
Предыдущая часть: Часть 1
Очистка данных
В любом проекте приходится заниматься «чисткой данных». К следующему этапу можно переходить только после приведения в порядок ваших данных.
Чаще всего пропущенные данные просто добавляют. Вы можете дополнить недостающие данные разными способами: по моде, среднему значению или медиане. Пробуйте разные способы и выбирайте наиболее эффективный, абсолютного правила нет. Обычно для категориальных признаков используют только моду, а для числовых — среднее значение или медиану.
Теперь давайте заполним недостающие данные о пункте отправления по моде, а возраст по медиане.
train_df['Embarked'].fillna(train_df['Embarked'].mode()[0], inplace = True)
train_df['Age'].fillna(train_df['Age'].median(), inplace = True)Другой подход чистки — это удаление данных, особенно если пробелов слишком много. Давайте удалим все данные о каютах.
drop_column = ['Cabin']
train_df.drop(drop_column, axis=1, inplace = True)Проверяем данные после чистки.
print('check the nan value in train data')
print(train_df.isnull().sum())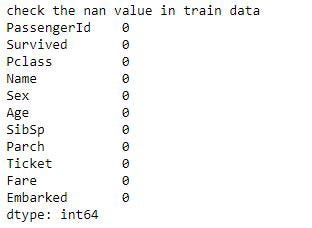
Отлично. Всё на месте. Чистка прошла успешно.

Конструирование признаков
После очистки данных мы приступаем к конструированию признаков.
Эта техника подразумевает поиск признаков или данных в других данных, доступных на текущий момент. Есть несколько способов создавать признаки, но чаще всего мы просто опираемся на здравый смысл.
Например, возьмём пункт отправления: эта колонка заполнена значениями Q, S, и C. Но так как библиотека Python не обрабатывает буквы, нам нужно заменить их на числа. Мы можем прибегнуть к технике One Hot Vectorization, преобразовав одну колонку в три. Назовём их Embarked_Q, Embarked_S и Embarked_C. Каждую из них заполним 0 или 1 в зависимости от того, сел ли пассажир в этом порту или нет.
Другой пример с колонками SibSp и Parch. Возможно, в обеих этих колонках нет ничего интересного, но наверное, вы захотите узнать, насколько велика была семья пассажира, который поднялся на борт корабля. Можно предположить, что чем больше семья, тем больше шансы на выживание, так как они могли помогать друг другу.
Поэтому мы создадим ещё одну колонку «family size», которая будет содержать значения из колонок sibsp и parch + 1 (сам пассажир).
Последней рассмотрим создание колонок интервалов. Здесь мы создаём диапазоны значений, чтобы сгруппировать несколько показателей вместе, так как бывает трудно сравнивать разные значения в одной категории. Например, имеет ли большое значение разница в возрасте 5 и 6 лет, или 45 и 46 лет?
Поэтому мы создадим колонки интервалов. Например, сделаем 4 колонки для разных возрастов. Children (0–14 лет), Teenager (14–20 лет), Adult (20–40 лет), и Elders (40+).
Запишем это в коде:
dataset = train_df
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
import re
# Define function to extract titles from passenger names
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
# Create a new feature Title, containing the titles of passenger names
dataset['Title'] = dataset['Name'].apply(get_title)
# Group all non-common titles into one single grouping "Rare"
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don','Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
dataset['Age_bin'] = pd.cut(dataset['Age'], bins=[0,14,20,40,120], labels=['Children','Teenage','Adult','Elder'])
dataset['Fare_bin'] = pd.cut(dataset['Fare'], bins=[0,7.91,14.45,31,120], labels=['Low_fare','median_fare', 'Average_fare','high_fare'])
traindf=train_df
drop_column = ['Age','Fare','Name','Ticket']
train_df.drop(drop_column, axis=1, inplace = True)
drop_column = ['PassengerId']
traindf.drop(drop_column, axis=1, inplace = True)
traindf = pd.get_dummies(traindf, columns = ["Sex","Title","Age_bin","Embarked","Fare_bin"],
prefix=["Sex","Title","Age_type","Em_type","Fare_type"])Теперь мы начинаем искать корреляцию для каждого признака:
sns.heatmap(traindf.corr(),annot=True,cmap='RdYlGn',linewidths=0.2) #data.corr()-->correlation matrix
fig=plt.gcf()
fig.set_size_inches(20,12)
plt.show()
Значение 1 говорит о высокой степени положительной корреляции, -1 — о высокой степени отрицательной корреляции. Например, мы видим отрицательную корреляцию между полами, потому что пол может быть либо женский, либо мужской. Кроме этой связи, мы не видим такой высокой корреляции. Значит мы готовы двигаться дальше.
