
Создаем интерактивный словарь
В этой серии из 10 статей мы будем использовать Python для написания 10 реальных приложений. И в процессе создания этих приложений мы будем осваивать всё новые важные и нужные инструменты, чтобы развивать ваши навыки владения Python.
Многие не понимают, что изучение языков программирования важно. Пускай это кажется сложным, но вам нужно попробовать. Не переживайте, если у вас нет никакого практического опыта работы с Python. Для начала вам будет достаточно просто понимать основы этого языка.
Первым приложением, которое мы создадим, будет словарь. Интерактивный словарь. Да, я знаю, что это просто. Но путешествие в тысячу миль начинается с первого шага, поэтому вам нужно его сделать. Так что будет делать наш словарь? Он будет возвращать значение слова, которое ввел пользователь, так ведь словари и работают, правильно? Кроме того, если пользователь сделал опечатку в слове, наша программа предложит наиболее подходящее слово, спрашивая “возможно, вы имели в виду это?”. А если слово имеет более одного значения, то программа должна возвращать их все. Теперь это уже не кажется таким легким, да? Давайте разбираться.
К концу этой статьи вы будете чувствовать себя так же, как и этот мужчина на фотографии после своего прыжка. Потому что изучение и переживание чего-то нового повышает наши настроение и мотивацию. И именно этим мы сегодня и займемся.

Примечание: Наряду с изучением того, как создавать приложения, уделите особое внимание тому, как написан код. Чистый код также очень важен.
Шаг 1 — Данные
Чтобы понять, как будет работать словарь, нам нужно понимать, какие данные он будет использовать в работе. Что ж, приступим. Данные тут представлены в формате JSON. Если вы уже знакомы с этим форматом, можете пролистать на пару абзацев вниз. Однако если вы видите это название впервые, или вам нужно освежить знания, я вам помогу. Советую вам посмотреть на данные, которые мы будем использовать, чтобы лучше разобраться с форматом JSON. Вы найдете их тут и тут.
Интересный факт: к 2017 году каждую секунду генерировалось 2,500,000,000,000,000,000 (2,5 квинтиллиона) байт информации. Да, вы не ошиблись, каждую секунду.
JSON, или JavaScript Object Notation — простейший, удобный для чтения (как для людей, так и для компьютеров) формат структурирования данных. Он, в основном, содержит две структуры: ключ и значение, связанное с этим ключом. Возьмем пример из наших данных. Ниже представлена пара “ключ/значение”. Ключ — это выражение “abandoned industrial site”, а значение — “Site that cannot be used for any purpose, being contaminated by pollutants”, определение этого выражения.
"abandoned industrial site": ["Site that cannot be used for any purpose, being contaminated by pollutants."]
Теперь давайте приступим к коду. Во-первых, мы импортируем библиотеку JSON, затем вызываем функцию load, чтобы загрузить наши данные в формате .json. Важно, что мы загружаем данные в формате .json, но храниться они будут в переменной “data”, как “словарь” Python. Если вы не знакомы со словарями Python, представляйте их в виде хранилищ. Это почти то же, что и формат JSON, и так же позволяет хранить пары “ключ-значение”.
#Import library
import json
#Loading the json data as python dictionary
#Try typing "type(data)" in terminal after executing first two line of this snippet
data = json.load(open("data.json"))
#Function for retriving definition
def retrive_definition(word):
return data[word]
#Input from user
word_user = input("Enter a word: ")
#Retrive the definition using function and print the result
print(retrive_definition(word_user))
После загрузки данных, создадим функцию, которая будет брать слово и искать его значение в этих данных. Это просто.

Шаг 2— Проверка на несуществующие слова
Использование простого элемента if-else поможет проводить проверку на несуществующие слова. Если такого слова нет в данных, просто дайте пользователю знать об этом. В нашем случае, программа выдаст “The word doesn’t exist, please double check it.” (“Такого слова не существует, пожалуйста, перепроверьте”)
#Import library
import json
#Loading the json data as python dictionary
#Try typing "type(data)" in terminal after executing first two line of this snippet
data = json.load(open("dictionary.json"))
#Function for retriving definition
def retrive_definition(word):
#Check for non existing words
if word in data:
return data[word]
else:
return ("The word doesn't exist, please double check it.")
#Input from user
word_user = input("Enter a word: ")
#Retrive the definition using function and print the result
print(retrive_definition(word_user))

