
R — очень мощный язык, разработанный специально для анализа и визуализации данных и машинного обучения, что делает его обязательным к изучению для любого начинающего специалиста по данным.
R особенно удобен для линейной алгебры. Встроенные типы данных, такие как векторы и матрицы, хорошо сочетаются со встроенными функциями, такими как алгоритмы решения собственных значений и определителей, а также с возможностями динамического индексирования.
В этой вводной в статье про R рассмотрим следующие реализации линейной алгебры:
Векторы
- присваивание векторов;
- векторные операции;
- генерирование последовательностей;
- логические векторы;
- пропущенные значения;
- индексирование векторов.
Массивы и матрицы
- массивы;
- индексация массивов;
- индексация матриц;
- внешнее произведение двух матриц;
- демонстрация всех возможных определителей одноразрядных матриц 2×2;
- обобщённое транспонирование массива;
- умножение матриц;
- линейные уравнения и инверсия;
- собственные значения и собственные векторы;
- сингулярное разложение и определители;
- выравнивание методом наименьших квадратов и QR-разложение;
- формирование блочных матриц.
Векторы
Присваивание векторов
R оперирует структурами данных, самой простой из которых является числовой вектор — упорядоченный набор чисел. Чтобы создать вектор x с четырьмя элементами 1, 2, 3 и 4, можно использовать объединяющую функцию c().
x <- c(1, 2, 3, 4)
Здесь используется оператор присваивания <-, указывающий на назначаемый объект. В большинстве случаев <- можно заменить на =.
Также можно использовать функцию assign():
assign('x', c(1, 2, 3, 4))
Оператор <- считается сокращённым вариантом этой функции.
Присваивание векторов работает и в обратном направлении:
c(1, 2, 3, 4) -> x
Векторные операции
Векторы используются различными способами.
Операция y <- c(x, 0, x) присвоит вектор 1, 2, 3, 4, 0, 1, 2, 3, 4 переменной y.
Векторы можно свободно перемножать и дополнять константами:
v <- 2*x + y + 1
Заметьте, что эта операция верна, даже когда x и y имеют разную длину. В данном случае R просто будет повторять x (иногда дробно), пока не достигнет длины y. Поскольку y равен 9 числам в длину, а x — 4, x повторится 2.25 раз пока не совпадёт с длиной y.
Можно использовать все арифметические операторы: +, -, *, / и ^, а также log, exp, sin, cos, tan, sqrt и многие другие. max(x) и min(x) отображают наибольший и наименьший элементы вектора x, а length(x) — количество элементов x; sum(x) выдаёт сумму всех элементов x, а prod(x) — их произведение.
mean(x) вычисляет выборочное среднее, var(x) возвращает выборочную дисперсию, sort(x) возвращает вектор того же размера, что и x, элементы в котором расположены в порядке возрастания.
Генерация последовательностей
В R существует множество методов для генерации последовательностей чисел. 1:30 аналогичен c(1, 2, …, 29, 30). Двоеточие имеет более высокий приоритет в выражении, поэтому 2*1:15 вернёт c(2, 4, …, 28, 30), а не c(2, 3, …, 14, 15).
30:1 используется для генерации последовательности в обратном направлении.
Для генерации последовательностей можно использовать и функцию seq(). seq(2,10) возвращает такой же вектор, что и 2:10. В seq(), можно также указать длину шага: seq(1,2,by=0.5) возвращает c(1, 1.5, 2).
Аналогичная функция rep() копирует объект различными способами. Например, rep(x, times=5) вернёт пять копий x впритык.
Логические векторы
Логические значения в R — TRUE, FALSE и NA. Логические векторы задаются условиями. val <- x > 13 задаёт val в качестве вектора той же длины, что x, со значением TRUE, если условие выполняется, и FALSE, если нет.
Логические операторы в R: <, <=, >, >=, == и !=, означающие, соответственно, меньше чем, меньше чем или равно, больше чем, больше чем или равно, равно или не равно.
Пропущенные значения
Функция is.na(x) возвращает логический вектор того же размера, что и x, со значение TRUE, если соответствующий элемент для x равен NA.
x == NA отличается от is.na(x), поскольку NA является не значением, а маркером для недоступной величины.
Второй тип “пропущенного значения” создаётся численными вычислениями, например 0/0. В этом случае значения NaN (не числа) рассматриваются как значения NA, то есть is.na(x) вернёт TRUE и для NA, и для NaN значений. is.nan(x) используется только для определения значений NaN.
Индексирование векторов
Первый вид индексации — через логический вектор. y <- x[!is.na(x)] устанавливает y значениям x, не равным NA или NaN.
(x+1)[(!is.na(x)) & x>0] -> z устанавливает z значениям x+1, больше 0 и не являющимся Na или NaN.
