
Необходимость детального исследования данных МО становится все более очевидной. Однако в компьютерном зрении оно до сих пор не получило широкого распространения, поскольку анализ больших наборов данных требует значительных трудозатрат. Тем не менее невозможно получить полное представление о наборе данных, просто просматривая изображения.
Особенно трудно это сделать в области обнаружения объектов (Object Detection) — технологии компьютерного зрения, определяющей местоположение объектов на изображении путем установления ограничивающей рамки (bounding box). Обнаружение объектов — это не просто их распознавание. Это также понимание их контекста, размера и взаимосвязи с другими элементами сцены. Поэтому точное представление о распределении классов, разнообразии размеров объектов и общих контекстах, в которых появляются классы, помогает при оценке и отладке найти закономерности ошибок в обученной модели. В результате выбор дополнительных обучающих данных становится более целенаправленным.
Мы предлагаем следующие подходы:
- Обогащение изучаемых наборов данных структурой из предварительно обученных или базовых моделей. Например, можно создавать эмбеддинги изображений и применять методы уменьшения размерности, такие как t-SNE и UMAP. Они способны генерировать карты сходства, облегчая навигацию по данным. Кроме того, с помощью алгоритмов обнаружения в предварительно обученных моделях можно извлекать контекст.
- Использование инструмента визуализации, способного интегрировать эту структуру со статистикой и функцией обзора исходных данных.
В этой статье представлено руководство по созданию интерактивной визуализации для обнаружения объектов с помощью Renumics Spotlight. Вы узнаете:
- как создать визуализацию для обнаружения людей на изображениях;
- как с помощью визуализации получить карту сходства, фильтры и статистику для навигации по данным;
- как визуализация позволяет детально рассмотреть каждое изображение с эталонными данными и результат работы Ultralytics YOLOv8.
Загрузка изображений с людьми из набора данных COCO
Сначала установим необходимые пакеты:!pip install fiftyone ultralytics renumics-spotlight
Функция возобновляемой загрузки FiftyOne позволит загрузить изображения из набора данных COCO с необходимыми параметрами, включив только 1000 изображений, содержащих одного или нескольких человек:
import pandas as pd
import numpy as np
import fiftyone.zoo as foz
# загрузка 1000 изображений с людьми из датасета COCO
dataset = foz.load_zoo_dataset(
"coco-2017",
split="validation",
label_types=[
"detections",
],
classes=["person"],
max_samples=1000,
dataset_name="coco-2017-person-1k-validations",
)Теперь можно использовать этот код:
def xywh_to_xyxyn(bbox):
"""convert from xywh to xyxyn format"""
return [bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]]
row = []
for i, sample in enumerate(dataset):
labels = [detection.label for detection in sample.ground_truth.detections]
bboxs = [
xywh_to_xyxyn(detection.bounding_box)
for detection in sample.ground_truth.detections
]
bboxs_persons = [bbox for bbox, label in zip(bboxs, labels) if label == "person"]
row.append([sample.filepath, labels, bboxs, bboxs_persons])
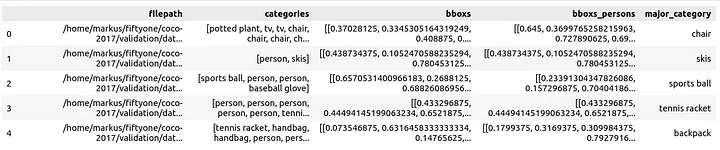
df = pd.DataFrame(row, columns=["filepath", "categories", "bboxs", "bboxs_persons"])
df["major_category"] = df["categories"].apply(
lambda x: max(set(x) - set(["person"]), key=x.count)
if len(set(x)) > 1
else "only person"
)Он позволит подготовить DataFrame Pandas со следующими столбцами:
- filepath (путь к файлу);
- categories (категории ограничительных рамок);
- bboxes (ограничительные рамки);
- bboxes_persons (ограничительные рамки, включающие людей);
- major_category (основная категория, помогающая понять контекст людей на изображениях).
