
Когда я разрабатывал набор скриптов для взлома, у меня не было никаких знаний об используемых алгоритмах при обработке изображений. Только спустя какое-то время я занялся изучением этого.
Когда я начинал, я предполагал примерно следующее:
- Изображение представляет собой матрицу с пикселями, расположенных в отдельных ячейках
- Цветное изображение имеет значения красного, зеленого и синего цветов для каждого пикселя (RGB). А черно-белое изображение имеет одно значение, которое варьируется от 0 до 255
- Каждый символ в captca четко определен
Итак, вот как выглядит страничка входа на университетский сайт:
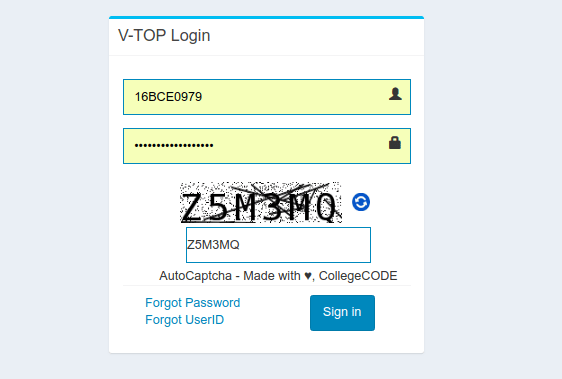
Начнем с моих замечаний по поводу самой картинки капчи (именно на этом сайте):

- Количество символов в капче всегда равно 6 и это изображение в градациях черного
- Расстояние между символами было везде одинаковым
- На изображении много рассеянных темных пикселей и линий, проходящих через символы на изображении
Затем я загрузил одно такое изображение с капчи и с помощью этого инструмента визуализировал изображение в двоичном формате (0 для черного и 1 для белого пикселя).

Мои предположения подтвердились! На изображении размером 45х180 каждому символу выделено по 30 пикселей, что делает их равномерно распределенными! Таким образом, первым моим шагом стало:
- Обрезать изображение капчи на 6 равномерных частей, по 30 пикселей в ширину каждая.
Я выбрал Python в качестве языка прототипирования, так как его библиотеки проще всего использовать и реализовывать. Затем я без труда нашел подходящую библиотеку — PIL. (прим. ред.: Python Imaging Library — библиотека языка Python, предназначенная для работы с растровой графикой). Я решил использовать модуль Image, поскольку моя операция ограничивалась только обрезкой и загрузкой изображения в виде матрицы.
Итак, согласно документации, синтаксис для обрезки изображения следующий:
from PIL import Image
image = Image.open("filename.xyz")
cropped_image = image.crop((left, upper, right, lower))В случае, если вы хотите обрезать только один символ:
from PIL import Image
image = Image.open("captcha.png").convert("L") # Grayscale conversion
cropped_image = image.crop((0, 0, 30, 45))
cropped_image.save("cropped_image.png")Изображение, которое будет получено в итоге:

Я написал простой скрипт и завернул все это дело в цикл, который извлекает 500 изображений captcha с сайта и сохраняет все обрезанные символы в папку.
Теперь переходим к моему третьему наблюдению — каждый символ четко определен. Чтобы «очистить» отрезанный символ (удалить ненужные строки и точки), я использовал следующий метод:
- Все пиксели в символе являются черными (0). Я использовал простую логику — если пиксель не совсем черный — он белый. Следовательно, для каждого пикселя, который имеет значение больше 0, я переназначил значение до 255 (сделал белым). Изображение преобразуется в матрицу 45×180 с использованием функции load(), а затем обрабатывается.
pixel_matrix = cropped_image.load()
for col in range(0, cropped_image.height):
for row in range(0, cropped_image.width):
if pixel_matrix[row, col] != 0:
pixel_matrix[row, col] = 255
image.save("thresholded_image.png")Для проверки моего метода, я применил код к оригинальному изображению:

