
Метод опорных векторов (далее МОВ) — это техника машинного обучения с учителем. Она используется в классификации, может быть применена к регрессионным задачам.
Метод определяет границу принятия решения (далее ГПР) вместе с максимальным зазором, который разделяет почти все точки на два класса, оставляя место для неправильной классификации.
МОВ — улучшенная версия алгоритмов максимального зазора. Его преимущество заключается в том, что он может определять как линейную, так и нелинейную границу с помощью функций ядра, поэтому он подходит для реальных задач, где данные не всегда полностью разделимы прямой линией.
Разделяющие гиперплоскости
Цель МОВ — определить гиперплоскость (также называется “разделяющей” или “ГПР”), которая разделяет точки на два класса.
Для ее визуализации представим двумерный набор данных:
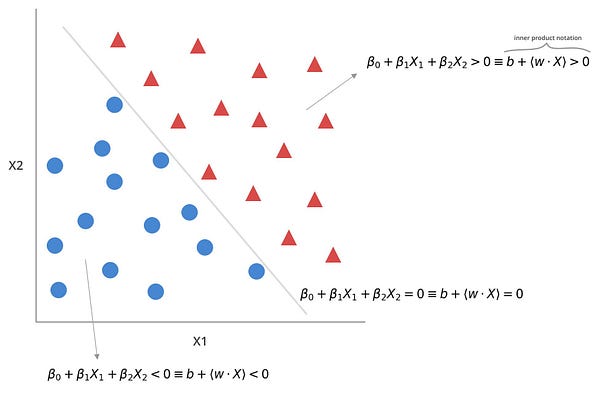
Гиперплоскостей, разделяющих точки, будет бесконечное множество, но поскольку мы работаем в двумерном пространстве, любая гиперплоскость всегда будет иметь (2–1) = 1 измерение (можно представить её простой линией регрессии).
В свою очередь, точки можно классифицировать, основываясь на том, где они находятся по отношению к ГПР:
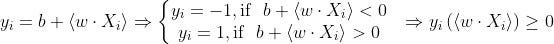
Если вы работаете с более чем двумя измерениями, например вектор объектов X имеет более чем два объекта, вы классифицируете сами векторы, а не точки.
Все векторы, которые падают ниже ГПР, принадлежат классу -1, а если выше, то 1.
Зазоры для повышения достоверности прогноза
Мы использовали обучающие данные для определения ГПР. А что насчет качества предсказаний?
Если вектор находится далеко от границы, то можно быть уверенным в его классе, даже если модель в чем-то ошибочна. Но какой класс назначить в ином случае?
МОВ также рисует границу зазора вокруг ГПР. Цель — максимально отделить векторы от нее. Зазор дает больше уверенности в прогнозах: векторы находятся как минимум на расстоянии длины этого зазора от границы, поэтому картина становится более ясной.
Положение зазора определяется с помощью векторов, наиболее близких к границам. Поэтому те из них, что лежат на зазоре, являются опорными векторами.
С зазором в качестве буфера вектор можно классифицировать по его местонахождению относительно зазора, длина которого представлена M.
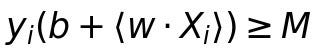
Пространство для неправильной классификации
Добавление зазора улучшает качество предсказаний, но этого недостаточно для реальных задач.
МОВ, как и классификаторы опорных векторов, использует важную характеристику, которая позволяет ошибаться и присваивать неверный класс некоторым векторам.
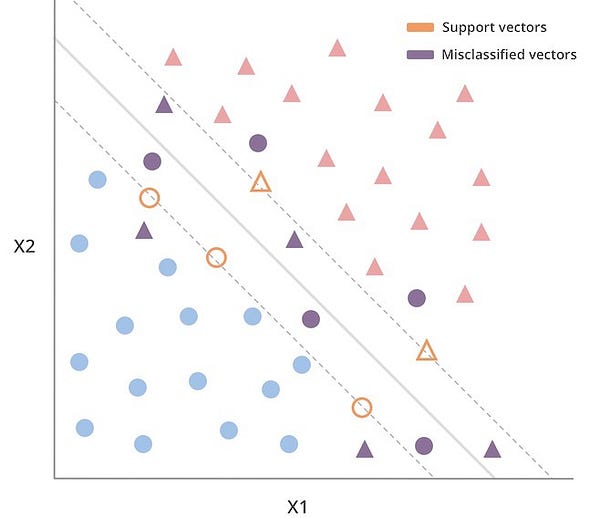
Вместо разделения векторов на два класса МОВ идет на компромисс, позволяя некоторым векторам попадать внутрь зазора и на неправильную сторону границы.
