
Введение
Вычисления на графических процессорах становятся всё более и более важными.
- Количество данных во всём мире удваивается каждый год.
- Приходит квантовая реальность. Закон Мура перестаёт работать.
Кроме того, растёт число онлайн-платформ анализа данных с поддержкой GPU. В их число входят:
- Kaggle
- Google Colaboratory
- Microsoft Azure
- AWS
В этой статье я познакомлю вас с RAPIDS — открытыми библиотеками NVIDIA для Python, а затем покажу, как она работает, ускоряя анализ данных в 50 раз. Код из статьи доступен на Github и Google Colaboratory.
RAPIDS
Для работы с большими данными в последние несколько дней было предложено множество решений: MapReduce, Hadoop, Spark. RAPIDS созданы как следующий шаг эволюции обработки данных. Благодаря формату Apache Arrow RAPIDS в оперативной памяти могут быть в 50 раз быстрее, чем Spark . Доступно масштабирование от однопроцессорной до мультипроцессорной архитектуры. RAPIDS имеет интерфейс, схожий с популярными Pandas и Sklearn.
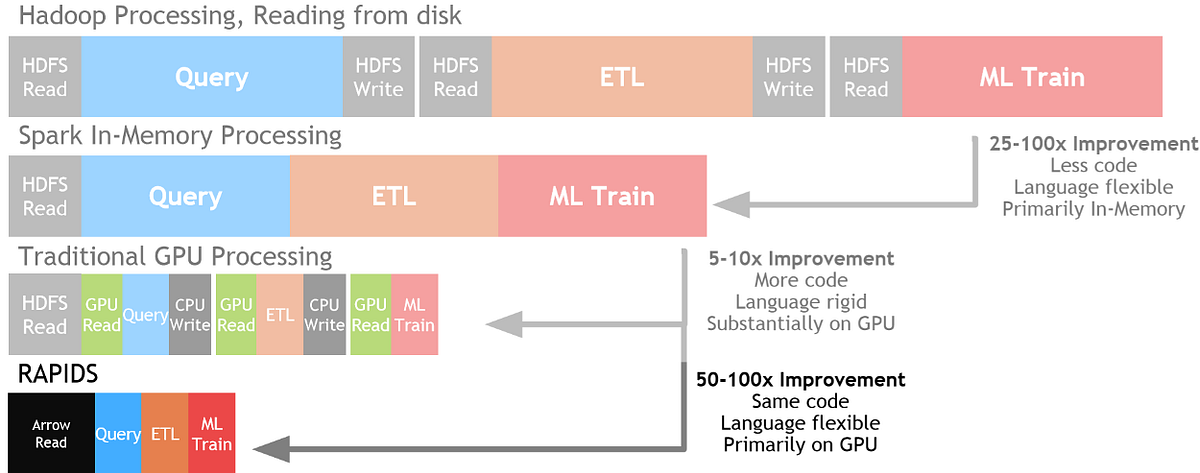
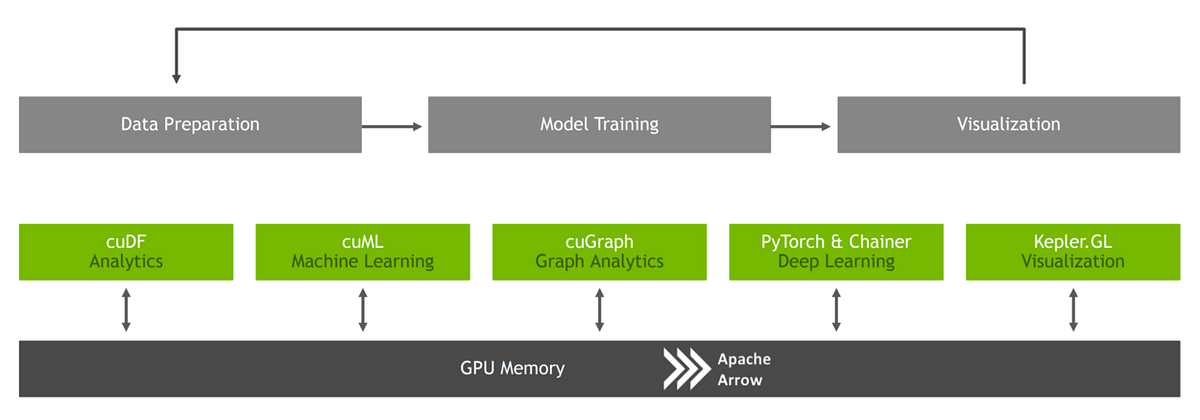
Все пакеты RAPIDS бесплатны и доступны в Anaconda, Docker, Google Colaboratory и других облачных платформах. Структура базируется на различных библиотеках для ускорения всех задач анализа данных от начала до конца:
cuDFдля задач предварительной обработки данных, какPandas.cuMLдля создания моделей ML, какSklearn.cuGraphдля выполнения задач с графами.
