
Документы содержат огромное количество важной информации. Однако во многих случаях эта информация скрыта глубоко в содержимом документов, что затрудняет ее использование для последующих задач. В этой статье я расскажу, как стабильно извлекать метаданные из документов, рассмотрю подходы к извлечению метаданных и проблемы, с которыми вы столкнетесь на этом пути.
Данная статья представляет собой общий обзор процесса извлечения метаданных из документов, в котором освещаются различные аспекты, требующие внимания при выполнении этой задачи.

Зачем извлекать метаданные документов
Прежде всего, важно понять, зачем нам вообще извлекать метаданные из документов. Если информация уже содержится в документах, нельзя ли просто находить ее с помощью RAG или подобных подходов?
Во многих случаях RAG-система действительно способна находить конкретные данные, но предварительное извлечение метаданных упрощает множество последующих задач. Используя метаданные, вы можете, например, фильтровать документы по таким параметрам, как:
- тип документа;
- адреса;
- даты.
Кроме того, если у вас внедрена система RAG, она во многих случаях будет работать эффективнее с дополнительными метаданными. Это происходит потому, что вы более четко предоставляете дополнительную информацию (метаданные) большой языковой модели (LLM).
Например, если задан вопрос, связанный с датами, гораздо проще сразу предоставить модели предварительно извлеченные данные из документов, чем заставлять ее извлекать эти даты во время выполнения запроса. Это позволяет сократить как затраты, так и задержки, и с высокой вероятностью улучшит качество ответов RAG-системы.
Как извлекать метаданные
Я выделяю три основных подхода к извлечению метаданных, от самых простых к наиболее сложным:
- Регулярные выражения (Regex).
- OCR + Большие языковые модели (LLM).
- Модели с поддержкой визуальных модальностей (Vision LLM).
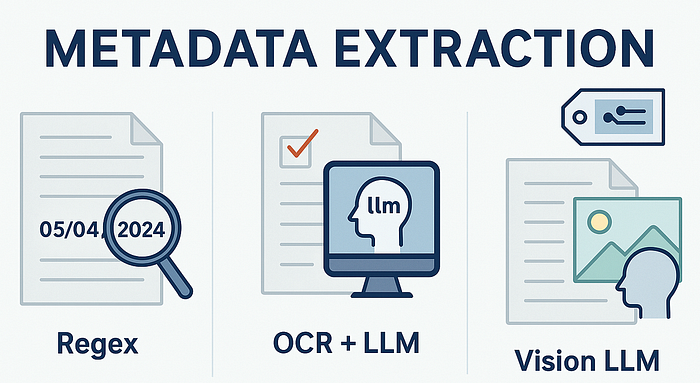
Регулярные выражения (Regex)
Regex — это самый простой и предсказуемый подход к извлечению метаданных. Регулярные выражения хорошо работают, если вы заранее знаете точный формат данных. Например, если вы обрабатываете арендные соглашения и точно знаете, что дата записана в формате «дд.мм.гггг» и всегда следует после слова «Дата: «, то Regex — это подходящий метод.
К сожалению, в большинстве случаев обработка документов сопряжена с определенными сложностями. Вам придется иметь дело с нестандартными документами и следующими проблемами:
- Даты находятся в разных частях документа.
- В тексте не хватает некоторых символов из-за плохого качества OCR-обработки.
- Даты записаны в разных форматах (например, «мм.дд.гггг», «22 октября», «22 декабря» и т. д.).
Из-за этого обычно приходится переходить к более сложным подходам, таким как OCR + LLM, который я опишу в следующем разделе.
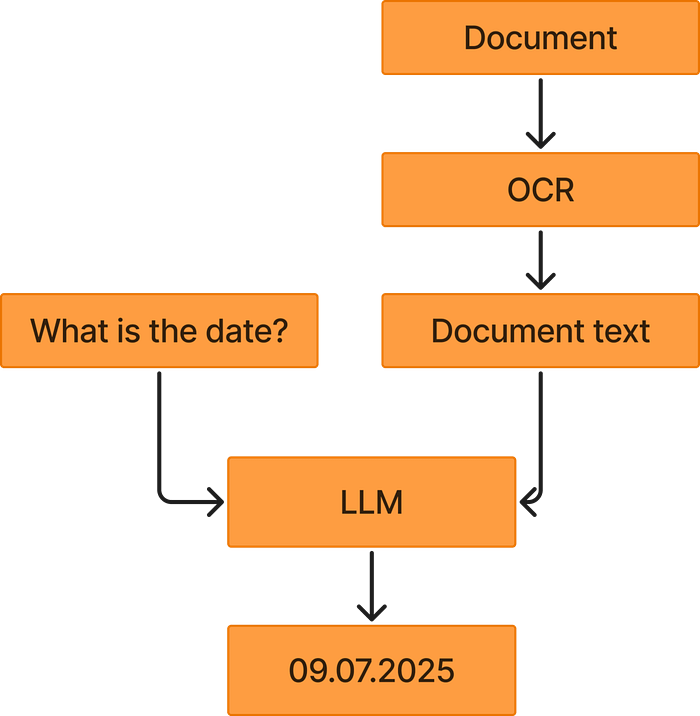
OCR + Большие языковые модели (LLM)
Мощный подход к извлечению метаданных — это комбинация OCR и LLM. Этот процесс начинается с применения OCR к документу для извлечения текстового содержимого. Затем вы берете распознанный текст и с помощью промпта (запроса) просите большую языковую модель извлечь нужные данные, например, дату из документа.