МОВ допускает неправильную классификацию в процессе обучения. Он лучше работает с большинством векторов в тестовом наборе.
Помимо зазора, модель теперь включает в себя слабые переменные, которые сообщат:
• классифицировано ли тестовое наблюдение правильно или нет;
• где наблюдение находится относительно ГПР и зазора.
Они могут иметь три возможных значения:

- 0 — классифицировано верно;
- >0 — неверная сторона границы зазора;
- >1 — неверная сторона гиперплоскости.
Число неправильно классифицированных векторов ограничено параметром C:
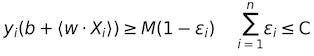
Эта модель точнее, но она все еще построена поверх классификаторов максимального зазора. Например, если C = 0 (то есть слабые переменные могут быть равны 0), модель возвращается к такому классификатору. Таким образом, есть линейная граница решения и максимально большой зазор, внутри которого не могут находиться векторы.
Рост числа слабых переменных влияет на количество допустимых ошибок, что, в свою очередь, затрагивает ширину зазора из-за выбора различных опорных векторов. Также он контролирует компромисс между смещением и дисперсией модели.

Большое число слабых переменных:
- Большой зазор.
- Низкий уровень дисперсии.
- Большое смещение.
- Больше опорных векторов.
Малое число слабых переменных:
- Малый зазор.
- Высокий уровень дисперсии.
- Низкое смещение.
- Меньше опорных векторов.
Наличие некоторого пространства для ошибок делает МОВ более гибким, но подход применим к ограниченному набору проблем.
В реальных задачах трудно разделить данные на два класса линейной границей.
Метод опорных векторов
Этот метод разделяет характеристики классификаторов запаса. Уникальность его в том, что он может определять как линейные, так и нелинейные ГПР.
Для второго МОВ использует функции для преобразования исходного пространства объектов в новое, которое может представлять эти нелинейные отношения.
Предположим, вы увеличиваете исходное пространство объектов возведением во вторую степень. Вы применили квадратичную функцию к исходному набору объектов. Теперь в этом расширенном пространстве есть оригинальная функция и ее квадратичная версия. Здесь неявно существует функция, которая сопоставляет эти два пространственных объекта.
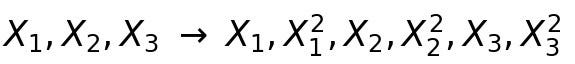
Если вы попытаетесь нарисовать границу решения в исходном пространстве объектов, она будет иметь квадратичную форму. Но если вы тренируете модель в расширенном пространстве, то обнаружите линейную границу, которая разделяет два класса. Поскольку это является преобразованием, квадратичная граница в исходном пространстве объектов соответствует линейной в расширенном.
Функции выше называются ядрами. Они работают как функции сходства между наблюдениями в обучающих и тестовых наборах.
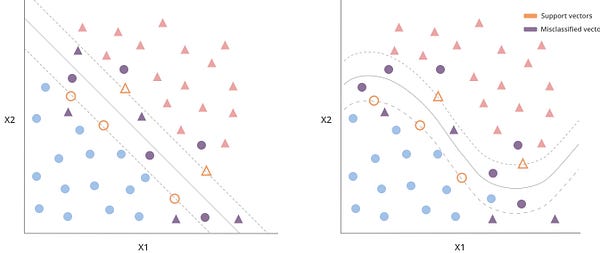
Когда есть модель, представленная внутренними результатами, можно подключить функцию ядра. Линейное ядро — это аналог применения линейных преобразований к пространству объектов. И в этом случае это то же, что и классификатор опорных векторов, потому что ГПР линейна.
