
Создаем блокировщик сайтов в 3 шага
Предыдущие части: Часть 1, Часть 2
Технологии стремительно развиваются, как и мир в целом. Каждый день вы сталкиваетесь с чем-то, о чем раньше никогда не слышали. Но это не проблема. Проблема в том, чтобы найти подходящие ресурсы, чтобы изучать всё в правильном порядке.
Постоянно спрашивайте себя: “А на то ли я трачу своё время?”. Ведь время — это всё, что у вас есть. И однажды вы можете обнаружить, что осталось его меньше, чем вы думали.
–Рэнди Пауш
Перед тем, как разбираться с машинным обучением и всеми этими современными словечками, которые у всех на слуху, давайте создадим блокировщик сайтов с простейшими структурами данных и файловыми операциями при помощи основных принципов Python. И возможно, через полгода вы скажете: “Начинал с самых азов, и вот теперь я здесь”. Возможно, кто знает.
Шаг 1 — Леонардо ди Каприо
Среда. Среда очень важна. По сути настроить её можно в 3 шага. Первое, найдите путь к файлу hosts (в Windows C:\Windows\System32\drivers\etc\hosts, а в Linux etc/hosts). Если вы с компьютером на “ты”, возможно, вы уже игрались с этим файлом. Но если же нет, файл hosts можно использовать, чтобы назначить имя хоста для IP адресов (перенаправлять сайты или блокировать их, указывая на localhost) в любой операционной системе.
Второе, нужно определиться с IP адресом, на который мы будем перенаправлять сайты, в нашем случае это localhost. localhost — это стандартное имя хоста, которое даётся самой машине. Чаще всего оно представлено IP адресом 127.0.0.1. И, наконец, нам нужен список сайтов, которые мы хотим блокировать.
#Path to the host file host_path = "/etc/hosts" #Redirect to local host redirect = "127.0.0.1" #Websites to block website_list = ["www.netflix.com","www.facebook.com"
Шаг 2 — Rihanna и Drake
Среда настроена. В какое время вы хотите блокировать эти сайты? Скорее всего, в рабочие часы, да? Но как мы будем это определять? Мы же не сможем делать это вручную? Конечно же, нет. Следовательно, мы будем использовать собственную библиотеку Python datetime, чтобы проверять время в момент работы кода.
Мы используем цикл while, потому что он позволяет быстрее запускать код. В условии if мы проверяем, рабочее сейчас время, между 8.00 и 16.00, или нет. Если код возвращает Rihanna, это значит, что сейчас рабочее время. А если вы видите Drake, развлекайтесь, это план Бога(Прим: песня “God’s plan”). time.sleep(5) добавляет пятисекундную задержку. Я думаю, это понятно.
Примечание — Для безопасности, скопируйте файл hosts в свою рабочую папку и задавайте путь именно к нему, а не к оригинальному файлу. Когда мы сделаем всё, что нам нужно, мы снова зададим путь к оригинальному файлу.
#Import libraries
import time
from datetime import datetime as dt
#Path to the host file, redirect to local host, list of websits to block
host_path = "/etc/hosts"
redirect = "127.0.0.1"
website_list = ["www.netflix.com","www.facebook.com"]
#Condition
while True:
#Check for the current time
if dt(dt.now().year,dt.now().month,dt.now().day,8) < dt.now() < dt(dt.now().year,dt.now().month,dt.now().day,16):
print("Rihanna")
else:
print("Drake")
time.sleep(5)
Шаг 3 — Дональд Трамп
Извините меня за эти несмешные шутки с заголовками, ничего не могу с собой поделать. Перейдем к финальному этапу, блокировке сайтов. Для этого мы будем использовать основные операции чтения/записи файлов на Python. Эта операция делится на 2 части. Сначала мы блокируем сайты в рабочее время, а затем разблокируем в нерабочее. Давайте сначала разберемся с первой частью.