Этот подход обычно работает очень хорошо, потому что большие языковые модели способны понимать контекст (какая дата является релевантной, а какая — нет) и могут распознавать даты, записанные в самых разных форматах. Во многих случаях LLM также способны понимать как европейский стандарт («дд.мм.гггг»), так и американский («мм.дд.гггг»).
Однако в некоторых сценариях для извлечения нужных метаданных требуется визуальная информация. В таких ситуациях необходимо применять самый современный метод — модели с поддержкой визуальных модальностей (Vision LLM).
Vision LLM (модель с поддержкой визуальных модальностей)
Использование Vision LLM — это наиболее сложный подход, который характеризуется наибольшей задержкой и стоимостью. В большинстве случаев запуск Vision LLM будет значительно дороже, чем использование чисто текстовых LLM.
При работе с Vision LLM обычно необходимо убедиться, что изображения имеют высокое разрешение, чтобы модель могла прочитать текст документов. Это, в свою очередь, требует обработки огромного количества визуальных токенов, что делает процесс дорогостоящим.
Тем не менее, комбинирование Vision LLM с изображениями высокого разрешения, как правило, способно извлекать сложную информацию, которая недоступна для связки OCR + LLM. Пример такой информации показан на изображении ниже.

Vision LLM также хорошо показывают себя в сценариях с рукописным текстом, где OCR может испытывать трудности.
Проблемы при извлечении метаданных
Как я уже отмечал, документы сложны и имеют разнообразные форматы. Поэтому при извлечении метаданных возникает множество трудностей. Выделю три основные:
- Проблема выбора Vision LLM или OCR + LLM.
- Работа с рукописным текстом.
- Работа с объемными документами.
Когда использовать Vision LLM вместо OCR + LLM
В идеале можно было бы использовать Vision LLM для всех случаев извлечения метаданных. Однако это обычно невозможно из-за высокой стоимости Vision LLM. Таким образом, мы должны решить, когда применять Vision LLM, а когда достаточно OCR + LLM.
Один из вариантов — определить, требует ли извлекаемый элемент метаданных визуальной информации или нет. Если речь идет о датах, то связка OCR + LLM будет работать достаточно хорошо почти во всех сценариях. Однако если вы имеете дело с элементами вроде отмеченных чекбоксов, как в примере выше, то необходимо применять Vision LLM.
Работа с рукописным текстом
Одна из проблем упомянутого подхода (OCR + LLM) заключается в том, что некоторые документы могут содержать рукописный текст, который традиционные OCR-системы распознают не очень хорошо. Если качество OCR низкое, то и LLM, извлекающая метаданные, будет работать плохо. Следовательно, если вы знаете, что будете иметь дело с рукописным текстом, рекомендую применять модели Vision LLM, так как они, по моему опыту, гораздо лучше справляются с почерком. Важно помнить, что многие документы содержат как машинописный, так и рукописный текст.
Работа с объемными документами
Во многих случаях также придется иметь дело с очень большими документами. Если это так, необходимо учитывать, насколько глубоко в документе может находиться нужный элемент метаданных.
Это важно, потому что вам нужно минимизировать затраты, а для обработки очень длинных документов требуется много входных токенов для LLM, что обходится дорого. В большинстве случаев важная информация (например, дата) находится в начале документа, и тогда вам не потребуется много входных токенов. Однако иногда нужная информация может находиться на 94-й странице, что потребует большого количества токенов.
Проблема в том, что вы заранее не знаете, на какой странице находятся метаданные. Таким образом, по сути, вам приходится принимать решение — например, просматривать только первые 100 страниц документа, предполагая, что в большинстве документов метаданные находятся в этом диапазоне. В редких случаях, когда данные находятся на 101-й странице и далее, вы упустите их, но зато значительно сэкономите на затратах.
Заключение
В этой статье я рассказал, как можно стабильно извлекать метаданные из документов. Эти метаданные часто играют ключевую роль при выполнении последующих задач, таких как фильтрация документов по определенным параметрам. Кроме того, мы разобрали три основных подхода к извлечению метаданных: с помощью Regex, связки OCR + LLM и Vision LLM, а также затронули некоторые проблемы, с которыми вы столкнетесь.
Считаю, что извлечение метаданных остается задачей, не требующей огромных усилий, но способной принести значительную пользу в последующих процессах. Поэтому я уверен, что важность извлечения метаданных сохранится в ближайшие годы, хотя, я полагаю, мы будем наблюдать переход от метода OCR + LLM к преимущественному использованию Vision LLM.
Читайте также:
- Утраченное искусство красоты кода
- Как обогатить контекст большой языковой модели (LLM) для улучшения ее возможностей
- 10 конструкций для написания Bash-скриптов
Читайте нас в Telegram, VK и Дзен
Перевод статьи Eivind Kjosbakken: How to Consistently Extract Metadata from Complex Documents