С полиномиальными ядрами вы проецируете исходное пространство объектов в полиномиальное. Граница, разделяющая классы, определяется полиномом более высокого порядка.
Использование ядер отличает классификаторы от метода опорных векторов, что открывает путь к решению более сложных задач. Но увеличение пространства признаков означает рост вычислительных требований. При большомпространстве функций подгонка модели станет дорогостоящей с точки зрения времени и ресурсов.
Ядра добавляют преимущество. МОВ не вычисляет преобразование каждого наблюдения в расширенное пространство. Используется трюк с ядром — вычисляется внутреннийрезультат наблюдений в этом пространстве. Этот трюкгораздо менее требователен.
МОВ делает два важных допущения:
- Данные линейно разделимы. Даже если линейная граница находится в расширенном пространстве.
- Модель представлена с использованием внутренних результатов, что допускает применение ядер.
Примеры
Я сгенерировал случайный набор данных и разделил его на два разных класса:
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def generate_random_dataset(size):
"""Генерация случайного набора данных, которая следует за квадратичным распределением
"""
x = []
y = []
target = []
for i in range(size):
# класс 0
x.append(np.round(random.uniform(0, 2.5), 1))
y.append(np.round(random.uniform(0, 20), 1))
target.append(0)
# класс 1
x.append(np.round(random.uniform(1, 5), 2))
y.append(np.round(random.uniform(20, 25), 2))
target.append(1)
x.append(np.round(random.uniform(3, 5), 2))
y.append(np.round(random.uniform(5, 25), 2))
target.append(1)
df_x = pd.DataFrame(data=x)
df_y = pd.DataFrame(data=y)
df_target = pd.DataFrame(data=target)
data_frame = pd.concat([df_x, df_y], ignore_index=True, axis=1)
data_frame = pd.concat([data_frame, df_target], ignore_index=True, axis=1)
data_frame.columns = ['x', 'y', 'target']
return data_frame
# Генерация набора данных
size = 100
dataset = generate_random_dataset(size)
features = dataset[['x', 'y']]
label = dataset['target']
# Получение 20% от набора данных для обучения
test_size = int(np.round(size * 0.2, 0))
# Разделение набора данных на обучающие и тестовые наборы
x_train = features[:-test_size].values
y_train = label[:-test_size].values
x_test = features[-test_size:].values
y_test = label[-test_size:].values
# Построение графика для обучающего набора
fig, ax = plt.subplots(figsize=(12, 7))
# Удаление верхней и правой границ
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
# Добавление основных линий сетки
ax.grid(color='grey', linestyle='-', linewidth=0.25, alpha=0.5)
ax.scatter(features[:-test_size]['x'], features[:-test_size]['y'], color="#8C7298")
plt.show()Перед любой классификацией тренировочный набор выглядит так:
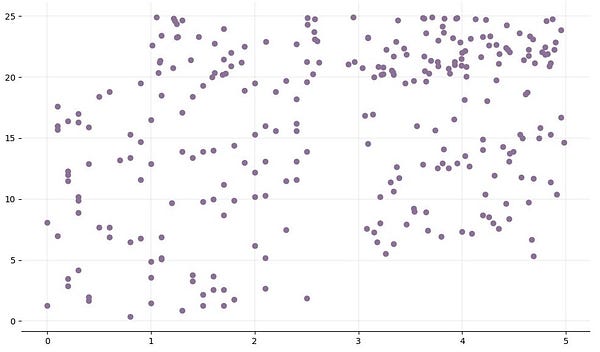
Между двумя группами точек данных есть небольшое пространство. Но ближе к центру неясно, к какому классу принадлежит каждая точка.
Квадратичная кривая может решить эту проблему. Подгоним МОВ с полиномиальным ядром второй степени.
from sklearn import svm
model = svm.SVC(kernel='poly', degree=2)
model.fit(x_train, y_train)Чтобы увидеть результат, можно построить ГПР и зазор вместе с набором данных.
