
Паттерны регулярных выражений (ReGex) выглядят как какая-то ерунда и все же являются мощным инструментом для извлечения информации из текста. Куча, казалось бы, случайных знаков препинания в сочетании с большим количеством скобок и парочкой букв на самом деле способна найти необходимую вам информацию.
На примере посмотрим, как можно извлечь информацию о стоимости и наименовании расходов из текстового файла. Он, конечно, не самый простой, но мы рассмотрим несколько разных функций регулярных выражений, которые помогут справиться с этой задачей. Предполагается, что вы уже имеете базовые знания о регулярных выражениях.
Для демонстрации я буду использовать Python и его специализированную библиотеку для регулярных выражений re, чтобы загрузить файл .txt и найти в нем наименование и стоимость всех расходов.
Образец текста представляет собой простой список следующего формата:
стоимость — наименование
стоимость — наименование
стоимость — наименование
стоимость — наименование
стоимость — наименование
Итого: total_costНапример:
0.70 — Кофе
0,75 — Кусочек торта
12 — Обед
15 — Обед
Итого: 28,45В этом примере нам потребовалось бы извлечь информацию из четырех строк списка расходов, игнорируя итоговую сумму (впоследствии ее без проблем можно вычислить).
Теперь рассмотрим отдельно каждую часть паттерна и в конце соберем их все вместе в финальный паттерн регулярных выражений, реализованный на Python.
Получение целых чисел
Как видно из примера, стоимость расходов может состоять из целого числа (два обеда) или это может быть число с плавающей запятой (кофе и кусок торта). Приведенный ниже паттерн соответствует стоимости, состоящей из целочисленной стоимости:
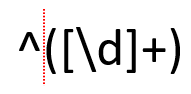
Красная пунктирная линия поставлена только для наглядного разделения частей паттерна.
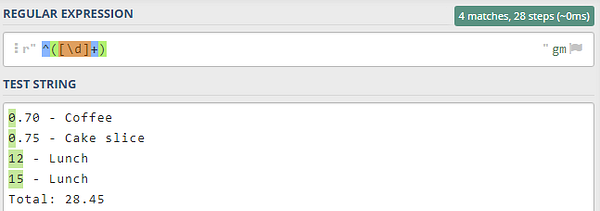
Карет (^) обозначает начало строки, то есть какой бы текст мы не сопоставляли, символ должен находиться в начале строки. Символ \d, заключенный в квадратные скобки, означает, что мы сопоставляем цифры (от 0 до 9), а + используется для сопоставления одной или нескольких цифр. Без знака + паттерн соответствовал бы только единице из стоимости первого обеда, а не его правильной стоимости — 12.
На следующих изображениях показан результат (не) использования квантификатора +. Все паттерны я тестирую на сайте regex101.com:
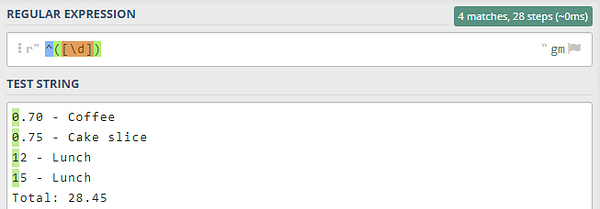
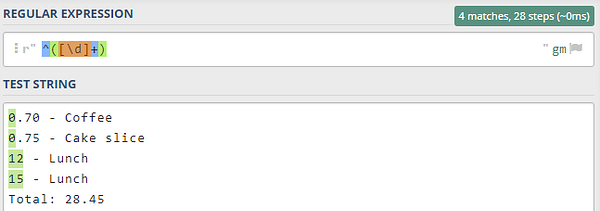
Что касается квадратных и круглых скобок, то первый тип используется для применения правила знака плюс “сопоставить одну или несколько цифр” к цифрам. Второй же используется для создания правильной группы регулярных выражений. Проще говоря, на группы можно ссылаться отдельно для каждого соответствия. Но к этой теме вернемся в конце, когда будем рассматривать скрипты Python.
Улучшение паттерна стоимости
Предыдущий паттерн работал для целочисленной стоимости. Однако существуют также числа с плавающей запятой. Нам нужно расширить возможности паттерна, чтобы в нем учитывались оба варианта:
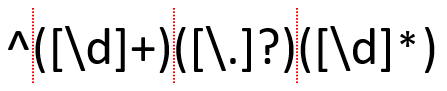
Можно скопировать предыдущий паттерн, поскольку мы все еще сопоставляем последовательности цифр. Поместим его в начало второго паттерна, но на данном этапе будем сопоставлять только цифры перед десятичной точкой.
