
Мне не нужно напоминать вам о том, что Интернет может быть очагом негатива, несмотря на все его положительные качества. Вы только взгляните на Reddit, YouTube или eelslap.com — поймете, что я имею в виду.
Твиттер всегда был платформой, где люди могут быть открытыми и делиться любыми деталями своей жизни со всем миром. Однако всегда есть те, кто не фильтрует порождения своего разума, вызывая споры.
Сегодня мы посмотрим, как можно автоматизировать процесс фильтрации оскорбительных твитов.
План
- Предварительная обработка данных.
- Очистка данных.
- Лексический анализ.
- Морфологический анализ.
- Визуализация данных.
- Извлечение признаков.
- Построение модели.
- Области улучшения.
Если вы захотите ближе познакомиться с проектом или дополнить код, заходите в репозиторий GitHub.
Предварительная обработка данных
Для начала нужно подготовить данные. Они находятся в репозитории.
У нас два файла: тестовый и тренировочный. Внутри тренировочного файла есть случайный набор различных твитов. Есть три признака: уникальный id, метка и сам текст твита. Метка нулевая, если твит не оскорбительный (не расистский или не сексистский, например). Метка равна “1”, когда твит очень жёсткий. Для начала мы импортируем полный набор библиотек:
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import string
import nltk
import warnings
warnings.filterwarnings('ignore', category=DeprecationWarning)
%matplotlib inlineТеперь возьмем pandas, чтобы прочитать тестовый и тренировочный файлы:

Давайте применим их, чтобы увидеть, как выглядят наши данные:
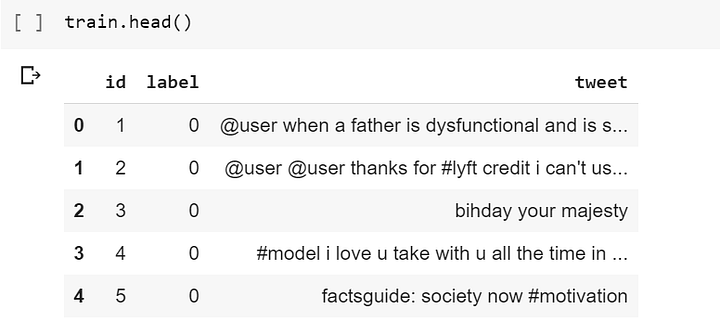
У меня форма записи такая:
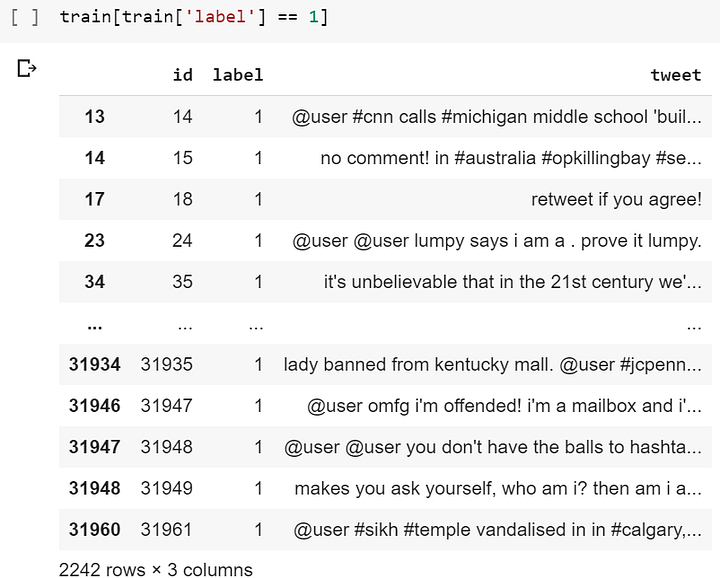
А теперь, когда мы загрузили данные, можно увеличить эффективность алгоритма машинного обучения. Для этого нужно очистить данные.
Очистка данных
Для очистки данных, мы сделаем три действия:
- Убираем ники.
- Убираем знаки препинания, цифры и специальные символы
- Убираем неинформативные короткие слова.
Чтобы сэкономить время, мы скомбинируем наши тестовый и тренировочный датафреймы и пройдём все шаги по очистке данных на каждом из них:

