
Потоковая передача данных важна во многих сферах:
- в трейдинге и выявлении мошенничества в финансах;
- получении представления о посещаемости сайта и вовлеченности в соцсети в онлайн-маркетинге;
- проведении оптимизации цен в реальном времени и управлении запасами в рознице;
- во многих других сценариях этих и других сфер.
Большинство инструментов инженерии данных ориентированы в основном на пакетную обработку, потоковая же передача остается небольшой, но растущей экосистемой.
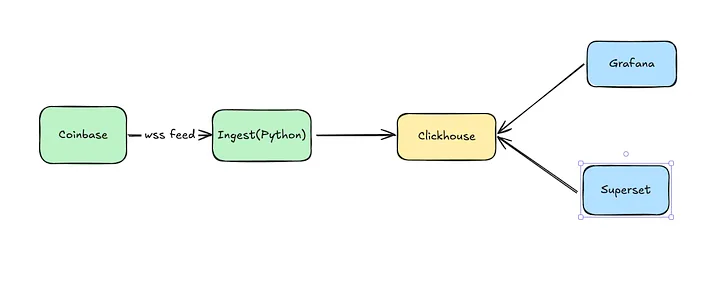
Рассмотрим пример построения базовых, наиболее заметных компонентов платформы потоковой аналитики: получение, хранение данных, наблюдаемость, инструмент аналитики. Вот исходный код, конфигурации, а также детализированные и суперлаконичные рабочие инструкции.
Получение данных
Прежде чем анализировать данные, их необходимо ввести в систему. Если говорить о пакетных данных, решений немало — Airbyte, Fivetran, Stitch, Meltano и другие. Большинство очень просты в установке и работе, хотя у каждого из них свои плюсы и минусы.
По потоковой передаче выбор более ограничен, хотя хорошие решения имеются: Striim, Estuary, Databricks, Redpanda, Bento, Flink. Они, как правило, проприетарные или относительно сложные. Поэтому вместо полнофункционального решения для продакшена я сделал собственную демоверсию — простую и расширяемую. Получение данных выполнено так, по лицензии MIT. Демоверсия легко настраивается и запускается, но здесь нет гарантий доставки, обработки обратного давления, возможности настройки сообщений и отказоустойчивости решения для продакшена.
Хранилище данных
Следующий базовый компонент платформы обработки данных — место для их хранения. Опять же, пакетно-ориентированных решений имеется немало. По потоковой же передаче данных выбор ограничивается ключевым отличием — возможностью приема большого объема данных с низкой задержкой. Для эффективной обработки потоковых данных воспользуемся Clickhouse — невероятно быстрым решением для их хранения. Очень эффективно им обрабатываются и пакетные данные, Clickhouse прост в работе при небольших масштабах. Другие неплохие решения — Druid, Pinot, Postgres с Timescale или Databricks.
Установка Clickhouse
Предварительно установив Docker, например Docker Desktop на MacBook, устанавливаем контейнер — это простейший вариант:
docker pull clickhouse/clickhouse-server:latest
docker run -d \
--name clickhouse-server \
-p 8123:8123 \
-p 9000:9000
Но этот способ опасен тем, что длительно данные на локальном компьютере не сохраняются. Поэтому при запуске немного корректируем его:
docker run -d \
--name clickhouse-server \
--ulimit nofile=262144:262144 \
-p 8123:8123 \
-p 9000:9000 \
-v $HOME/clickhouse/data:/var/lib/clickhouse \
-v $HOME/clickhouse/config/clickhouse-server:/etc/clickhouse-server \
-v $HOME/clickhouse/logs:/var/log/clickhouse-server \
clickhouse/clickhouse-server:latest
Здесь требуется чуть больше работы: необходимо создать каталоги и конфигурации. Зато все конфигурации и данные стабильны.
По завершении получим запущенный локально сервер Clickhouse. Запускаем клиент Clickhouse:
docker exec -it clickhouse-server clickhouse-client
Появилась командная строка Clickhouse? Значит, сервер Clickhouse запущен и доступен:

Создадим в этой командной строке базу данных для хранения данных. Воспользуемся Coinbase trades feed — каналом операций с криптовалютой в реальном времени. Он находится в свободном доступе, опирается на умеренный объем данных и достаточное количество различных каналов для интересных проектов.