Целое число — это последовательность из одной или нескольких цифр. С другой стороны, число с плавающей запятой имеет две таких последовательности, разделенные десятичной точкой (.). Таким образом, можно повторить эту группу целочисленных соответствий, [\d]+, чтобы соответствовать целочисленной и десятичной частям числа с плавающей запятой. Необходимо только добавить группу в середину паттерна, чтобы он соответствовал и десятичной точке.
Следовательно, будем использовать [\.]?. Все, что находится внутри квадратных скобок, будет сопоставлено буквально, но поскольку точка имеет особое значение в регулярных выражениях, нам придется добавить к ней префикс \ (обратную косую черту) указывая, что необходимо сопоставить фактический период между последовательностями цифр. В противном случае точка будет использоваться для сопоставления любого найденного символа.
Обратите внимание, что мы также изменили квантификатор во второй последовательности цифр с + на *, потому что теперь нам нужно использовать правило “сопоставить ноль или более цифр”. Если бы стоимость одного из обедов была менее 10, то мы не смогли бы сопоставить это однозначное целое число с двумя “сопоставить одну или несколько цифр” (одна до десятичной точки, а другая после).
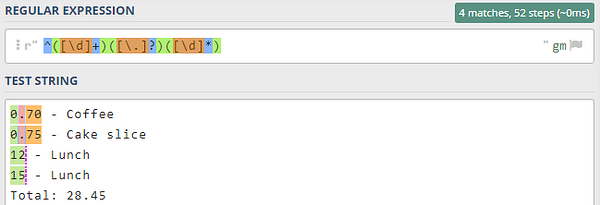
Теперь все значения стоимости успешно сопоставлены. Цвета затрудняют понимание того, что вся стоимость соответствует каждому наименованию, но когда мы реализуем паттерн в Python, мы увидим, что фактически сопоставляем всю стоимость. Поскольку мы группируем части паттерна с помощью круглых скобок, мы сопоставляем всю стоимость, а также имеем доступ к отдельным группам соответствия.
Получение наименования расходов
Со стоимостью разобрались, самая трудная часть позади. Теперь необходимо просто сопоставить остальные данные в соответствующей строке, то есть дефис, разделяющий стоимость и наименование, а также само наименование.
Давайте вспомним, как выглядит одна строка из списка расходов:
0.70 — Кофе
То есть за стоимостью следует пробел, затем дефис, затем еще один пробел и, наконец, само наименование, которое представляет собой последовательность символов (букв, цифр, пробелов и т. д.).
Затем можно создать две простые группы для этого паттерна: одну, которая соответствует дефису и пробелам вокруг него, и вторую, соответствующую наименованию. Поскольку наименование может состоять из символов различного типа, на этот раз мы используем возможности точки, то есть добавляем ее, чтобы она соответствовала любому символу. Опять же, звездочка соответствует нулю или более символов в последовательности:
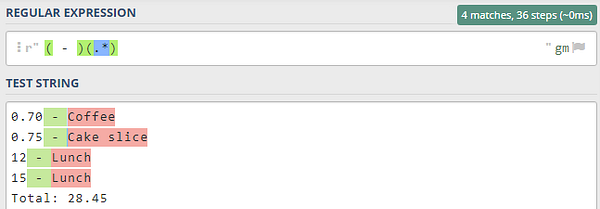
Ни дефис, ни окружающие его пробелы не являются частью расходов как таковых, но они являются важнейшими текстовыми обозначениями для сопоставления расходов.
Собираем паттерн полностью
Теперь, когда мы разобрали каждую часть паттерна по отдельности, пора взглянуть на финальный паттерн и скрипт Python, который его реализует:
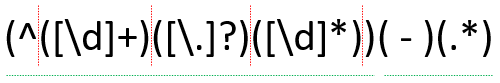
Зеленое подчеркивание используется только для визуального разделения паттернов стоимости и наименования.