RAPIDS имеет дополнительную интеграцию с PyTorch и Chainer для глубокого обучения, Kepler GL для визуализации и Dask для распределённых вычислений.
Демонстрация
Я покажу, как RAPIDS ускоряет анализ данных более чем в 5 раз в сравнении со Sklearn. Напомню: весь код доступен в Google Colaboratory. Протестируйте его сами!
Чтобы использовать библиотеки, мы сначала должны подключить к нашему Google Colaboratory поддержку GPU. Это будет Tesla T4. Затем устанавливаем зависимости. На моём GC есть инструкция.
Предобработка
Как только всё установлено, импортируем необходимые библиотеки:
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from xgboost import XGBClassifier
import cudf
import xgboost as xgb
from sklearn.metrics import accuracy_scoreСравниваем Sklearn и RAPIDS. В нашем случае я решил использовать Pandas для предварительной обработки данных и для Sklearn, и для RAPID. На GC доступна предобработка с cuDF вместо Pandas.
Я решил сгенерировать простой набор данных, используя распределение Гаусса. Он содержит три признака и две метки, 0/1. Величины и стандартные отклонения подобраны так, чтобы упростить решение проблемы классификации. Данные разделимы линейно:
# Создаём линейно разделяемый набор с гауссовым распределением.
# Первая его половина с меткой 0, вторая с меткой 1.
# Принципы генерации данных схожи, а метки различны.
# Поэтому классифицировать их легко.
dataset_len = 8000000
dlen = int(dataset_len/2)
X_11 = pd.Series(np.random.normal(2,2,dlen))
X_12 = pd.Series(np.random.normal(9,2,dlen))
X_1 = pd.concat([X_11, X_12]).reset_index(drop=True)
X_21 = pd.Series(np.random.normal(1,3,dlen))
X_22 = pd.Series(np.random.normal(7,3,dlen))
X_2 = pd.concat([X_21, X_22]).reset_index(drop=True)
X_31 = pd.Series(np.random.normal(3,1,dlen))
X_32 = pd.Series(np.random.normal(3,4,dlen))
X_3 = pd.concat([X_31, X_32]).reset_index(drop=True)
Y = pd.Series(np.repeat([0,1],dlen))
df = pd.concat([X_1, X_2, X_3, Y], axis=1)
df.columns = ['X1', 'X2', 'X3', 'Y']
df.head()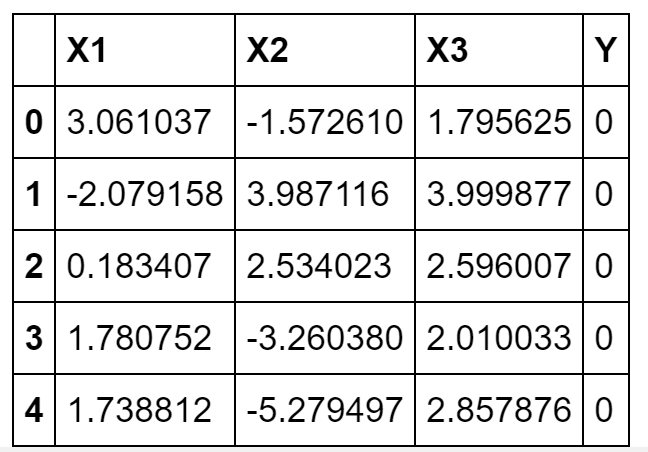
Набор сгенерировался. Делим его признаки и метки по осям и определяем функцию предварительной обработки:
X = df.drop(['Y'], axis = 1).values
y = df['Y']
def preproces(df, X, y, train_size = 0.80):