Создаем базу данных:
CREATE DATABASE IF NOT EXISTS coinbase_demo;
Теперь создаем пользователя:
-- Этот пользователь понадобится в инструментах для доступа к Clickhouse
CREATE USER coinbase IDENTIFIED BY 'password';
-- Предоставляем разрешения
GRANT ALL ON coinbase_demo.* TO coinbase;
Создаем таблицу для хранения тиковых данных:
-- Таблица для хранения необработанных тикерных данных из Coinbase
-- Внимание: последовательность сортировки ключей — «time», «product_id», «sequence» — может быть неоптимальной,
-- поскольку у «time» кардинальность выше, чем у «product_id», что не оптимально
-- для обобщенного алгоритма исключения
CREATE TABLE IF NOT EXISTS coinbase_demo.coinbase_ticker
(
sequence UInt64,
trade_id UInt64,
price Float64,
last_size Float64,
time DateTime,
product_id String,
side String,
open_24h Float64,
volume_24h Float64,
low_24h Float64,
high_24h Float64,
volume_30d Float64,
best_bid Float64,
best_bid_size Float64,
best_ask Float64,
best_ask_size Float64
)
ENGINE = MergeTree()
ORDER BY (time, product_id, sequence);
Получение данных
Хранилищем данных обзавелись, теперь введем в систему данные. Воспользуемся инструментом, созданным для этой демоверсии:
git clone https://github.com/Vertrix-ai/streaming-analytics-demo.git
cd streaming-analytics-demo
poetry install
Для него в корневом каталоге репозитория находится простая конфигурация. Чтобы поменять базу данных, имя пользователя и т. д., вносим изменения здесь:
source:
wss_url: "wss://ws-feed.exchange.coinbase.com"
type: coinbase
subscription:
product_ids:
- "BTC-USD"
channels:
- "ticker"
sink:
type: clickhouse_connect
host: "localhost"
port: 8123
database: "coinbase_demo"
table: "coinbase_ticker"
user: "coinbase"
password: "password"
Теперь приступаем к приему данных:
poetry run python streaming_analytics_demo/listen.py --config demo_config.yaml
Подтверждаем получение сообщений и данных в Clickhouse:
select * from coinbase_demo.coinbase_ticker;
Наблюдаемость
Прежде чем анализировать получаемые данные, убедимся в их надежности — без этого случаются странные результаты аналитики или, что еще хуже, казалось бы разумные результаты оказываются неверными. Необходимо также, чтобы при возникновении проблем инструменты наблюдаемости «поднимали тревогу». Если этого нет, проблемы часто замечаются слишком поздно.
Как в случае с хранилищем данных, так и с их получением, «современный стек данных» в основном ориентирован на пакетные рабочие нагрузки. Наблюдаемость же потоковых данных обеспечивается обычно инструментами с закрытым исходным кодом. Для демоверсии достаточно базового функционала Open Source инструмента Grafana. Выбор необычный — скорее, из мира DevOps, но основные компоненты здесь имеются.
Начнем с действительно базовой метрики — скорости приема данных в минуту. Другие — пропуски в последовательности, операции с нулевым объемом и т. д. — тоже важны. Но эта метрика — хорошее начало, да и реализация у них аналогичная.
