
Мемоизация — это кэширование вывода функции, чтобы последующие вызовы могли использовать этот кэшированный результат без лишних вычислений. В JavaScript при условии правильной реализации эта техника может оптимизировать производительность удивительным образом.
Думаю, вы не откажетесь ускорить свой JS-код, так что в этой статье мы рассмотрим практический пример мемоизации в JavaScript.
Спойлер: в примере не будет использоваться последовательность Фибоначчи или факториал, о которых я немного скажу позже.
Что есть мемоизация?
В упрощенной форме мемоизация — это, когда выполняется дорогостоящая функция с параметрами a и b, и ее результаты кэшируются. Затем, когда та же функция вызывается с теми же параметрами a и b, ее вывод просто возвращается из кэша.
В Википедии мемоизация определена так:
В программировании — это сохранение результатов выполнения функций для предотвращения повторных вычислений. Является одним из способов оптимизации, применяемым для увеличения скорости выполнения компьютерных программ.
Далее:
Функция мемоизации запоминает результаты, соответствующие определенному набору входных данных. Последующие вызовы с этими входными данными возвращают запомненный результат без его повторного вычисления. Таким образом, исчезают затраты на все повторные вызовы с данными параметрами.
Пример без чисел Фибоначчи и факториала
Честно говоря, меня уже утомили одни и те же примеры с последовательностью Фибоначчи и факториалами. И в Википедии, и в 8 из 10 поисковых результатов по запросу “мемоизация JavaScript” используются именно такие примеры. Да, мы делали это в университете, когда разбирали рекурсию. Но я, как и многие современные программисты, не прибегал к факториалам и числам Фибоначчи уже лет так 14.
Если вам все же интересны именно такие примеры, то можете почитать этот пост (англ). Кое-кто на Free Code Camp даже продемонстрировал, как создать собственную функцию мемоизации. Но наша задача сегодня в другом. Мы будем использовать эту технику в практическом русле.
Требования
Прежде чем перейти к коду, нужно понимать, что от вас ожидается:
- Общее понимание работы промисов и асинхронного кода в JS.
- Понимание REST API.
- Умение написать простой API с реляционной СУБД в качестве хранилища.
К делу!
Практический пример: мемоизация для веб-ответа
В качестве примера мы возьмем Quotes API и мемоизируем ответ, который будет являться промисом. Для этой цели мы используем библиотеку p-memoize. Есть и другие весьма популярные варианты, например lodash.memoize, mem и fast-memoize.
Наиболее интересной из перечисленных библиотек я считаю mem, а p-memoize просто является ее версией для промисов/async. И mem, и p-memoize разрабатывал один человек.
А так как я уже работал с p-memoize ранее, то и в этом примере буду использовать ее. Выбранный нами пример API генерации цитат является открытым и развернут на Zeet.
Я выбрал Zeet, потому что это не бессерверная платформа, и после применения мемоизации мы увидим наглядное сокращение времени ответа.
Время ответа без мемоизации
Прежде чем мемоизировать функцию, мы рассмотрим код в файле /routes/quotes.js:
const express = require('express');
const router = express.Router();
const quotes = require('../services/quotes');
/* GET quotes listing. */
router.get('/', async function(req, res, next) {
try {
res.json(await quotes.getMultiple(req.query.page));
} catch (err) {
console.error(`Error while getting quotes `, err.message);
res.status(err.statusCode || 500).json({'message': err.message});
}
});Это простой маршрут Express.js, где мы получаем строки из quotes.getMultiple. В данном случае при каждом вызове будет выполняться запрос к базе данных.
Посмотрим, какое будет время ответа при использовании этого подхода. С помощью инструмента нагрузочного тестирования Vegeta мы выполним простой тест, отправляя по 50 запросов/сек в течение 30 секунд. Вот команда для запуска:
echo "GET https://geshan-nodejs-posgresql.zeet.app/quotes" \
| vegeta attack -duration=30s -rate=50 -output=results-veg-no-mem.bin && cat results-veg-no-mem.bin \
| vegeta plot --title="Quotes API before memozie" > quotes-api-before-memoize.htmlПосле выполнения теста отобразится его вывод:
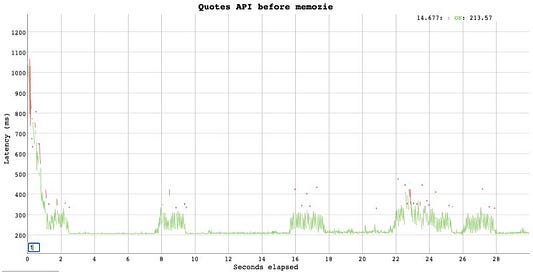
Здесь мы видим, что самый быстрый ответ составил ~205 мс, а самый медленный 1,5 с. Я намеренно установил скорость 50 запросов в секунду. Красные точки — это 500 ошибок, вызванных проблемами с подключением к базе данных.
Спустя первые несколько запросов время ответа становится вполне приемлемым, так как мы используем пул соединений с базой данных.
