
Краткий обзор модуля Collections в Python
Если реализацию сложно объяснить — идея плоха: The Zen of Python
Python — достаточно мощный ЯП с поддержкой модульного программирования. Модульное программирование представляет собой процесс разделения одной комплексной задачи программирования на несколько маленьких и более управляемых подзадач/модулей. Модули напоминают кирпичики Лего, которые образуют большую задачу, если собрать их вместе.
Модульность обладает множеством преимуществ при написании кода:
- Возможность повторного использования
- Поддерживаемость
- Простота
Функции, модули и пакеты обеспечивают модуляризацию кода в Python.
Введение
Начнем с небольшого обзора модулей и пакетов.
Module
Модуль — это сценарий .py, который можно вызвать в другом сценарии .py. Модуль — это файл, содержащий определения и операторы Python, который участвует в реализации набора функций. Название модуля эквивалентно названию файла с расширением .py. Для импорта одних модулей из других используется команда import. Импортируем модуль math.
# import the library
import math
#Using it for taking the log
math.log(10)
2.302585092994046Встроенные модули в Python
В Python имеется бесчисленное количество встроенных модулей и пакетов практически на любой случай. Полный список можно посмотреть здесь.
При изучении модулей в Python пригодятся две функции — dir и help.
- Встроенная функция
dir()используется для обнаружения функций, реализованных в каждом модуле. Она возвращает отсортированный список строк:
print(dir(math))

- Функция
helpвнутри интерпретатора Python предоставляет информацию об определенной функции в модуле:
help(math.factorial)

Packages
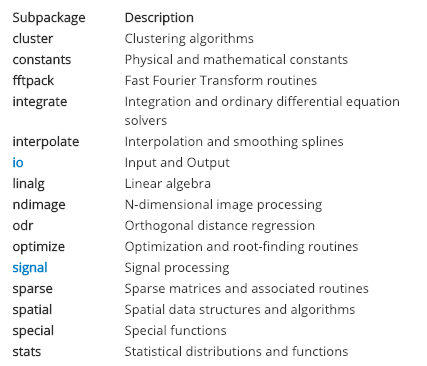
Пакеты — это коллекция модулей, собранных вместе. Базовые пакеты машинного обучения — Numpy и Scipy — состоят из коллекции сотен модулей. Ниже приведен неполный список подпакетов, доступных в SciPy.
Модуль Collections
Collections — это встроенный модуль Python, реализующий специализированный контейнер типов данных. Является альтернативой встроенным контейнерам общего назначения Python, таким как dict, list, set и tuple.
Рассмотрим несколько структур данных, представленных в этом модуле:
1. namedtuple()
Доступ к данным, хранящимся в обычном кортеже, можно получить с помощью индексов. Пример:
plain_tuple = (10,11,12,13)
plain_tuple[0]
10
plain_tuple[3]
13Не обязательно давать названия отдельным элементам, хранящимся в кортеже. В этом есть необходимость лишь в том случае, если кортеж обладает множеством полей.
Именно здесь функциональность namedtuple проявляет свои силы. Это функция для кортежей с именованными полями (Named Fields), которую можно рассматривать как расширение встроенного типа данных tuple. Именованные кортежи задают значение для каждой позиции в кортеже, делая код более читаемым и самодокументируемым. Доступ к объектам, хранящимся в кортеже, можно получить с помощью уникального (удобного для чтения) идентификатора. Это избавляет от необходимости запоминать целочисленные индексы. Рассмотрим его реализацию.
from collections import namedtuple
fruit = namedtuple('fruit','number variety color')
guava = fruit(number=2,variety='HoneyCrisp',color='green')
apple = fruit(number=5,variety='Granny Smith',color='red')Построение namedtuple начинается с передачи названия объекта type (fruit). Затем передается строка с пробелами между названиям каждого поля. Теперь можно обращаться к различным параметрам:
guava.color
'green'
apple.variety
'Granny Smith'Namedtuples — эффективная для памяти опция при определении неизменяемых полей в Python.
2. Counter
Counter — это подкласс dict, который используется для подсчета объектов hashable. Элементы хранятся в качестве ключей словаря, а количество объектов сохранено в качестве значения. Рассмотрим несколько примеров с Counter.
#Importing Counter from collections
from collections import Counter
- Со строками
c = Counter('abcacdabcacd')
print(c)
Counter({'a': 4, 'c': 4, 'b': 2, 'd': 2})- Со списками
lst = [5,6,7,1,3,9,9,1,2,5,5,7,7]
c = Counter(lst)
print(c)
Counter({'a': 4, 'c': 4, 'b': 2, 'd': 2})- С предложением
s = 'the lazy dog jumped over another lazy dog'
words = s.split()
Counter(words)
Counter({'another': 1, 'dog': 2, 'jumped': 1, 'lazy': 2, 'over': 1, 'the': 1})Помимо доступных для всех словарей методов, объекты Counter поддерживают еще три дополнительных:
- elements()
Возвращает количество каждого элемента. В случае, если количество элемента меньше одного, метод не выполняется.
c = Counter(a=3, b=2, c=1, d=-2)
sorted(c.elements())
['a', 'a', 'a', 'b', 'b', 'c']- most_common([n])
Возвращает список наиболее повторяемых элементов и количество каждого из них. Количество элементов указывается в значении n. Если ни одно из значений не указано, возвращается количество всех элементов.
s = 'the lazy dog jumped over another lazy dog'
words = s.split()
Counter(words).most_common(3)
[('lazy', 2), ('dog', 2), ('the', 1)]Распространенные шаблоны использования объекта Counter()
sum(c.values()) # total of all counts
c.clear() # reset all counts
list(c) # list unique elements
set(c) # convert to a set
dict(c) # convert to a regular dictionary c.items() # convert to a list like (elem, cnt)
Counter(dict(list_of_pairs)) # convert from a list of(elem, cnt)
c.most_common()[:-n-1:-1] # n least common elements
c += Counter() # remove zero and negative counts
3. defaultdict
Словари — это эффективный способ хранения данных для дальнейшего извлечения, в котором данные представлены в виде неупорядоченного множества пар key:value. Ключи — это уникальные и неизменяемые объекты.
fruits = {'apple':300, 'guava': 200}
fruits['guava']
200Все очень просто, когда значения представлены целыми числами или строками. Однако если они представлены в форме списков и словарей, значение (пустой список или словарь) нужно инициализировать при первом использовании ключа. defaultdict автоматизирует и упрощает этот процесс. Для лучшего понимания рассмотрим пример ниже:
d = {}
print(d['A'])