# label_encoder object knows how to understand word labels.
label_encoder = preprocessing.LabelEncoder()
# Преобразуем метки
y = label_encoder.fit_transform(y)
# identify shape and indices
num_rows, num_columns = df.shape
delim_index = int(num_rows * train_size)
# Делим данные на тестовые и тренировочные
X_train, y_train = X[:delim_index, :], y[:delim_index]
X_test, y_test = X[delim_index:, :], y[delim_index:]
# Проверяем размерность.
print('X_train dimensions: ', X_train.shape, 'y_train: ', y_train.shape)
print('X_test dimensions:', X_test.shape, 'y_validation: ', y_test.shape)
# Размерность в процентах.
total = X_train.shape[0] + X_test.shape[0]
print('X_train Percentage:', (X_train.shape[0]/total)*100, '%')
print('X_test Percentage:', (X_test.shape[0]/total)*100, '%')
return X_train, y_train, X_test, y_test
X_train, y_train, X_test, y_test = preproces(df, X, y)У нас есть тестовые и тренировочные данные. Наконец, мы готовы обучить модель. Используем XGBoost как классификатор.
RAPIDS
Преобразуем наборы в матрицы для XGBoost:
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)Начинаем обучение:
%%time
# Начальные параметры XGBoost.
params = {}
clf = xgb.train(params, dtrain)Вывод ниже. С XGBoost из RAPIDS мы тренировали модель менее двух минут:
CPU times: user 1min 54s, sys: 307 ms, total: 1min 54s
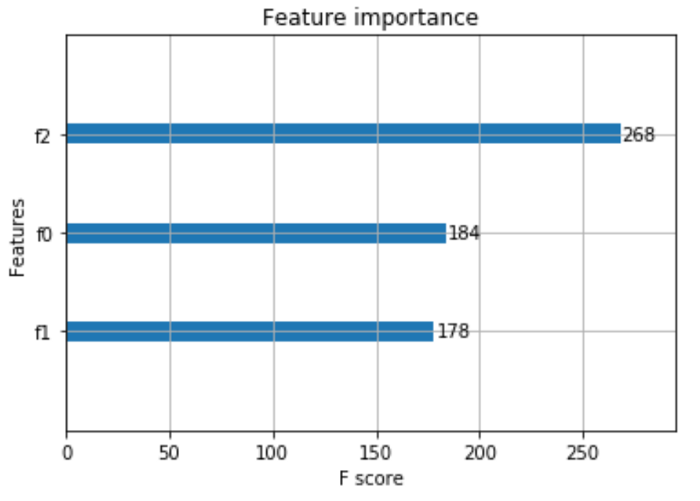
Wall time: 1min 54sКроме того, RAPIDS предоставляет удобный метод importance для отрисовки важности данных на диаграмме:
xgb.plot_importance(clf)
Это может быть полезно для уменьшения размерности ваших данных. Мы можем уменьшить риск переобучения и ускорить работу, просто выбирая наиболее важные признаки и тренируя на них модель.
Наконец, выясним точность классификатора:
XGB accuracy using RAPIDS: 98.0 %
Повторим это со Sklearn:
%%time
model = XGBClassifier()
model.fit(X_train, y_train)11 минут. RAPIDS быстрее Sklearn в 5,8 раз: 662/114. Используя cuDF вместо Pandas, мы можем добиться результатов ещё быстрее.
CPU times: user 11min 2s, sys: 594 ms, total: 11min 3s
Wall time: 11min 2sСчитаем точность:
sk_pred = model.predict(X_test)
sk_pred = np.round(sk_pred)
sk_acc = round(accuracy_score(y_test, sk_pred), 2)
print("XGB accuracy using Sklearn:", sk_acc*100, '%')Точность та же: 98,0%. Это значит, что RAPIDS работает быстрее и без потери точности.
XGB accuracy using Sklearn: 98.0 %
Заключение
Выше мы видим: используя RAPIDS, можно добиться стабильного уменьшения времени работы с данными (в случае очень больших данных с дней до часов и с часов до минут). Наконец, RAPIDS предоставляет ценную документацию и примеры. Посмотрите здесь и здесь, если хотите узнать больше. Также я создал два других примера: cuGraph и интеграция с Dask, здесь и здесь.
Читайте также:
- Машинное обучение. С чего начать? Часть 1
- Алгоритмы машинного обучения простым языком. Часть 1
- Руководство по машинному обучению для новичков
Перевод статьи Pier Paolo Ippolito: GPU Accelerated Data Analytics & Machine Learning

 улучшить написание кода на Swift")



