
В основе Koan лежат его цели и то, как эти цели взаимосвязывают людей и команды внутри компании. Эти связи зачастую оказываются сложными, потому что один и тот же человек может одновременно вести несколько разных команд со смежными целями. Для моделирования этого процесса мы используем графовую базу данных, построенную на основе DynamoDB и называемую таблицей записей.
С чего всё началось
Наше приложение наглядно показывает список объектов, имеющих множество связей с другими объектами. Попытки организовать это на базе той же DynamoDB, но при помощи традиционной нормализованной структуры таблицы, были малоэффективны. В частности, приведу пример с нашим списком целей: список целей может включать тысячи единиц, каждая из которых может иметь огромное число связей с командами, пользователями, другими целями и прочими данными системы. Более ранние версии Koan разрешали эту ситуацию очень примитивно, а именно единовременно получая список целей компании из базы данных и отправляя их клиенту. В итоге этот процесс стал слишком медленным, и возникла необходимость в создании модели пагинации. Чтобы справляться с обработкой всей необходимой информации посредством DynamoDB, мы спроектировали так называемую таблицу записей:
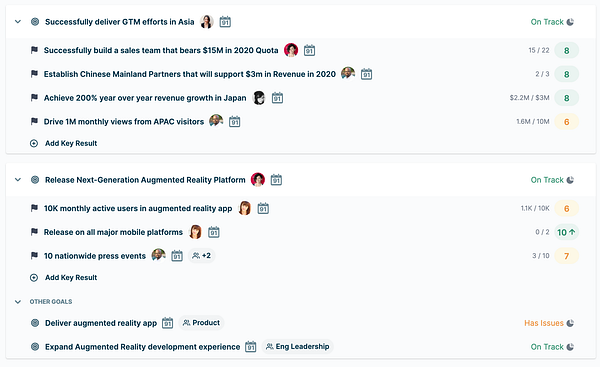
На этом скриншоте показан список задач команды, состоящий из двух основных целей, разделённых на 4 и 3 Key Results (ключевых результата), а также двух второстепенных целей внизу. Для каждой цели и ключевого результата нам нужно отобразить одного или нескольких лидеров, отвечающих за реализацию задачи, а также одну или более команд, связанных с этой целью.
Следовательно, имеющиеся здесь данные можно визуально представить так:
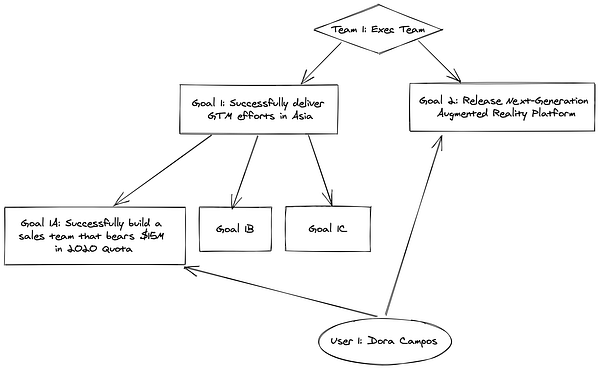
Конечно же, это лишь небольшое подмножество из всего того, что мы показываем. Дора Кампус ведёт две из представленных здесь целей, но она также может принимать участие и в ряде других, являясь при этом членом их команд. Цели вроде “10 nationwide press events” (10 общенациональных пресс-конференций) могут иметь собственные подцели и ключевые результаты, и такую цепочку можно продолжить далее.
Моделирование этой схемы вызывает сложности по следующим причинам:
- Нам нужно поддерживать множество связей между несколькими типами моделей.
- Нам нужно одновременно показывать в UI несколько типов и уровней ассоциаций.
- Нам нужно показывать одни и те же данные разными способами: список целей команды может показывать данные, существенно перекликающиеся с целями пользователя в его профиле, которые в свою очередь перекликаются с постоянной ссылкой цели и т.д.
- Представление списка целей — это лишь одно из нескольких мест, где нам необходимо отражать сложные связи. Пользователи также могут ассоциироваться с командами несколькими способами, например являться менеджером команды, её членом или наблюдателем, имеющим право только на чтение.
- Если целей слишком много для единовременного запроса от клиента, тогда нам нужен способ пагинировать результаты.