Стартуем простым запросом:
-- Этим запросом показывается число строк, полученных за минуту
-- Обобщенные табличные выражения за каждую минуту с начала данных и до сих пор
WITH time_series AS (
SELECT
arrayJoin(
range(
toUnixTimestamp(
(SELECT min(tumbleStart(time, toIntervalMinute(1)))
FROM coinbase_demo.coinbase_ticker)
),
toUnixTimestamp(
(SELECT max(tumbleStart(now(), toIntervalMinute(1)))
FROM coinbase_demo.coinbase_ticker)
),
60 # увеличение на 60 секунд, или одну минуту
)
) as minute
),
-- Обобщенные табличные выражения для поминутной разбивки операций
trade_by_minute AS (
SELECT
tumbleStart(time, toIntervalMinute(1)) as minute,
time,
last_size,
product_id
FROM coinbase_demo.coinbase_ticker
)
-- Выбираются минута и количество строк, полученных за каждую минуту
SELECT
fromUnixTimestamp(ts.minute) as minute,
countIf(t.last_size > 0 AND t.last_size IS NOT NULL) as num_rows
FROM time_series ts
LEFT JOIN trade_by_minute t ON fromUnixTimestamp(ts.minute) = t.minute
GROUP BY ts.minute
ORDER BY ts.minute DESC;
После выполнения этого запроса появляется таблица с желаемой информацией:
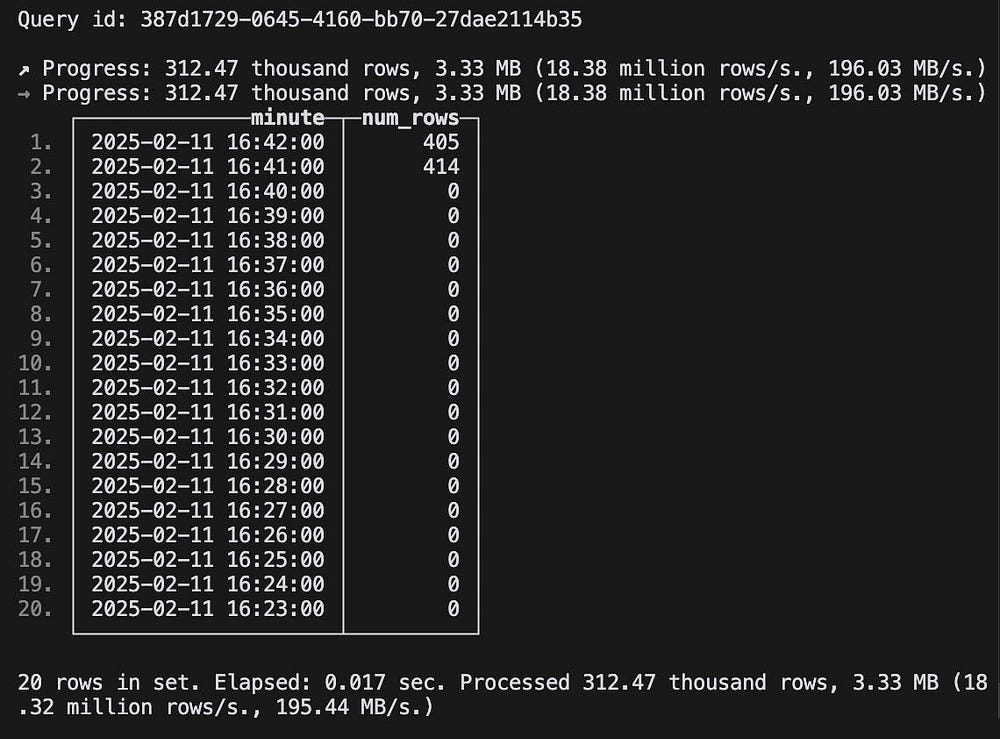
Но толку от нее не много: заранее об этом оповестить нельзя и результаты не увидеть без ручных этапов, неэффективных и трудновыполнимых. Инструментом наблюдаемости получение этой информации сильно облегчится.
Установка Grafana
Сначала установим Grafana, проще через Homebrew:
brew update
brew install grafana
Дальше заставим Grafana «общаться» с Clickhouse. Кроме относительной стабильности, выбранные для этой популярной демоверсии инструменты отличаются доступностью интеграции.
Затем установим плагин Grafana Clickhouse в соответствии с инструкциями. А также создадим пользователя только для чтения — для доступа из Grafana в Clickhouse:
CREATE USER IF NOT EXISTS grafana IDENTIFIED WITH sha256_password BY 'password';
GRANT SELECT ON coinbase_demo.* TO grafana;
Теперь, настроив конфигурацию, разрешим Grafana доступ к Clickhouse. В Grafana плагины конфигурируются в пользовательском интерфейсе, но ради повторяемости сделаем это в конфигурационном файле источника данных:
apiVersion: 1
datasources:
- name: ClickHouse
type: grafana-clickhouse-datasource
jsonData:
defaultDatabase: database
port: 9000
host: localhost
username: grafana
tlsSkipVerify: false
secureJsonData:
password: password
Дальше помещаем этот файл в каталог provisioning и перезапускаем Grafana:
cp ~/projects/streaming_analytics_demo/observability/datasource.yaml provisioning/datasources/
brew services restart grafana
Настроив все это, переходим в http://localhost:3000 и авторизуемся. Учетные данные по умолчанию — admin/admin, после авторизации их предлагается изменить.