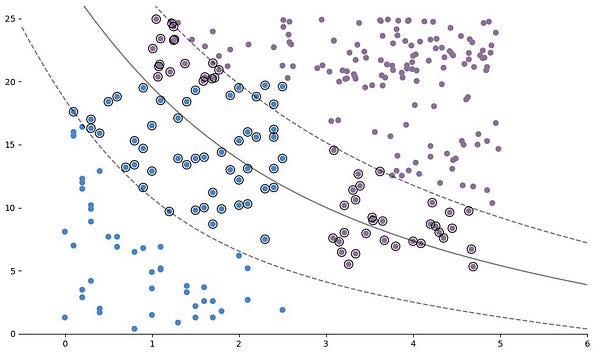
Код для построения границы решения и зазоров:
fig, ax = plt.subplots(figsize=(12, 7))
# Удаление верхней и правой границ
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['right'].set_visible(False)
# Создание сетки для оценки модели
xx = np.linspace(-1, max(features['x']) + 1, len(x_train))
yy = np.linspace(0, max(features['y']) + 1, len(y_train))
YY, XX = np.meshgrid(yy, xx)
xy = np.vstack([XX.ravel(), YY.ravel()]).T
train_size = len(features[:-test_size]['x'])
# Присвоение классам различных цветов
colors = y_train
colors = np.where(colors == 1, '#8C7298', '#4786D1')
# Построение графика набора данных
ax.scatter(features[:-test_size]['x'], features[:-test_size]['y'], c=colors)
# Получение разделяющей гиперплоскости
Z = model.decision_function(xy).reshape(XX.shape)
# Рисунок границ решения и запасов
ax.contour(XX, YY, Z, colors='k', levels=[-1, 0, 1], alpha=0.5, linestyles=['--', '-', '--'])
# Выделение опорных векторов окружностями
ax.scatter(model.support_vectors_[:, 0], model.support_vectors_[:, 1], s=100, linewidth=1, facecolors='none', edgecolors='k')
plt.show()Если мы рассчитаем точность этой модели по сравнению с тестовым набором, то получим хороший результат, учитывая, что набор очень мал и генерируется случайно.
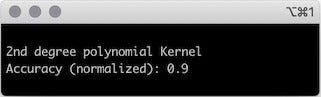
from sklearn.metrics import accuracy_score
predictions_poly = model.predict(x_test)
accuracy_poly = accuracy_score(y_test, predictions_poly)
print("2nd degree polynomial Kernel\nAccuracy (normalized): " + str(accuracy_poly))Точность хорошая, но может ли упрощенный подход решить проблему? Чтобы соответствовать МОВ с линейным ядром, нужно обновить параметр ядра.
model = svm.SVC(kernel='linear')
model.fit(x_train, y_train)model = svm.SVC(kernel='linear')
model.fit(x_train, y_train)
Нарисуйте ГПР аналогично:
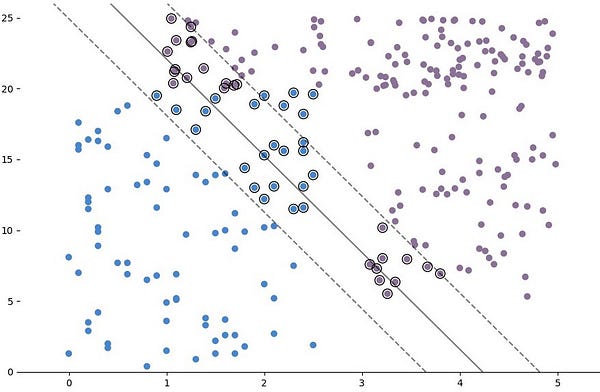
Неправильно классифицированных точек стало меньше, как и точек внутри зазора. Точность этой модели немного лучше, чем у той, что имеет полиномиальное ядро.
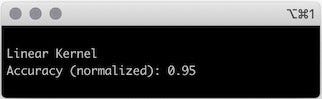
Как выяснилось, для этой задачи более простая модель — МОВ с линейным ядром — оказалась лучшим решением.
Спасибо за чтение!
Читайте также:
- Выбор оптимального алгоритма поиска в Python
- 5 секретов наилучшего использования кортежей в Python
- Утиная типизация в Python - 3 примера
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Carolina Bento: Support Vector Machines explained with Python examples

")