Второй метод осуществляется с вектором положительных целых значений. В этом случае значения должны быть в наборе {1, 2, …, length(x)}. Для формирования результата соответствующие элементы вектора выбираются и объединяются в этом порядке. Важно помнить, что, в отличие от других языков, в R первый индекс равен 1, а не 0.
x[1:10] возвращает первые 10 элементов x, предполагая, что length(x) не менее 10. c(‘x’, ‘y’)[rep(c(1,2,2,1), times=4)] создаёт символьный вектор длиной 16, где ‘x’, ‘y’, ‘y’, ‘x’ повторяются четыре раза.
Вектор отрицательных целых чисел определяет значения, которые должны быть исключены. y <- x[-(1:5)] устанавливает y всем значениям x, кроме первых пяти.
Наконец, вектор символьных строк может использоваться, когда у объекта есть атрибут name для идентификации его компонентов. Для <- c(1, 2, 3, 4) можно задать имя каждому индексу вектора names(fruit) <- c(‘mango’, ‘apple’, ‘banana’, ‘orange’). Затем элементы можно вызывать по имени lunch <- fruit[c(‘apple’, ‘orange’)].
Преимущество этого подхода в том, что иногда буквенно-цифровые имена запомнить легче, чем индексы.
Обратите внимание, что индексированное выражение может встречаться на принимающей стороне присвоения, где оно только для этих элементов вектора. Например, x[is.na(x)] <- 0 заменяет все значения NA и NaN в векторе x на 0.
Другой пример: y[y<0] <- -y[y<0] аналогичен y <- abs(y) — код просто заменяет все значения меньше 0 на отрицательные значения.
Массивы и матрицы
Массивы
Массив — это проиндексированный набор записей данных, не обязательно численный.
Вектор размерности — это вектор неотрицательных чисел. Если длина равна k, тогда массив k-размерный. Размерности индексируются от единицы вверх до значения, указанного вектором размерности.
Вектор может использоваться R в качестве массива, как атрибут dim. Если z — вектор из 1500 элементов, присвоение dim(z) <- c(100, 5, 3) означает, что z теперь представлен как массив 100 на 5 на 3.
Индексирование массивов
На индивидуальные элементы массива можно ссылаться, указав имя массива и в квадратных скобках индексы, разделённые запятыми.
Первое значение вектора a — 3 на 4 на 6 — может быть вызвано как a[1, 1, 1], а последнее как a[3, 4, 6].
a[,,] отображает массив полностью, следовательно, a[1,1,] берёт первую строку первого 2-размерного сечения a.
Индексирование матриц
Следующий код генерирует массив 4 на 5: x <- array(1:20, dim = c(4,5)).
Массивы определяются вектором значений и размерностью матрицы. Значения вычисляются сначала сверху вниз, затем слева направо.
array(1:4, dim = c(2,2)) вернёт
1 3
2 4а не
1 2
3 4В матрицах индексов запрещены отрицательные индексы, а значения NA и ноль разрешены.
Внешнее произведение двух матриц
Важной операцией с векторами является внешнее произведение. Если a и b — это два численных массива, их внешним произведением является массив, вектор размерности которого получается объединением двух векторов размерности, а вектор данных достигается формированием всех возможных произведений элементов вектора данных a и элементов вектора b. Внешнее произведение вычисляется с помощью оператора %o%:
ab <- a %o% b
Другой способ:
ab <- outer(a, b, ‘*’)
Фактически любую функцию можно применить к двум массивам, используя внешнюю () функцию. Предположим, мы определили функцию f <- function(x, y) cos(y)/(1+x²). Функцию можно применить к двум векторам x и y с помощью z <- outer(x, y, f).
Демонстрация всех возможных определителей одноразрядных матриц 2×2
Рассмотрим определители матриц 2 на 2 [a, b; c, d], где каждая запись представляет собой неотрицательное число от 0 до 9. Задача: найти определители всех возможных матриц этой формы и отобразить на графике высокой плотности частоту, с которой встречается значение.
Или, перефразируя, нужно найти распределение вероятности определителя, если каждая цифра выбирается независимо и равномерно случайным образом.
Один из умных способов сделать это — использовать внешнюю функцию дважды.
d <- outer(0:9,0:9)
fr <- table(outer(d, d, ‘-’))
plot(fr, xlab = ‘Determinant’, ylab = ‘Frequency’)Первая строка присваивает d этой матрице:
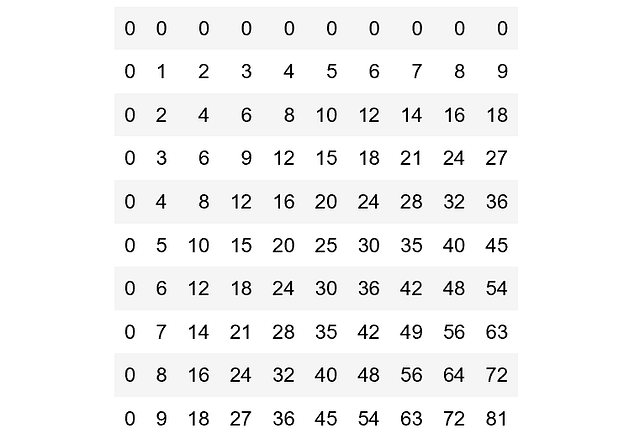
Вторая строка снова использует внешнюю функцию для расчёта всех возможных определителей. Последняя строка строит график.