Проверяем текущее время. Так, чтобы прочесть содержимое файла, его надо сначала открыть — основное правило работы с файлами. Сперва мы открываем файл, потом считываем всё его содержимое и сохраняем его в нашей переменной ‘content’, это наше содержимое. r+, которое вы видите после пути к файлу, — это разрешение на чтение и запись как из файла, так и в файл. Вы открыли файл, считали содержимое, что теперь? Проверьте находится ли сайт в списке, и, если нет, добавьте его туда. Первая часть сделана, сайта из списка теперь блокированы. Вы можете увидеть, как работает ваш код.
while True:
#Check for the current time
if dt(dt.now().year,dt.now().month,dt.now().day,8) < dt.now() < dt(dt.now().year,dt.now().month,dt.now().day,16):
print("Rihanna")
#Open file and read the content
file = open(host_path,"r+")
content = file.read()
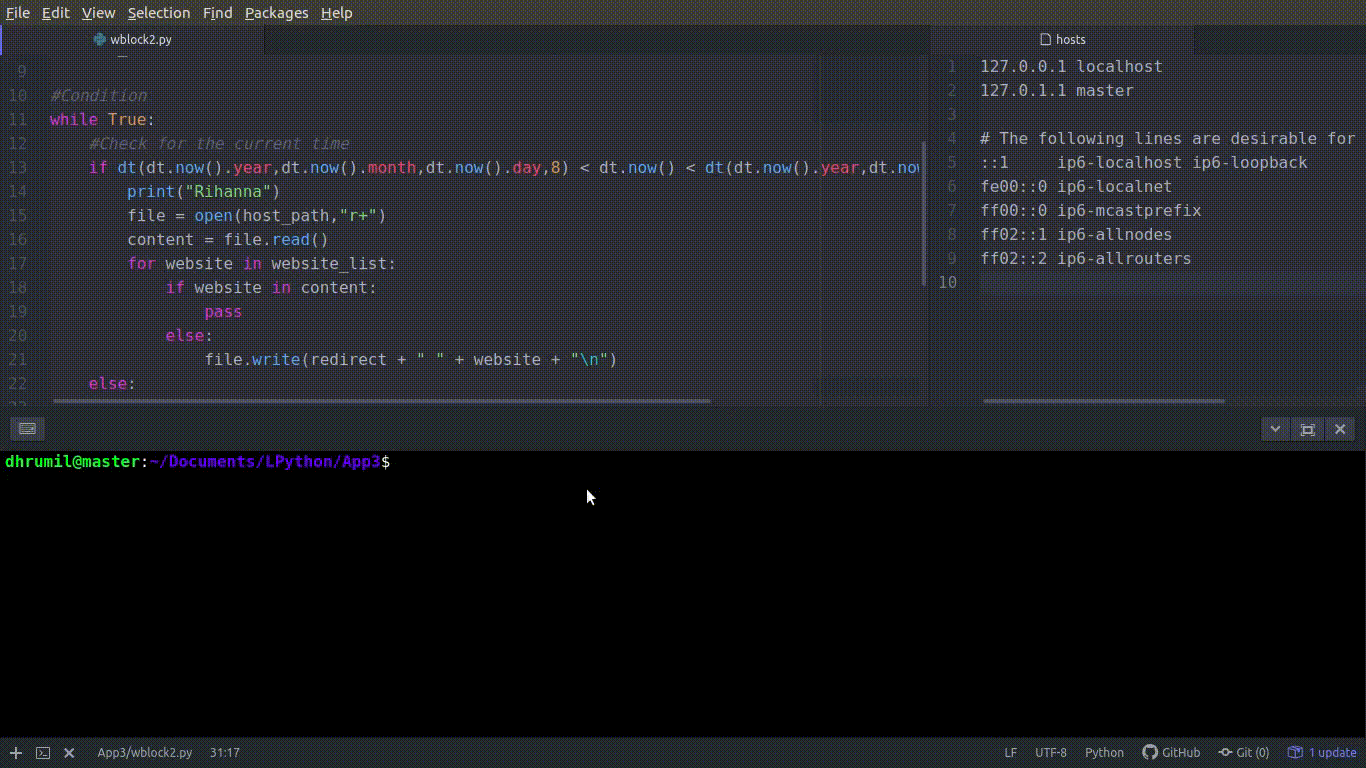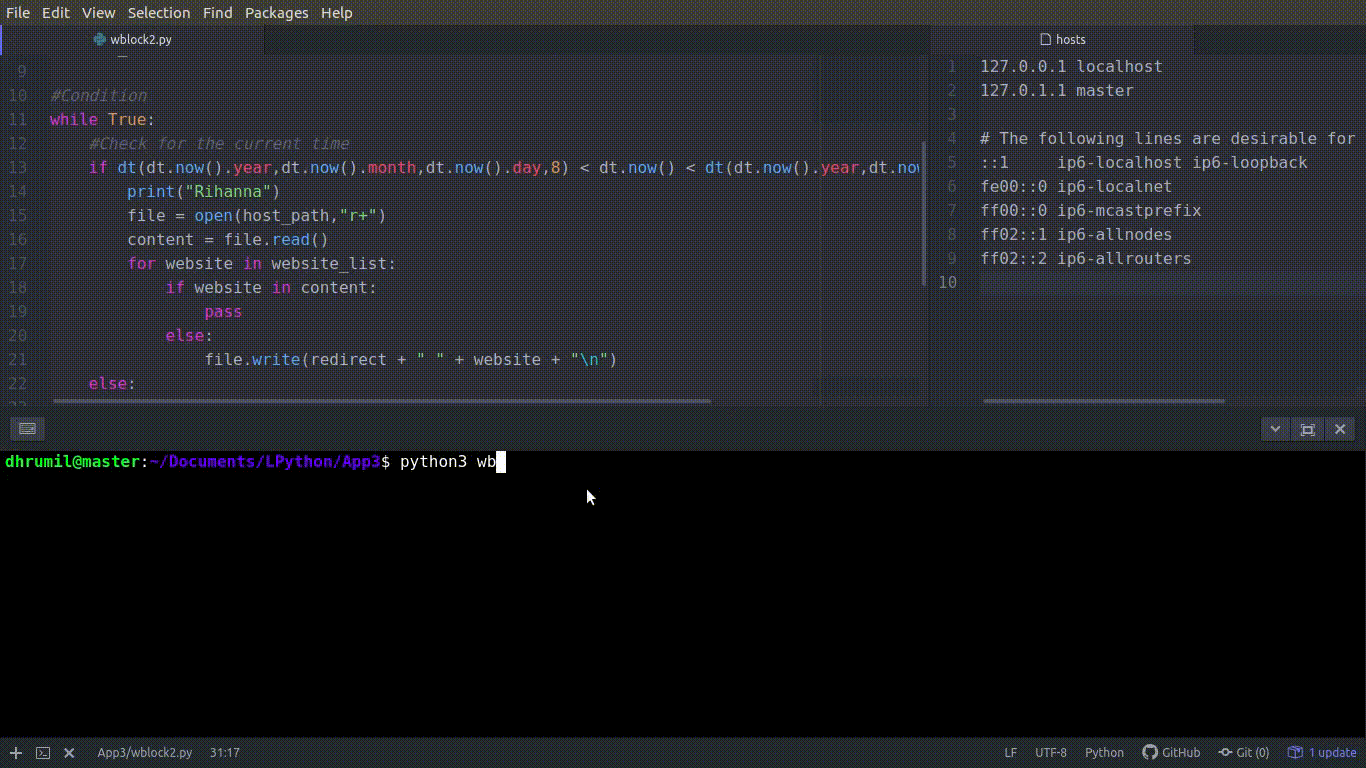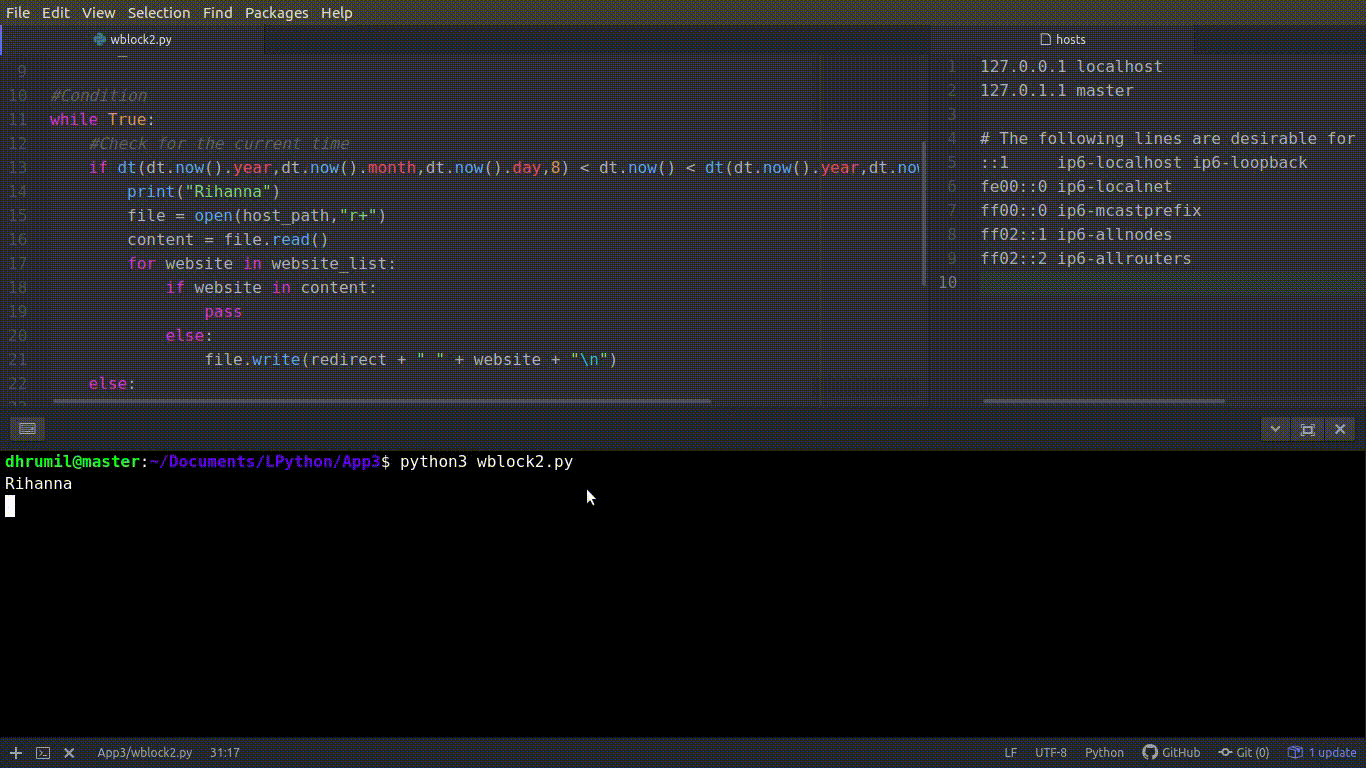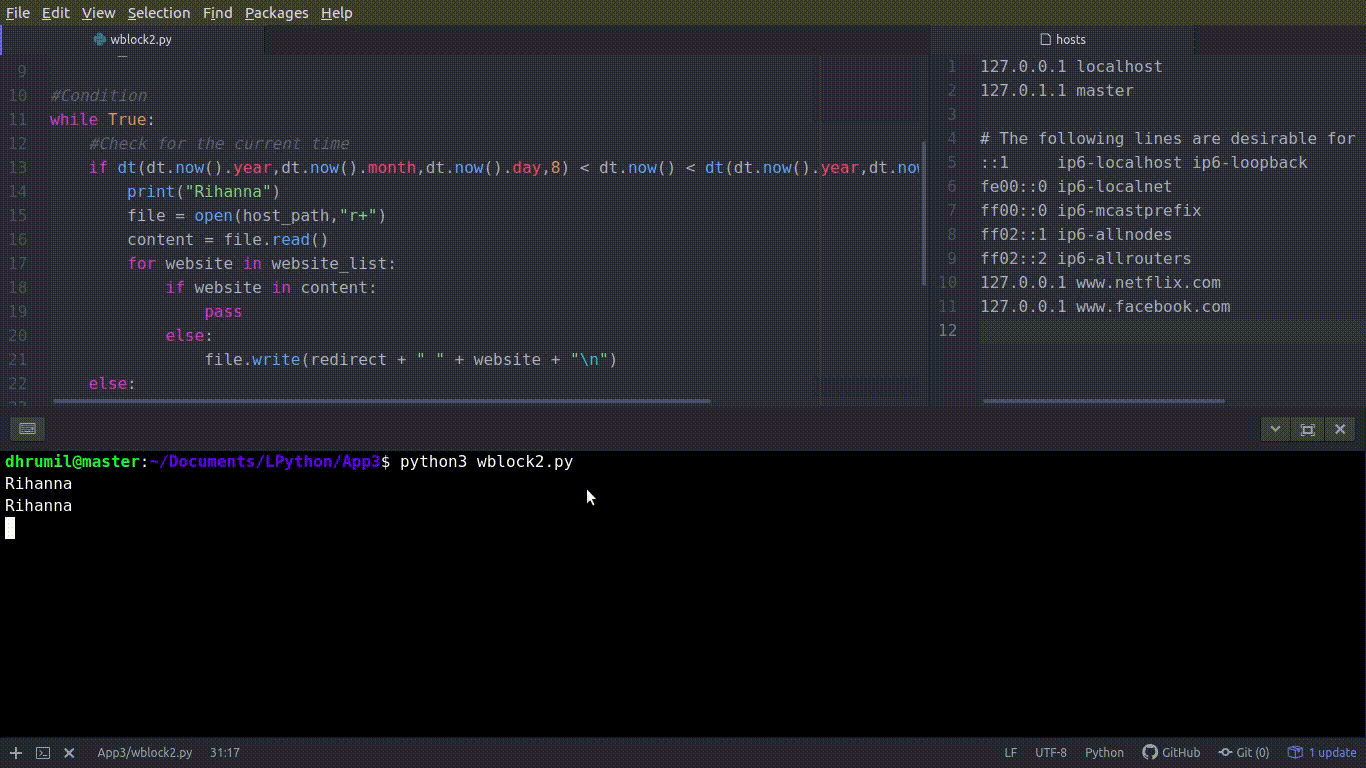
for website in website_list:
if website in content:
pass
else:
#Write the IP of loalhost and name of the website to block
