
Разработка Python 3.10 стабилизировалась, и пришло время наконец-то протестировать все те новые функции, которые войдут в финальный выпуск.
Мы расскажем все самое интересное о том, что было добавлено в этот релиз Python: сопоставление структурных шаблонов, заключенные в скобки менеджеры контекста, нововведения, касающиеся типов, а также новые и улучшенные сообщения об ошибках.
Сопоставление структурных шаблонов
Сопоставление структурных шаблонов — невероятная и просто потрясающая функция, которая будет добавлена в Python.
Возьмем оператор if-else, который выглядит вот так:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"I'm a teapot\n"
]
}
],
"source": [
"http_code = \"418\"\n",
"\n",
"if http_code == \"200\":\n",
" print(\"OK\")\n",
"elif http_code == \"404\":\n",
" print(\"Not Found\")\n",
"elif http_code == \"418\":\n",
" print(\"I'm a teapot\")\n",
"else:\n",
" print(\"Code not found\")"
]
}
]
}Изменим синтаксис так, чтобы он выглядел следующим образом:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": 3
},
"orig_nbformat": 2
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"http_code = \"418\"\n",
"\n",
"match http_code:\n",
" case \"200\":\n",
" print(\"OK\")\n",
" case \"404\":\n",
" print(\"Not Found\")\n",
" case \"418\":\n",
" print(\"I'm a teapot\")\n",
" case _:\n",
" print(\"Code not found\")"
]
}
]
}Это новый оператор match-case. Круто, но пока ничего особенного.
Особенным его делает сопоставление структурных шаблонов. Оно позволяет выполнять ту же логику match-case, но исходя из того, соответствует ли структура объекта сравнения заданному шаблону.
Определим теперь два словаря с разными структурами:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"dict_a = {\n",
" 'id': 1,\n",
" 'meta': {\n",
" 'source': 'abc',\n",
" 'location': 'west'\n",
" }\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"dict_b = {\n",
" 'id': 2,\n",
" 'source': 'def',\n",
" 'location': 'west'\n",
"}"
]
}
]
}Затем напишем шаблон для dict_a:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"source": [
"```python\n",
"{\n",
" 'id': int,\n",
" 'meta': {'source': str,\n",
" 'location': str}\n",
"}\n",
"```"
],
"cell_type": "markdown",
"metadata": {}
}
]
}И шаблон для dict_b тоже:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": 3
},
"orig_nbformat": 2
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"source": [
"```python\n",
"{\n",
" 'id': int,\n",
" 'source': str,\n",
" 'location': str\n",
"}\n",
"```"
],
"cell_type": "markdown",
"metadata": {}
}
]
}Поместим их вместе в оператор match-case, и вместе со всем тем, что было в else, а фактически уже в case _, мы получим:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"output_type": "stream",
"name": "stdout",
"text": [
"1 abc west\n2 def west\nno match\n"
]
}
],
"source": [
"# в цикле проходятся оба словаря и 'test'\n",
"for d in [dict_a, dict_b, 'test']:\n",
" match d:\n",
" case {'id': ident,\n",
" 'meta': {'source': source,\n",
" 'location': loc}}:\n",
" print(ident, source, loc)\n",
" case {'id': ident,\n",
" 'source': source,\n",
" 'location': loc}:\n",
" print(ident, source, loc)\n",
" case _:\n",
" print('no match')"
]
}
]
}Особенно полезно это для обработки данных (пример смотрите на этом видео на 15:23).
Заключенные в скобки менеджеры контекста
Это небольшое изменение связано с куда более крупным нововведением, появившемся с версии Python 3.9 — новым парсером PEG.
У предыдущего синтаксического анализатора Python было много ограничений, не позволявших разработчикам на Python свободно использовать синтаксис.
С появлением в Python 3.9 парсера PEG эти барьеры были устранены, что в долгосрочной перспективе способно привести к более элегантному синтаксису. И первой ласточкой здесь стали новые, заключенные в скобки менеджеры контекста.
До Python 3.9 для открытия двух (или большего числа) потоков файлового ввода-вывода мы писали что-то вроде этого:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"with open('file1.txt', 'r') as fin, open('file2.txt', 'w') as fout:\n",
" fout.write(fin.read())"
]
}
]
}До появления нового парсера мы использовали два контекстных менеджера, но только они оба должны были находиться на одной строке.
Эта первая строка довольно длинная, и даже слишком. Но из-за ограничений синтаксического анализатора единственным способом разделения этой строки на несколько строк было использование \ (символа продолжения строки):
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"with open('file1.txt', 'r') as fin, \\\n",
" open('file2.txt', 'w') as fout:\n",
" fout.write(fin.read())"
]
}
]
}Это хороший способ, но нехарактерный для Python. Новый парсер позволяет разделить эту строку на несколько строк. Делается это с помощью круглых скобок:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"with (open('file1.txt', 'r') as fin,\n",
" open('file2.txt', 'w') as fout):\n",
" fout.write(fin.read())"
]
}
]
}А это как раз для Python характерно.
Прежде чем идти дальше, еще раз отметим одну маленькую странность в этой новой функции: она не совсем новая.
Посмотрите:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"with (open('file1.txt', 'r') as fin,\n",
" open('file2.txt', 'w') as fout):\n",
" fout.write(fin.read())"
]
}
]
}В Python 3.9 она работает. А все потому, что новый синтаксический анализатор позволял использовать этот синтаксис, хотя и не поддерживался официально до Python 3.10.
Нововведения, касающиеся типов
Обновления в Python затронули и типы.