Итак, желая запрашивать цели команды наряду с лидерами и другими командами, эти цели реализующими, давайте попытаемся смоделировать понятную схему в нашей базе данных.
Моделирование при помощи DynamoDB
Для решения этой задачи мы создали таблицу записей — единую таблицу DynamoDB, способную уместить все наши типы моделей со всеми связями между ними. На языке графа каждый элемент в этой таблице записей является либо “узлом”, либо “ребром”.
- Узел — это объект первого класса во вселенной Koan. К ним относятся цели, пользователи, команды и т.д.
- Ребро — это представление связи между двумя узлами графа. Его примером является принадлежность к цели, а именно связь между целью и пользователем, командой или организацией. Ребра по своей сути однонаправлены (т.е. ребро от A к B не соответствует ребру от B к A).
Элементы в таблице DynamoDB уникально идентифицированы комбинацией их ключа раздела и ключа сортировки. Важная характерная черта DynamoDB в том, что она отлично подходит для запросов конкретных элементов по ID или по ключу сортировки в рамках одного ключа раздела, но при этом не очень годится для выполнения запросов среди самих ключей разделов.
Как же мы фактически храним эти узлы и ребра в БД, если вся она организована посредством ключей разделов и ключей сортировок? На деле структура ключей DynamoDB работает естественным образом как список смежных вершин. Пара ключ раздела и ключ сортировки представляют в этом графе ребро, где первый представляет исходный узел ребра, а второй — цель этого ребра.
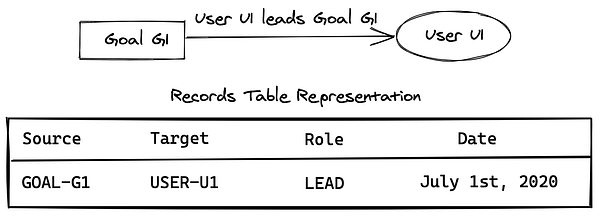
Например, в этой диаграмме отношение User U1 к Goal G1 можно рассмотреть как ребро, где G1 является источником, а U1 — целью. В таблице записей мы обращаемся к ключу раздела как к источнику, а к ключу сортировки как к роли пользователя в совместном достижении цели, и когда пользователь стал с ней ассоциирован. В данной БД в итоге это выглядит так:
{
source: 'GOAL-G1',
target: 'GOALMEMBERSHIP-USER-U1',
memberRole: 'LEAD', // Имейте в виду, что в ребре можно хранить произвольные метаданные
date: '2020-07-01',
gsi0: '500-LEAD', // Объясняется ниже
}Обратите внимание, что на практике ID вроде G1 — это UUID в нашей БД. В связи с этим ID в данной таблице записей хранятся в качестве UUID, где в виде префикса указывается тип объекта. К примеру, id цели может быть таким GOAL-cb421e73-43bb-4c68-bea3-be8f1f6140e8. Такой префикс типа необходим, поскольку мы используем одну таблицу для хранения множества типов данных. У рёбер также есть типы: в примере выше ребро имеет тип GOALMEMBERSHIP. Это позволяет нам поддерживать несколько типов связей между двумя одинаковыми типами узлов. Например, если бы мы собирались хранить между пользователями и целями связь “subscriber” (подписчик), то могли бы добавить к полю target префикс GOALSUBSCRIBER, создавая тем самым значения target вроде GOALSUBSCRIBER-USER-U1.
Но это только рёбра, а где хранятся узлы?
Узлы представлены в виде ссылающихся на самих себя рёбер. Другими словами, мы можем рассматривать данные узла как ребро с одинаковыми source и target.
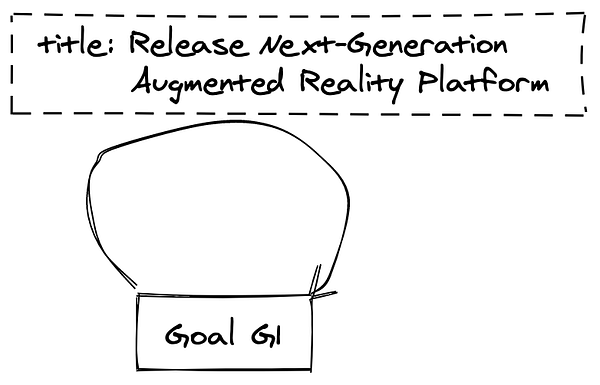
Например, цель узла G1 хранится с ключом раздела GOAL-G1 и ключом сортировки GOAL-G1. Поэтому цель в таблице записей может выглядеть так:
{
source: 'GOAL-G1',
target: 'GOAL-G1',
title: 'Release Next-Generation Augmented Reality Platform',
// ... и т.д. с другими данными цели
}Внутри DynamoDB эти узлы и рёбра выглядят так:

Хорошо, но какая нам от этого польза?
