
Современный Google Translate просто потрясает своими возможностями. Для реализации способности выполнять перевод между любой парой из десятков поддерживаемых языков создатели этого инструмента очень находчиво использовали одну из самых продвинутых разработок в области NLP (обработки естественного языка).
В машинном переводе существует два основных подхода: основанный на правилах и, собственно, на самом машинном обучении. В первом задействуется коллекция массивных словарей пословных или даже пофразовых переводов, из которых и строится итоговый текст.
В первую очередь здесь нужно учитывать, что грамматические структуры языков существенно различаются. Возьмите, к примеру, испанский, в котором объекты имеют мужской или женский род. Все прилагательные или слова вроде ‘the’ или ‘a’ должны соответствовать роду объекта, который они описывают. Перевод фразы ‘the big red apples’ на испанский потребовал бы написания каждого слова во множественном числе и женском роде, потому что таковы атрибуты слова ‘apples’. Кроме того, в испанском прилагательные обычно следуют за существительным, хотя не всегда.
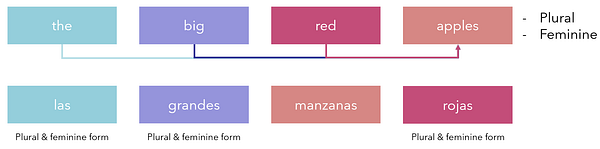
В результате получится ‘las [the] grandes [big] manzanas [apples] rojas [red]’. Такая грамматика и необходимость изменения всех прилагательных абсолютно бессмысленна с позиции чисто англоговорящего человека. В рамках одного только англо-испанского перевода существует слишком много несогласованностей в фундаментальной структуре, чтобы все их отслеживать. Тем не менее по-настоящему глобальный перевод должен выполняться между каждой парой языков.
Наряду с данной задачей возникает и проблема: перевод между, например, французским и мандаринским. Единственным разумным, основанном на правилах решением в данном случае было бы перевести французский на базовый язык, к примеру, английский, и уже с него затем делать перевод на мандаринский. Это подобно игре в глухой телефон: нюанс фразы, сказанной на одном языке, искажается шумами и грубым обобщением.

Здесь становится очевидной не только беспомощность перевода, основанного на правилах или словарях, но также и необходимость создания универсальной модели, которая сможет изучить словарь и структуру двух языков. При этом разработка такой модели является весьма трудной задачей по ряду причин:
- Она должна быть достаточно легковесной, чтобы работать оффлайн, предоставляя возможность использования при отсутствии интернет-соединения. Более того, в ней должен поддерживаться перевод между любой парой языков, и все они должны загружаться на смартфон или ПК пользователя.
- Модель должна иметь достаточную скорость для генерации перевода в реальном времени.
- Продолжая рассматривать пример выше — в английском слова ‘big red apple’ последовательны. Однако если мы будем обрабатывать эти данные слева направо, то испанский перевод получится неточным, поскольку в данном языке прилагательные, даже находясь перед существительным в английском, изменяют свою форму в зависимости от этого существительного. Поэтому модель также должна учитывать и непоследовательный перевод.
- Системы, основанные на машинном обучении, всегда зависят от наборов данных, в связи с чем слова, не представленные среди этих данных, будут совершенно неизвестны модели, которой потребуется надежность и хорошая память на редкие слова. Где же взять коллекцию качественно переведенных данных, представляющих всю грамматику и словарь того или иного языка?
- Легковесная модель не может запомнить весь словарь языка. Как она сможет работать с неизвестными словами?
- Многие азиатские языки вроде японского или мандаринского основаны не на буквах, а на символах. В них для каждого слова существует один уникальный символ. Модель машинного обучения должна уметь выполнять двусторонний перевод между буквенными системами вроде английской, испанской или немецкой, где также присутствуют буквы с ударением, и символьными системами вроде корейской.
Когда Google Translate только появился, в нем использовался фразовый алгоритм, который основывается на правилах, но при этом дополнительно усложнен. Тем не менее вскоре после этого Google разработали технологию нейронного машинного перевода (GNMT), которая позволила повысить его качество во много раз.
