
Итак, вы написали Python-скрипт, который обучает и оценивает модель машинного обучения. И теперь вам хочется оптимизировать гиперпараметры и повысить производительность модели.
Я помогу!
В данной статье я покажу вам, как преобразовать скрипт в целевую функцию, которую можно оптимизировать через любую библиотеку оптимизации гиперпараметров.
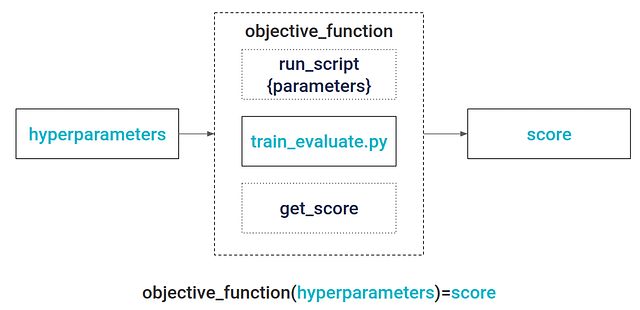
Весь процесс состоит из 3 шагов, изучив которые вы научитесь оптимизировать параметры моделей так, как будто знали это всегда.
Готовы?
Поехали!
Полагаю, ваш скрипт main.py выглядит примерно так:
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
data = pd.read_csv('data/train.csv', nrows=10000)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
(X_train, X_valid,
y_train, y_valid )= train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'objective': 'binary',
'metric': 'auc',
'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
model = lgb.train(params, train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
print('validation AUC:', score)Шаг 1: отделяем параметры поиска от кода
Возьмите параметры, которые хотите оптимизировать, и поместите их в словарь в начало скрипта. Это действие позволит вам эффективно отделить параметры поиска от остального кода.
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
data = pd.read_csv('../data/train.csv', nrows=10000)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'objective': 'binary',
'metric': 'auc',
**SEARCH_PARAMS}
model = lgb.train(params, train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
print('validation AUC:', score)Шаг 2: заворачиваем логику обучения и оценки в функцию
Теперь вы можете поместить всю логику обучения и оценки внутрь функции train_evaluate. Эта функция принимает параметры на вход, а на выходе выдает результат проверки.
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
SEARCH_PARAMS = {'learning_rate': 0.4,
'max_depth': 15,
'num_leaves': 20,
'feature_fraction': 0.8,
'subsample': 0.2}
def train_evaluate(search_params):
data = pd.read_csv('../data/train.csv', nrows=10000)
X = data.drop(['ID_code', 'target'], axis=1)
y = data['target']
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1234)
train_data = lgb.Dataset(X_train, label=y_train)
valid_data = lgb.Dataset(X_valid, label=y_valid, reference=train_data)
params = {'objective': 'binary',
'metric': 'auc',
**search_params}
model = lgb.train(params, train_data,
num_boost_round=300,
early_stopping_rounds=30,
valid_sets=[valid_data],
valid_names=['valid'])
score = model.best_score['valid']['auc']
return score
if __name__ == '__main__':
score = train_evaluate(SEARCH_PARAMS)
print('validation AUC:', score)Шаг 3: запускаем скрипт оптимизации гиперпараметров
Осталось совсем немного.
Теперь мы используем train_evaluate в качестве цели в любой библиотеке оптимизации неизвестной функции («черного ящика»).
Я предпочитаю Scikit Optimize, но вы можете выбрать другую библиотеку.
Процедура следующая:
- задаем область поиска
SPACE; - создаем целевую функцию
objectiveдля минимизации; - запускаем оптимизацию через функцию
forest_minimize.
В данном примере я опробую 100 различных конфигураций и начну с 10 случайно выбранных наборов параметров.
import skopt
from script_step2 import train_evaluate
SPACE = [
skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),
skopt.space.Integer(1, 30, name='max_depth'),
skopt.space.Integer(2, 100, name='num_leaves'),
skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),
skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')]
@skopt.utils.use_named_args(SPACE)
def objective(**params):
return -1.0 * train_evaluate(params)
results = skopt.forest_minimize(objective, SPACE, n_calls=30, n_random_starts=10)
best_auc = -1.0 * results.fun
best_params = results.x
print('best result: ', best_auc)
print('best parameters: ', best_params)Вот и все.
Объект results содержит информацию о лучшей оценке и комбинации параметров для ее получения.