Переходим в Connections («Подключения») -> Data sources («Источники данных»), где находится источник данных Clickhouse:
Прокручиваем вниз и нажимаем кнопку Test («Тестировать»), появится надпись Data source is working, то есть источник данных рабочий:
Дашборд наблюдаемости
Установив Grafana и подключившись к Clickhouse, создадим дашборд для построенного ранее запроса.
В меню выбираем Dashboards («Дашборды»), нажимаем New («Новый»), затем Add visualization («Добавить визуализацию»). Выбираем источник данных Clickhouse и SQL Editor («Редактор SQL»). Запускаем строки выше, полученные за минуту, и появится график скорости получения, нажимаем Save («Сохранить») и присваиваем дашборду название:
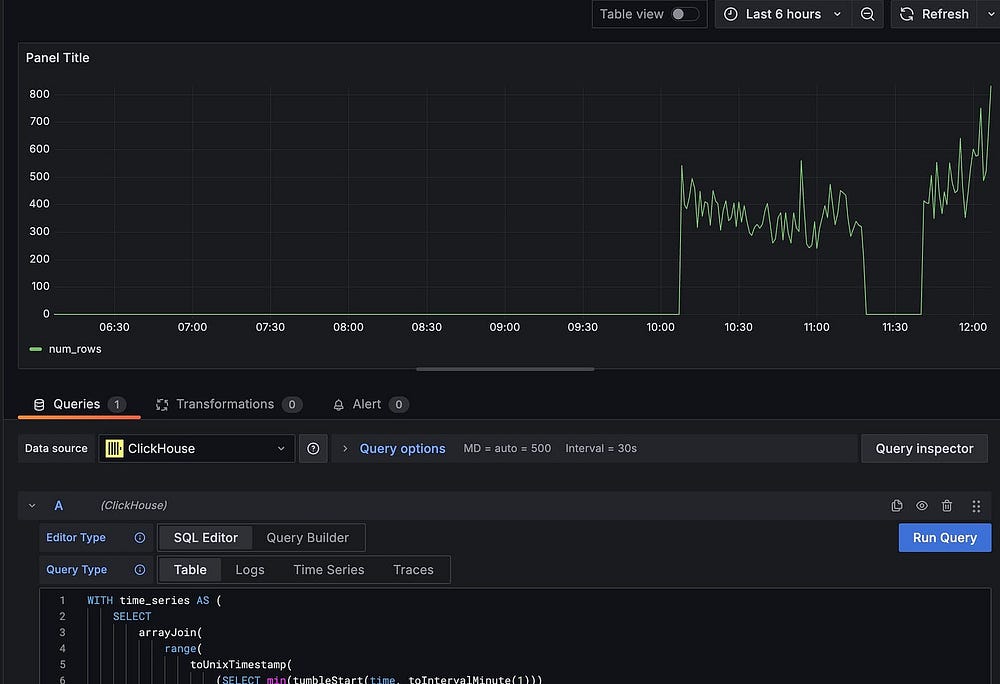
Наблюдаемость — это не только графики, но и данные для активации оповещений, добавим их в дашборд. Во вкладке Alerting («Оповещения») нажимаем New Alert Rule («Новое правило генерирования оповещений»).
Отсюда добавим новый запрос:
-- Запрос на получение тиков за последнюю минуту
SELECT
count(sequence)
FROM coinbase_ticker
WHERE time > now() - INTERVAL 1 minute;
В параметрах Options настраиваем его на ежеминутный запуск.
Затем добавляем новый Threshold («Порог») для ввода Input «A» и задаем условие Is Below («Ниже») 1. Запустив запрос, увидим, что сообщения получены в последнюю минуту и состояние оповещения normal. Теперь сохраняем оповещение и выходим. Оповещение появится в Alert rules («Правила оповещений»). Также имеется возможность настроить уведомления по почте.