Шаг 3 — Чувствительность к регистру
Каждый пользователь вводит слова по-своему. Одни напишут слово в нижнем регистре, а другие могут написать то же слово с заглавной буквы. Нам нужно, чтобы результат для каждого из этих вариантов был одинаковым. Например, при вводе “Rain” и “rain” должны выводиться одни и те же результаты. Чтобы добиться этого, мы конвертируем слово, введенное пользователем, в нижний регистр, потому что наши данные записаны так же. Для этого используем встроенную функцию Python lower().
Условие 1 — Чтобы удостовериться, что программа возвращает значение слов, которые начинаются с заглавной буквы ( Delhi, Texas), мы проведем проверку на заглавную букву в условии else-if.
Условие 2 — Чтобы удостовериться, что программа возвращает значение сокращений (USA, NATO), мы проведем проверку на верхний регистр.
#Import library
import json
#Loading the json data as python dictionary
#Try typing "type(data)" in terminal after executing first two line of this snippet
data = json.load(open("dictionary.json"))
#Function for retriving definition
def retrive_definition(word):
#Removing the case-sensitivity from the program
#For example 'Rain' and 'rain' will give same output
#Converting all letters to lower because out data is in that format
word = word.lower()
#Check for non existing words
#1st elif: To make sure the program return the definition of words that start with a capital letter (e.g. Delhi, Texas)
#2nd elif: To make sure the program return the definition of acronyms (e.g. USA, NATO)
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
#Input from user
word_user = input("Enter a word: ")
#Retrive the definition using function and print the result
print(retrive_definition(word_user))

Ваш словарь уже может выполнять свою основную задачу, возвращать значение слова. Но давайте пойдем чуть дальше. Не правда ли круто, что Google предлагает вам правильный вариант слова, если вы допустили опечатку в поисковой строке?
Что, если сможем сделать то же самое в нашем словаре? Здорово, правда? Перед тем, как приступить к этому в Шаге 5, давайте в Шаге 4 разберемся как работает эта функция.
Шаг 4 — Самое точное соответствие
Если при вводе слова пользователь допустил опечатку, наверное, вы хотите предложить ему наиболее подходящее слово и спросить, не это ли слово имелось в виду. Тут нам поможет библиотека Python difflib. Есть два способа решения этой задачи, мы попробуем оба и выберем более эффективный.
Способ 1 — Sequence Matcher
Давайте разбираться. Для начала импортируем библиотеку и вызываем из неё функцию. Функции SequenceMatcher() нужны 3 параметра. Первый параметр — “Junk”, он проверяет на наличие пробелов и пропущенных строк, в нашем случае мы вводим “None”. Второй и третий параметры — слова, которые вы сравниваете. И добавленная функция ratio выдаст вам результат в виде числа.
#Import library
import json
# This is a python library for 'Text Processing Serveices', as the offcial site suggests.
import difflib
from difflib import SequenceMatcher
#Let's load the same data againdata = json.load(open("dictionary.json"))
#Run a Sequence Matcher
#First parameter is 'Junk' which includes white spaces, blank lines and so onself.
#Second and third parameters are the words you want to find similarities in-between.
#Ratio is used to find how close those two words are in numerical terms
value = SequenceMatcher(None, "rainn", "rain").ratio()
#Print out the value
print(value)

Как вы видите, сходство между словами “rainn” и “rain” — 0,89, то есть 89%. Это первый способ. Однако в этой же библиотеке есть и другая функция, которая сразу выводит наиболее подходящее слово, без всяких чисел.
Способ 2 — Get Close Matches
Эта функция работает так: первый параметр — слово, для которого вы хотите найти самое точное соответствие. Второй параметр — список слов, с которыми это слово нужно сравнить. Третий параметр определяет, сколько совпадений вы хотите видеть в результате. И последний параметр — cutoff. Помните, в первом способе мы получили число, 0,89? Cutoff принимает указанное число, как наименьшее значение, позволяющее считать слово подходящим (0.99 — наибольшее возможное значение для самого подходящего слова). Этот параметр вы можете настроить, как вам нужно.
#Import library
import json
# This is a python library for 'Text Processing Serveices', as the offcial site suggests.
import difflib
from difflib import get_close_matches
#Let's load the same data again
data = json.load(open("dictionary.json"))
#Before you dive in, the basic template of this function is as follows
#get_close_matches(word, posibilities, n=3, cutoff=0.66)
#First parameter is of course the word for which you want to find close matches
#Second is a list of sequences against which to match the word
#[optional]Third is maximum number of close matches
#[optional]where to stop considering a word as a match (0.99 being the closest to word while 0.0 being otherwise)
output = get_close_matches("rain", ["help","mate","rainy"], n=1, cutoff = 0.75)
# Print out output, any guesses?
print(output)