Самое интересное нововведение здесь — это включение нового оператора, который ведет себя как логическое ИЛИ для типов. Раньше для этого мы использовали метод Union:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"from typing import Union\n",
"\n",
"def add(x: Union[int, float], y: Union[int, float]):\n",
" return x + y"
]
}
]
}Теперь не нужно писать from typing import Union, а вместо Union[int, float] осталось int | float. Так что сейчас он выглядит намного чище:
{
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.0"
},
"orig_nbformat": 2,
"kernelspec": {
"name": "python3",
"display_name": "Python 3.10.0 64-bit",
"metadata": {
"interpreter": {
"hash": "0af001259c9085d3649b2fae0bd6b291d17df5c9f127f6973a1b7698b4048c39"
}
}
}
},
"nbformat": 4,
"nbformat_minor": 2,
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"def add(x: int | float, y: int | float):\n",
" return x + y"
]
}
]
}Улучшенные сообщения об ошибках
Скорее всего, вы сразу бросились к поисковику, впервые увидев такую ошибку:
SyntaxError: unexpected EOF while parsing
Самый первый результат в выдаче поисковика при вводе SyntaxError оказывается тем, что многие из нас, конечно, и предполагали:
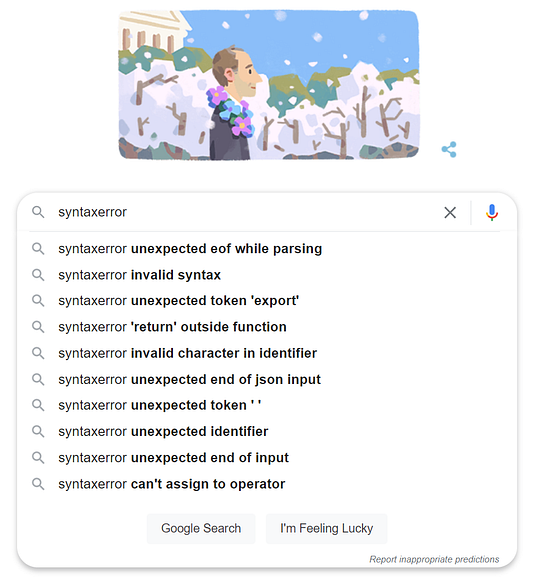
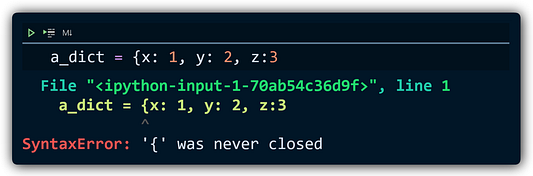
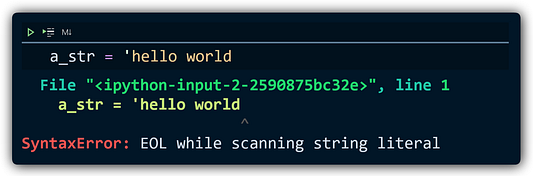
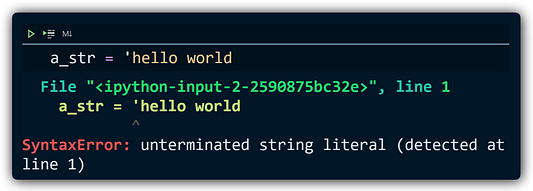
Не самое четкое сообщение об ошибке, и в Python таких много. К счастью, кто-то обратил на это внимание, и многие из этих сообщений значительно улучшились:

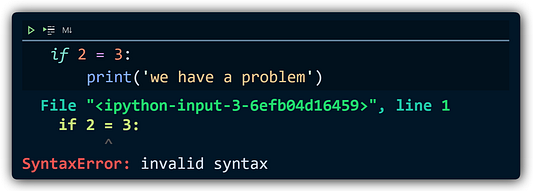
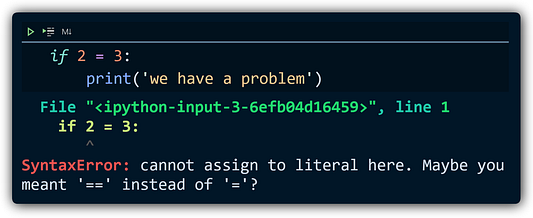
Есть еще несколько изменений, перечисленных в официальном списке изменений, но не показанных во время тестирования, в том числе:
from collections import namedtoplo
> AttributeError: module 'collections' has no attribute 'namedtoplo'. Did you mean: namedtuple?Здесь AttributeError такой же, как и раньше, но с уже введенным именем атрибута namedtoplo, в котором допущена опечатка (правильное название атрибута — namedtuple).
Подобные улучшения замечены и с сообщениями об ошибке NameError:
new_var = 5
print(new_vr)
> NameError: name 'new_vr' is not defined. Did you mean: new_var?Есть много и других обновлений сообщений об ошибках! Ознакомьтесь со всеми ими здесь.
Вот и все. Это были основные новые функции, которые появятся в Python 3.10!
Полный выпуск ожидается 4 октября 2021 года, а пока разработчики Python занимаются улучшением того, что уже добавлено. Но никаких других новых функций не появится.
Хотите ознакомиться самостоятельно? Бета-версия 3.10.0b1 доступна для скачивания здесь.
Надеюсь, статья вам понравилась. Спасибо за внимание.
Все изображения принадлежат автору, за исключением тех, на которых указано иное.
Читайте также:
- Python и веб-разработка: краткое руководство
- Как с помощью Python создавать математическую мультипликацию типа 3Blue1Brown
- Как отслеживать события файловой системы в Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи James Briggs: What’s New in Python 3.10?