Теперь прекращаем прием данных: Alert rule изменится на firing («Активация»), а входящие сообщения перестанут поступать на дашборд. Перезапускаем прием данных: оповещения вернутся в normal.
Этим подчеркивается и важность мониторинга данных. Без него мы бы не узнали, что прием данных прекратился, пока не получили бы странные результаты от аналитиков — возможно, слишком поздно.
Доработки
Для обновления данных на дашборде каждую минуту запускается запрос. Для Clickhouse это небольшой набор данных, на моем ноутбуке получаются такие временные характеристики:
5304 rows in set. Elapsed: 0.046 sec. Processed 791.55 thousand rows, 8.44 MB (17.23 million rows/s., 183.77 MB/s.)
Peak memory usage: 37.01 MiB.
Ежеминутное выполнение этого запроса — пустая трата ресурсов. Доработаем материализованным представлением.
Сначала для хранения числа операций в минуту создаем в клиенте Clickhouse таблицу:
-- Таблица для хранения числа операций за минуту
-- Чтобы эффективно обрабатывать обновления в «num_trades», применяется «SummingMergeTree»
CREATE TABLE IF NOT EXISTS coinbase_demo.trades_per_minute
(
minute DateTime,
num_trades UInt64
)
ENGINE = SummingMergeTree()
ORDER BY minute;
SummingMergeTree() — это специальный механизм для суммирования последовательных данных. Когда принимаются новые данные, они суммируются во время слияния. При этом поддерживаются быстрые вставки, но нет необходимости суммировать все строки при каждом запросе к таблице.
В этом случае создаем материализованное представление, которым обновляется таблица числа операций в минуту:
CREATE MATERIALIZED VIEW IF NOT EXISTS coinbase_demo.trades_per_minute_mv
TO coinbase_demo.trades_per_minute
AS
SELECT
tumbleStart(time, toIntervalMinute(1)) as minute,
countIf(last_size > 0) as num_trades
FROM coinbase_demo.coinbase_ticker
GROUP BY minute;
Ключевым словом TO материализованному представлению здесь приказывается обновить таблицу числа операций в минуту. Оператором select выдается запрос для получения входящих данных из источника, в данном случае таблицы тиков Coinbase, в которой хранятся необработанные данные.
Теперь выполним старый запрос к таблице, в которой уже принимаются данные, обрабатываем 916 940 строк — всю таблицу — масштабировать это было бы проблематично:
5819 rows in set. Elapsed: 0.025 sec. Processed 916.94 thousand rows, 9.78 MB (36.19 million rows/s., 386.05 MB/s.)
Peak memory usage: 37.02 MiB.
Теперь запустим новый запрос — с материализованным представлением и тем же результатом:
WITH time_series AS (
SELECT
arrayJoin(
range(
toUnixTimestamp(
(SELECT min(minute)
FROM coinbase_demo.trades_per_minute)
),
toUnixTimestamp(
(SELECT tumbleStart(now(), toIntervalMinute(1)))
),
60 -- увеличение на 60 секунд, или одну минуту
)
) as minute,
0 as num_trades
),
-- Нужно получить сумму операций в минуту, потому что
-- из-за «SummingMergeTree» суммирование задерживается до времени слияния. Это
-- делается ради производительности вставки, поэтому последняя минута могла пока
-- не суммироваться.
summed_trades AS (
SELECT
minute,
sum(num_trades) as num_trades
FROM coinbase_demo.trades_per_minute
GROUP BY minute
ORDER BY minute DESC
),
-- Теперь, чтобы получить операции в минуту, объединяем временны́е ряды с суммированными
-- операциями.
SELECT
fromUnixTimestamp(ts.minute) as minute,
greatest(ts.num_trades, t.num_trades) as num_trades
FROM time_series ts
LEFT JOIN coinbase_demo.trades_per_minute t ON fromUnixTimestamp(ts.minute) = t.minute
ORDER BY minute DESC;
Этот новый запрос намного эффективнее. Им обрабатываются только те 5834 строки, которые сейчас находятся в таблице trades_per_minute. Хотя оба запроса в этом наборе данных возвращаются очень быстро, по мере увеличения набора данных разница будет заметнее:
5834 rows in set. Elapsed: 0.026 sec.
Возвращаясь на дашборд, заменяем старый запрос новым.
