghost (Ghost — это блог-платформа с открытым исходным кодом):
$ kubectl create deploy ghost --image=ghost --replicas 4
Как видно на kube-ops-view, на k8s-2 и k8s-3 развертываются 4 новых пода, обозначенных красным цветом (в каждом узле по 2 реплики):
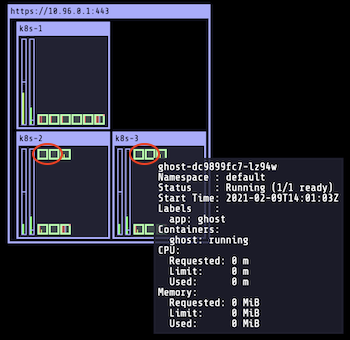
И следующая команда поможет в этом убедиться:
$ k get po -l app=ghost \
-o custom-columns=NAME:.metadata.name,NODE:.spec.nodeName
NAME NODE
ghost-dc9899fc7-9254f k8s-3
ghost-dc9899fc7-946ck k8s-2
ghost-dc9899fc7-lz94w k8s-3
ghost-dc9899fc7-vsnqn k8s-2Ни один из подов ghost не был развернут на k8s-1 (ведущем узле), и тому есть объяснение.
Ограничения
По умолчанию для k8s-1 есть ограничение, добавленное к нему kubeadm во время настройки кластера. По сути, это объект, представляющий пару ключ-значение, где значение выражает его эффект. Следующая команда показывает ограничение, существующее в k8s-1:
$ kubectl describe node k8s-1 | grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
- Ключ —
node-role.kubernetes.io/master - Эффект —
NoSchedule.
Когда на узел устанавливается ограничение, оно препятствует развертыванию на нем пода. Это свойство можно сравнить с плохим запахом: под не приблизится к узлу, пока в спецификации не будет определена толерантность с такой же парой “ключ-значение”, как и у самого ограничения. В нашем случае определенные поды ghost не соответствуют указанному ограничению, поэтому развернуть их на k8s-1 нельзя.
Примечание: чтобы сделать под толерантным к ограничению, нужно указать в его спецификации соответствующую запись tolerations:
...
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoScheduleУдалим ограничение, обеспечивая возможность развертывания подов приложения на k8s-1. Этот шаг допустим в нашем примере, но в случае с реальным кластером можно обойтись и без этого, используя свойство tolerations в спецификации подов, явно подлежащих развертыванию на ведущем узле.
$ kubectl taint node k8s-1 node-role.kubernetes.io/master-
Удаление ограничений не приводит к повторному развертыванию имеющихся подов. Наоборот, для этого требуется принудительная команда с нашей стороны:
$ kubectl rollout restart deploy/ghost
Теперь видно, что произошло перераспределение 4 подов. На этот раз планировщик принял во внимание 3 узла, поскольку у мастера уже нет никакого ограничения.
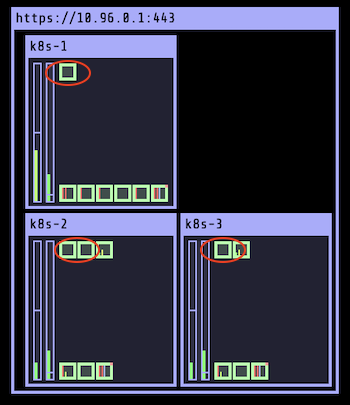
$ kubectl get po -l app=ghost \
-o custom-columns=NAME:.metadata.name,NODE:.spec.nodeName
NAME NODE
ghost-7564b56ff4-26nth k8s-3
ghost-7564b56ff4-h2pm4 k8s-2
ghost-7564b56ff4-m72c5 k8s-2
ghost-7564b56ff4-vd6nv k8s-1Команды Cordon/Uncordon (блокировка/разблокировка)
В некоторых случаях требуется остановить распределение дополнительных подов, не удаляя уже работающие в нем. С этой целью можно заблокировать узел. С помощью следующей команды сделаем это для k8s-2:
$ kubectl cordon k8s-2
На этом этапе текущие поды продолжают работу в данном узле, а вот новые добавить уже нельзя. Обзор всех узлов кластера позволяет увидеть, что k8s-2 отмечен флагом SchedulingDisabled:
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-1 Ready control-plane,master 25m v1.20.0
k8s-2 Ready,SchedulingDisabled <none> 25m v1.20.0
k8s-3 Ready <none> 25m v1.20.0Увеличим число реплик и посмотрим, на какие узлы распределяются новые поды:
$ kubectl scale deploy/ghost --replicas=8
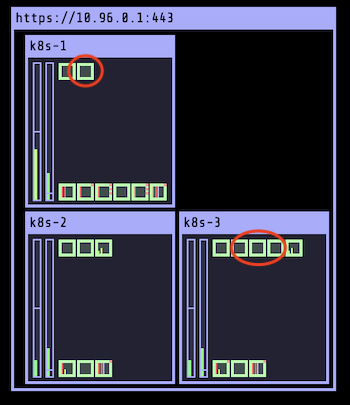
Как и ожидалось, число подов на k8s-2 осталось неизменным. Можно вернуть узел в прежнее состояние с помощью такой команды, как:
$ kubectl uncordon k8s-2
Теперь k8s-2 может принимать дополнительные поды, поскольку запрет на присвоение для него был снят.
