
У таких языков JVM, как Java и Scala, есть возможность запускать параллельный код с помощью класса Thread. Потоки, как известно, сложны и подвержены ошибкам, поэтому очень важно четко представлять, как они работают.
Начнем с Javadoc для Thread.sleep:
Приводит к тому, что выполняемый в данный момент поток переходит в спящий режим (временно прекращает выполнение) на указанное количество миллисекунд.
Каковы последствия прекращения выполнения (cease execution), также известного как блокировка, и что означает это понятие? Имеет ли оно негативное влияние? И если да, то можно ли обеспечить переход в спящий режим без блокировки?
О чем мы расскажем в этой статье
Данная статья затрагивает много вопросов, и, возможно, вы узнаете много интересного для себя.
- Что происходит на уровне ОС во время сна?
- Проблема со спящим режимом.
- Проект Loom и виртуальные потоки.
- Функциональное программирование и дизайн.
- Библиотека ZIO для параллелизма в Scala.
Начнем мы с этого простого фрагмента на Scala, который на протяжении всей статьи будем модифицировать, чтобы достичь цели:
println("a")
Thread.sleep(1000)
println("b")Все довольно просто: программа печатает “a”, а затем через 10 секунд печатает “b”.
Сосредоточимся на Thread. sleep и попытаемся понять, как достигается с его помощью сон. После этого мы сможем увидеть проблему и конкретизировать ее.
Как сон работает на уровне ОС?
Вот что происходит “под капотом” при запуске Thread.sleep.
- Он вызывает потоковый API базовой ОС.
- Поскольку JVM использует отображение один к одному между потоками Java и ядра, она просит ОС отказаться от “прав” потока на ЦП в течение указанного времени.
- По истечении этого времени планировщик ОС разбудит поток с помощью прерывания (это эффективно) и назначит ему фрагмент процессора, чтобы он мог возобновить работу.
Критический момент здесь в том, что спящий поток полностью извлекается и во время сна не переиспользуется.
Ограничения потоков
Вот несколько важных ограничений, которые сопутствуют потокам.
- Ограниченное количество создаваемых потоков. Примерно после тридцати тысяч вы получите такую ошибку:
java.lang.OutOfMemoryError : unable to create new native Thread
- Создание потоков JVM дорогостояще с точки зрения памяти, так как они поставляются с выделенным стеком.
- Слишком много потоков JVM будут нести дополнительные расходы из-за дорогостоящих переключателей контекста и совместного пользования конечными аппаратными ресурсами.
Теперь, когда мы лучше понимаем, что происходит за кулисами, вернемся к проблеме со спящим режимом.
Проблема со спящим режимом
Определим проблему более конкретно: запустим фрагмент кода для наглядности. Чтобы проиллюстрировать суть, воспользуемся следующей функцией.
def task(id: Int): Runnable = () =>
{
println(s"${Thread.currentThread().getName()} start-$id")
Thread.sleep(10000)
println(s"${Thread.currentThread().getName()} end-$id")
}Вот что делает эта простая функция:
- печатает
start, за которым следует идентификатор потока; - уходит в сон на 10 секунд;
- печатает
end, за которым следует идентификатор потока.
Ваша цель состоит в том, чтобы выполнять одновременно две задачи, имея в распоряжении один поток.
Мы хотим одновременно запустить две задачи, то есть вся программа должна выполняться в общей сложности за десять секунд. Но у нас есть только один поток.
Готовы ли вы принять этот вызов?
Поэкспериментируем с количеством задач и потоков, чтобы понять, в чем именно проблема.
1 задача -> 1 поток
new Thread(task(1)).start()
Результат:
12:11:08 INFO Thread-0 start-1
12:11:18 INFO Thread-0 end-1Запустим jvisualvm, чтобы проверить, что делает поток:
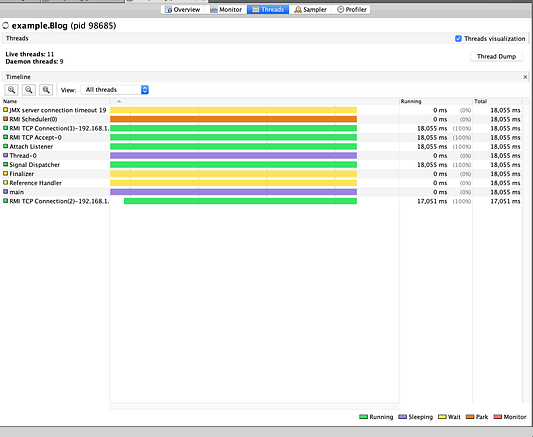
Как видно, нулевой поток (Thread-0) находится в фиолетовом (спящем) состоянии.
