
По мере того, как машинное обучение всё больше внедряют в бизнес-процессы, жизненно важным становится наличие инструмента, который позволяет быстро решать поставленные задачи. Зачастую в качестве такого инструмента выбирают Python. Поэтому, я считаю руководство по Python для машинного обучения будет действительно полезным.
Введение. Машинное обучение с помощью Python
Итак, почему Python? По моему опыту, Python один из самых простых в изучении языков программирования. Data аналитик, не имея глубоких познаний в программировании, должен иметь возможность быстро обрабатывать данные, и Python отлично подходит для этого.
Насколько это сложно?
for anything in the_list:
print(anything)Это просто. Синтаксис Python имеет больше общего с человеческим языком, чем с машинным. В Python нет надоедливых фигурных скобок, которые только сбивают с толку. Моя коллега из отдела обеспечения качества, которая не имеет отношения к программированию, может написать качественный код на Python в течение дня.
Не удивительно, что Python выбирают создатели библиотек, работы которых в последствии используют специалисты по обработке данных и аналитики для решения своих задач. Далее мы обсудим эти must-have библиотеки для машинного обучения.
- Numpy
Знаменитая библиотека для анализа числовых данных. Она способна на многое: от вычисления медианы распределения данных до обработки многомерных массивов.
2. Pandas
Тот самый инструмент, который поможет вам обрабатывать CSV файлы.
3. Matplotlib
Библиотека для визуализации данных, например дата фреймов Pandas.
4. Seaborn
Так же служит для визуализации, но больше подходит для отображения статистических данных. Например: гистограммы и круговые диаграммы, кривые, корреляционные таблицы.
5. Scikit-Learn
И, наконец, самое главное — библиотека с алгоритмами и другими необходимыми вещами для машинного обучения.
6. Tensorflow и Pytorch
Об этих библиотеках стоит написать отдельный урок. Их используют для так называемого глубокого обучения. Здесь я не буду о них говорить, попробуйте сами разобраться. Оно того стоит.

Проекты
Чтение уроков и повторение упражнений без практики не принесёт должных результатов. Чтобы лучше разобраться в теме, нужно погрузится в реальные данные. Для этого есть платформа, где вы найдёте подходящие проекты по машинному обучению.

На Kaggle вы сможете поработать с данными, решать задачи и получить хороший опыт. Кроме того, на Kaggle проводят соревнования по машинному обучению с денежным призом $100,000.
Пример проекта, который мы рассмотрим в этом уроке:
Titanic: Machine Learning from Disaster
Речь пойдёт о печально известном «Титанике». Трагическая катастрофа 1912 года, в которой погибли 1502 из 2224 пассажиров и экипажа. В этом конкурсе (или уроке) на основе реальных данных о катастрофе ваша задача предсказать, выжил ли человек во время трагедии.
Урок
Для начала давайте установим необходимые инструменты.
В первую очередь установите сам Python с официального сайта. Чтобы не было проблем с совместимостью библиотек, установите версию 3.6 или выше.
Далее установите все необходимые библиотеки через Python pip. Pip должен установиться автоматически с дистрибутивом Python.
В терминале, командной строке или Powershell введите следующее:
pip install numpy
pip install pandas
pip install matplotlib
pip install seaborn
pip install scikit-learn
pip install jupyterЕсли вы ещё не знакомы с jupyter notebook, то это популярный инструмент для интерактивного написания кода. Название состоит из слов Julia, Python, и R. Напишите в терминале jupyter notebook, и вам откроется такая страничка:

Наберите код в зелёном поле и сразу увидите результат.
Теперь, когда все инструменты установлены, можно приступать.
Исследование данных
Первым делом нужно изучить данные. Для этого загрузите данные с Kaggle и извлеките их в каталог, в котором вы запустили Jupyter notebook.
Импортируем нужные библиотеки:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
%matplotlib inlineЗагружаем данные:
train_df=pd.read_csv("train.csv")
train_df.head()Вы должны увидеть такую таблицу:

Это и есть наши данные. Здесь есть следующие колонки:
- PassengerId — идентификатор пассажира;
- Survived — выжил или нет;
- Pclass — класс обслуживания (1 — эконом, 2 — бизнес, 3 — первый класс);
- Name — имя пассажира;
- Sex — пол;
- Age — возраст;
- Sibsp — количество родственников пассажира на борту (братья/сёстры, муж/жена);
- Parch — количество детей и родителей пассажира на борту;
- Ticket — информация о билете;
- Cabin — номер каюты (NaN — нет данных);
- Embarked — пункт отправления (S —Саутгемптон, Q — Квинстаун, C — Шербур).
В процессе изучения данных часто всплывают недостающие данные. Давайте найдём их:
def missingdata(data):
total = data.isnull().sum().sort_values(ascending = False)
percent = (data.isnull().sum()/data.isnull().count()*100).sort_values(ascending = False)
ms=pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
ms= ms[ms["Percent"] > 0]
f,ax =plt.subplots(figsize=(8,6))
plt.xticks(rotation='90')
fig=sns.barplot(ms.index, ms["Percent"],color="green",alpha=0.8)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
return ms
missingdata(train_df)Результат:
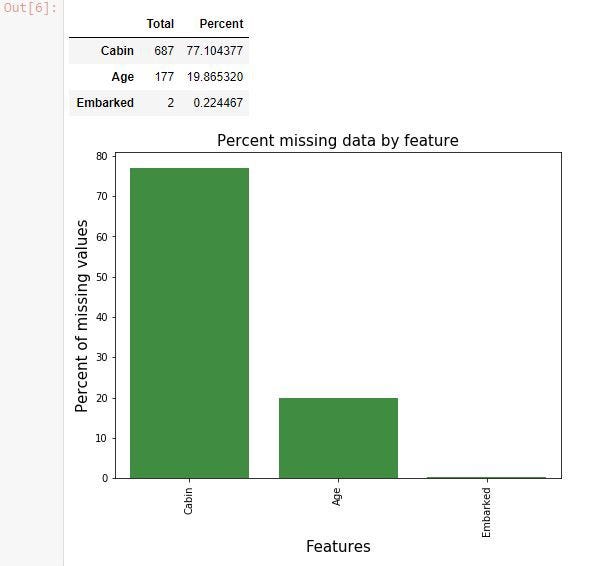
Отсутствуют некоторые значения в колонках Cabin, Age и Embarked. Очень много неизвестных номеров кают. С этим нужно что-то делать. Это называют очисткой данных.
В следующей части мы займёмся чисткой данных от ненужной информации, выявим признаки и построим модель машинного обучения.
Tirmidzi Faizal Aflahi: How to get started with Machine Learning in about 10 minutes