Инструментарий аналитики
Получив данные в БД и возможность благодаря этому выявлять проблемы, перейдем к аналитике. Казалось бы, уже имеются все необходимые инструменты — мы запускаем запросы в Grafana и создаем на их основе дашборды. Проблема в том, что Grafana ориентирована на наблюдаемость и мониторинг временны́х рядов: здесь легко работать инфраструктурным командам, нет широкого функционала пользовательского взаимодействия и поддержки специализированного анализа, которые имеются в других инструментах. Почему бы не интегрировать специальный инструмент бизнес-аналитики, установив Superset?
Установка
Чтобы установить Superset для этой демоверсии, воспользуемся Docker Compose. Установка не производственного уровня, но простая — для демонстрационных целей. Сначала клонируем репозиторий Superset:
git clone - depth=1 https://github.com/apache/superset.git
cd superset
Прежде чем запускать контейнер, устанавливаем зависимости и вносим изменения в конфигурацию:
touch ./docker/requirements-local.txt
Включаем в новый файл requirements-local.txt это:
clickhouse-connect>=0.6.8
Теперь запускаем Superset:
docker compose -f docker-compose-non-dev.yml up
Потребуется время на загрузку всех зависимостей и сборку образа Superset. По завершении получаем доступ к пользовательскому интерфейсу Superset. Если пароль администратора не менялся, заходим с admin/admin. Справа вверху нажимаем + и выбираем Data («Данные») -> Connect Database («Подключить базу данных»).
Добавленный ранее Clickhouse доступен в supported databases, то есть среди поддерживаемых баз данных.
Аналитика
Инфраструктура готова, переходим к аналитике. Для набора данных криптоопераций создадим дашборд с 5-минутками средневзвешенной по объему стоимости за последние 24 часа.