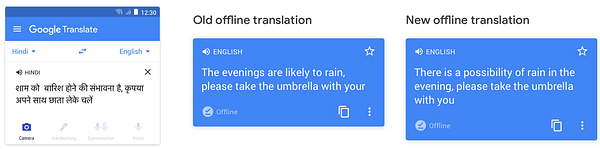
В нем учли все перечисленные выше проблемы, для которых были выработаны инновационные решения, позволившие создать усовершенствованный Google Translate — наиболее популярный сервис переводов на сегодня.
Очевидно, что создавать модель для каждой пары языков неразумно: число необходимых глубоких моделей достигло бы сотен, и для эффективного или оффлайн использования все их пришлось бы хранить на телефоне/ПК пользователя. Вместо этого Google решили создать одну обширную нейросеть, которая смогла бы выполнять перевод между любой парой языков, получая два токена (индикаторы и ввод), представляющие эти языки.
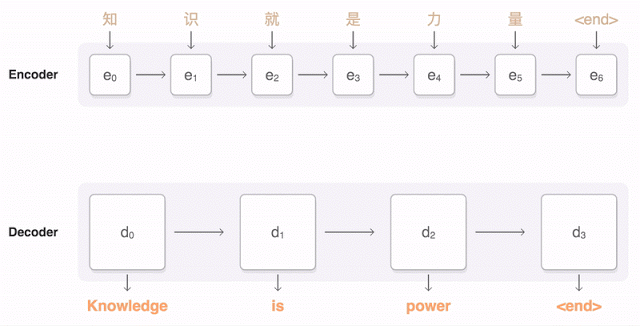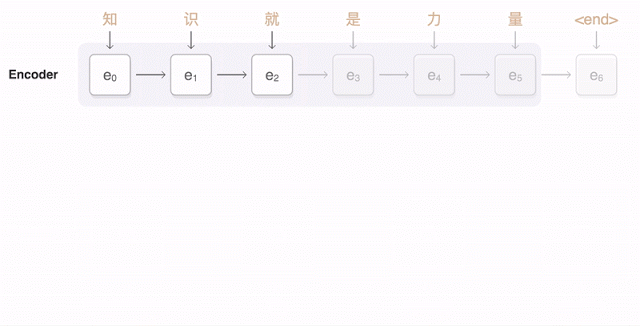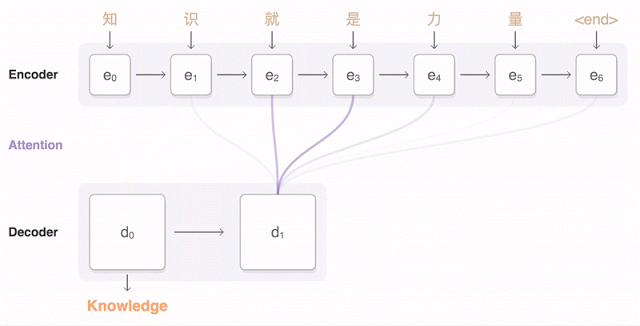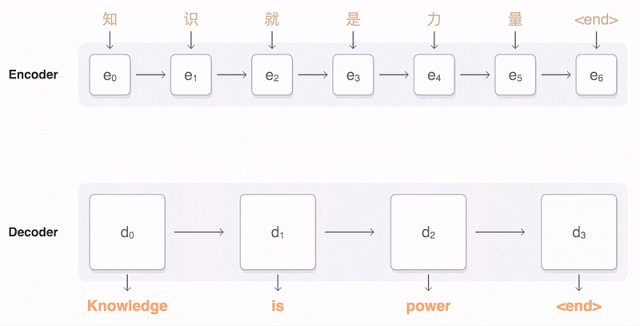
В основе данной модели была заложена структура энкодер-декодер. Один сегмент нейронной сети ищет возможность уменьшения исходного языка в его фундаментальное понятное машине ‘универсальное представление’. В то же время другой сегмент получает это представление и многократно преобразует лежащие в его основе смыслы в целевой язык. Данная архитектура называется ‘Transformer’. Нижеприведенный график наглядно представляет принцип ее работы, показывая, как начально сгенерированное содержимое используется в генерации последующих выводов, а также суть формирования последовательности слов.