Здесь нет ничего нового — просто те же паттерны, которые вы видели раньше, на этот раз собранные в единый паттерн:
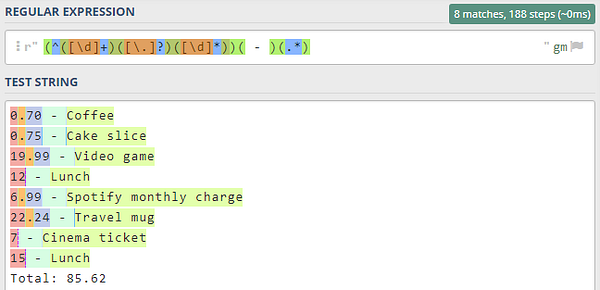
Теперь перейдем к коду Python!
Для начала посмотрим на образец текста:
0.70 - кофе
0.75 - кусок торта
19.99 - видеоигра
12 - обед
6.99 - ежемесячная оплата подписки на Spotify
22.24 - термокружка
7 - билет в кино
15 - обед
Итого: 85.62А теперь напишем скрипт!
import re
import datetime
import pandas as pd
PATTERN = r'(^([\d]+)([\.]?)([\d]*))( - )(.*)'
# Загрузить текст
with open("expenses.txt", "r") as f:
expenses_txt = f.readlines()
# Соединить все строки в одну
whole_txt = "".join(expenses_txt)
# Найти все сопоставления расходов
matches = re.findall(PATTERN, whole_txt, flags=re.MULTILINE)
# Извлечь необходимую информацию сопоставления
expenses = [ [m[5], m[0]] for m in matches ]
# Создать датафрейм для расходов
df = pd.DataFrame(data=expenses)
# Указать новый индекс, чтобы получить еще один столбец
df.reset_index(inplace=True)
# Переименовать столбцы
df.columns = ["ExpenseID", "Name", "Cost"]
# Увеличить все ID, чтобы они начинались с 1
df["ExpenseID"] += 1
# Экспортировать как CSV
df.to_csv("expenses.csv", index=False)В этом скрипте мы загружаем текст из файла .txt, затем, путем сопоставления шаблона регулярного выражения, извлекаем расходы и сохраняем данные в датафрейме pandas, который экспортируется в формате CSV.
Функции достаточно простые, но давайте взглянем на них поближе:
1. f.readlines() получает весь текст из файла в виде списка строк (строка для каждой строки текста).
2. "".join(expenses_text)создает одну строку из различных строк текста (строки включают символы новой строки, поэтому мы все еще знаем, где начинается и заканчивается каждая строка).
3. re.findall сопоставляет расходы, используя созданный нами паттерн.
4. re.MULTILINE гарантирует, что мы получим каждое сопоставление, а не только первое.
5. [[m[5], m[0]] for m in matches] создает список списков, где внутренние списки содержат наименование и стоимость расходов.
6. Раздел pandas создает новый датафрейм, используя этот список списков, добавляет столбец индекса, начинающийся с единицы, и экспортирует его в виде нового CSV-файла.
Наконец мы добрались и до групп регулярных выражений. Если выводить отдельные соответствия, возвращенные методом re.findall, выясняется, что функция возвращает кортеж для каждого соответствия:
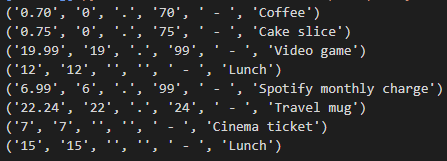
Каждый элемент кортежа представляет собой группу паттернов. Другими словами, для каждого наименования расходов имеется доступ ко всей стоимости, целой части, десятичной точке, части с плавающей запятой, дефису и окружающим его пробелам, а также к наименованию расходов. Нам нужны только первая и последняя группы, но полезно иметь доступ к различным частям соответствия без дальнейших преобразований строк.
Заключение
В приведенном выше примере нам удалось создать следующий CSV-файл, имея на старте лишь текстовый файл:

Как я уже говорил в начале, это упражнение простое, но дает хорошую практику регулярных выражений.
Напоследок, я хотел бы посоветовать вам regex101.com, этот ресурс отлично подходит для написания и тестов паттернов, а также чит-лист регулярных выражений Python на Debuggex.
Читайте также:
- Когда ИИ или машинное обучение неуместны
- 4 шага к совершенству: правила для идеальных функций
- 25 наборов аудиоданных для исследований
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи José Fernando Costa: Using RegEx to extract expenses information from a text file