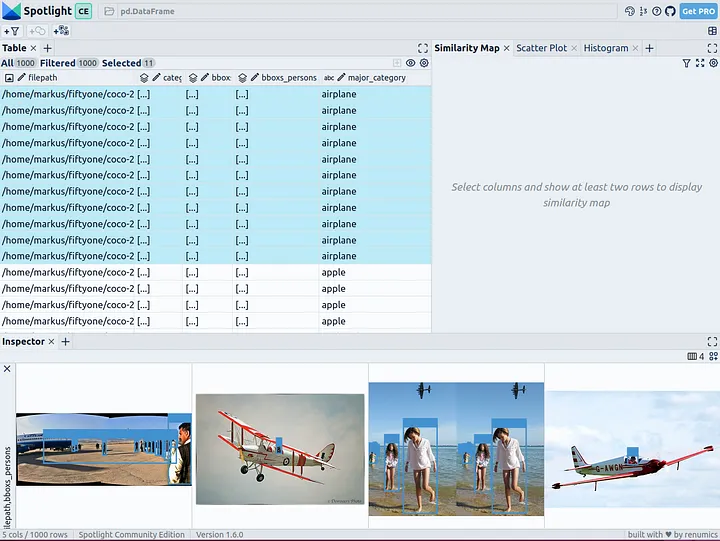
Теперь можно визуализировать этот датафрейм с помощью Spotlight:
from renumics import spotlight
spotlight.show(df)Можете использовать кнопку “add view” (“добавление представления”) в inspector view и выбрать bboxs_persons вместе с filepath в представлении BoundingBox, чтобы отобразить соответствующие ограничительные рамки с изображениями:
Обогащение данных с помощью эмбеддингов
Для обогащения данных структурой будем использовать эмбеддинги изображений (плотные векторные представления) из базовых моделей. ViT-эмбеддинги можно применять ко всему изображению для структурирования набора данных с использованием дальнейших методов уменьшения размерности, таких как UMAP и t-SNE, чтобы получить 2D-карту сходства