Рассмотрите приведенную ниже альтернативную визуализацию этой связи энкодер-декодер (модель seq2seq). Промежуточное внимание между энкодером и декодером мы рассмотрим позже.
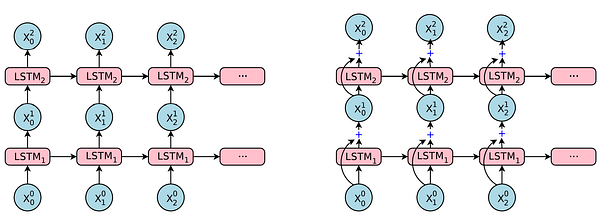
Энкодер состоит из восьми составленных в стек LSTM-слоев. Коротко говоря, LSTM — это улучшение поверх RNN (нейронной сети, спроектированной для последовательных данных), которое позволяет этой сети ‘запоминать’ полезную информацию, чтобы в дальнейшем делать более точные прогнозы. Чтобы решить проблему непоследовательности языка, первые два слоя добавляют двунаправленность. Розовые узлы указывают на чтение слева направо, а зеленые справа налево. Это позволяет GNMT применять различные грамматические структуры.
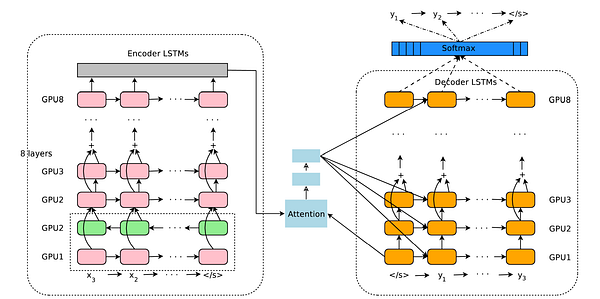
Модель декодера также выполнена из восьми LSTM-слоев. В данном случае они стремятся перевести зашифрованное содержимое в целевой язык.
Между этими двумя моделями располагается ‘Механизм внимания’. Человеку внимание помогает удерживать концентрацию на задаче и находить для нее решения, не отвлекаясь на стороннюю информацию. В модели GNMT механизм внимания помогает определить неизвестные сегменты сообщения и повысить их важность, чтобы при расшифровке они получили повышенный приоритет. Это решает большую часть проблемы ‘редких слов’, когда словам, встречающимся в наборе данных не так часто, уделяется больше внимания.
Для имитации правильного градиентного потока использовался пропуск соединений или соединения, перескакивающие через определенные слои. Как и в случае с моделью ResNet (остаточная сеть), обновление градиентов может быть перехвачено на одном определенном слое, влияя на идущие перед ним. В настолько глубокой нейронной сети, включающей 16 LSTM-слоев, их пропуск, позволяющий градиентам пересекать потенциально проблемные слои, необходим не только для ускорения обучения, но и для повышения производительности.
Создатели GNMT вложили много усилий в разработку эффективной низкоуровневой системы, выполняющейся на TPU — специализированном аппаратным тензорном процессоре для машинного обучения, спроектированным Google для оптимального обучения.
Интересным преимуществом использования одной модели для обучения всех переводов оказалась возможность их изучения не напрямую. Например, если GNMT обучалась только на англо-корейском, корейско-английском, японско-английском и англо-японском, то в итоге модель хорошо переводила с японского на корейский и наоборот несмотря на то, что напрямую этому не обучалась. Эта практика, также известная как обучение методом нулевого выстрела, существенно улучшила время обучения, необходимое для развертывания модели.
Особой пре- и постобработке подвергается ввод и вывод GNMT, включающий, к примеру, особые символы, часто встречающиеся в азиатских языках. В данном случае ввод токенизируется в соответствии со специально разработанной системой, использующей сегментацию слов и маркеры для начала, середины и конца каждого слова. Такие дополнения сделали связь между фундаментально различающимися представлениями языков более гибкой.