Нажатие кнопки “Thread Dump” выведет следующее:
"Thread-0" #13 prio=5 os_prio=31 tid=0x00007f9a3e0e2000 nid=0x5b03 waiting on condition [0x0000700004ac8000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at example.Blog$.$anonfun$task$1(Blog.scala:7)
at example.Blog$$$Lambda$2/1359484306.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Locked ownable synchronizers: - NoneМы видим, что этим потоком больше нельзя воспользоваться, пока он не выйдет из спящего режима.
2 задачи -> 1 поток
Проиллюстрируем эту проблему, запустив уже две такие задачи только с одним доступным потоком:
import java.util.concurrent.Executors
// исполнитель, которому доступен только один поток
val oneThreadExecutor = Executors.newFixedThreadPool(1)
// отправка двух задач исполнителю
(1 to 2).foreach(id =>
oneThreadExecutor.execute(task(id)))Получим следующий вывод:
2020.09.28 21:49:56 INFO pool-1-thread-1 start-1
2020.09.28 21:50:07 INFO pool-1-thread-1 end-1
2020.09.28 21:50:07 INFO pool-1-thread-1 start-2
2020.09.28 21:50:17 INFO pool-1-thread-1 end-2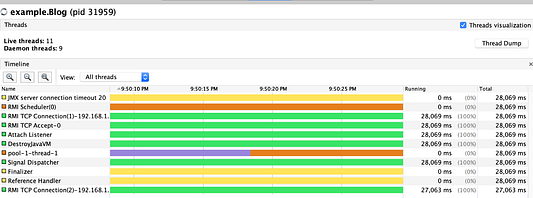
Как видите, для pool-1-thread-1 отображается фиолетовый цвет (состояние сна). У задач нет другого выбора, кроме как запускаться последовательно, потому что поток выводится из употребления каждый раз, когда задействуется Thread.sleep.
2 задачи -> 2 потока
Запустим тот же самый код при двух доступных потоках. Получим следующее:
// исполнитель с доступом к двум потокам
val oneThreadExecutor = Executors.newFixedThreadPool(2)
// отправка двух задач исполнителю
(1 to 2).foreach(id =>
oneThreadExecutor.execute(task(id)))Вывод:
2020.09.28 22:42:04 INFO pool-1-thread-2 start-2
2020.09.28 22:42:04 INFO pool-1-thread-1 start-1
2020.09.28 22:42:14 INFO pool-1-thread-1 end-1
2020.09.28 22:42:14 INFO pool-1-thread-2 end-2Каждый поток может выполнять по одной задаче за раз. В конце концов мы достигли того, чего хотели, выполнив одновременно две задачи, и вся программа закончилась за 10 секунд.
Это было легко, потому что мы воспользовались двумя потоками (pool-1-thread-1 и pool-1-thread-2), но нам хотелось бы сделать то же самое с одним.
Проблема зафиксирована. Теперь поищем решение.
Проблема: Thread.sleep is blocking
Теперь мы понимаем, что не можем пользоваться Thread. sleep — он блокирует поток. Это делает его непригодным к работе до тех пор, пока он не возобновится, и не дает выполнять больше одной задачи одновременно.
К счастью, есть решения, о которых мы поговорим далее.
Первое решение: обновите JVM с помощью Project Loom
Выше уже говорилось, что потоки JVM сопоставляются один к одному с потоками ОС. И эта роковая ошибка дизайна приводит нас сюда.
Project Loom стремится исправить это, добавив виртуальные потоки.
Вот наш код, переписанный с участием виртуальных потоков от Loom:
Thread.startVirtualThread(() -> {
System.out.println("a")
Thread.sleep(1000)
System.out.println("b")
});Самое удивительное, что Thread. sleep больше ничего не блокирует! Он полностью асинхронен. И вдобавок ко всему, виртуальные потоки очень дешевы. Вы можете создавать их сотнями тысяч без каких-либо накладных расходов или ограничений.
Все наши проблемы теперь решены. Кроме того, что Project Loom не будет доступен по крайней мере до выпуска JDK 17 (во время написания статьи запланирован на сентябрь 2021 года).
Вернемся назад и попробуем выйти из затруднения с текущими возможностями JVM.
Ключевая идея: вы можете выразить сон в терминах планирования задачи на будущее
Если вы скажете начальнику, что заняты и возобновите работу через десять минут, начальник не будет знать, что вы собираетесь вздремнуть. Он видит только то, что вы начали работать утром, затем сделали паузу на десять минут, а затем снова приступили к работе.
Вот это:
start
sleep(10)
endСо стороны эквивалентно этому:
start
resumeIn(10s, end)Выше мы запланировали завершение задачи через десять секунд.