Высокая степень корреляции между двумя признаками значит, что мы можем исключить один из них, так как они содержат одну и ту же информацию.
Построение модели машинного обучения
from sklearn.model_selection import train_test_split #for split the data
from sklearn.metrics import accuracy_score #for accuracy_score
from sklearn.model_selection import KFold #for K-fold cross validation
from sklearn.model_selection import cross_val_score #score evaluation
from sklearn.model_selection import cross_val_predict #prediction
from sklearn.metrics import confusion_matrix #for confusion matrix
all_features = traindf.drop("Survived",axis=1)
Targeted_feature = traindf["Survived"]
X_train,X_test,y_train,y_test = train_test_split(all_features,Targeted_feature,test_size=0.3,random_state=42)
X_train.shape,X_test.shape,y_train.shape,y_test.shapeВы можете выбрать любой алгоритм, включённый в библиотеку scikit-learn:
- Logistic Regression
- Random Forest
- SVM
- K Nearest Neighbor
- Naive Bayes
- Decision Trees
- AdaBoost
- LDA
- Gradient Boosting
Выберите тот, который покажет лучшую производительность.
Давайте попробуем мой любимы алгоритм Random Forest.
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(criterion='gini', n_estimators=700,
min_samples_split=10,min_samples_leaf=1,
max_features='auto',oob_score=True,
random_state=1,n_jobs=-1)
model.fit(X_train,y_train)
prediction_rm=model.predict(X_test)
print('--------------The Accuracy of the model----------------------------')
print('The accuracy of the Random Forest Classifier is', round(accuracy_score(prediction_rm,y_test)*100,2))
kfold = KFold(n_splits=10, random_state=22) # k=10, split the data into 10 equal parts
result_rm=cross_val_score(model,all_features,Targeted_feature,cv=10,scoring='accuracy')
print('The cross validated score for Random Forest Classifier is:',round(result_rm.mean()*100,2))
y_pred = cross_val_predict(model,all_features,Targeted_feature,cv=10)
sns.heatmap(confusion_matrix(Targeted_feature,y_pred),annot=True,fmt='3.0f',cmap="summer")
plt.title('Confusion_matrix', y=1.05, size=15)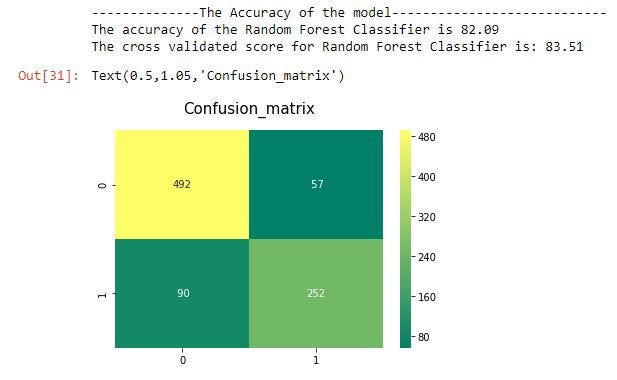
Он показал точность в 83%. Хороший результат для первого раза.
Здесь мы видим кросс-валидацию по K блокам. Если, например, K = 10, значит вы разбиваете данные на 10 блоков и вычисляете среднее значение всех результатов и получаете конечную оценку.
Детали
В целом мы закончили. Но есть ещё один шаг. Чтобы получить лучший результат нужна «тонкая настройка». Я имею в виду поиск наилучшего параметра для алгоритмов машинного обучения. Посмотрите на код random forest:
model = RandomForestClassifier(criterion='gini', n_estimators=700,
min_samples_split=10,min_samples_leaf=1,
max_features='auto',oob_score=True,
random_state=1,n_jobs=-1)Здесь ещё много назначенных по умолчанию параметров, которые нужно настроить. Вы можете менять их как угодно.
Кстати, есть один инструмент, который называется Grid Search. Он найдёт для вас оптимальные параметры автоматически.
# Random Forest Classifier Parameters tunning
model = RandomForestClassifier()
n_estim=range(100,1000,100)
## Search grid for optimal parameters
param_grid = {"n_estimators" :n_estim}
model_rf = GridSearchCV(model,param_grid = param_grid, cv=5, scoring="accuracy", n_jobs= 4, verbose = 1)
model_rf.fit(train_X,train_Y)
# Best score
print(model_rf.best_score_)
#best estimator
model_rf.best_estimator_Теперь можете попробовать все сами. Удачи!
Заключение
Было ведь не трудно, да? Машинное обучение с помощью Python — это просто. Всё необходимое уже создано, просто берите и используйте в своих целях.
Tirmidzi Faizal Aflahi: How to get started with Machine Learning in about 10 minutes





