
Многим знакомы отправка и получение сообщений в Apache Kafka. Но что происходит после отправки сообщения?
Прежде чем переходить к описанию этапов, обратимся к кластерам Kafka.
Кластер Kafka
Кластер Kafka состоит из брокеров, каждый брокер — это отдельный сервер, где запускается программное обеспечение Kafka, внутри которого создаются темы для распределения потоков данных. Каждая тема разбивается на разделы, упорядоченные журналы записей. Каждый раздел темы размещается в любом брокере кластера.
Зачем нужны разделы?
Для эффективного масштабирования Kafka и распределения данных.
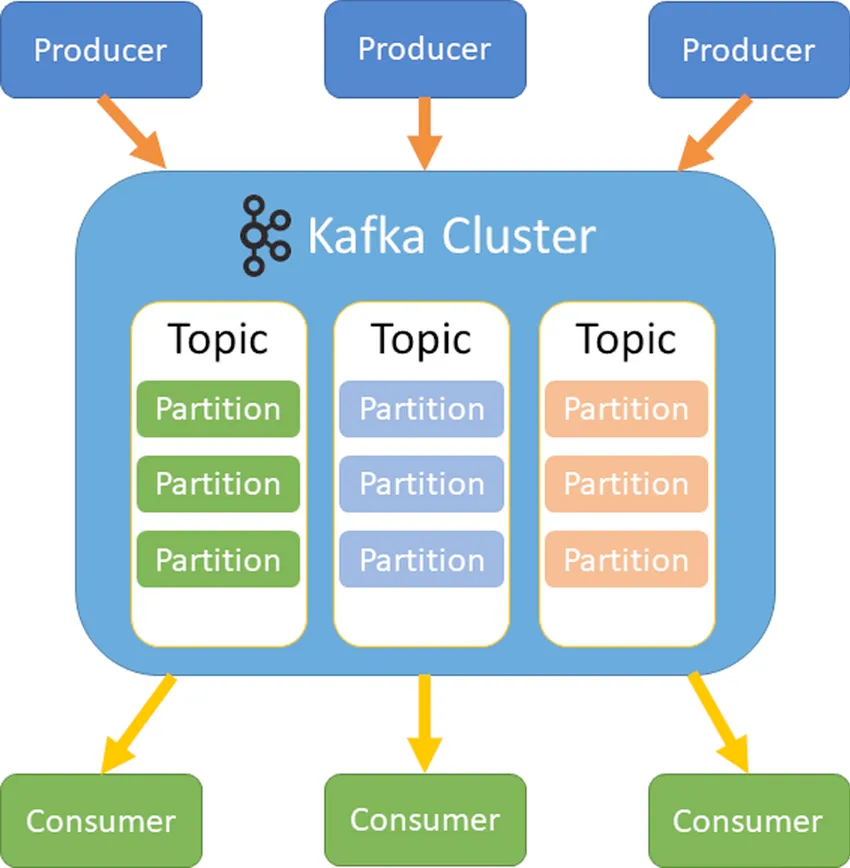
Жизненный цикл сообщений
Разделим жизненный цикл сообщений на четыре этапа:
- Отправка сообщения
- Самоуправляемый кворум метаданных Kafka
- Сохранение сообщения в Kafka
- Получение сообщений
Этап 1. Отправка сообщений
Представьте температурный датчик, которым ежеминутно выдаются показания температуры. Эти показания собираются приложением и отправляются в тему Kafka temperature_readings. В каждое сообщение включаются временна́я метка, идентификатор датчика и значение температуры:
{
"timestamp": "2024-10-12T10:00:00Z",
"sensor_id": "sensor_1",
"temperature": 25.5
}
Этап 2. Самоуправляемый кворум метаданных Kafka
Раньше координация кластеров, выбор лидера и поддержание метаданных осуществлялись в Kafka при помощи ZooKeeper, который ради более эффективного управления кластером Kafka заменен с 2021 года самоуправляемым кворумом метаданных. Его обычно называют режимом KRaft, и занимается он:
- Управлением всеми метаданными и задачами вроде выбора лидера, обеспечения высокой доступности и отказоустойчивости, не используя внешние сервисы наподобие ZooKeeper.
- Выбором лидера: для каждого раздела темы своим внутренним кворумом Kafka выбирается брокер-лидер, чтобы сообщение отправлялось отправителем лидеру раздела.
- Упрощением операций, повышением отказоустойчивости, масштабируемости и независимости от внешних сервисов.
Но в чем разница между ZooKeeper и Kraftmode?
В прежней архитектуре Kafka метаданные кластера, выборы лидеров и присвоения разделов управлялись внешними узлами ZooKeeper, который был внешним контролером, брокеры им координировались.
В новой архитектуре метаданные управляются теперь изнутри брокерами, один из которых — лидер кворума. Нет больше зависимости от ZooKeeper, оптимизируются операции Kafka, повышаются масштабируемость, отказоустойчивость и производительность.
Этап 3. Отправка сообщения в Kafka
Как только обнаруживается брокер-лидер раздела, отправителем этому брокеру отправляется сообщение. Затем сообщение записывается брокером в соответствующий раздел темы temperature_readings.
Механизм сохранения сообщения в разделе — журнально-структурированный подход, согласно которому оно просто добавляется в конец журнала. В Kafka, после того как сообщения записаны, они не перезаписываются и не изменяются. Новые сообщения добавляются одно за другим, поэтому появляются смещения. Каждому сообщению в разделе присваивается уникальное смещение, этот идентификатор для получателей. Смещение аналогично указателю на на местоположение сообщения в журнале:

Этап 4. Получение сообщения
Приложение-получатель, такое как конвейер обработки данных, подписывается на тему temperature_readings. Сообщения от брокера получаются и обрабатываются получателем, в Kafka используется модель получения по извлечении, согласно которой сообщения запрашиваются-извлекаются получателями в собственном темпе.
Как только получателем обрабатывается пакет сообщений, они им подтверждаются посредством фиксации смещений. Если получатель перезапускается, считывание возобновляется им с последнего зафиксированного смещения. Если сталкивается с ошибкой при обработке сообщения, благодаря имеющемуся в Kafka управлению смещениями повторяется с последнего известного смещения или же эти необработаные сообщения пропускаются, для чего реализуются очереди недоставленных сообщений.
Вкратце описав эти четыре этапа жизненного цикла сообщений Kafka, мы попробовали разобраться с тем, что происходит между отправкой сообщения и его получением.
Читайте также:
- Автомасштабирование по запаздыванию Kafka с KEDA
- Обработка дублированных сообщений в Kafka
- Получение одного события разными группами получателей в Kafka с Spring Boot
Читайте нас в Telegram, VK и Дзен
Перевод статьи Mohamed Osama Ayoup: Message LifeCycle in Kafka: What Happens After Producing a Message to Consume It





