
В своём дипломном проекте я решил продолжить работать с естественным языком, фильмами и IBM Watson. В предыдущем проекте я визуализировал психологические профили персонажей фильмов, а в этом проекте решил пойти еще дальше. Позвольте несколько вводных слов до нашего погружения в проект.
Проблема

До того как я стал специалистом по данным, я был погружён в дизайн и в 2015 году основал свою компанию Screenshot Production. Мы работали индивидуально под каждого человека, чтобы он ощутил себя частью чего-то большего. В продажах мы ориентировались на результаты предварительного опроса.
Такой метод сильно воздействует, но не масштабируется. Мы обычно были в состоянии разместить 100–150 человек за выходные, и билеты должны были быть непомерно дорогими, только чтобы окупить затраты на организацию.
Основной вопрос проекта был таким: можем ли мы использовать науку о данных и глубокое обучение с генерацией, чтобы обеспечить такой же эффективный и персонализированный опыт в виде нарратива и воздействовать на сотни тысяч людей одновременно? Другими словами, можем ли мы использовать социальный профиль пользователя в сочетании с вымышленным диалогом, чтобы создать надёжный, интерактивный и полностью персонализированный нарратив?
До того как начать радоваться, позвольте дать короткий ответ: не сейчас. Генерация текста относительно молода как область, а мой опыт не так обширен для лонгридов. Но я создал генератор коротких историй. Это шаг к цели.
Методы, данные и процессы
Как и в предыдущем проекте, я использовал корпус фильмов, подготовленный университетом Калифорнии в Санта-Круз. Этот корпус разбит по жанрам и содержит диалоги из 960 фильмов. Диалоги отделены от описания сцен.
Я очистил и обработал данные с Pandas, разбив их по персонажам. Затем отфильтровал по следующему условию: сто строк и не менее трёх слов в каждой, чтобы получить главных героев вместе с диалогами, которые ярко их характеризуют.
Затем я создал базу данных с иерархической структурой, содержащую жанр, название, персонажа и диалоги для всех жанров:
def process_df():
for genre, titles in sorted_genre_dict_items:
print(genre)
genre_file_char_dict[genre] = {}
titles = sorted(titles)
for title in titles:
print('\t' + title)
genre_file_char_dict[genre][title] = {}
os.chdir(genre)
with codecs.open(title + '_dialog.txt', 'r', 'utf8') as fp:
f = fp.read()
text = clean_text(f)
speaker = re.findall(r"([A-Z]+\s?[A-Z]+[^a-z0-9\W])",text)
dialogue = re.compile('[A-Z]+\s?[A-Z]+[^a-z0-9\W]').split(text)[1:]
movie_df = pd.DataFrame(list(zip(speaker, dialogue)), columns=['Character', 'Dialogue'])
movie_df['Dialogue'] = movie_df['Dialogue'].str.lower()
movie_df = movie_df.groupby('Character').filter(lambda x: len(x) > 100)
movie_df = movie_df[movie_df.Dialogue.str.count(' ') > 3]
char_list = movie_df.Character.unique()
os.chdir('../')
for idx, char in enumerate(char_list):
if char in good_char_list:
char_df = movie_df[movie_df['Character'] == char] #отдельный датафрейм для каждого персонажа
genre_file_char_dict[genre][title][char] = char_df
process_df()Затем пропустил каждого персонажа через IBM Watson, чтобы получить психологические портреты. Учтите, что Watson нуждается в отдельном конфигурировании, а ниже написана функция, чтобы пропустить данные через Watson:
for genre, titles in genre_file_char_dict.items():
#print(genre)
for title in titles:
#print('\t' + title)
chars = genre_file_char_dict[genre][title]
for char, df in chars.items():
#print('\t\t' + char)
text = df['Dialogue'].values
combined_text = ''
for line in text:
combined_text += line + '\n'
if len(combined_text.split(' ')) >= 100:
try:
profile = service.profile(combined_text, accept='application/json').get_result()
except Timeout:
todo = dict(genre=genre, title=title, char=char, combined_text=combined_text, profile=profile)
timeout_todo.append(todo)
genre_file_char_dict[genre][title][char] = {'text': combined_text,
В базе оказалось более трёх тысяч персонажей. Затем я использовал Tweepy, чтобы получить последние 200 твитов наших пользователей и составить их психологический портрет с помощью Watson:
def analyze(handle):
#Доступы к API твиттера
consumer_key = 'yourconsumerkey'
consumer_secret = 'yourkey'
access_token = 'yourkey'
access_token_secret = 'yourkey'
# Авторизация
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
#Последние 200 твитов пользователя
tweets = api.user_timeline(screen_name=handle,
# 200 is the maximum allowed count
count=200,
include_rts = False,
# Necessary to keep full_text
# otherwise only the first 140 words are extracted
tweet_mode = 'extended'
)
#Все твиты в одну строку text.