С помощью этого мы способны запрашивать любое число узлов напрямую, выполняя операцию BatchGetItem для главного индекса таблицы (т.е. имея список ID целей, мы можем прочитать их все напрямую за одну операцию). Более того, теперь мы можем запрашивать узлы на основе связей рёбер, например запрашивать все цели, ведомые пользователем. Для этого нам нужно использовать DynamoDB Query API совместно с его функцией Глобальных вторичных индексов (GSI).
Глобальные вторичные индексы
GSI аналогичны индексам в традиционной таблице SQL, но ограничены тем, что индексируют они только одно поле. Структура GSI схожа с основной структурой ID главного индекса DynamoDB тем, что имеет ключ раздела и ключ сортировки, но при этом ID GSI не уникален. В нашем случае мы поддерживаем GSI с ключом раздела, установленным как поле target, и ключом сортировки, установленным как поле gsi0, показанное ниже. Поле gsi0 выведено из остальных полей в ребре специально продуманным способом, чтобы активировать интересующие нас запросы. В случае выше оно выводится непосредственно из поля memberRole, но с префиксом 500-, который мы вскоре рассмотрим.
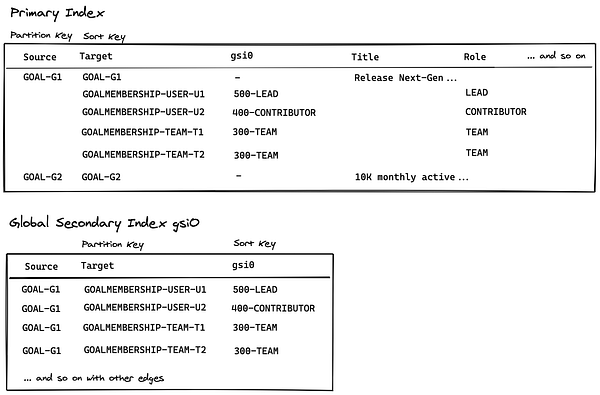
Query API позволяет нам указывать один ключ раздела и условие ключа сортировки, по которому нужно извлечь элементы. В данном случае мы хотим получить все рёбра принадлежности к цели, соединяющие конкретного пользователя U1 с целями, где U1 является лидером. Для этого мы можем выполнить запрос к GSI для получения элементов, чей ключ раздела (т.е. target) является GOALMEMBERSHIP-USER-U, а ключ сортировки (т.е. gsi0) представлен 500-LEAD. Выполнение этого запроса предоставит нам рёбра, соответствующие интересующим нас целям. Однако стоит помнить, что эти рёбра не содержат фактических данных о цели вроде её title. Эти данные хранятся только в самом узле цели, поэтому нам по-прежнему нужно извлечь узлы, соединённые с только что полученными рёбрами. Мы делаем это, выполнив операцию BatchGetItem для главного индекса с id целей, которые хранятся в каждом ребре в виде поля source. В результате мы получим список целей, которые ведёт пользователь.
Но зачем нам префикс 500-?
Помните, что поле gsi0 — это ключ сортировки. Он так называется, потому что Query API позволяет нам запрашивать либо элементы, лексикографически находящиеся до или после конкретного ключа сортировки, либо значения, которые начинаются с конкретного префикса этого ключа. Мы используем его, чтобы иметь возможность запрашивать несколько уровней принадлежности к цели за один раз. Для таких ролей, как LEAD, CONTRIBUTOR и TEAM, мы храним поле gsi0 (название будет объяснено в конце) в виде 500-LEAD, 400-CONTRIBUTOR и 300-TEAM. (200 и 100 на данный момент зарезервированы для других задач). Это позволяет нам выполнять запросы вроде “получить все цели, в которых участвует или которые ведёт пользователь U”, указав ключ раздела GOALMEMBERSHIP-USER U и условие ключа сортировки как “всё, где значение gsi0 будет >= 400-CONTRIBUTOR”. Каждый тип ребра может предоставить собственную логику вывода значения gsi0 на основе своих полей.