Сначала добавим набор данных Superset с тиковыми данными. Создаем его из таблицы в базе данных и делаем из этого диаграмму или же в SQL Lab пишем запрос и после строим диаграмму из него. Выбираем второй подход:
-- Разбиваем предыдущие 24 часа на 5-минутные интервалы,
-- этот временной период требуется отобразить на диаграмме
WITH time_series AS (
SELECT
arrayJoin(
range(
toUnixTimestamp(
(SELECT tumbleStart((now() - INTERVAL 24 HOUR), toIntervalMinute(5)))
),
toUnixTimestamp(
(SELECT tumbleStart(now(), toIntervalMinute(5)))
),
300 -- увеличение на 300 секунд, или пять минут
)
) as interval
),
-- Вычисляем компоненты средневзвешенной стоимости
vwap AS (
SELECT
tumbleStart(time, toIntervalMinute(5)) as period,
SUM(price * last_size) as volume_price,
SUM(last_size) as total_volume
FROM coinbase_demo.coinbase_ticker
WHERE
period >= now() - INTERVAL 24 HOUR
AND last_size > 0 -- Отфильтровываем операции с нулевым объемом
AND price > 0 -- Отфильтровываем недопустимые значения стоимости
GROUP BY period
)
-- Объединяем вычисление средневзвешенной стоимости во временны́е ряды и получаем 5-минутную средневзвешенную стоимость за последние 24 часа
SELECT
fromUnixTimestamp(interval) as vwap_period,
IF(v.total_volume > 0, v.volume_price/v.total_volume, 0) as vwap
FROM time_series ts
LEFT JOIN vwap v ON fromUnixTimestamp(ts.interval) = v.period
ORDER BY vwap_period DESC;
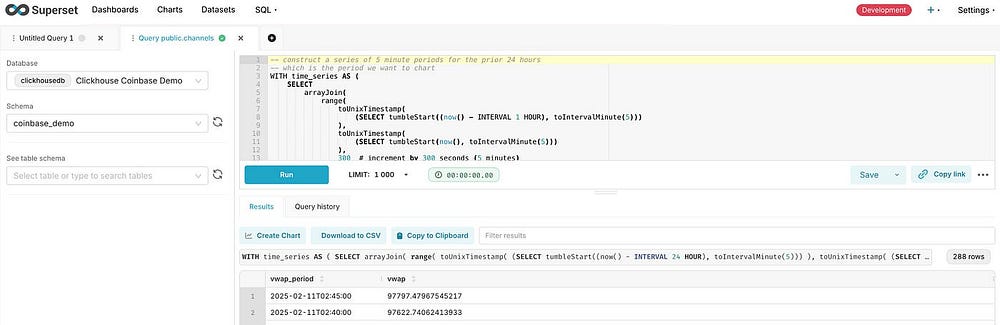
Чтобы построить диаграмму, нажимаем кнопку Сhart («Диаграмма») под запросом, а затем заполняем форму мастера:
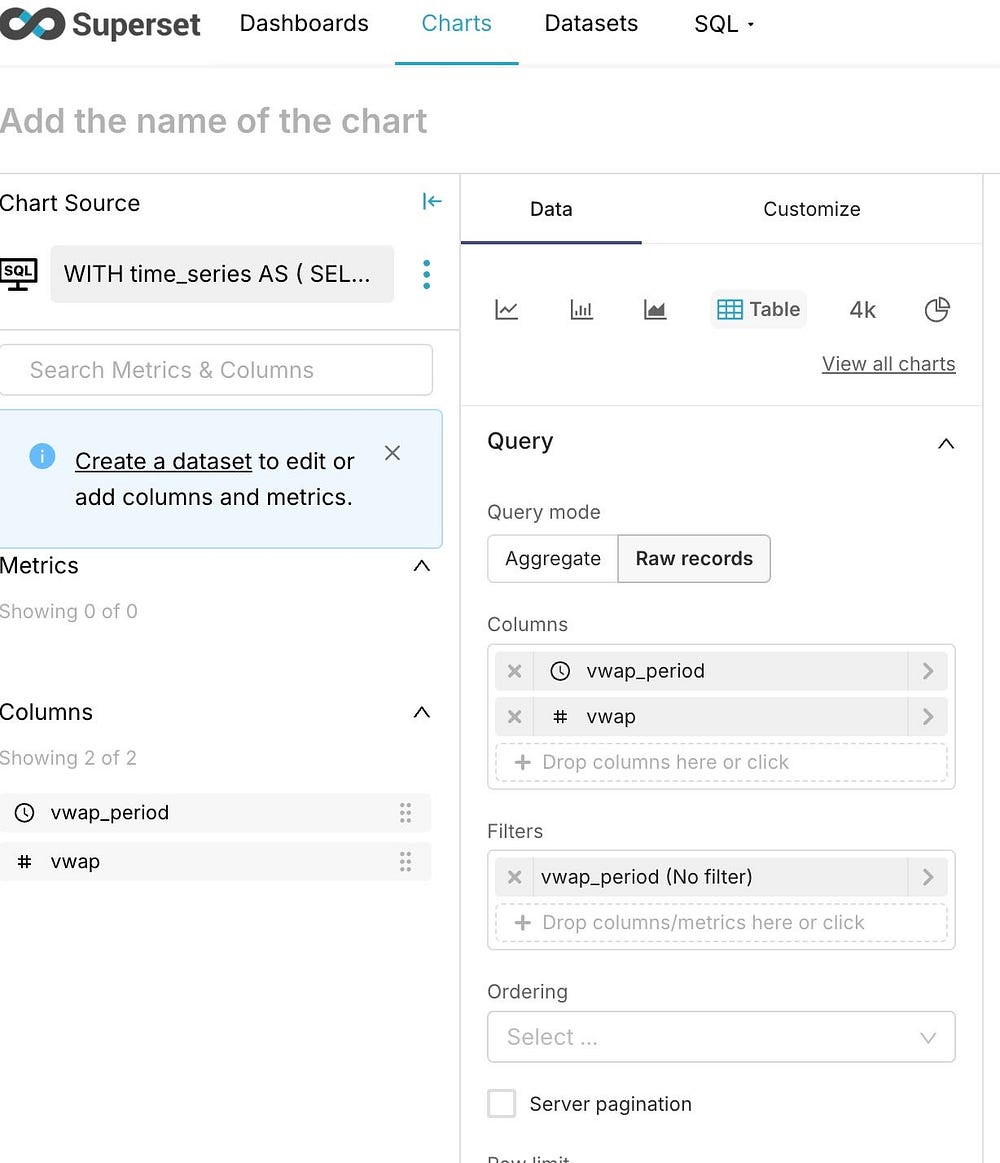
При сохранении диаграммы указываем, в какой дашборд ее добавить.