Вот и все, спящий режим больше не нужен. Хватит возможности планировать события в будущем.
Мы свели одну проблему к другой, которая проще и легче решается.
Недостатки планирования
К счастью, планировать задачи несложно. Просто нужно сменить исполнителя:
val oneThreadScheduleExecutor = Executors.newScheduledThreadPool(1)
Теперь вместо функции execute можно воспользоваться функцией shedule:
oneThreadScheduleExecutor.schedule
(task(1),10, TimeUnit.SECONDS)Правда, это не совсем то, чего мы хотели. Нам нужно разделить начальный и конечный вывод десятью секундами, поэтому изменим функцию следующим образом:
def nonBlockingTask(id: Int): Runnable = () => {
println(s"${Thread.currentThread().getName()} start-$id")
val endTask: Runnable = () =>
{
println(s"${Thread.currentThread().getName()} end-$id")
}
//вместо Thread.sleep на 10 секунд мы планируем расписание на будущее, и вот, никакой блокировки
oneThreadScheduleExecutor.schedule(endTask, 10, TimeUnit.SECONDS)
}Результат:
2020.09.28 23:35:45 INFO pool-1-thread-1 start-1
2020.09.28 23:35:45 INFO pool-1-thread-1 start-2
2020.09.28 23:35:56 INFO pool-1-thread-1 end-1
2020.09.28 23:35:56 INFO pool-1-thread-1 end-2Получилось. Единственный поток и две параллельные задачи, которые “спят” по десять секунд каждая.
Но в действительности вы вряд ли будете писать именно такой код. Что делать, если нужно выполнить еще одну задачу в середине, как здесь?
00:00:00 start
00:00:10 middle
00:00:20 endНужно будет изменить реализацию nonBlockingTask и добавить туда еще один вызов schedule. И всё быстро станет очень запутанным.
Как написать DSL с неблокирующим сном при помощи функционального программирования
Функциональное программирование на Scala — одно удовольствие, а писать DSL (доменно-специфичный язык) с использованием принципов ФП довольно просто.
Начнем с конца. Нам нужно, чтобы окончательная версия программы выглядела примерно так:
def nonBlockingFunctionalTask(id: Int) = {
Print(id,"start") andThen
Print(id,"middle").sleep(1000) andThen
Print(id,"end").sleep(1000)
}Этот мини-язык добивается точно такого же поведения, как и предыдущее решение, но не проявляет недостатков компонентов запланированного исполнителя и потоков.
Модель
Определим типы данных:
object Task {
sealed trait Task { self =>
def andThen(other: Task) = AndThen(self,other)
def sleep(millis: Long) = Sleep(self,millis)
}
case class AndThen(t1: Task, t2: Task) extends Task
case class Print(id: Int, value: String) extends Task
case class Sleep(t1: Task, millis: Long) extends TaskВ функциональном программировании типы данных содержат только данные и никакого поведения. Таким образом, весь этот код “ничего не делает” — он просто фиксирует структуру языка и необходимую информацию.
Воспользуемся двумя функциями:
sleepдля перевода задачи в спящий режим.andThenдля сцепления задач.
Обратите внимание, что их реализация ничего не делает — только помещает в правильный класс.
Теперь воспользуемся функцией nonBlockingFunctionalTask:
import Task._
//создает 2 задачи, не запускает их, никакие потоки не задействованы
(1 to 2).toList.map(nonBlockingFunctionalTask)Это описание проблемы. Ничего не происходит, просто строится список из двух задач, каждая из которых описывает действия, которые нужно выполнить.
Если мы выведем результат в REPL, то получим следующее:
res3: List[Task] = List(
//первая задача
AndThen(AndThen(Print(1,start),Sleep(Print(1,middle),10000)),Sleep(Print(1,end),10000)),
//вторая задача
AndThen(AndThen(Print(2,start),Sleep(Print(2,middle),10000)),Sleep(Print(2,end),10000))
)Напишем интерпретатор, который превратит это дерево в элемент, который будет выполнять задачи.
Интерпретатор
В ФП функция, которая превращает описание в исполняемую программу, называется интерпретатором (interpreter). Он берет описание программы, ее модель и интерпретирует в исполняемую форму. Здесь он будет выполнять и планировать задачи напрямую.
Для начала нам понадобится стек, который позволит кодировать зависимости между задачами. Каждый start >>= middle >>= end будет помещаться в стек, а затем выскакивать в порядке выполнения. Это будет видно при реализации.