Ну а теперь создадим регулярное выражение, которое даст нам возможность точно выделить и удалить ники из наших твитов:
def remove_pattern(input_txt, pattern):
r = re.findall(pattern, input_txt)
for i in r:
input_txt = re.sub(i, '', input_txt)
return input_txt
combi['tidy_tweet'] = np.vectorize(remove_pattern)(combi['tweet'], "@[\w]*")Сейчас наш скомбинированный датафрейм больше не должен содержать ники. Мы можем удалить специальные символы, цифры и знаки препинания простым скриптом:
# Remove special characters, numbers, punctuation
combi['tidy_tweet'] = combi['tidy_tweet'].str.replace("[^a-zA-Z#]", " " )Затем мы удалим очень короткие слова, так как они не имеют в нашем случае много смысла:
# Removing short words
combi['tidy_tweet'] = combi['tidy_tweet'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))Давайте посмотрим, как наш комбинированный датафрейм выглядит теперь:
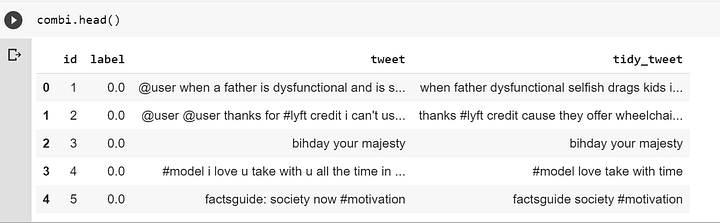
Отлично!
Лексический анализ
А вот тут начинается самое интересное. Машинные алгоритмы распознают текст не так, как мы с вами. Люди понимают смысл слов, а программа — может обнаруживать паттерны, проходясь по очень большим текстам. Нам же с вами было бы сложно прочитать такое количество текста быстро.
Хорошо, что у нас есть способ предварительно обработать текст. Речь идет о лексическом анализе. После его окончания текст структурирован таким образом, чтобы “котлеты были отдельно от мух”.
Как это может выглядеть? Пример:
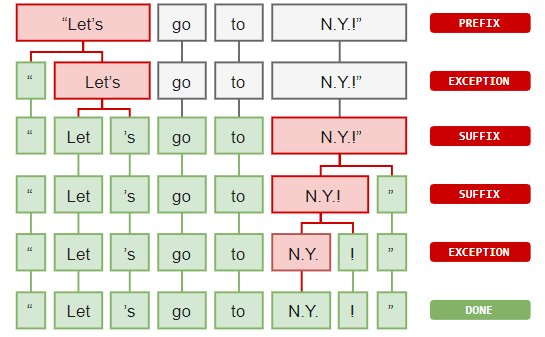
Суть лексического анализа проста. Происходит сортировка текста на отдельные компоненты:

Бум! С этой частью закончили.
Морфологический анализ
После лексического анализа идёт этап морфологического анализа. Он конвертирует каждое слово, полученное после лексического анализа, в его инфинитив. Например, морфологический анализ слова “creating” выдаст результат “create”, а “consignment” станет “consign”.
from nltk.stem.porter import *
stemmer = PorterStemmer()
tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x])Вот как выглядят твиты после анализа:


Визуализация данных
Перед тем, как подойти ближе к машинному обучению, было бы хорошо увидеть, что происходит в наших данных. Визуализация — это превосходный способ по-настоящему изучить и понять данные.
Вот некоторые вопросы, на которые мы отвечаем:
- Какое слово чаще всего встречается в наборе данных?
- Какие слова чаще всего есть в негативных и позитивных твитах?
- Сколько хештегов в твите?
- Какие есть закономерности?
Общие слова
Чтобы посмотреть на самые часто встречающиеся слова в наших твитах, мы можем создать облако слов и на самом деле увидеть их.
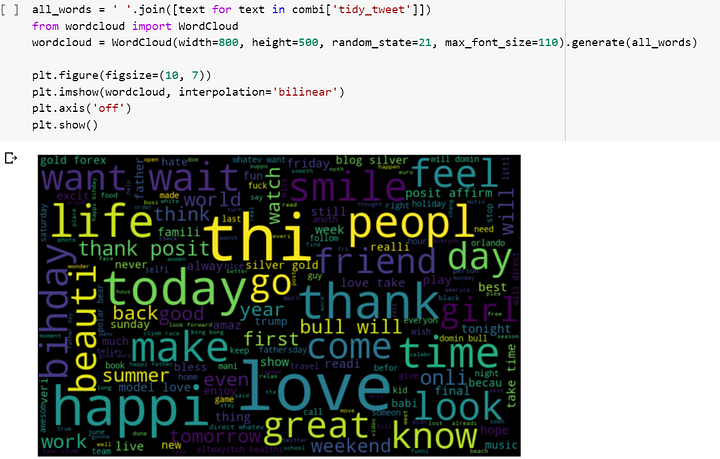
Предупреждение: слова в этом облаке определенно небезопасны.
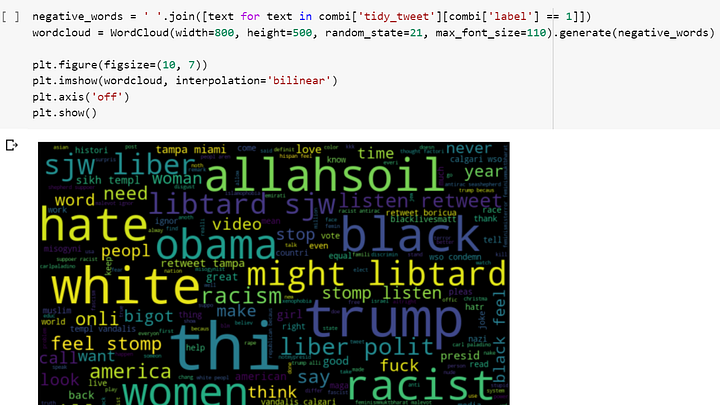
Хештеги
Мы специально оставляли хештеги, потому что они могут нести много полезной информации. Мы будем извлекать хештеги и смотреть, какие из них появляются чаще других:
def hashtag_extract(x):
hashtags = []
for i in x:
ht = re.findall(r"#(\w+)", i)
hashtags.append(ht)
return hashtags
HT_regular = hashtag_extract(combi['tidy_tweet'][combi['label'] == 0])
HT_negative = hashtag_extract(combi['tidy_tweet'][combi['label'] == 1])
HT_regular = sum(HT_regular, [])
HT_negative = sum(HT_negative, [])А теперь давайте выведем наиболее частые хештеги:
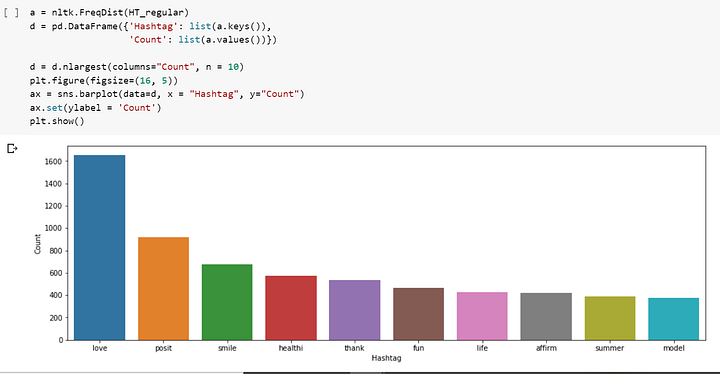
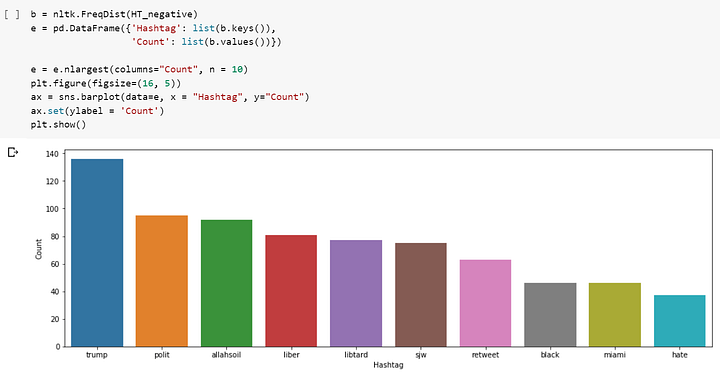
Извлечение признаков
Теперь, когда мы прошли все запланированные этапы, настало время перейти к настоящему машинному обучению.
Возьмем алгоритм логистической регрессии для того, чтобы обучить нашу предиктивную модель. Перед началом обучения модели, мы должны трансформировать текстовые данные в такой формат, который алгоритм действительно сможет прочитать.
Есть два метода на наш выбор: “мешок-слов” и TF-IDF (частота слов–инверсивная частота в документе).
Сначала мы поработаем по методу “мешок-слов”:

А потом по методу TF-IDF:

Теперь мы можем пользоваться полученными датафреймами в процессе обучения наших моделей логистической регрессии.
Построение модели
Время создать наши модели. Сначала мы создадим датафрейм с “мешком-слов”:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
train_bow = bow[:31962, :]
test_bow = bow[31962:, :]
xtrain_bow, xvalid_bow, ytrain, yvalid = train_test_split(train_bow, train['label'], random_state=42, test_size=0.3)
lreg = LogisticRegression()
lreg.fit(xtrain_bow, ytrain)
prediction = lreg.predict_proba(xvalid_bow)
prediction_int = prediction[:,1] >= 0.3
prediction_int = prediction_int.astype(np.int)Давайте посмотрим насколько точны результаты наших предсказаний:

Теперь построим модель с датафреймом по TF-IDF:
train_tfidf = tfidf[:31962, :]
test_tfidf = tfidf[31962:, :]
xtrain_tfidf = train_tfidf[ytrain.index]
xvalid_tfidf = train_tfidf[yvalid.index]
lreg.fit(xtrain_tfidf, ytrain)
prediction = lreg.predict_proba(xvalid_tfidf)
prediction_int = prediction[:, 1] >= 0.3
prediction_int = prediction_int.astype(np.int)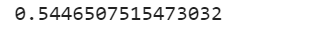
Конечно, нашу модель еще улучшать и улучшать, но тем не менее это уже отличный старт.
Что можно улучшить
- Берите разные данные из Твиттера.
- Пробуйте разные методы обработки естественного языка.
- Используйте разные алгоритмы машинного обучения.
- Настраивайте гиперпараметры.
Спасибо, что выделили время и почитали эту статью! Заходите также посмотреть мое портфолио на Github.
Читайте также:
- Простое руководство по аргументам командной строки Python
- Полное руководство по встроенным структурам данных Python
- Обработка естественного языка в Python. Основы
Перевод статьи Jerry Xu: How To Detect Mean Tweets with Machine Learning





