
Jupyter Notebook — важный инструмент для специалиста по науке о данных. С его помощью можно выполнять базовые задачи, такие как очистка данных, визуализация, создание моделей машинного обучения и многие другие. В Jupyter Notebook можно использовать Python и R (в зависимости от ядра), сохранять результаты выполнения кода в ячейках и делиться ими с другими людьми.
Анализ данных в Python
В Python можно группировать данные и создавать сводные таблицы с помощью встроенных функций из библиотеки pandas.
Классический способ создания сводных таблиц — с помощью старого доброго метода pivot_table. Как и у большинства методов Python, его синтаксис прост и удобен для чтения.
Однако чем сложнее логика слоя сводной таблицы, тем больше времени потребуется для ее написания. Более того, результирующая сводная таблица всегда является статической, а не интерактивной. При каждой смене расположения данных в сводной сетке, необходимо переписывать код. Возможно, вам не придется вносить много изменений, однако это время можно было бы потратить на то, чтобы лучше разобраться в данных.
Как создавать интерактивные сводные таблицы данных в Python
Самая интересная особенность этого подхода заключается в возможности сохранить полученный ноутбук с интерактивными компонентами визуализации данных в HTML и отправить его партнерам по команде. Они смогут открыть его в браузере, поэкспериментировать со сводной таблицей и диаграммами, сделать собственные наблюдения, сохранить отчет и отправить его обратно. Такой подход может значительно повысить продуктивность анализа данных в целом.
Мы будем работать в JupyterLab — пользовательском интерфейсе для Jupyter Notebooks, в котором можно найти все элементы классического Jupyter, такие как ноутбуки и файловый браузер. Помимо этого, JupyterLab предлагает более расширенную функциональность: возможность устанавливать расширения, разворачивать, сворачивать и перетаскивать ячейки, а также предоставляет функцию автозаполнения вкладок.
Создание отчета в JupyterLab
Запускаем JupyterLab. Для начала импортируем необходимые библиотеки Python: pandas, JSON и модуль display из IPython. Во всех этих библиотеках встроен дистрибутив Anaconda, однако, если вы не работаете с ним, то установите эти библиотеки глобально или в виртуальной среде.
- pandas — неотъемлемый инструмент для работы со структурами данных в Python.
- IPython — API для интерактивных и параллельных вычислений в Python. display — это его модуль, представляющий собой API для инструментов отображения в IPython.
- Библиотека json предоставляет API для кодирования и декодирования JSON. Если вы уже работали с модулями
marshalилиpickle, то знакомы с этим API.
Для визуализации данных мы будем использовать библиотеку JavaScript Flexmonster Pivot Table & Charts.
Для демонстрации воспользуемся набором данных «Цены на авокадо» из Kaggle. Это легкий набор, содержащий разумное количество полей. Вы можете выбрать любой понравившийся вам набор данных.
▶ Загрузите данные. С помощью pandas прочитайте данные CSV на фрейме данных. Удалите «Unnamed: 0» — столбец индекса, который часто появляется при чтении файлов CSV.
df = pd.read_csv('avocado.csv')
df.drop(columns=['Unnamed: 0'], inplace=True)
▶ Вызовите метод to_json() на фрейме данных, чтобы преобразовать его в строку JSON и сохранить в переменную json_data.
json_data = df.to_json(orient='records')
Параметр orient определяет ожидаемый формат строки JSON. Устанавливаем его в значение records. Это значение переводит объект в структуру, подобную списку: [{column -> value}, … , {column -> value}]. Именно с этим форматом работает Flexmonster.
▶ Теперь создадим экземпляр Flexmonster с помощью вложенного словаря. Здесь нужно указать все необходимые параметры инициализации и передать декодированные данные компоненту. Для декодирования JSON воспользуемся методом json.loads().
flexmonster = {
"container": "#pivot-container",
"componentFolder": "https://cdn.flexmonster.com/",
"width": "100%",
"height": 430,
"toolbar": True,
"report": {
"dataSource": {
"type": "json",
"data": json.loads(json_data) # decoding JSON
},
"slice": {
"reportFilters": [
{
"uniqueName": "Date.Year",
"filter": {
"members": [
"date.year.[2018]"
]
}
},
{
"uniqueName": "Date.Month",
"filter": {
"members": [
"date.month.[january]"
]
}
}
],
"rows": [
{
"uniqueName": "region"
},
{
"uniqueName": "type"
}
],
"columns": [
{
"uniqueName": "[Measures]"
}
],
"measures": [
{
"uniqueName": "Total Volume",
"aggregation": "sum"
},
{
"uniqueName": "Total Bags",
"aggregation": "sum"
}
],
"sorting": {
"column": {
"type": "desc",
"tuple": [],
"measure": {
"uniqueName": "Total Volume",
"aggregation": "sum"
}
}
}
},
"options": {
"grid": {
"type": "classic"
}
},
"formats": [
{
"name": "",
"decimalPlaces": 2
}
]
}
}Как видите, мы сразу устанавливаем срез, опции и форматы. Если пропустить этот шаг, то в сводной таблице отобразится срез по умолчанию.