Команда Drain
Иногда требуется удалить текущие поды, выполняющиеся на конкретном узле, и перераспределить их по другим узлам кластера. Как правило, это актуально при выполнении на узле операции обслуживания.
Для этого применим команду drain в отношении k8s-3, как показано ниже:
$ kubectl drain --ignore-daemonsets k8s-3
Примечание: при очистке узла от подов нельзя удалять те из них, которыми управляет DaemonSet, например kube-proxy, weave-net и т. д. Выполняя команду drain, важно явно указать на необходимость игнорировать поды DaemonSet с помощью флага ignore-daemonsets.
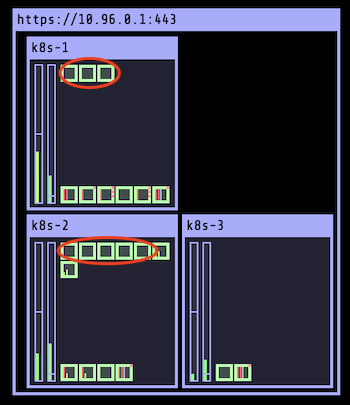
Исходя из нижеследующего примера, процесс очистки узла также препятствует распределению на него новых подов: на данный момент k8s-3 заблокирован.
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-1 Ready control-plane,master 30m v1.20.0
k8s-2 Ready <none> 30m v1.20.0
k8s-3 Ready,SchedulingDisabled <none> 30m v1.20.0Для того, чтобы возобновить распределение подов на этот узел, его нужно разблокировать.
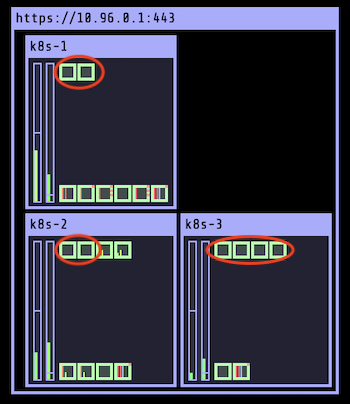
$ kubectl uncordon k8s-3$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-1 Ready control-plane,master 22h v1.20.0
k8s-2 Ready <none> 22h v1.20.0
k8s-3 Ready <none> 22h v1.20.0Как и раньше, необходимо принудительно перезапустить развертывание по команде для восстановления пода и перераспределения его по узлу кластера:
$ kubectl rollout restart deploy/ghost
Заключение
В данной статье были рассмотрены часто используемые команды при работе с узлами и подготовке их к обслуживанию. Кратко была затронута тема ограничений, свойств, обуславливающих процесс распределения подов по узлам.
В спецификации пода доступен еще ряд свойств для более тонкой настройки этапа распределения (nodeSelector, nodeAffinity, podAffinity и podAntiAffinity).
Читайте также:
- Kubernetes: преимущества простых кластеров
- Kubernetes избавляется от Docker
- Airflow и Kubernetes - лучшее решение для конвейеров данных Geoblink
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Luc Juggery: K8s Tips: Playing With Nodes