Примечание:
Если вы хотите визуализировать процесс обучения, а затем сохранить диагностические диаграммы, то добавьте обратный вызов и вызов функции, которые будут записывать каждый поиск значения гиперпараметра в Neptune. С этим вам поможет вспомогательная функция из библиотеки neptune-contrib.
import neptune
import neptunecontrib.monitoring.skopt as sk_utils
import skopt
from script_step2 import train_evaluate
neptune.init('jakub-czakon/blog-hpo')
neptune.create_experiment('hpo-on-any-script', upload_source_files=['*.py'])
SPACE = [
skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),
skopt.space.Integer(1, 30, name='max_depth'),
skopt.space.Integer(2, 100, name='num_leaves'),
skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),
skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')]
@skopt.utils.use_named_args(SPACE)
def objective(**params):
return -1.0 * train_evaluate(params)
monitor = sk_utils.NeptuneMonitor()
results = skopt.forest_minimize(objective, SPACE, n_calls=100, n_random_starts=10, callback=[monitor])
sk_utils.log_results(results)
neptune.stop()Теперь при запуске вариации параметров вы увидите следующее:
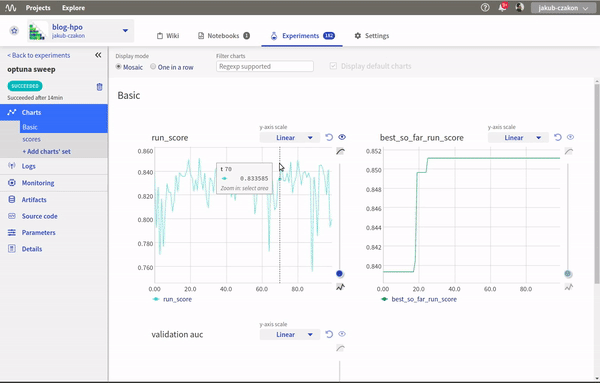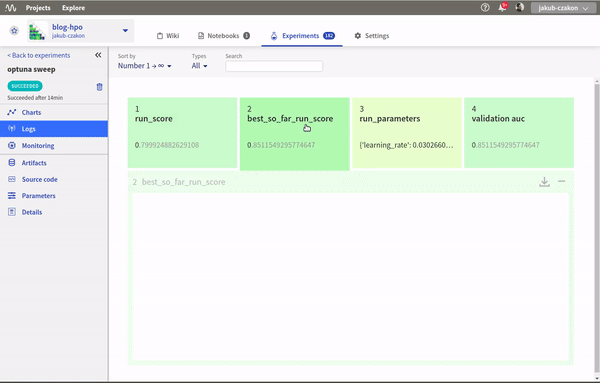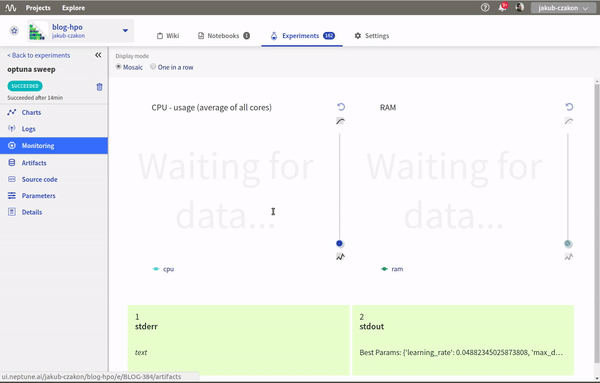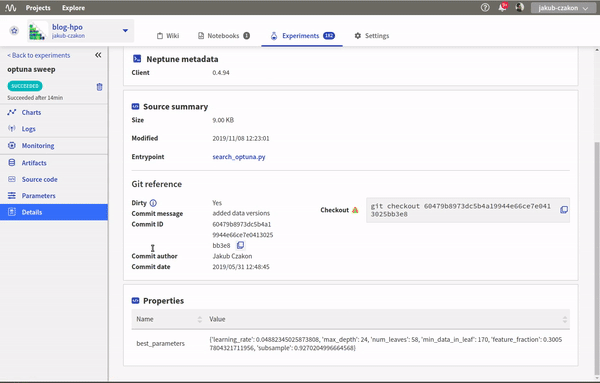
Посмотреть весь код, графики и результаты можно в эксперименте skopt по вариации гиперпараметров.
Заключение
В данной статье вы научились оптимизировать гиперпараметры любого Python-скрипта в 3 шага.
Надеюсь, эти знания помогут вам создавать качественные модели машинного обучения быстрее и проще.
Читайте также:
- 15 Python пакетов, которые нужно попробовать
- Избегайте этих нелепых ошибок при работе с Python
- Перестаньте использовать range() в цикле for в Python
Перевод статьи Jakub Czakon:How to Do Hyperparameter Tuning on Any Python Script in 3 Easy Steps