▶ Теперь преобразуем объект Python в JSON с помощью json.dumps():
flexmonster_json_object = json.dumps(flexmonster)
▶ Следующий шаг — определение функции, которая отображает сводную таблицу непосредственно в ячейку. Для этого определяем многострочную строку и передаем ее в импортированную функцию HTML:
def render_pivot_table(json_component):
layout = '''
<script src="https://cdn.flexmonster.com/flexmonster.js"></script>
<h1>Flexmonster Integration with Jupyter Notebook</h1>
<div id="pivot-container"></div>
<script>
new Flexmonster({0});
</script>
'''.format(json_component)
return HTML(layout)▶ И, наконец, передаем JSON в функцию рендеринга и вызываем ее:
render_pivot_table(flexmonster_json_object)
На странице отображается интерактивная сводная таблица. Набор данных готов к работе: вы можете переупорядочить поля в сетке, изменять агрегаты, настраивать фильтрацию и сортировку, форматировать значения и многое другое для создания уникального отчета. Более того, если вы пропустите способ отображения записей в фрейме данных, то сможете переключиться из сводного режима в плоское представление. Таким образом, можно увидеть данные в исходном виде, но с интерактивной функциональностью.
Сводная таблица выглядит следующим образом:
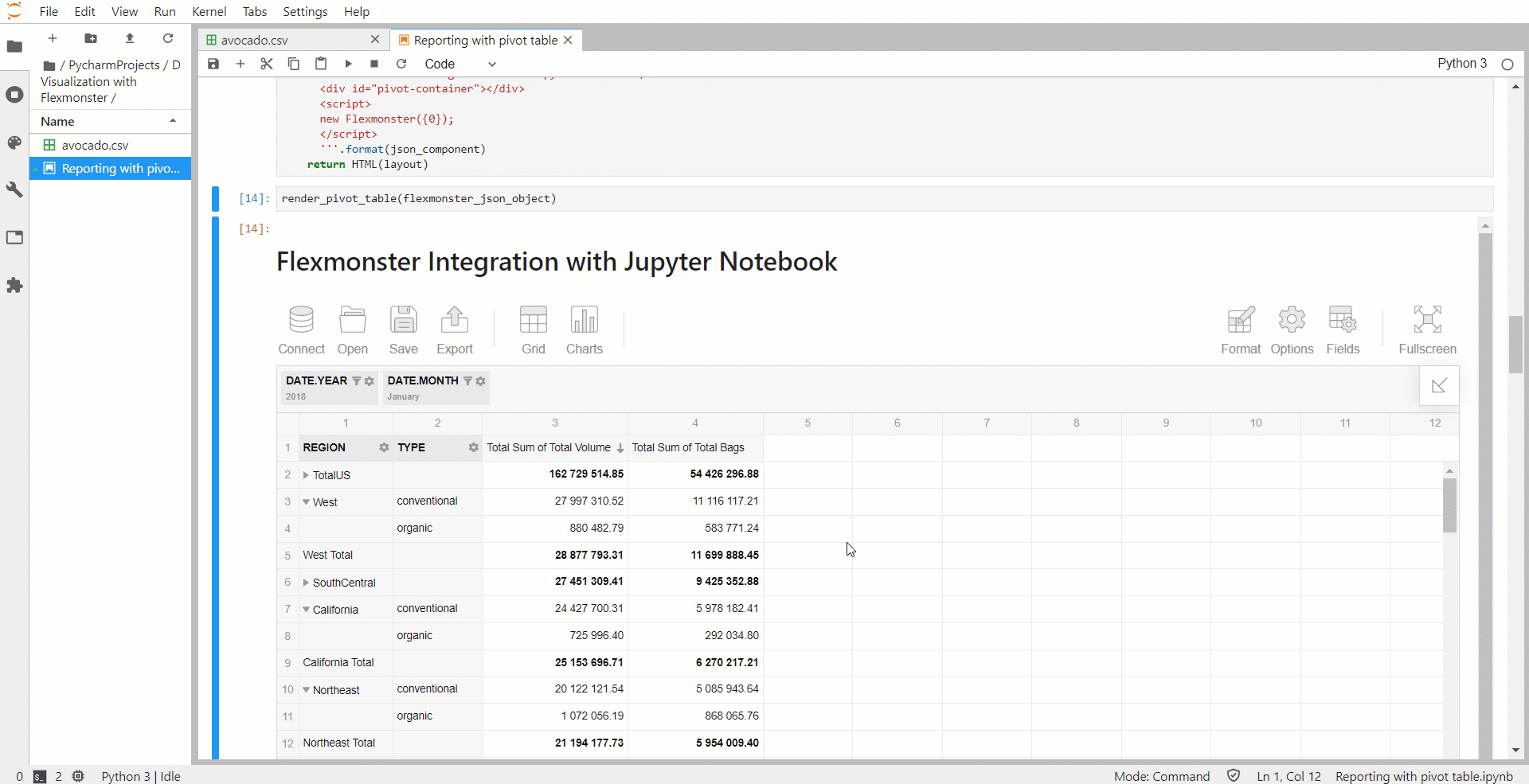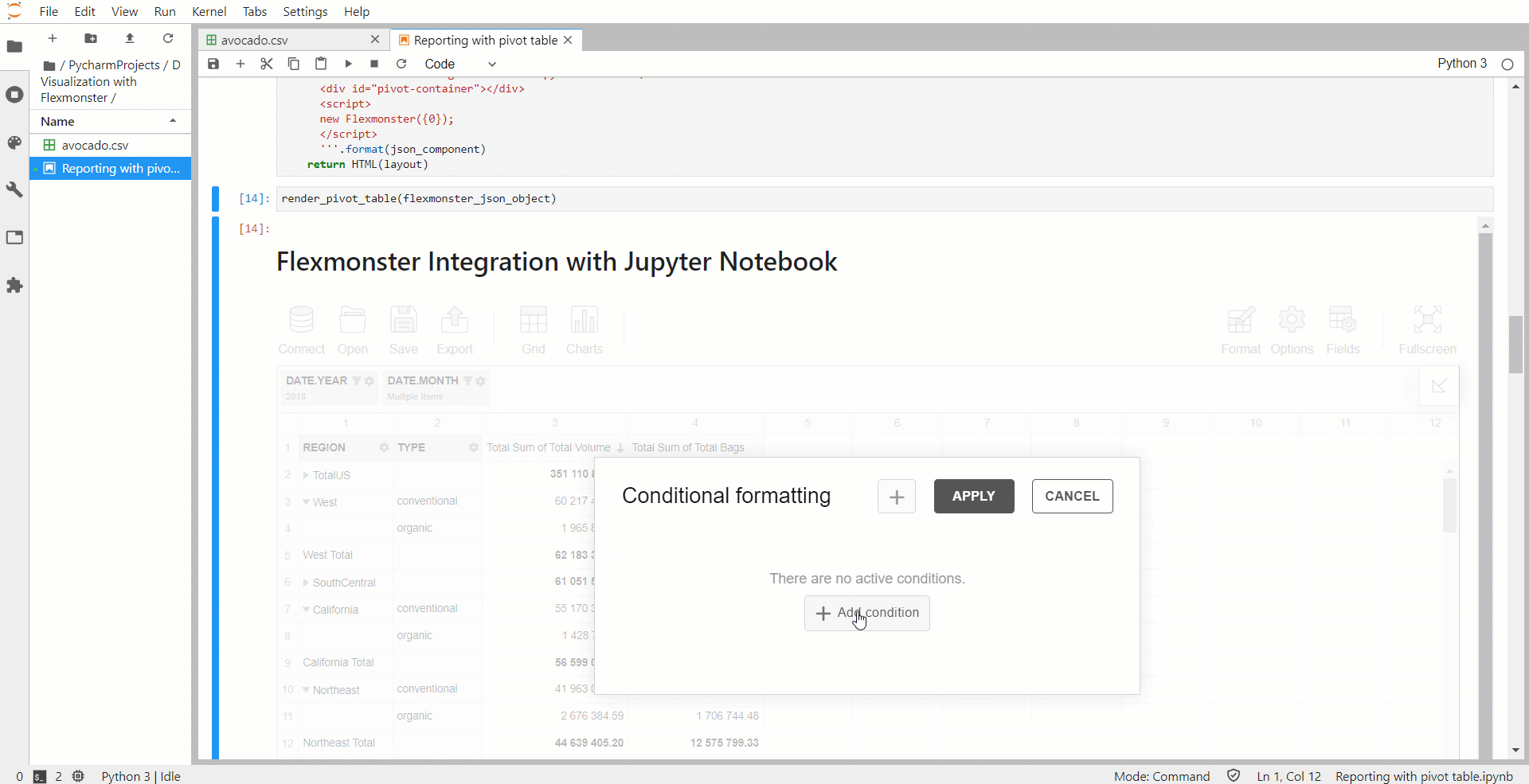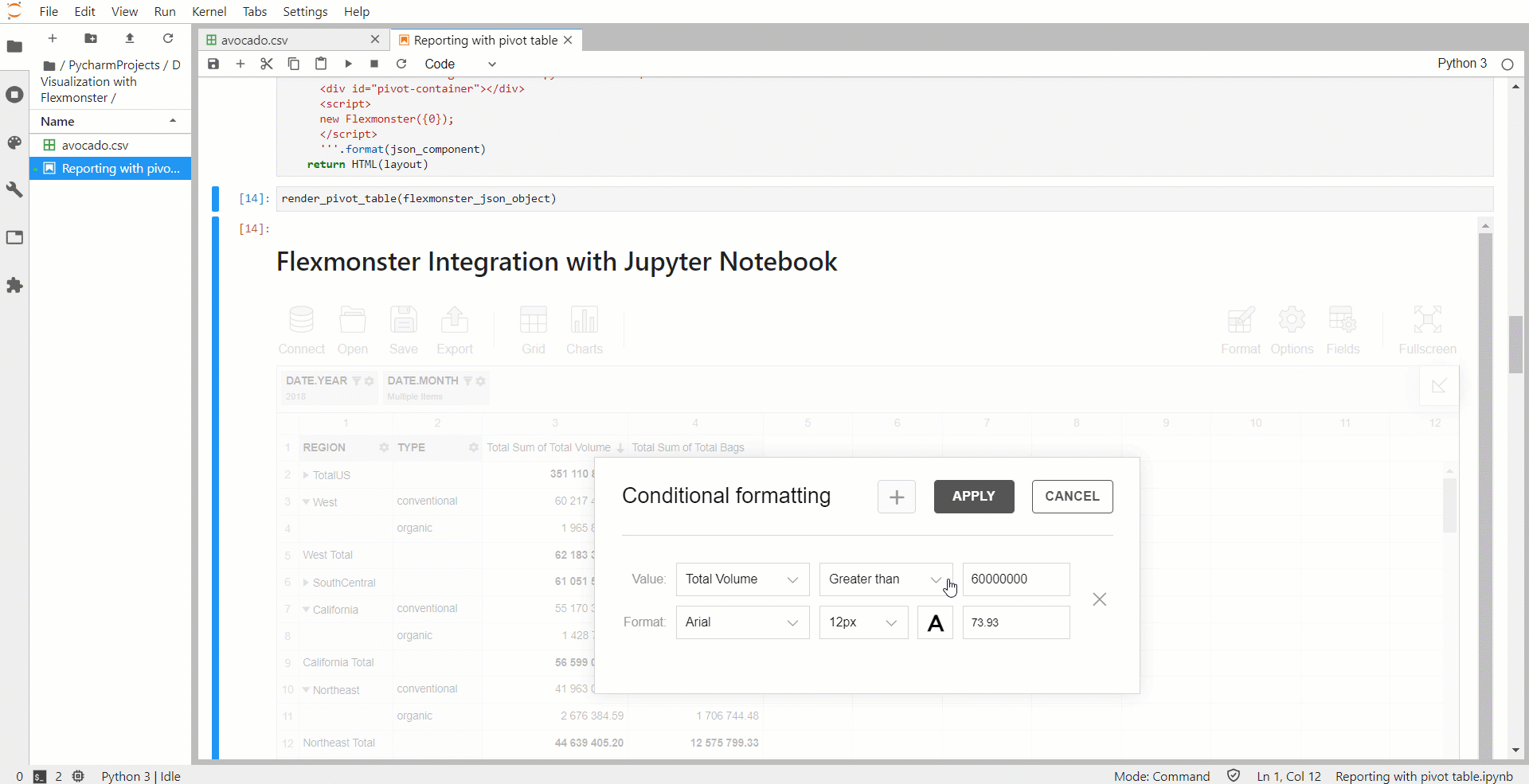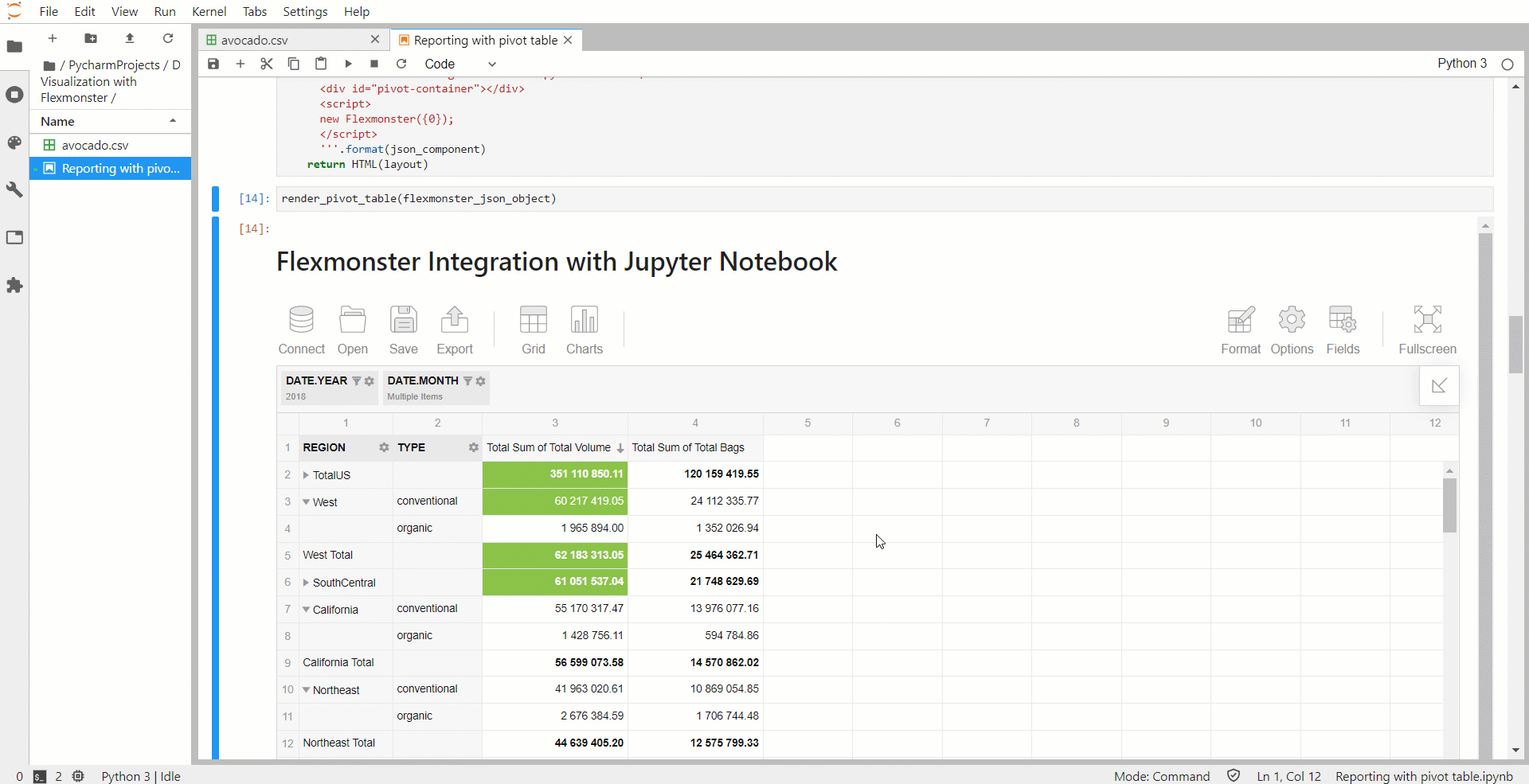
Вы также можете применить условное форматирование, чтобы сосредоточиться на самых важных значениях.
Создание панели индикаторов в Jupyter Notebook
Теперь немного усложним логику, добавив больше элементов в ноутбук. Две сводные диаграммы сделают визуализацию данных более универсальной. Для этого определяем дополнительную функцию, которая принимает несколько компонентов JSON и отображает их на странице. Ее логика