text = ""
for s in tweets:
if (s.lang =='en'):
text += s.full_text
#Доступы к IBM Watson
url = 'https://gateway.watsonplatform.net/personality-insights/api'
apikey = 'yourapikey'
service = PersonalityInsightsV3(url=url, iam_apikey=apikey, version='2017-10-13' )
#Анализ твитов Watson PI API
profile = service.profile(text, accept='application/json').get_result()
#Результаты
return profileЗатем я сравнил профили из Твиттера с профилями персонажей фильмов, используя коэффициент Отиаи и нашёл наиболее похожего на пользователя персонажа. Я использовал эту функцию:
def most_similar_character(twitter_handle, user_defined_genre):
user_personality = analyze(twitter_handle)['personality']
user_personality_vector = [0,0,0,0,0]
for idx, trait in enumerate(user_personality):
user_personality_vector[idx] = trait['percentile']
# print(trait['name'], trait['percentile'])
best_char_personality_vector = [0,0,0,0,0]
best_char_title = 'No Title Match'
best_char_name = 'No Character Match'
best_similarity_score = 0
titles = genre_file_char_dict[user_defined_genre].keys()
for title in titles:
chars = genre_file_char_dict[user_defined_genre][title].keys()
for char in chars:
try:
profile = genre_file_char_dict[user_defined_genre][title][char]['profile']
personality = profile['personality']
char_personality_vector = [0,0,0,0,0]
for idx, trait in enumerate(personality):
char_personality_vector[idx] = trait['percentile']
similarity_score = round(cosine_similarity((user_personality_vector,
char_personality_vector))[0][1], 3)
if similarity_score > best_similarity_score:
best_char_personality_vector = char_personality_vector
best_char_title = title
best_char_name = char
best_similarity_score = similarity_score
except:
continue
# print(genre, title, char)
# print('\n')
print('Genre: ' + genre + '\n' +
'Title: ' + best_char_title + '\n'
+ 'Character Name: ' + best_char_name + '\n'
+ 'Similarity Score: ' + str(best_similarity_score) + '%')Наконец, я задействовал OpenAI GPT-2, чтобы сгенерировать короткий твит от лица персонажа. Эта нейросеть была обучена с помощью GPT-2 Simple индивидуально на каждом диалоге персонажа в корпусе фильмов и настроена так, чтобы текст не превышал длину твита.
Предварительные результаты
Результаты всей этой работы были обнадеживающими! Я проверил её с помощью ряда твиттеров людей в моей группе, а также с некоторыми известными профилями, такими как Илона Маска (он оказался похож на Спока из Star Trek), и почувствовал, что результаты в большинстве случаев имеют смысл. Я также создал небольшое веб-приложение на Flask, ниже результат для Дональда Трампа:
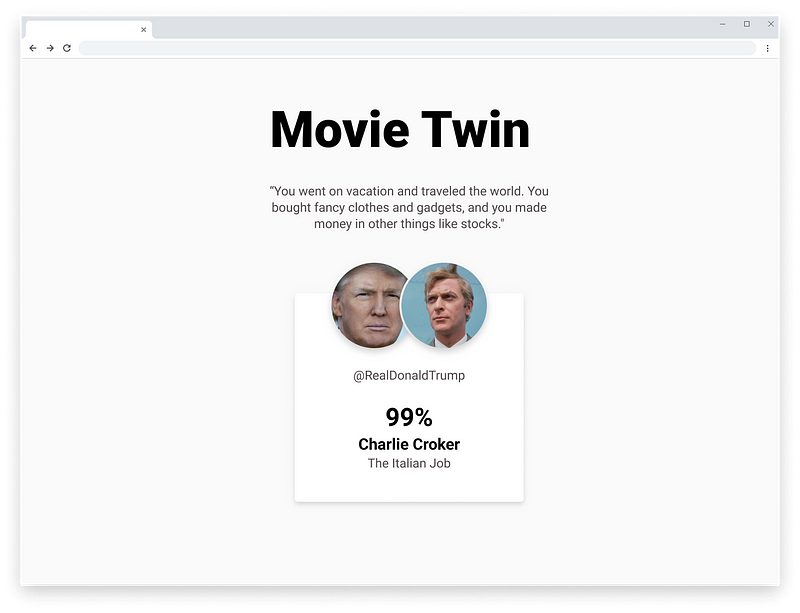
Трамп на 99% похож на Чарли Крокера из “Ограбления по-итальянски”. Читаем описание персонажа: “Вышедший из тюрьмы лидер криминальной группировки, который намеревается ограбить инкассаторский грузовик с 500 килограммами золота”. Хорошо звучит!
Читайте также:
- Биномиальное распределение
- Значение Data Science в современном мире
- Настройка Data Science окружения на вашем компьютере
Перевод статьи Nicholas Sherwin: Personalized, Generative Narratives