В качестве обучающих данных Google использовали документы и стенограммы Объединенных Наций, а также Европейского парламента. Так как в этих организациях вся документация содержит профессиональный высококачественный перевод на разные языки — эти данные послужили отличной стартовой точкой. Позже для внедрения понимания культурных особенностей языков, сленга и неформальных выражений, Google стали также использовать пользовательский ввод, предлагаемый сообществом.
GNMT оценивалась по разным метрикам. В процессе обучения эта модель использовала перплексивность журнала. Перплексивность — это форма энтропии, в частности энтропии Шеннона, поэтому легче будет начать ее объяснение с этого. Энтропия — это среднее число бит, используемое для шифрования информации, содержащейся в переменной. Следовательно перплексивность — это то, насколько хорошо модель вероятностей может предсказать выборку. Одним из примеров перплексивности может быть число символов, которые пользователь должен ввести в окно поиска, чтобы механизм отправки запроса оказался по меньшей мере на 70% уверен в том, что пользователь введет какой-либо один запрос. Такой метод является естественным выбором для оценки NLP-задач и моделей.
Для измерения степени приближенности машинного перевода к человеческому применяется показатель BLEU. В этом случае измерение производится по шкале от 0 до 1 с использованием алгоритма сопоставления строк. Данный метод до сих пор широко распространен, поскольку проявил высокую корреляцию с качеством человеческого перевода: верные слова вознаграждаются, а за верные последовательные слова и более длинные/сложные начисляются дополнительные бонусы.
Тем не менее данный алгоритм считает, что профессиональный человеческий перевод является идеальным, оценивает модель только по избранным предложениям и не отличается особой надежностью в трактовке вариаций фраз и синонимов. Поэтому высокий показатель BLEU (>0,7) обычно является признаком чрезмерного обучения.
Несмотря на это, ниже мы видим, что повышение данного дробного показателя продемонстрировало увеличение способности к моделированию языка:
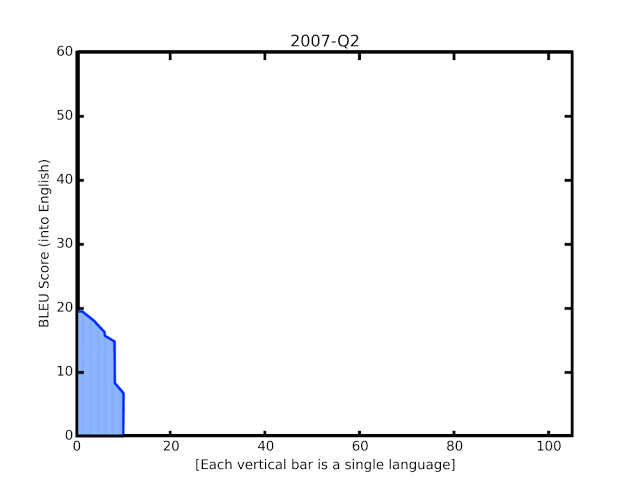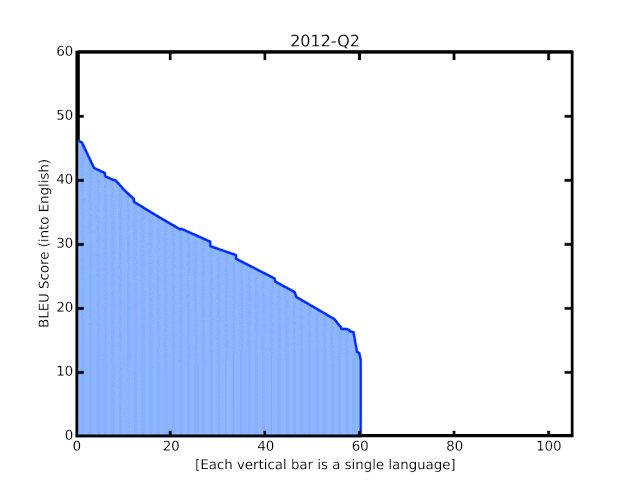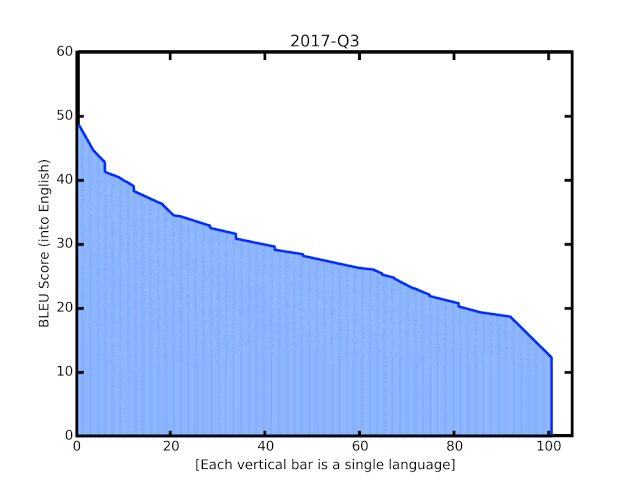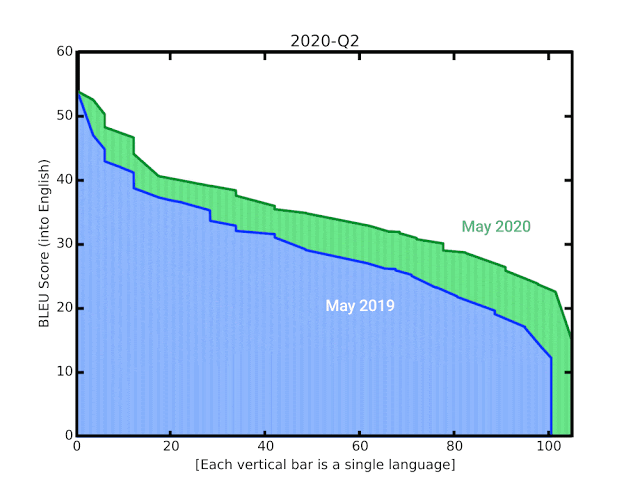