Наконец, редактируем дашборд, нажав на …, и задаем ему интервал обновления, например, каждые 10 секунд.
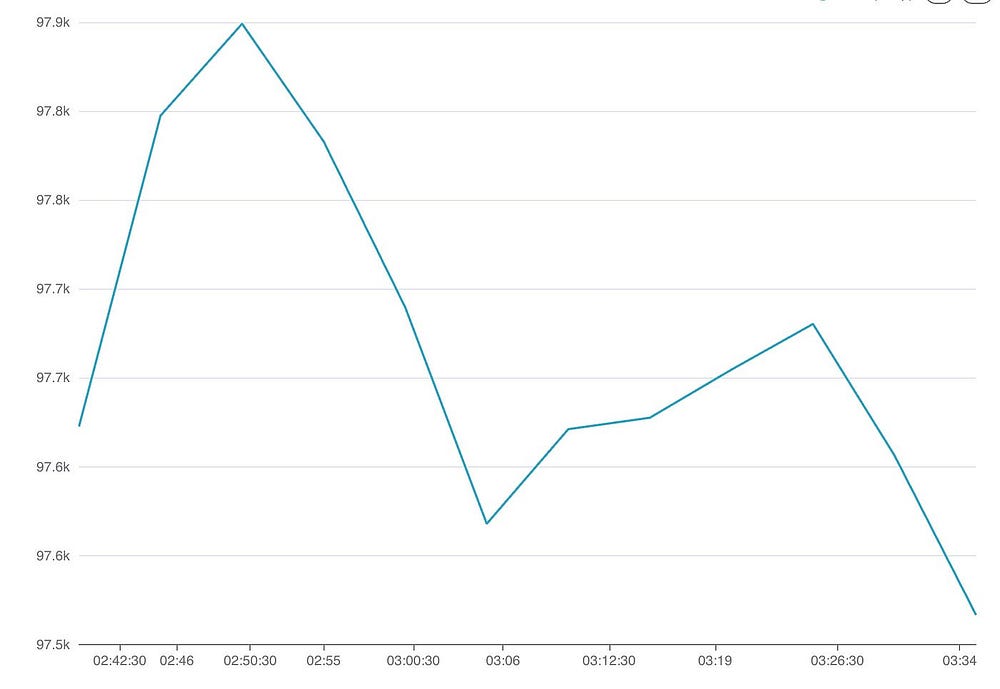
Здесь имеются те же проблемы производительности, что и при мониторинге приема данных. В Superset весь запрос каждый раз просто перезапускается, и снова создается материализованное представление — это тот же процесс.
Заключение
Мы наладили получение данных пользовательским инструментом Python, высокопроизводительное хранилище данных в Clickhouse, наблюдаемость с Grafana и аналитику в Superset. Научились сохранять и запрашивать потоковые данные в Clickhouse, материализованными представлениями убирать часть вычислений со времени запрашивания на время загрузки, представили удобные инструменты аналитики и мониторинга для конечных пользователей платформы.
На первое время этого достаточно. Когда же наборов данных станет больше, на стороне бизнеса неизбежно появятся вопросы о значимости данных, их происхождении и качестве.
По инженерной части тоже предстоит многое сделать. Системой реализуется базовая функциональность, но по мере масштабирования — если оставить ее в этом состоянии — появятся проблемы в управлении.
Мы начали писать интересные запросы, источник же истины для моделей данных и преобразований разделен между базой данных и инструментом бизнес-аналитики. Там, где мы разбиваем запросы, где имеются трудности с отслеживанием того, как получаются наборы данных, появятся проблемы. И при внесении изменений это, скорее всего, обернется проблемами продакшена. Но их устранение — тема другой статьи.
Читайте также:
- Matplotlib или Plotly: как выбрать библиотеку для визуализации данных в Python
- Мониторинг приложения Golang с Prometheus, Grafana, New Relic и Sentry
- Дашбордное решение Apache Superset
Читайте нас в Telegram, VK и Дзен
Перевод статьи Chris Pike: Building a Simple Streaming Data Platform