file.write(redirect + " " + website + "\n")
else:
print("Drake")
А теперь пришло время для Netflix и отдыха, поэтому нам нужно эти сайты разблокировать. По сути, нам нужно удалить сайты, которые мы добавили в файл. Чтобы это сделать, сначала открываем файл. Вместо того, чтобы читать весь файл, как поток данных, мы будем читать по строчкам. Поэтому используемfile.readlines(). Используем file.seek(0), чтобы установить курсор в начало файла. Теперь важная часть. Вдумчиво прочтите её пару раз. Цикл может показаться вам сложным и запутанным, но это, на самом деле, не так. У нас есть if и forв одной строке. website in line проверяет первую строчку файла hosts, но какой сайт она ищет? Благодаря for она ищет сайт из нашего списка сайтов. Проще говоря, суть этой строки такова: если в строке из хост-файла нет сайта из нашего списка, записываем эту строку. Если в строке содержится нужный нам сайт, то её игнорируем. Я надеюсь, что теперь стало понятно, потому что это важно. Вот так сайты удаляются из списка.
else:
print("Drake")
#Open hosts file and read content from it- line by line
file = open(host_path,'r+')
content = file.readlines()
#Take back pointer to starting of the file from the end of file
file.seek(0)
for line in content:
#Please check explaination for this line
if not any(website in line for website in website_list):
file.write(line)
file.truncate()
time.sleep(5)
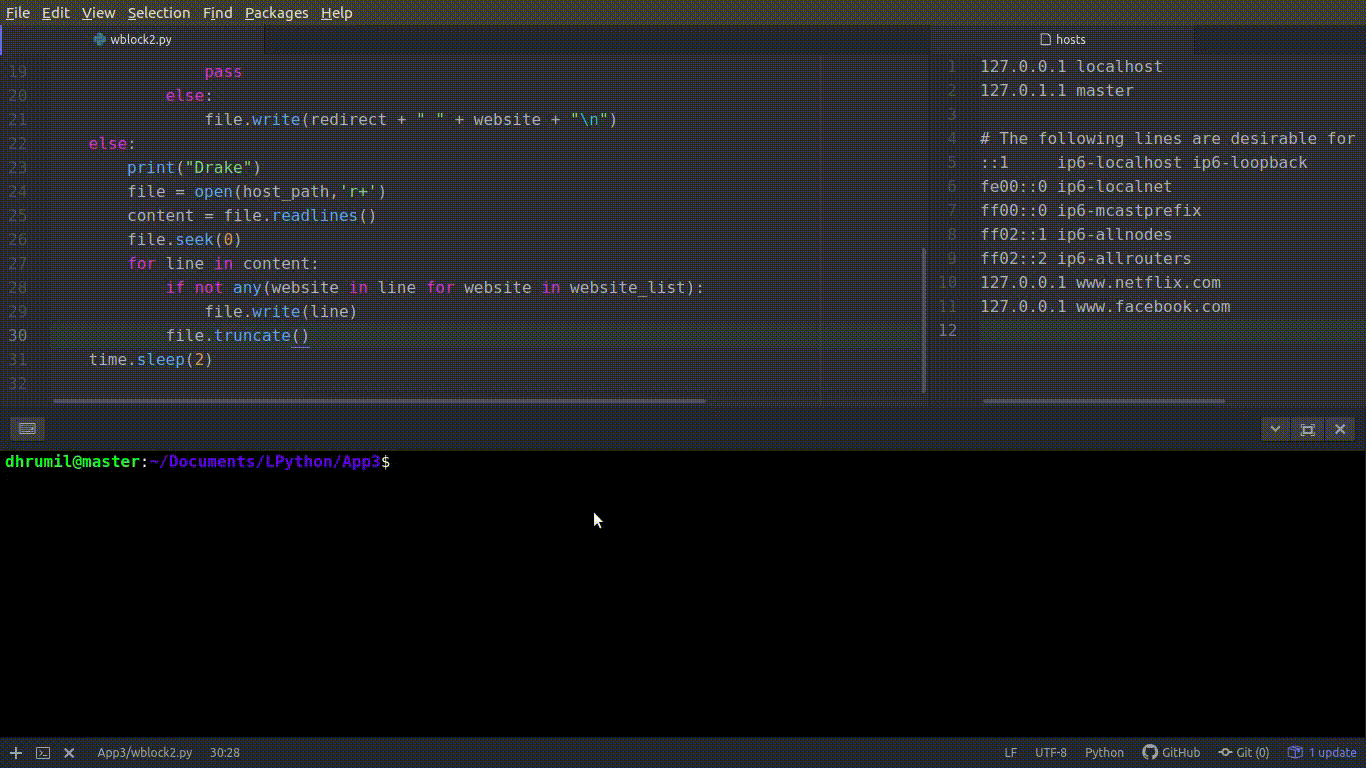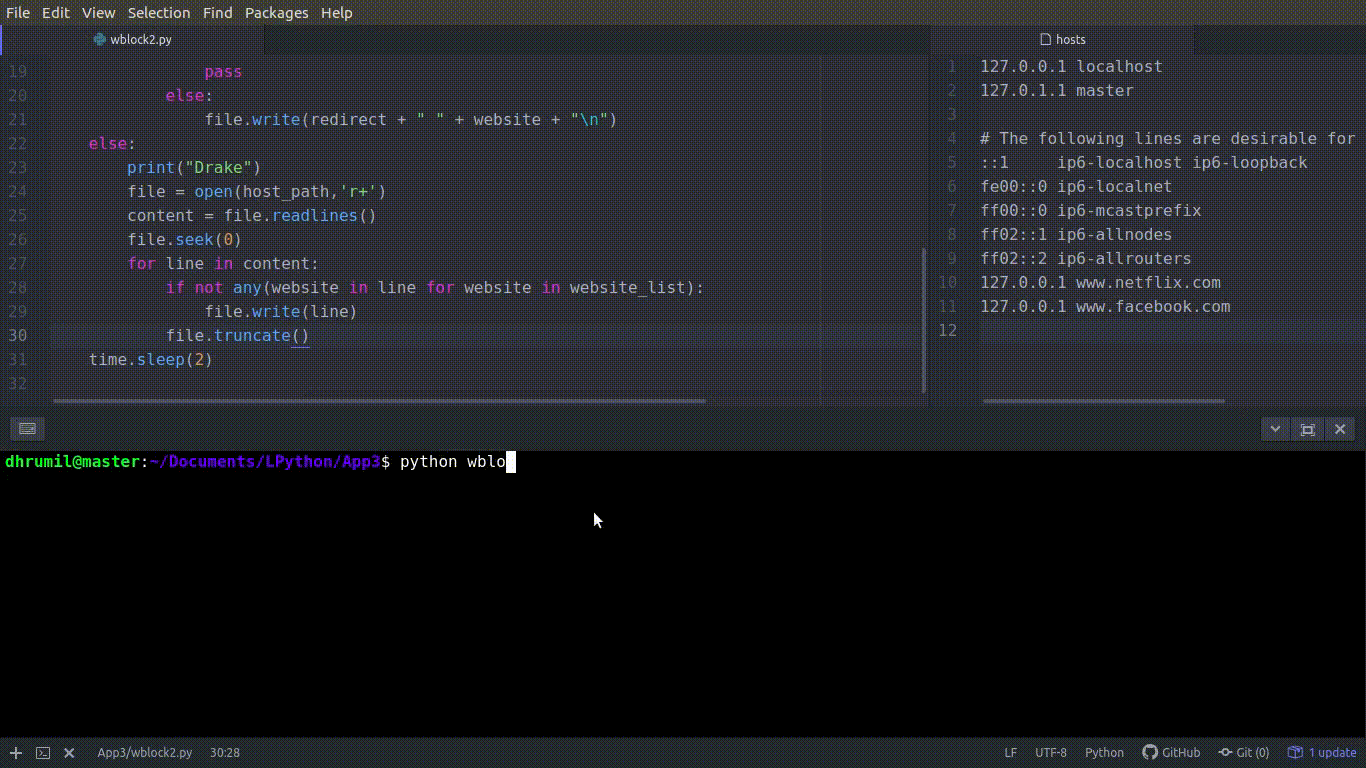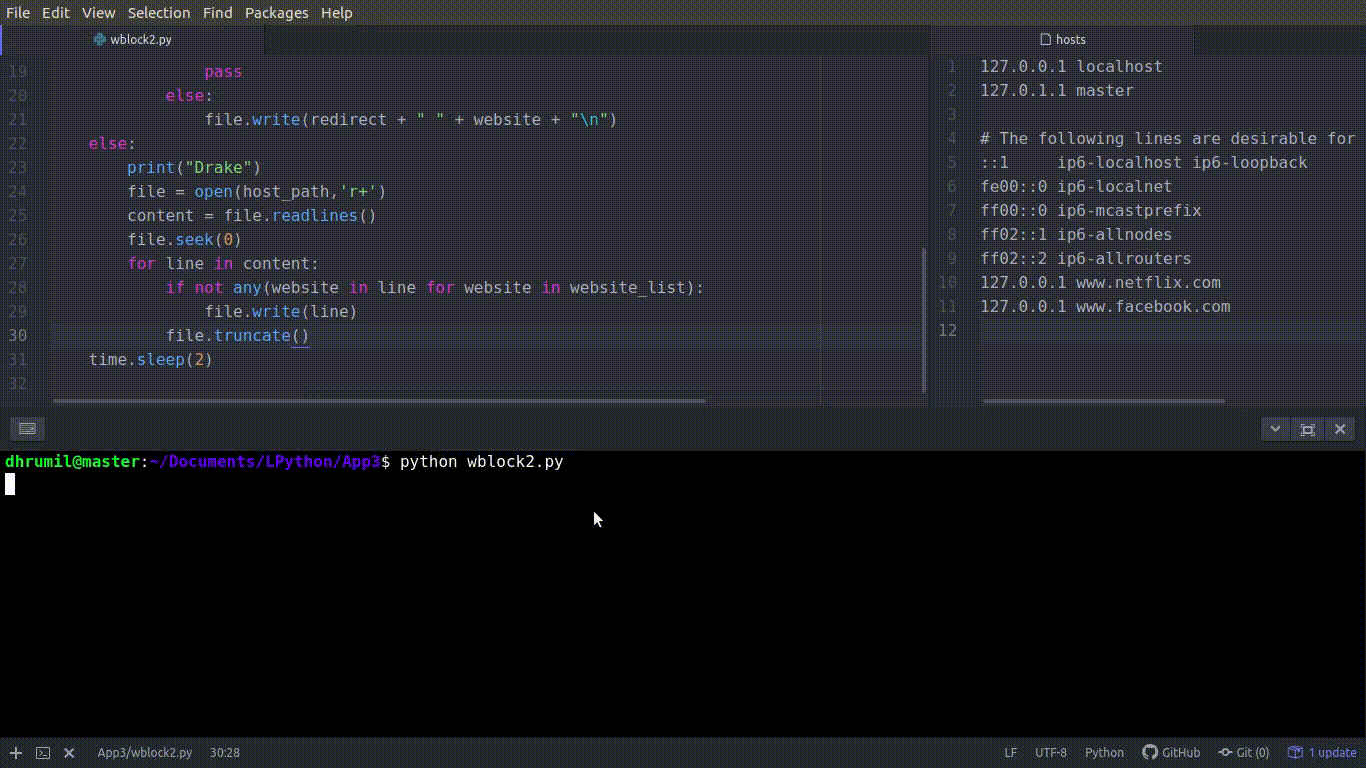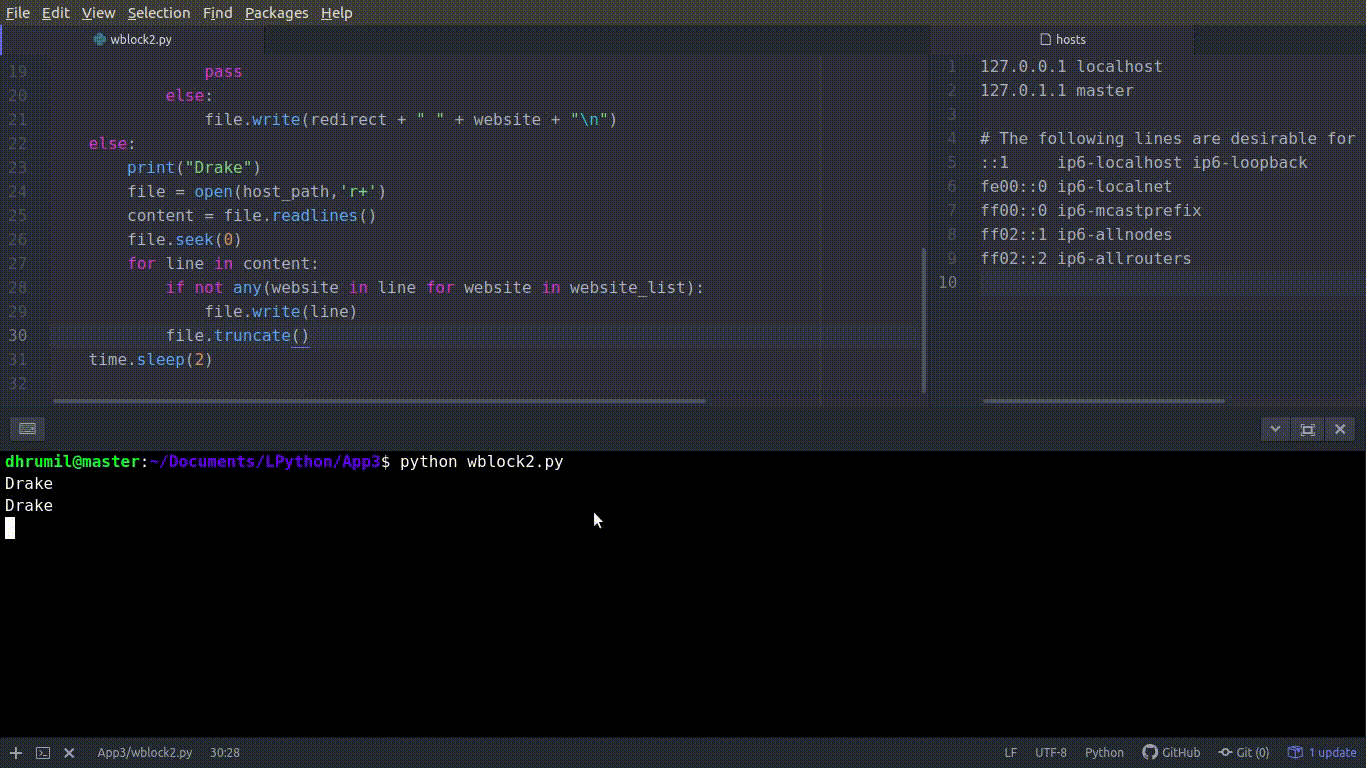
Почти готово
Вы отлично поработали и создали блокировщик сайтов, но вы же не хотите каждый раз применять код, чтобы блокировать сайты, верно? Поэтому мы используем для этого