И вот что получилось:
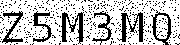
Как вы можете видеть, все пиксели, которые были не совсем черными, были удалены. Включая темные линии, которые проходят через все изображение. Только после того, как проект был завершен, я узнал, что вышеупомянутый метод называется порогом обработки изображений.
Теперь поговорим о следующем моем замечании,точнее о том, что на изображении много рассеянных темных пикселей и линий, проходящих через символы на изображении. Создадим специальный цикл, который будет проверять следующее: если соседний пиксель белый и пиксель, противоположный тому соседнему пикселю тоже белый, а центральный пиксель черный, то по условию цикла, центральный пиксель также станет белым!
for column in range(1, image.height - 1):
for row in range(1, image.width - 1):
if pixel_matrix[row, column] == 0 \
and pixel_matrix[row, column - 1] == 255 and pixel_matrix[row, column + 1] == 255 :
pixel_matrix[row, column] = 255
if pixel_matrix[row, column] == 0 \
and pixel_matrix[row - 1, column] == 255 and pixel_matrix[row + 1, column] == 255:
pixel_matrix[row, column] = 255Что получилось в итоге:
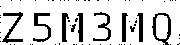
Итак, как вы видите, на изображении остались только необходимые нам символы! Хотя может показаться, что некоторые из символов потеряли несколько своих пискелей, тем не менее, они послужат отличной “базой” для их сравнения с другими изображениями. В конце концов, главная причина, по которой мы так оптимизируем изображение, состоит в том, чтобы создать наиболее точное изображения для каждого возможного символа капчи.
Я применил описанный выше цикл ко всем обрезанным символам и сохранил их в отдельной папке. Следующей задачей было назвать каждый символ из списка «ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789» и назначить ему соответствующее изображение. Когда я закончил, получился следующий “скелет”:

Я использовал несколько различных скриптов, для того чтобы отобрать наилучшие изображения среди всех изображений символов. Изображение, с наименьшим количеством темных пикселей наилучшим образом подходит для изображений нашего “скелета”. Таким образом, получилось два скрипта:
- Один для группировки изображений, отсортированных по символу (ограничения: нет темных пикселей и совпадений с уже имеющимися >= 90–95%)
- Второй для отбора лучшего изображения для каждого символа
Таким образом, у нас уже были созданы изображения библиотеки. Затем мы преобразовали их в пиксельные матрицы и сохранили в виде файла JSON.
И наконец, вот алгоритм, который решает/взламывает любое новое изображение captcha:
- Каждый символ в новом изображении captcha, я принудительно прогонял через изображения JSON, которые я сгенерировал. Сходство рассчитывается на основе расположения темных пикселей на изображении.
Сам алгоритм взлома был примерно следующим:
Например, если пиксель был черным и находился в условных позициях 4 и 8 на изображении капчи и в нашем изображении “скелета” находилось совпадение, то счет увеличивался на 1. Этот подсчет сравнения количества темных пикселей в изображении скелета используется для вычисления итогового совпадения в процентах.
Затем выбирается символ(изображение символа), который имеет наивысший процент совпадения:
import json characters = "123456789abcdefghijklmnpqrstuvwxyz" captcha = "" with open("bitmaps.json", "r") as f: bitmap = json.load(f)for j in range(image.width/6, image.width + 1, image.width/6): character_image = image.crop((j - 30, 12, j, 44)) character_matrix = character_image.load() matches = {} for char in characters: match = 0 black = 0 bitmap_matrix = bitmap[char] for y in range(0, 32): for x in range(0, 30): if character_matrix[x, y] == bitmap_matrix[y][x] and bitmap_matrix[y][x] == 0: match += 1 if bitmap_matrix[y][x] == 0: black += 1 perc = float(match) / float(black) matches.update({perc: char[0].upper()}) try: captcha += matches[max(matches.keys())] except ValueError: print("failed captcha") captcha += "0" print captcha
И конечным результатом будет:

Где капча с символами “Z5M3MQ” была успешна взломана!
На этом пожалуй все! Для меня это был отличный опыт, кроме того, я разработал специальное расширение для Chrome, которое использует мой алгоритм!
Весь мой код можете посмотреть здесь!
Хорошо знаете Python? Пройдите наш небольшой тест и проверьте свои знания!
Перевод статьи Priyansh Jain: How I developed a captcha cracker for my University’s website