изображений. Для структурирования данных по размеру или количеству содержащихся объектов можно также использовать результаты предварительно обученного детектора объектов. Кроме того, использование результатов работы предварительно обученного детектора объектов поможет классифицировать данные на основе размера или количества обнаруженных объектов. Поскольку набор данных COCO уже содержит эту информацию, используем ее напрямую.
В Spotlight встроена поддержка модели ViT и UMAP.
- ViT (Vision Transformer) — трансформер, предназначенный для обработки визуальных данных.
- UMAP (Uniform Manifold Approximation and Projection) — алгоритм МО, выполняющий нелинейное снижение размерности.
Эта поддержка включается автоматически при использовании пути к файлу для создания эмбеддингов:
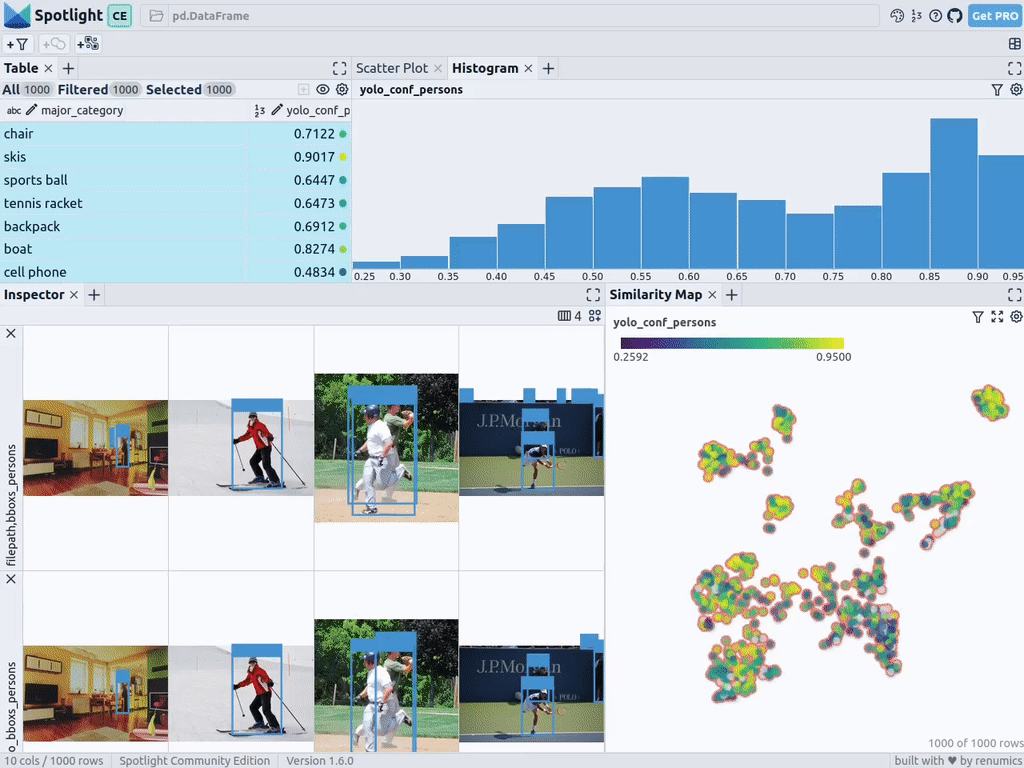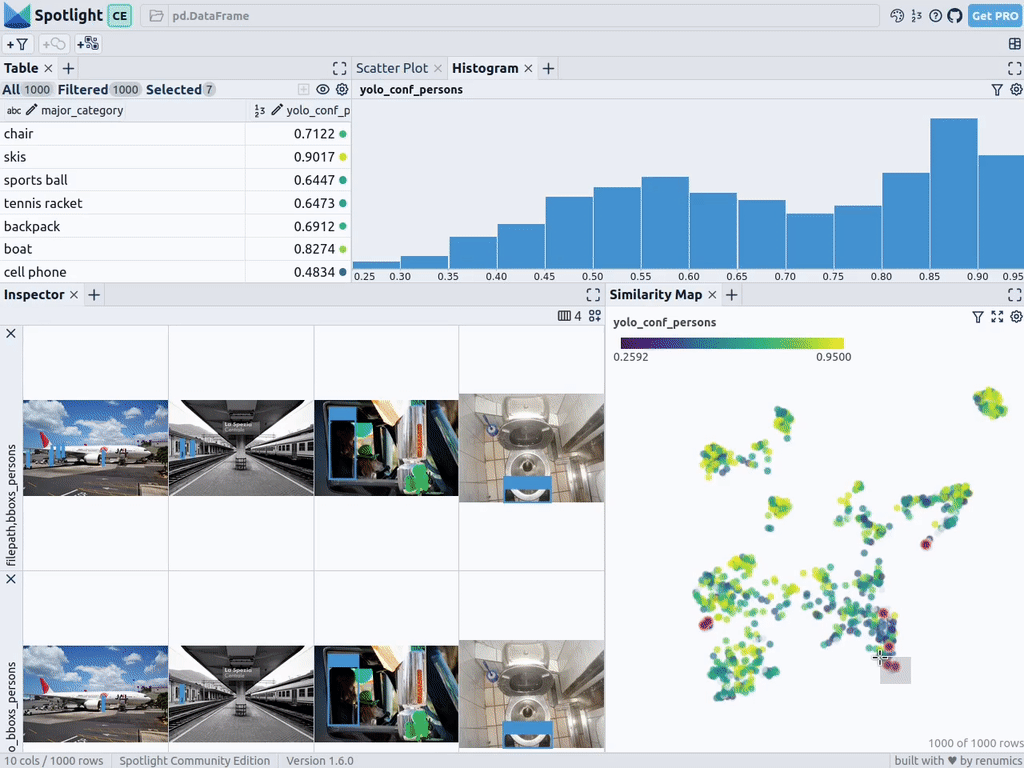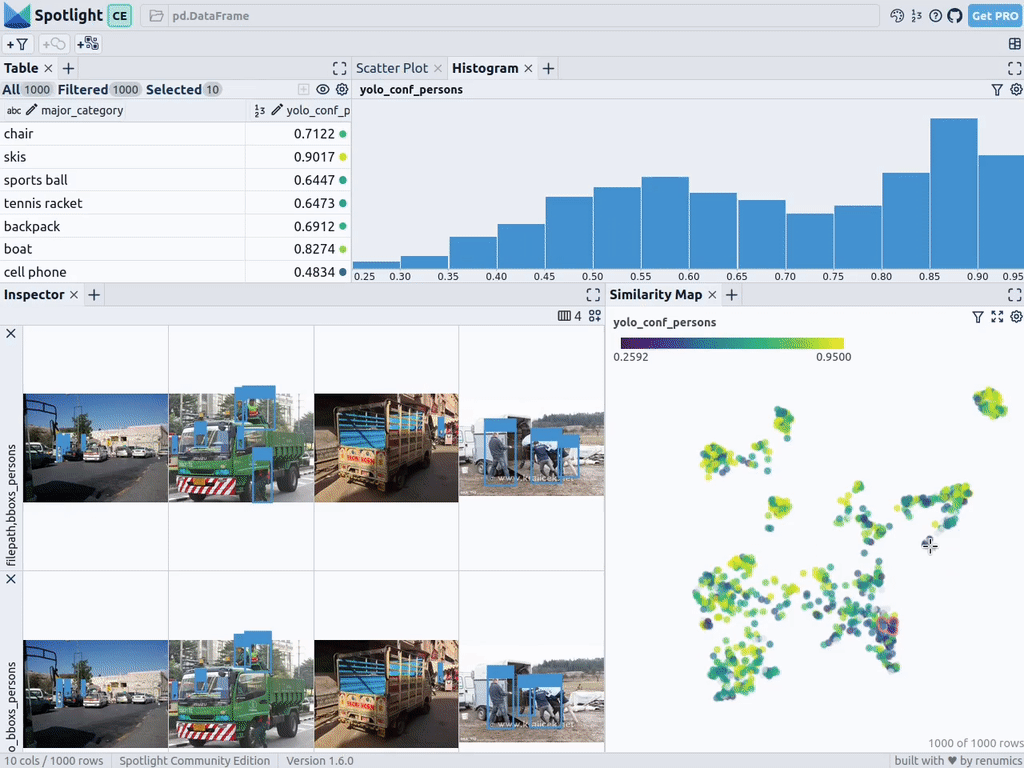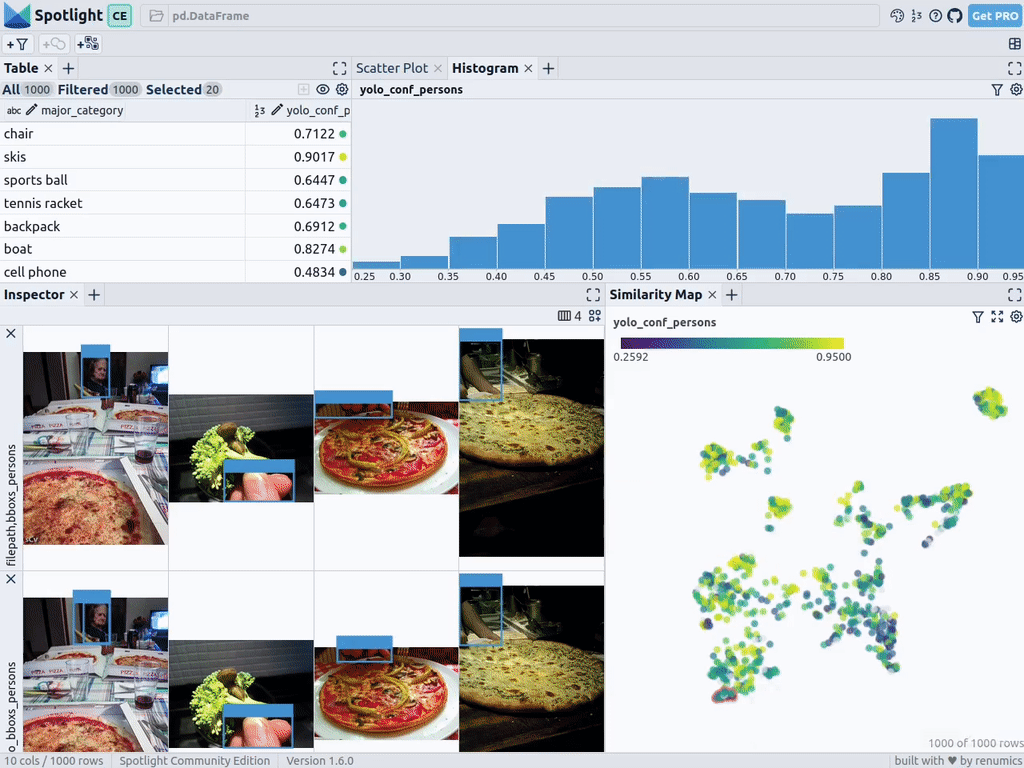
spotlight.show(df, embed=["filepath"])Spotlight вычислит эмбеддинги и применит UMAP, чтобы показать результат на карте сходства. Цветом кодируется основная категория. Теперь можно использовать карту сходства для навигации по данным:

Результаты предварительно обученной модели YOLOv8
Ultralytics YOLOv8 — это современная модель обнаружения объектов для их быстрой идентификации. Она предназначена для оперативной обработки изображений и подходит для задач обнаружения в реальном времени, а также может применяться к большому количеству данных без длительного ожидания.