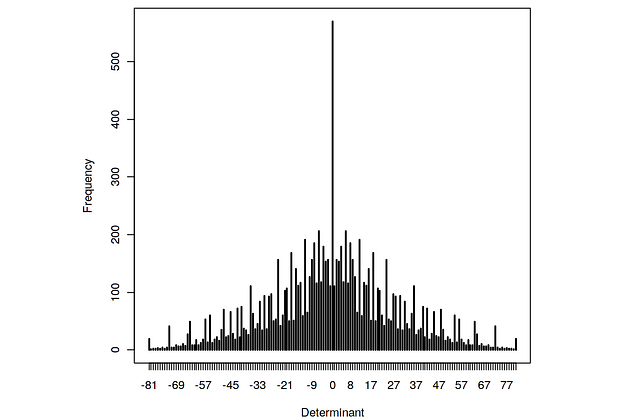
Обобщённое транспонирование массива
Функция aperm(a, perm) используется для перестановки массива a. Аргументом perm должна быть перестановка чисел {1,…, k}, где k — количество индексов в a. Результатом функции будет массив того же размера, что и a, но прежняя размерность, заданная perm[j], становится новой размерностью j-th.
Проще понять, если думать об этом как об обобщённом транспонировании матриц. Если A — это матрица, тогда B — просто результат перестановки матрицы A:
B <- aperm(A, c(2, 1))
В таких особых случаях перестановку осуществляет функция t().
Умножение матриц
Для умножения матриц используется оператор %*% . Если A и B являются квадратными матрицами одинакового размера, A*B — это поэлементное произведение двух матриц. A %*% B — это скалярное произведение (произведение матриц).
Если x — вектор, тогда x %*% A %*% x — его квадратичная форма.
crossprod() осуществляет перекрёстные произведения. Таким образом crossprod(X, y) аналогична операции t(X) %*% y, но более эффективна.
diag(v), где v — вектор — задаёт диагональную матрицу с элементами вектора в качестве диагональных элементов. diag(M), где m — матрица — задаёт вектор основных диагональных элементов M (так же как и в Matlab). diag(k), где k — единичное числовое значение — возвращает единичную матрицу k на k.
Линейные уравнения и инверсия
Решение линейных уравнений является инверсией умножения матриц. Если
b <- A %*% x
с заданными только A и b, вектор x — решение системы линейных уравнений, которое быстро решается в R:
solve(A, b)
Собственные значения и собственные векторы
Функция eigen(Sm) вычисляет собственные значения и собственные векторы симметричной матрицы Sm. Результат — это список, где первый элемент отображает значения, а второй — векторы. ev <- eigen(Sm) присваивает этот список ev.
ev$val — это вектор собственных значений Sm, и ev$vec — матрица соответствующих собственных векторов.
Для больших матриц лучше избегать вычисления собственных векторов, если они не нужны, используя выражение:
evals <- eigen(Sm, only.values = TRUE)$values
Сингулярное разложение и определители
Функция svd(m) принимает произвольный матричный аргумент m и вычисляет его сингулярное разложение. Оно состоит из 1) матрицы ортонормированных столбцов U с тем же пространством столбцов, что и m, 2) второй матрицы ортонормированных столбцов V, пространство столбцов которой является пространством строк m, 3) и диагональной матрицы положительных элементов D:
m = U %*% D %*% t(V)
det(m) используется для вычисления определителя квадратной матрицы m.
Выравнивание методом наименьших квадратов и QR-разложение
Функция lsfit() возвращает список заданных результатов процедуры выравнивания методом наименьших квадратов. Присваивание наподобие этого:
ans <- lsfit(X, y)
выдаёт результаты выравнивания методом наименьших квадратов, где y — это вектор наблюдений, а X — проектная матрица.
ls.diag() используется для диагностики регрессии.
Тесно связанной функцией является qr().
b <- qr.coef(Xplus,y)
fit <- qr.fitted(Xplus,y)
res <- qr.resid(Xplus,y)Они вычисляют ортогональную проекцию y на диапазон X в fit, проекцию на ортогональное дополнение в res и вектор коэффициентов для проекции в b.
Формирование блочных матриц
Матрицы можно строить из других векторов и матриц с помощью функций cbind() и rbind().
cbind() формирует матрицы, связывая матрицы горизонтально (поколоночно), а rbind() связывает матрицы вертикально (построчно).
В присвоении X <- cbind(arg_1, arg_2, arg_3, …) аргументами cbind() должны быть либо векторы любой длины, либо столбцы одинакового размера (одинаковым количеством строк).
rbind() выполняет соответствующую операцию для строк.
Читайте также:
- R - язык для статистической обработки данных. Часть 1/3
- Анализ текста средствами языка программирования R
- 5 базовых статистических концептов, которые должен знать каждый специалист по обработке данных
Перевод статьи Andre Ye: Intro to R: Linear Algebra