Время ответа с мемоизацией
Далее с помощью библиотеки p-memoize мы мемоизируем функцию getMultiple. Изменения в файле routes/quotes.js после выполнения npm i p-memoize будут следующие:
const express = require('express');
const router = express.Router();
const quotes = require('../services/quotes');
const pMemoize = require('p-memoize');
const ONE_MINUTE_IN_MS = 60000;
const memGetMultiple = pMemoize(quotes.getMultiple, {maxAge: ONE_MINUTE_IN_MS});
/* GET quotes listing. */
router.get('/', async function(req, res, next) {
try {
res.json(await memGetMultiple(req.query.page));
} catch (err) {
console.error(`Error while getting quotes `, err.message);
res.status(err.statusCode || 500).json({'message': err.message});
}
});Что же изменилось:
- В строке 4 мы добавили библиотеку p-memoize.
- Далее мы установили константу на 60 000 мс, что равно 1 минуте. Это будет длительность хранения кэша мемоизации в памяти.
- Затем на строке 6 мы мемоизируем функцию
quotes.getMultiple. - Ниже в маршруте
getмы используем эту функцию вместо оригинальной.
Эти изменения также доступны в пул-реквесте. Теперь при выполнении того же нагрузочного теста с 50 запросами в секунду результат получается такой:
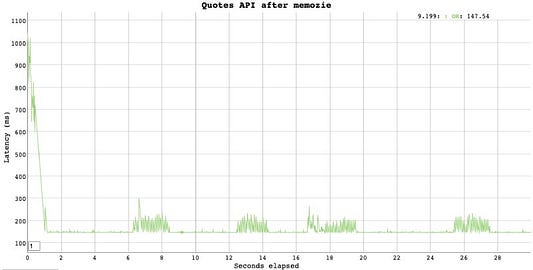
Здесь самый быстрый ответ составил ~157 мс, а самый медленный (похоже, что первый) занял 1,05 c. В целом время ответа сокращается на 50-75 мс.
Еще одно преимущество в том, что при всех этих 1 500 запросах, фактически, в течение 30 сек обращение к БД происходит только один раз.
То же видно из логов Zeet, описывающих развертывание этой ветки:
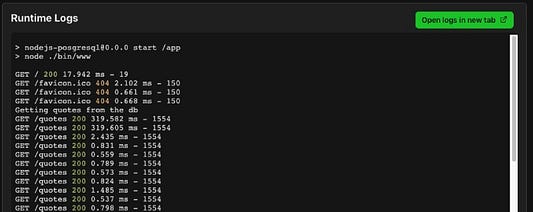
Здесь мы видим, что первый запрос достиг базы данных, отобразив запись Getting quotes from the db. Далее в течение одной минуты повторное обращение к БД не происходит.
Поэтому оставшиеся 1499 запросов получают мемоизированный результат. Первые два запроса заняли ~320 мс, после чего на оставшиеся уходило от 0,5 до 2,4 мс. Все благодаря мемоизации.
Если бы мы выполняли тест локально, то результаты оказались бы еще быстрее, так как из процесса исключается передача по сети. Локальные тесты также избежали бы таких сложностей, как SSL-рукопожатие.
Однако я хотел показать более практичный и реалистичный пример мемоизации, так как мне сильно надоели все эти факториалы и числа Фибоначчи.
Здесь я использовал p-memoize, вы же можете применить любую другую библиотеку. Лично я рекомендую fast-memoize или memoizee. Первая заявляет себя как максимально быстрая библиотека в JS с поддержкой N аргументов. Испытайте ее.
Дополнительные примечания
С учетом выбранной библиотеки не стоит забывать о следующем:
- Мемоизация может просто кэшировать первый параметр, выдавая неожиданные результаты. Например, в p-memoize при наличии более одного аргумента их нужно объединять.
- Не во всех языках она поддерживается. Например, в PHP нет собственного простого способа мемоизировать возвращаемое функцией значение, так как в этом языке все процессы в ходе запроса запускаются и уничтожаются. То же касается и бессерверных функций.
- Очевидно, что мемоизировать можно только те функции, которые что-либо возвращают. Пустые функции мемоизировать нельзя.
В данном примере мы могли также использовать для кэширования ответа в браузере заголовок Cache-Control. Эта техника относится к кэшированию на уровне HTTP и также заслуживает внимания.
Заключение
Взгляните на мемоизацию несколько иначе и начинайте применять ее в более практических целях. Избавьтесь от идеи, что ее можно использовать только для таких вещей, как факториалы и числа Фибоначчи. Начните задействовать этот прием для любых ресурсоемких задач, допускающих кэширование, например запросов GET.
Надеюсь, что после прочтения этой статьи вы стали лучше разбираться в мемоизации, особенно ее применении в JavaScript. Продолжайте учиться!
Читайте также:
- Пишем фронтенд-компоненты на ванильном JS
- Познай прокси-объект JavaScript как самого себя
- Мы снова написали самый быстрый JS-фреймворк UI
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Geshan Manandhar: Want To Build Faster Web Apps? Use JavaScript Memoization