Начнем с загрузки предварительно обученной модели:
from ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")Выполним обнаружения (detections):
detections = []
for filepath in df["filepath"].tolist():
detection = detection_model(filepath)[0]
detections.append(
{
"yolo_bboxs": [np.array(box.xyxyn.tolist())[0] for box in detection.boxes],
"yolo_conf_persons": np.mean([
np.array(box.conf.tolist())[0]
for box in detection.boxes
if detection.names[int(box.cls)] == "person"
]),
"yolo_bboxs_persons": [
np.array(box.xyxyn.tolist())[0]
for box in detection.boxes
if detection.names[int(box.cls)] == "person"
],
"yolo_categories": np.array(
[np.array(detection.names[int(box.cls)]) for box in detection.boxes]
),
}
)
df_yolo = pd.DataFrame(detections)На GeForce RTX 4070 Ti с 12 ГБ этот процесс занимает менее 20 секунд. Теперь можно включить результаты в датафрейм и визуализировать их с помощью Spotlight:
df_merged = pd.concat([df, df_yolo], axis=1)
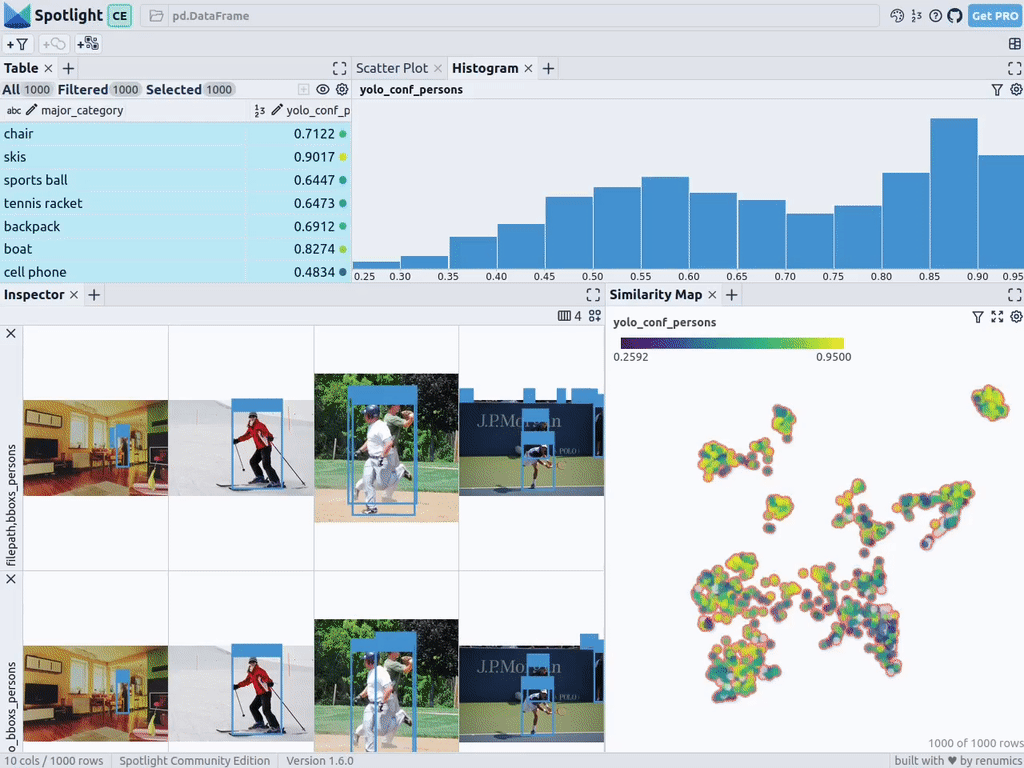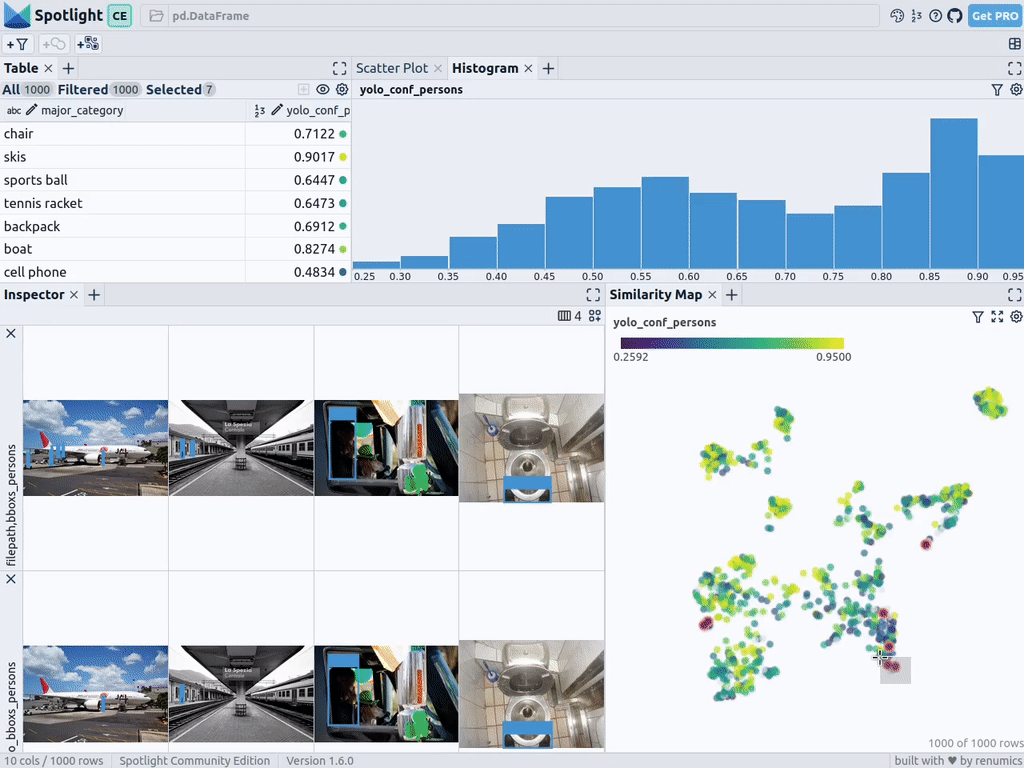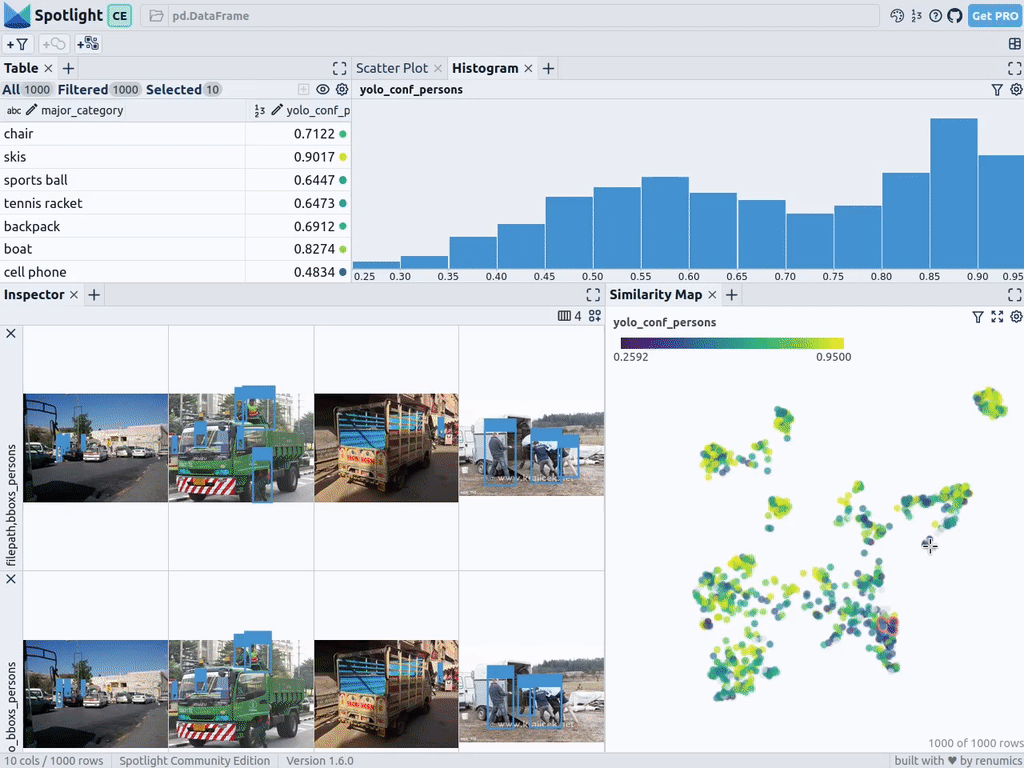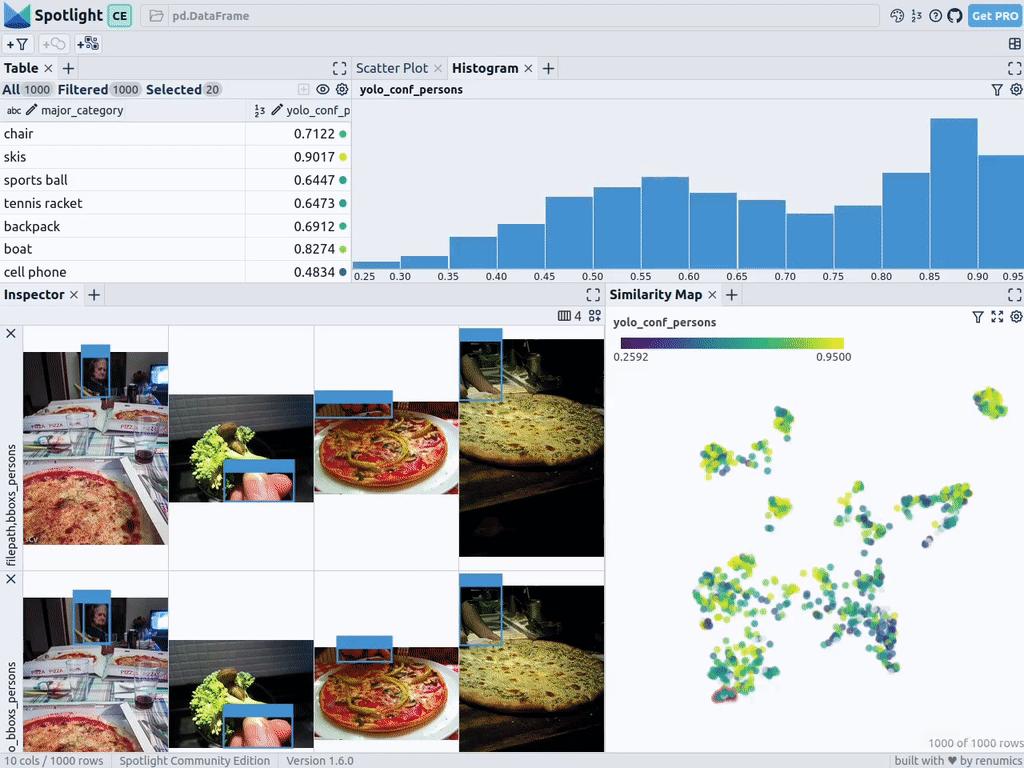
spotlight.show(df_merged, embed=["filepath"])Spotlight снова вычислит эмбеддинги и применит UMAP, чтобы отобразить результат на карте сходства. Но на этот раз можно выбрать уровень доверия к модели для обнаруженных объектов и использовать карту сходства для навигации по кластерам с низким уровнем доверия. Вот изображения, в которых модель не уверена, и в целом похожие изображения.
Этот краткий анализ показывает, что модель сталкивается с систематическими проблемами при работе с изображениями в следующих кластерах:
- Поезда с людьми, стоящими снаружи; люди кажутся очень маленькими из-за большого размера поезда.
- Автобусы и другие большие транспортные средства, внутри которых люди едва видны.
- Самолеты с людьми, стоящими снаружи.
- Изображения еды крупным планом, на которых видны только руки или пальцы людей.
Вам нужно решить, действительно ли эти проблемы влияют на ваши задачи по обнаружению людей. Если да, то рассмотрите возможность расширения набора данных с помощью дополнительных обучающих данных, чтобы оптимизировать работу модели в этих конкретных сценариях.
Читайте также:
- Когда ИИ или машинное обучение неуместны
- Большой языковой модели недостаточно: пример использования Merkle Genai. Часть 2
- Почему стоит упрощать проекты МО
Читайте нас в Telegram, VK и Дзен
Перевод статьи Markus Stoll: 🔍 How to Explore and Visualize ML-Data for Object Detection in Images