Используя наработки GNMT, Google запустили расширения, которые смогли выполнять визуальный перевод текста в реальном времени. Первая сеть определяла потенциальные буквы, которые передавались в сверточную нейронную сеть для распознавания. Далее распознанные слова передавались в GNMT для очередного распознавания и затем отображались в шрифте и стиле оригинала.

Вы только представьте, сколько сложностей сопряжено с созданием подобного сервиса: распознание отдельных букв, соединение воедино слов, определение размера и шрифта текста, правильное отображение картинки.
GNMT применяется и во многих других приложениях, хотя иногда с измененной архитектурой. Тем не менее данная модель является знаковой для NLP, демонстрируя чудеса легковесного, но при этом эффективного дизайна, выработанного благодаря ряду технологических прорывов, совершенных на протяжении нескольких лет и на сегодняшний день доступного каждому.
Ключевые моменты
- Существует множество сложных задач, в которых дело касается предоставления именно глобального сервиса переводов. Такая модель должна быть легковесной, но также понимать словарь, грамматику и связи между десятками языков.
- Системы переводов, основанные на правилах, и даже их усложненные варианты, работающие с фразами, не справляются с выполнением качественного перевода.
- GNMT использует архитектуру Transformer, в которой энкодер и декодер состоят из 8 LSTM-слоев каждый. Два первых слоя энкодера позволяют двунаправленное чтение, беря таким образом в расчет непоследовательную грамматику.
- Модель GNMT также использует пропуск соединений для обеспечения качественного градиентного потока.
- В GNMT было задействовано обучение методом нулевого выстрела, что позволило существенно ускорить сам процесс обучения, а также понимание языков.
- Модель обучалась на журнале перплексивности и формально оценивалась с помощью стандартной метрики BLEU.
Благодаря достижениям GNMT, вышедшим за рамки текстового перевода и позволившим выполнять уже перевод с изображения в изображение, а также из голоса в голос, глубокое обучение сделало огромный скачок в направлении понимания человеческого языка. Теперь GNMT можно рассматривать уже не в качестве некой эзотерической и непрактичной, а в виде инновационной, легковесной, и общедоступной модели.
Читайте также:
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Andre Ye: Breaking Down the Innovative Deep Learning Behind Google Translate