выглядит так же, как и логика одной сводной таблицы. Компоненты сводных диаграмм определяются так же, как компоненты сводных таблиц.
В срезах отчетов для сводных диаграмм можно установить фильтры Top X для ограничения количества категорий, отображаемых в диаграммах, чтобы сделать их более аккуратными и компактными.
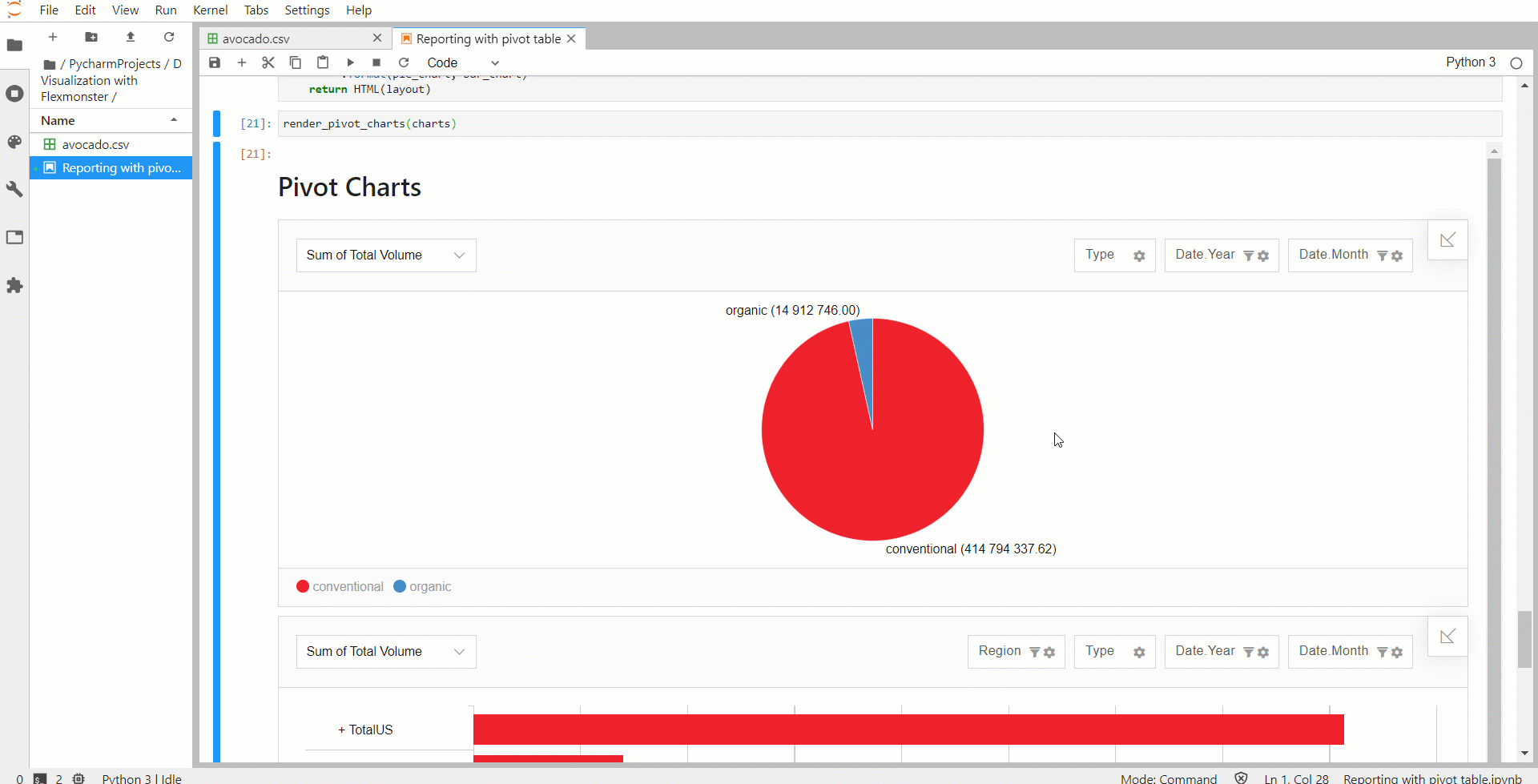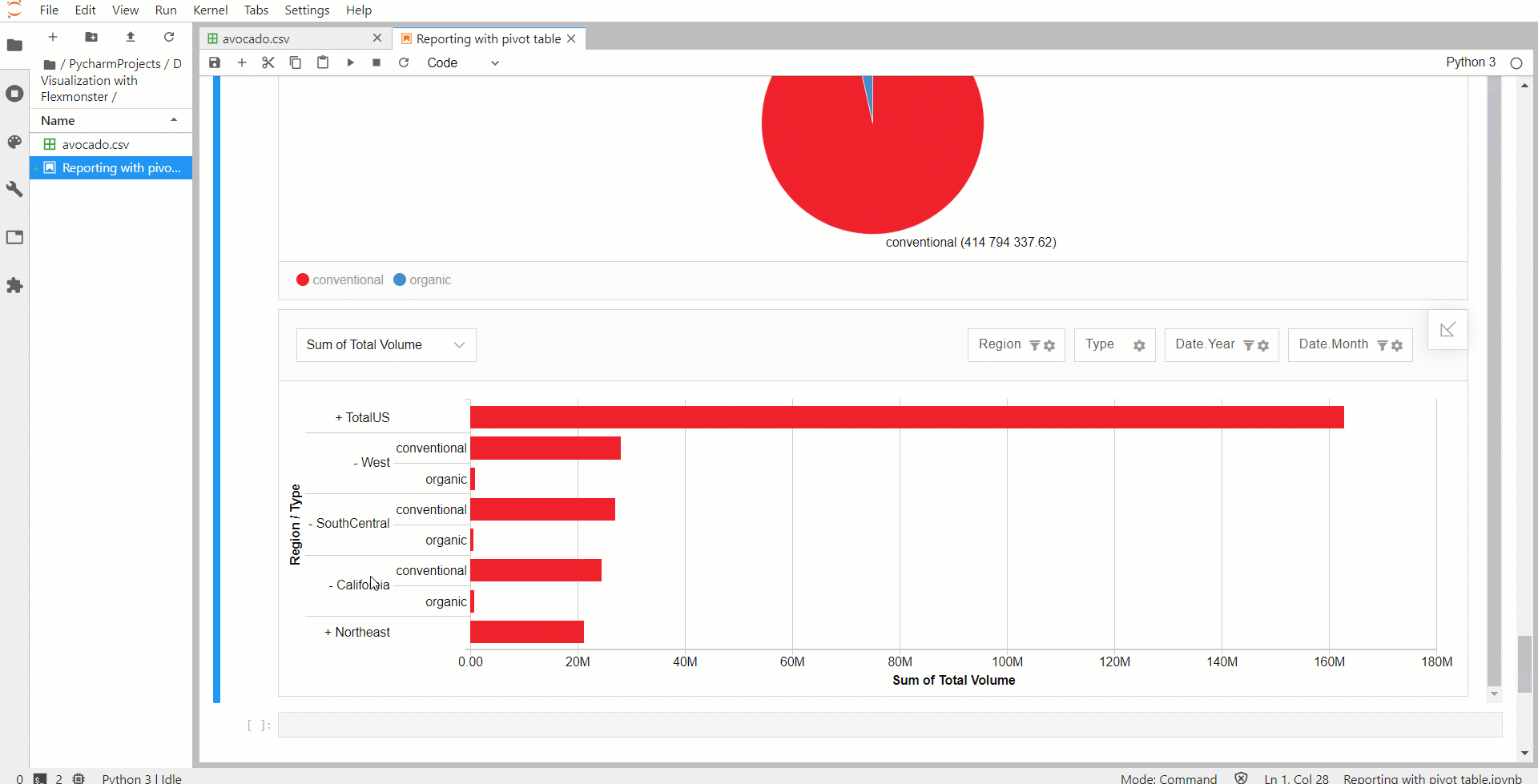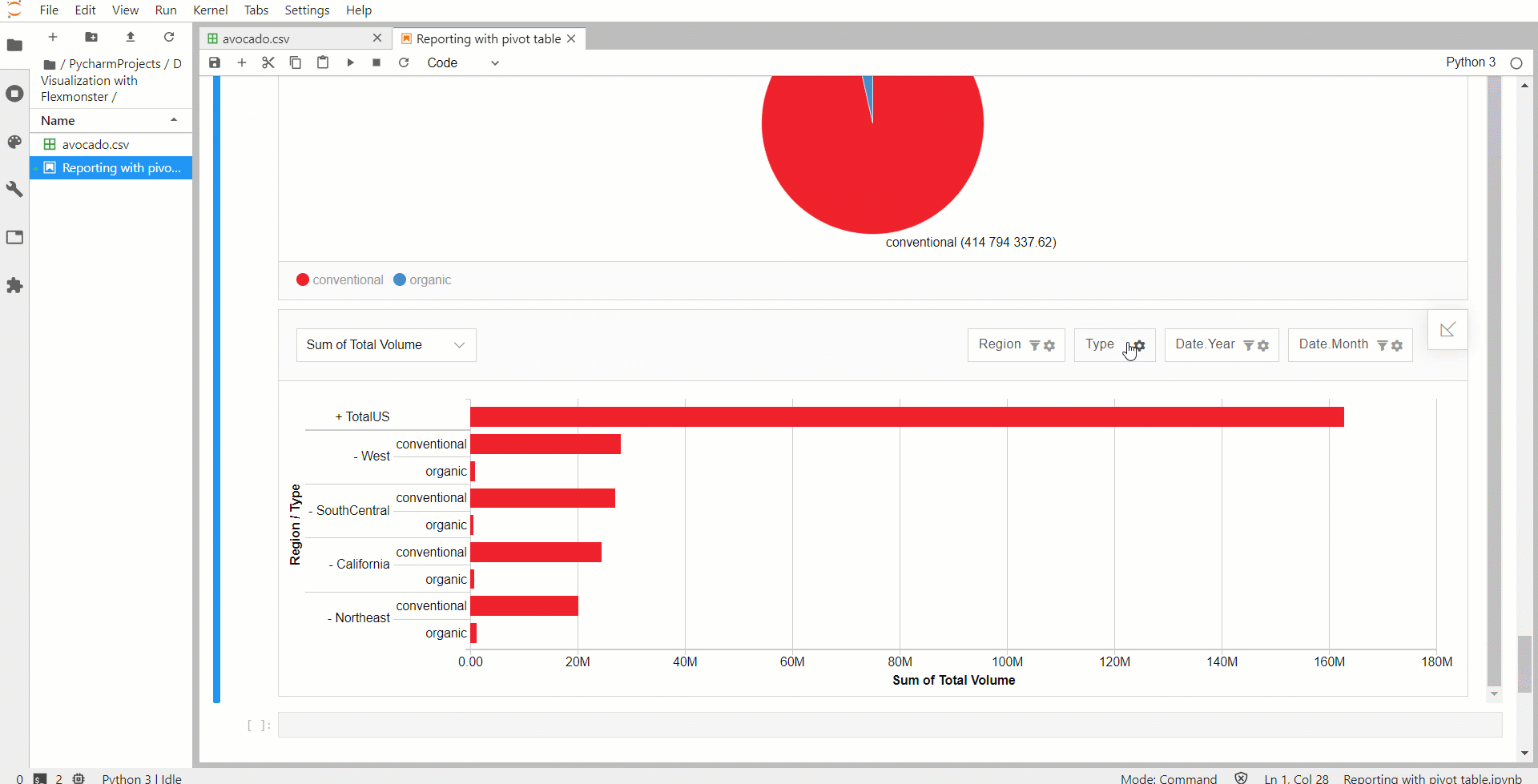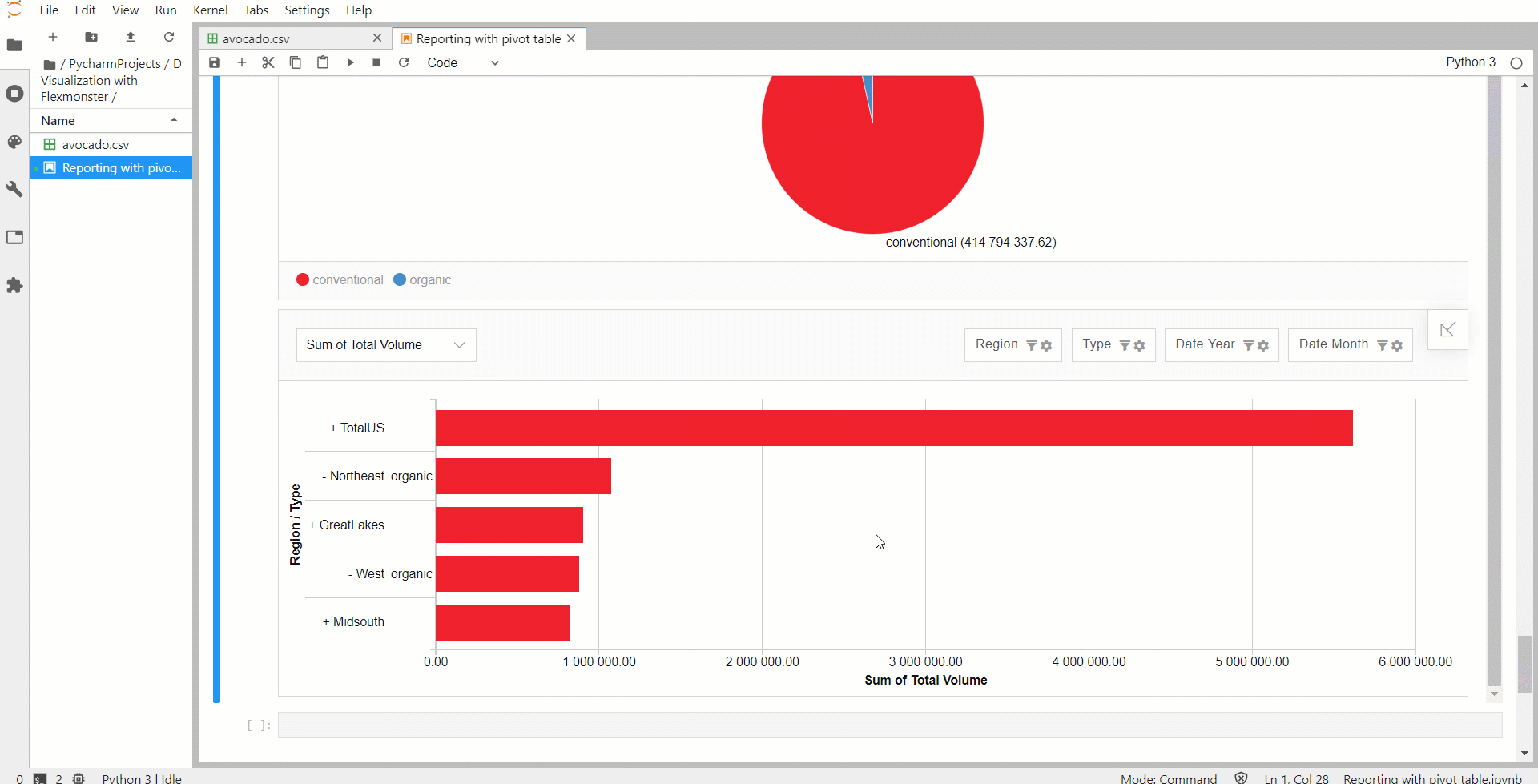
Интерактивная панель индикаторов в Jupyter Notebook готова к работе!
Заключение