Словарь Python выдает ошибку, поскольку ‘A’ на данный момент не находится в словаре. Рассмотрим тот же самый пример с использованием defaultdict.
from collections import defaultdict
d = defaultdict(object)
print(d['A'])
<object object at 0x7fc9bed4cb00>defaultdict создает элементы, для которых нужно получить доступ (если они еще не существуют). defaultdict также является объектом-словарем и содержит те же методы, что и словарь. Разница заключается в том, что он устанавливает первый аргумент (default_factory) в качестве типа данных по умолчанию для словаря.
4.OrderedDict
OrderedDict — это подкласс словаря, в котором хранится порядок добавления ключей. При итерации упорядоченного словаря элементы возвращаются в порядке добавления их ключей. Поскольку упорядоченный словарь запоминает порядок добавления, его можно использовать в сочетании с сортировкой для создания отсортированного словаря:
- обычный словарь
d = {'banana': 3, 'apple': 4, 'pear': 1, 'orange': 2}
- словарь, отсортированный по ключу
OrderedDict(sorted(d.items(), key=lambda t: t[0]))
OrderedDict([('apple', 4), ('banana', 3), ('orange', 2), ('pear', 1)])- словарь, отсортированный по значению
OrderedDict(sorted(d.items(), key=lambda t: t[1]))
OrderedDict([('pear', 1), ('orange', 2), ('banana', 3), ('apple', 4)])- словарь, отсортированный по длине строки
OrderedDict(sorted(d.items(), key=lambda t: len(t[0])))
OrderedDict([('pear', 1), ('apple', 4), ('banana', 3), ('orange', 2)])Стоит отметить, что в Python 3.6 обычные словари отсортированы по добавлению, т. е. словари запоминают порядок добавления элементов.
Заключение
Модуль Collections также включает и другие полезные типы данных, такие как deque, Chainmap, UserString и т. д. Я рассказал лишь о самых используемых. Для более полного объяснения посмотрите официальную документацию Python.
Перевод статьи Parul Pandey: Python’s Collections Module — High-performance container data types.