В Query API реализована ещё одна тонкость, а именно встроенная пагинация. Через параметры EsclusiveStartKey и Limit мы можем получить первые N рёбер цели, ассоциированные с командой, а затем получить следующие N, когда это понадобится клиенту.
Вот мы и подошли к завершению. Теперь мы можем извлечь все цели команды, сделав запрос ко вторичному индексу на получение рёбер принадлежности, а затем произведя чтение из главного индекса для получения узлов целей. Но нам по-прежнему нужно получить всех лидеров и команды, связанные с этими целями, что потребует выполнить запрос ко всем целям, которые мы извлекли. Но когда мы это сделаем, нам всё ещё потребуется выполнить операцию BatchGetItem для извлечения узлов пользователей и команд, ассоциированных с этими рёбрами, а с этой задачей DynamoDB уже так ловко не справится. Помните, что мы можем делать запрос только либо конкретных элементов по их ID (где ID — это комбинация ключа раздела и ключа сортировки), либо по ключу сортировки в рамках одного раздела. Таким образом, мы оказываемся в ситуации, напоминающей запрос N+1.
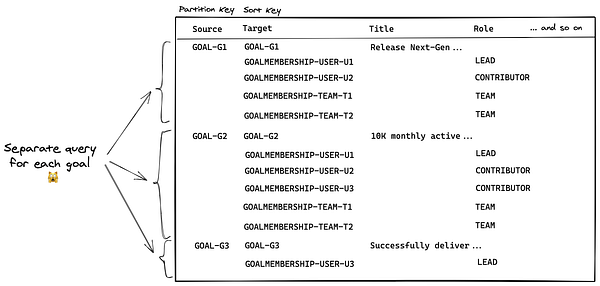
Несмотря на то, что мы могли бы выполнить все эти запросы по отдельности в параллельном режиме, это всё равно окажется неэффективным. Кроме того, такой подход будет стоить немалых затрат в денежном эквиваленте.
Ввод множества рёбер
Для решения сложившейся задачи мы создали так называемое множество рёбер. Его можно представить как точную копию рёбер узлов, хранящуюся непосредственно в узле. Множество рёбер — это строчное множество в DynamoDB, в котором находится содержимое полей target и рёбер gsi0, соединённых с узлом. Например, так как в нашей цели лидером является USER-U1, множество рёбер содержит GOALMEMBERSHIP-USER-U1-LEAD. Это сериализация информации ключа ребра, которую затем сразу после считывания мы можем десериализовать в id пользователя и роль его принадлежности. Используя данные множеств рёбер всех считанных нами других целей, мы можем составить операцию BatchGetItem, которая либо извлекает всех лидеров для полученных целей, либо все команды, либо и то и другое.
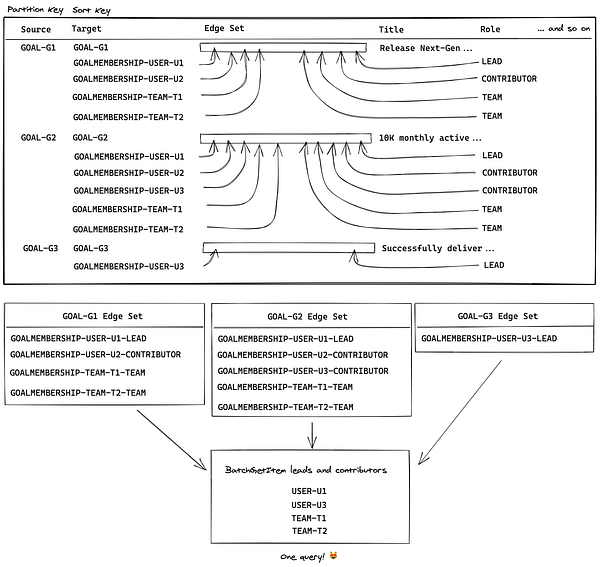
Здесь мы храним информацию о рёбрах цели внутри её множества рёбер. Таким образом, как только мы считаем из таблицы множество узлов цели посредством операции BatchGetItem, то тут же получим информацию об их рёбрах из множеств рёбер каждой цели. Затем мы можем выполнить ещё одну операцию BatchGetItem для получения любых интересующих нас ассоциированных узлов, которые в данном случае являются списком лидеров и команд.
