
Делаем анализ тональности высказываний в Twitter за 3 минуты
Предыдущие части: Часть 1, Часть 2, Часть 3, Часть 4
В этой части мы создадим скрипт Python, который при помощи Twitter поможет нам понять, что люди думают на выбранную нами тему. Для этого нам понадобится библиотека для обработки текстов на естественном языке TextBlob и всего лишь 15 строчек кода. Но почему именно Twitter? Нравится нам это или нет, люди по всему миру каждый день, каждую секунду оставляют в этой социальной сети свою реакцию и мнение по тысячам различных поводов. Прежде чем перейти к коду, давайте разберемся с основным механизмом работы анализа тональности высказываний.
Как работает анализ тональности
- Мы получаем какой-то вводимый текст, в нашем случае это твит.
- Мы разбиваем его на несколько частей или коротких предложений, в зависимости от длины сообщения. Этот процесс называется токенизация —разделение больших текстов на маленькие синтаксические единицы (токены).
- Когда мы работаем со словами, мы можем посчитать, сколько раз встречается то или иное слово. Это модель словарного пакета(это просто название, вам необязательно их запоминать).
- И, наконец, определяется значение тональности (“настроения”) каждого слова, а после этого — общее значение тональности всего текста.

Вот и всё. Так это и работает. Теперь, когда вы знаете теорию, перейдем к практике.
Шаг 1 — Подготовка
Для выполнения анализа тональности высказываний в Twitter нам нужны будут всего 2 библиотеки. Первая — tweepy, библиотека Python для доступа к API Twitter. А вторая — textblob, библиотека для обработки текстовых данных. Также она предоставляет простой API для решения основных задач в обработке естественных языков: морфологической разметки, выделения именных конструкций, анализа тональности высказываний и т.д.
Чтобы получить доступ в данным Twitter, вам нужно перейти на страницу Twitter Developer Apps и создать приложение. После этого вы получите пароли, которые нам пригодятся позже.
#Импортируем библиотеки
import tweepy
from textblob import TextBlob
#Создаем приложение на apps.twitter.com и вводим ваши пароли и токены
consumer_key = '3KFL*************'
consumer_secret = 'yltO********************'
access_token = '3014895**************'
access_token_secret = 'w7rZ*****
Шаг 2 — Аутентификация вашего приложения
Когда у вас есть пароли и токены, вы должны приступить к аутентификации. 0AuthHandler нужны пароли аутентификации. Access tokens определяет разрешения — чтение, запись, или же и то, и другое. После этого предоставьте этот код API tweepy, и всё.
#Аутентифицируйте ваше приложение
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
Шаг 3 — Анализ тональности высказываний
С помощью аутентифицированного аккаунта (api) мы можем вести поиск по конкретным словам, которые нужны для анализа тональности. После выбора ключевых слов и подборки твитов, мы обработаем их при помощи textblob.
Для начала, мы выведем самые последние твиты, связанные с нашим ключевым словом. После мы используем textblob, чтобы определить тональность каждого отдельного твита и выведем её тоже. Посмотрим, что сказал глава Apple Тим Кук.
# Ищем твиты
public_tweets = api.search('Tim Cook')
for tweet in public_tweets:
#Выводим твиты
print(tweet.text)
#Используем textblob для определения тональности твита
analysis = TextBlob(tweet.text)
print(analysis.sentiment)
print('\n')
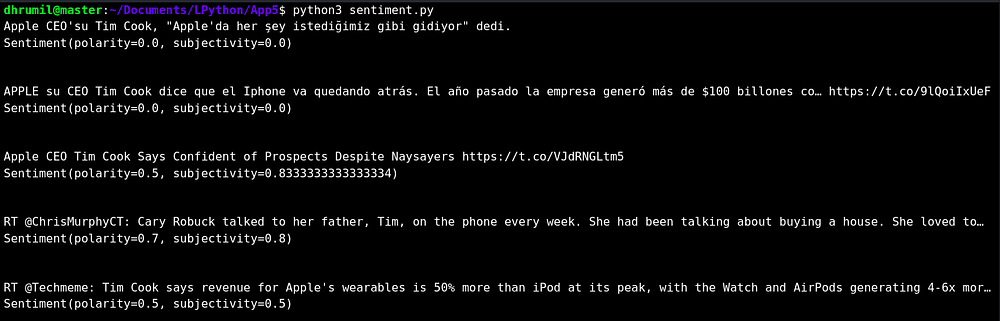
Как вы видите, программы выводит несколько твитов, а также анализ их тональности. Важно отметить, что polarity определят, насколько эмоциональная окраска текста позитивна или негативна (от -1 до 1).Аsubjectivity измеряет насколько в тексте выражено личное мнение автора.
В заключение
Я пытался сделать эту статью максимально краткой, потому что анализ тональности — это важный аспект теории анализа данных. И переизбыток информации мог вас отпугнуть в самом начале. Существуют огромные приложения, которые используют анализ тональности высказываний, очень рекомендую вам ознакомиться с ними. Приятного изучения!
Перевод статьи Dhrumil Patel: Master Python through building real-world applications (Part 5)