Теперь переходим к интерпретатору. Не волнуйтесь, если не понимаете этот код. Он довольно сложный, но есть и более простое решение.
def interpret(task: Task, executor: ScheduledExecutorService): Unit = {
def loop(current: Task, stack: Stack[Task]): Unit =
current match {
case AndThen(t1, t2) =>
loop(t1,stack.push(t2))
case Print(id, value) =>
stack.pop match {
case Some((t2, b)) =>
executor.execute(() => {
println(s"${Thread.currentThread().getName()} $value-$id")
})
loop(t2,b)
case None =>
executor.execute(() => {
println(s"${Thread.currentThread().getName()} $value-$id")
})
case Sleep(t1,millis) =>
val r: Runnable = () =>{loop(t1,stack)}
executor.schedule(r, millis, TimeUnit.MILLISECONDS)
}
loop(task,Nil)
}И вывод получается точно таким, как и ожидалось:
2020.09.29 00:06:39 INFO pool-1-thread-1 start-1
2020.09.29 00:06:39 INFO pool-1-thread-1 start-2
2020.09.29 00:06:50 INFO pool-1-thread-1 middle-1
2020.09.29 00:06:50 INFO pool-1-thread-1 middle-2
2020.09.29 00:07:00 INFO pool-1-thread-1 end-1
2020.09.29 00:07:00 INFO pool-1-thread-1 end-2Один поток выполняет две параллельные “спящие” задачи. За этим стоит много кода и много работы. Как обычно в таких ситуациях, надо спросить себя: есть ли библиотека, которая уже решает эту проблему. Оказывается, есть, и это ZIO.
Сон без блокировки в ZIO
ZIO — это функциональная библиотека для асинхронного и параллельного программирования. Принцип ее работы схож с нашим маленьким DSL: она предоставляет несколько типов, которые можно смешивать и сопоставлять, чтобы описать свою программу. Затем она снабжает нас интерпретатором, который позволяет запускать ZIO-программу.
Как уже упоминалось, паттерн интерпретатора широко распространен в ФП. Как только вы его освоите, перед вами откроется новый мир.
ZIO.sleep — улучшенный вариант Thread.sleep
ZIO предоставляет функцию ZIO.sleep, неблокирующую версию Thread.sleep. Вот наша функция, написанная с помощью ZIO:
import zio._
import zio.console._
import zio.duration._
object ZIOApp extends zio.App {
def zioTask(id: Int) =
for {
_ <- putStrLn(s"${Thread.currentThread().getName()} start-$id")
_ <- ZIO.sleep(10.seconds)
_ <- putStrLn(s"${Thread.currentThread().getName()} end-$id")
} yield ()Это поразительно похоже на первый фрагмент:
def task(id: Int): Runnable = () =>
{
println(s"${Thread.currentThread().getName()} start-$id")
Thread.sleep(10000)
println(s"${Thread.currentThread().getName()} end-$id")
}Ключевое различие заключается в синтаксисе for, который позволяет связывать операторы с типом ZIO. Это очень похоже на функцию andThen из рассмотренного ранее мини-языка.
Как и прежде в случае с мини-языком, эта программа — просто описание. Это чистая информация, и она ничего не делает. Чтобы что-то сделать, нужен интерпретатор.
Интерпретатор ZIO
Чтобы интерпретировать ZIO-программу, нужно просто расширить интерфейс ZIO.App и поместить его в метод run, а ZIO возьмет на себя запуск. Примерно так:
object ZIOApp extends zio.App
{
override def run(args: List[String]) = {
ZIO
//две ZIO-задачи стартуют параллельно
.foreachPar((1 to 2))(zioTasks)
//завершает программу, когда закончит
.as(ExitCode.success)
}И получаем результат — задачи корректно выполняются за десять секунд:
2020.09.29 00:45:12 INFO zio-default-async-3-1594199808 start-2
2020.09.29 00:45:12 INFO zio-default-async-2-1594199808 start-1
2020.09.29 00:45:33 INFO zio-default-async-7-1594199808 end-1
2020.09.29 00:45:33 INFO zio-default-async-8-1594199808 end-2Выводы
- Каждый поток JVM сопоставляется с потоком ОС в режиме один к одному. И в этом корень многих проблем.
Thread.sleepблокирует текущий поток и делает его непригодным для дальнейшей работы.- Проект Loom (который будет доступен в JDK 17) решит множество проблем.
- Чтобы добиться неблокирующего сна, можно воспользоваться
ScheduledExecutorService. - Можно применить функциональное программирование для моделирования языка, где сон не создает блокировку.
- Библиотека ZIO обеспечивает неблокирующий сон “из коробки”.
Читайте также:
- Избегаем исключения Null Pointer Exception в Java с помощью Optional
- 20 сокращений JavaScript, которые сэкономят ваше время
- Графовое моделирование данных на Java
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Daniel Sebban: How to Use Thread.sleep Without Blocking on the JVM