планировщик задач. Использовать будем Cron Job Scheduler (он сразу установлен в операционную систему, вам не придется ничего устанавливать). Просто откройте таблицу Cron с разрешением sudo и параметром -e.

После команды “@reboot” добавьте путь к нашему главному файлу.
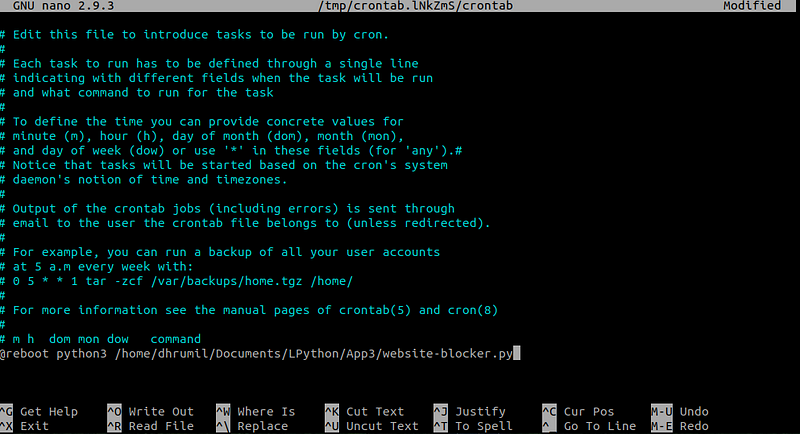
Всё готово. В успешно заблокировали сайты из нашего списка. Перезагрузите компьютер и посмотрите, что изменилось.
Итоговые примечания
Сейчас блокировщики сайтов широко распространены и вы можете найти их в ваших браузерах в виде расширений. Но многие ли знают, как работают эти приложения? Единицы. Но знать, как такие вещи работают, важно. Весь код этого приложения, и других приложений тоже, вы можете найти в моём профиле GitHub. Поздравляю вас с тем, что освоили это. Встретимся в следующей части.
Насколько хорошо вы знаете Python? На нашем сайте вы найдете множество интересных тестов, включая тесты по Python, которые помогут проверить ваш уровень знаний языка! Небольшой тест; Большой тест.
Перевод статьи Dhrumil: Master Python through building real-world applications (Part 3)
 - залог отличной документации")