Тем не менее осталась ещё одна проблема, а именно согласованность. Множество рёбер излишне и в следствие этого денормализовано, что создаёт риск непоследовательности, а именно проблему обеспечения синхронизации множества рёбер с элементами рёбер в таблице? В 2018 году для решения этого вопроса AWS разработали специальный функционал — транзакции. Используя их, мы можем быть уверены, что, когда мы добавляем ребро в базу данных, его данные также добавляются во множество рёбер. Схожим образом при удалении ребра мы используем транзакцию для обеспечения его удаления из множества рёбер.
Общий итог
Давайте вернёмся к нашему изначальному примеру. Мы хотели получить все цели команды наряду с лидерами этих целей и ассоциированными командами. При помощи таблицы записей мы можем добиться этого за три шага:
- Выполнить запрос к GSI для получения рёбер целей, соединяющих с ними нашу команду. Это даст нам список ID целей.
- Выполнить операцию BatchGetItem для главного индекса, чтобы извлечь цели на основе только что полученных ID.
- Выполнить BatchGetItem для главного индекса, чтобы получить релевантные узлы, ассоциированные с только что полученными целями. В частности, мы получим пользователей-лидеров и команды.
Мы решили нашу изначальную проблему и также ряд других. Например, показ страницы, содержащей только цели, которые ведёт пользователь, — это вопрос изменения запроса GSI для получения рёбер целей, соединённых с пользователем, имеющим роль принадлежности LEAD. Нахождение всех участников конкретной цели можно выполнить простым инспектированием множества рёбер цели. Поскольку мы моделировали таким образом всё больше и больше данных, то смогли при необходимости выполнять всё более запутанные запросы, не прибегая при этом к значительному рефакторингу.
Это высокоуровневый обзор работы нашей таблицы записей. Управление правилами и структурой этой таблицы весьма витиеватое занятие, поэтому с целью его упрощения мы разработали вокруг DocumentClient DynamoDB клиентскую библиотеку, основанную на TypeScript. Эта библиотека, на данный момент ещё являющаяся закрытой, предоставляет декларативный интерфейс для определения всех полей и рёбер узла, а также для конфигурирования способа вывода GSI-значений ребра, сериализованных значений множеств рёбер и т.д.
На заметку
- Откуда название
gsi0? Мы используем имяgsi0, потому что DynamoDB допускает до 25 GSI на таблицу. Ничто не мешает нам создать второй GSI под именемgsi1, который будет индексировать принадлежности к цели, выполняя сортировку по дате, а не по уровню принадлежности. Структура таблицы записей позволяет индексирование нескольких типов рёбер в одном GSI, но для индексирования одного и того же типа ребра другим ключом сортировки требуется новый GSI. - Что случается, когда множество рёбер становится слишком большим? Один элемент в таблице DynamoDB не может превышать 400KB. Несмотря на то, что это немало, встречаются случаи, когда у узла могут быть сотни или даже тысячи рёбер. Связь “subscriber”, упомянутая нами ранее, может с лёгкостью представить такой вариант поведения. В подобных случаях наша библиотека позволяет опускать во множестве рёбер определённые их типы. Несмотря на то, что это не идеальное решение, на практике оно удовлетворяет ожиданиям продукта: список людей, подписавшихся на цель, не требует всецелого отображения в UI для нескольких целей за раз.
- Почему множество рёбер хранится в качестве множества DynamoDB, а не в более эффективном в отношении пространства формате? Использование множества DynamoDB для множеств рёбер позволяет выполнять добавление и удаление рёбер в запросах при помощи выражений
ADDиDELETEсоответственно. Это означает, что мы можем создавать в узле новое ребро, не нуждаясь в предварительном считывании узла из базы данных.
Читайте также:
- Почему в базе данных происходит взаимоблокировка?
- Запуск DBT в Azure Functions с помощью Snowflake
- Инновационный алгоритм глубокого обучения в Google Translate
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Ashwin Bhat: Modeling Graph Relationships in DynamoDB