Не нужно же пояснять результат, правда? Наиболее подходящее слово из трёх — “rainy”, его программа и выводит. Если вы добрались до этого этапа, молодцы, сложная часть позади. Теперь нужно просто вставить это в ваш код, чтобы получить результат.
Шаг 5 — Возможно, вы имели в виду это?
Чтобы было удобнее читать, я добавил только часть кода с if-else. Вы уже видели первые два выражения else-if, давайте разберемся с третьим. Это проверка на наличие подходящих соответствий, потому что мы можем вывести результат, только если у слова есть соответствия. Функция get close matches берет введенное пользователем слово в качестве первого параметра и сравнивает с ним все загруженные нами данные. Как мы поняли ранее, в данном случае ключом будут слова из наших данных, а значением — их определения. [0] в операторе возврата означает, что в результате будет выведено наиболее точное из всех соответствий.
#Check for non existing words
#1st elif: To make sure the program return the definition of words that start with a capital letter (e.g. Delhi, Texas)
#2nd elif: To make sure the program return the definition of acronyms (e.g. USA, NATO)
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
#3rd elif: To find a similar word
#-- len > 0 because we can print only when the word has 1 or more close matches
#-- In the return statement, the last [0] represents the first element from the list of close matches
elif len(get_close_matches(word, data.keys())) > 0:
return ("Did you mean %s instead?" % get_close_matches(word, data.keys())[0])

Да, да, именно это я и имел в виду. А что теперь? Нельзя просто так оставить этот вопрос. Если это пользователь и имел ввиду, программа должна возвращать значение этого слова. Этим мы и займемся в следующем шаге.
Шаг 6 — Возвращение значения
Ещё одно действие пользователя, ещё один оператор if-else, и всё. Программа выводит значение предложенного слова.
elif len(get_close_matches(word, data.keys())) > 0:
action = input("Did you mean %s instead? [y or n]: " % get_close_matches(word, data.keys())[0])
#-- If the answers is yes, retrive definition of suggested word
if (action == "y"):
return data[get_close_matches(word, data.keys())[0]]
elif (action == "n"):
return ("The word doesn't exist, yet.")
else:
return ("We don't understand your entry. Apologies.")

Шаг 7 —Вишенка на торте
Да, мы получаем значение слова “rain”, но вместе с ним выводятся квадратные скобки и всё прочее. Выглядит не очень красиво. Давайте уберем всё лишнее, и придадим этому более чистый вид. Вы знаете, что у слова “rain” несколько значений? Есть немало многозначных слов, поэтому для них программа будет повторять вывод, пока не выдаст все значения, а для однозначных слов она просто будет выводить это значение.
#Retrive the definition using function and print the result
output = retrive_definition(word_user)
#If a word has more than one definition, print them recursively
if type(output) == list:
for item in output:
print("-",item)
#For words having single definition
else:
print("-",output)
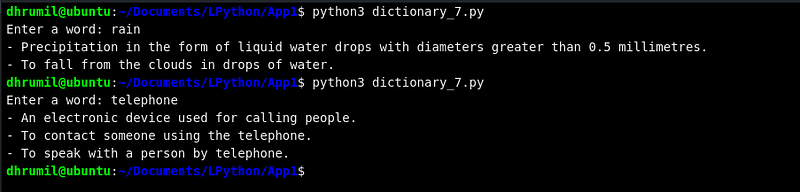
Выглядит намного красивее, правда? Ниже прикрепляю весь код полностью, можете изменять и улучшать его, как вам вздумается.
Код
#Import library
import json
from difflib import get_close_matches
#Loading the json data as python dictionary
#Try typing "type(data)" in terminal after executing first two line of this snippet
data = json.load(open("data.json"))
#Function for retriving definition
def retrive_definition(word):
#Removing the case-sensitivity from the program
#For example 'Rain' and 'rain' will give same output
#Converting all letters to lower because out data is in that format
word = word.lower()
#Check for non existing words
#1st elif: To make sure the program return the definition of words that start with a capital letter (e.g. Delhi, Texas)
#2nd elif: To make sure the program return the definition of acronyms (e.g. USA, NATO)
#3rd elif: To find a similar word
#-- len > 0 because we can print only when the word has 1 or more close matches
#-- In the return statement, the last [0] represents the first element from the list of close matches
if word in data:
return data[word]
elif word.title() in data:
return data[word.title()]
elif word.upper() in data:
return data[word.upper()]
elif len(get_close_matches(word, data.keys())) > 0:
action = input("Did you mean %s instead? [y or n]: " % get_close_matches(word, data.keys())[0])
#-- If the answers is yes, retrive definition of suggested word
if (action == "y"):
return data[get_close_matches(word, data.keys())[0]]
elif (action == "n"):
return ("The word doesn't exist, yet.")
else:
return ("We don't understand your entry. Apologies.")
#Input from user
word_user = input("Enter a word: ")
#Retrive the definition using function and print the result
output = retrive_definition(word_user)
#If a word has more than one definition, print them recursively
if type(output) == list:
for item in output:
print("-",item)
#For words having single definition
else:
print("-",output)
Итог
Можно многому научиться, применяя свои знания на практике. Сегодня вы узнали о данных JSON, основных функциях Python, новой библиотеке ‘difflib’ . И, что не менее важно, вы узнали, как писать чистый код. Берите разные наборы данных и применяйте свои навыки, потому что только так можно стать специалистом в сфере анализа данных.
Приятного обучения.
Перевод статьи Dhrumil Patel: Master Python through building real-world applications (Part 1)