Мы рассмотрели новый способ манипулирования и представления данных в Jupyter Notebook с помощью Python и библиотеки визуализации данных JavaScript. Как вы могли заметить, настройка не требует много кода и времени.
Выполнив ее однажды, вы сможете исследовать данные в привычном рабочем пространстве.
Этот подход освобождает вас от переписывания фрагментов кода при каждой необходимости взглянуть на данные под новым углом, а также прекрасно сочетается с главной идеей Jupyter Notebooks — сделать визуализацию и анализ данных интерактивными и гибкими.
Полную версию кода можно найти на GitHub. ?
Расширенные опции
Краткий список основных функций, с помощью которых можно улучшить отчеты:
- Отображение
В большинстве случаев реальные данные неаккуратны и непоследовательны: поля могут быть названы с использованием разных случаев, непонятных сокращений и т. д. Для уточнения можно воспользоваться отображением (mapping) — свойством отчета, которое устанавливает конфигурации представлений, применяемых к источнику данных. Еще одним преимуществом этой функциональности форматирования является явная настройка типов данных. С ее помощью можно указать компоненту способ обработки полей, что повлияет на выбор агрегатов, доступных для иерархий полей.
В примере GitHub показано, как определить объект mapping и установить его в сводную таблицу.
- Экспорт
Сводная таблица содержит методы и события JavaScript API. Вы можете настроить сохранение отчетов в различных форматах локально или в удаленных точках, таких как серверы, с помощью метода exportTo.
- Расчетные значения
Чтобы ввести новые формулы в отчет, можно добавить расчетные значения.
Читайте также:
- 4 совета по улучшению Jupyter Notebooks
- Прокачка Jupyter Notebooks
- Как легко оптимизировать Jupyter Notebook. Часть 1
Перевод статьи Veronika Rovnik: Interactive Reporting in Jupyter Notebook





