
Вы наверняка встречали файлы с расширением .tar, .zip или .gz . А знаете ли вы, чем они отличаются, почему мы их используем, и какой формат наиболее эффективен?
Различия между tar, .zip и .gz
Если вам некогда вникать в подробности, то вот краткое и понятное объяснение:
- .tar — архивный файл без сжатия
- .zip — (как правило) сжатый архивный файл
- .gz — файл (архивный или не архивный), который сжали с помощью gzip
История развития архивов
Эта история началась в далёких 70х, как и многое из того, что связано с Unix системой и ей подобными. Морозное январское утро 1979 года ознаменовалось появлением утилиты tar в составе дистрибутива Unix V7.
Утилита tar была разработана для эффективной записи большого количества файлов на магнитные ленты. Большинство современных пользователей Linux незнакомы с ленточными накопителями. Тем не менее, tar архивы (они же tarballs) до сих пор широко используются, когда нужно упаковать несколько файлов или даже древо каталога целиком (или целый «лес» 🙂 в один файл.
Главное, что нужно запомнить о tar файле ― что это просто архив, без сжатия. Другими словами, если вы архивируете 100 файлов по 50kb, то на выходе получите архив размером около 5000kb. Используя только tar, единственное на что можно рассчитывать это экономия пространства за счёт файловой системы. Например, файл длинной 1 байт использует 4kb дискового пространства, а 1000 таких файлов займёт уже 4Mb, а tar архив с этими файлами займёт всего 1Mb.
Стоит отметить, что tar не единственный стандартный инструмент Unix для создания архивов. Программисты вероятно знакомы с форматом ar, так как он используется для создания статических библиотек, которые являются по сути архивами скомпилированных файлов. Но ar позволяет создать архив из чего угодно. Например, пакеты .deb в системе Debian не что иное, как архивы ar. А пакеты mpkg в MacOS X — это cpio архивы, сжатые с помощью gzip. Но эти форматы не стали так популярны у пользователей, как tar. Вероятно, потому что использовать команды tar удобнее и проще.

Архивы — это хорошо, но с началом эры персональных компьютеров, люди поняли, что, сжимая данные можно существенно экономить память. Поэтому, спустя десять лет после появления tar, уже в мир MS-DOS, пришёл формат архива с возможностью сжатия — zip. Наиболее распространённый алгоритм сжатия в zip — это Deflate, который использует алгоритмы LZ77. Формат zip многие годы страдал от обременений патентами компании PKWARE.
В то же время был создан gzip, который также использовал алгоритм LZ77, но для бесплатного использования, не нарушая патент PKWARE.
Gzip создавался только для сжатия файлов, согласно ключевому понятию в философии Unix ― «Делай что-то одно, но делай это хорошо». Таким образом, чтобы создать сжатый архив ― сначала вам нужно создать архив, например с помощью утилиты tar, а после этого сжать его. Так получается файл .tar.gz (иногда сокращается до .tgz, из-за соблюдения давно забытых ограничений в имени файла MS-DOS).
По мере развития компьютерных наук создавались и другие алгоритмы, для более эффективного сжатия. Например реализация алгоритма Барроуза — Уилера в bzip2 (отсылка к .tar.bz2 архивам). Или более новый формат xz, в котором реализован алгоритм LZMA. Этот алгоритм используется в архиваторе 7zip.
Доступность и ограничения
Сегодня вы можете без проблем использовать любой формат архивных файлов как в Linux, так и в Windows.
Благодаря нативной поддержке формата zip в Windows, zip особенно актуален для кроссплатформенного применения. Порой, zip файл можно встретить в неожиданных местах. Например, этот формат использовала компания Sun для архивов JAR, в которых распространяется скомпилированное приложение Java. Файлы OpenDocument (.odf, .odp …) в офисных приложениях, на самом деле являются zip архивами. Если вам интересно, распакуйте один из них и посмотрите, что внутри:
sh$ unzip some-file.odt Archive:some-file.odt extracting: mimetype inflating: meta.xml inflating: settings.xml inflating: content.xm [...] inflating: styles.xml inflating: META-INF/manifest.xml
Несмотря на всё вышесказанное, в UNIX-мире я бы предпочёл использовать tar архивы, потому что формат zip недостаточно надёжно поддерживает все метаданные файловой системы Unix. Дело в том, что формат zip определяет лишь небольшой набор обязательных атрибутов файла для каждой записи: имя файла, дата изменения, право доступа. Кроме этих базовых атрибутов, архиватор может хранить и другие метаданные, в дополнительном поле заголовка zip. Но, поскольку дополнительное поле зависит от реализации, нет никаких гарантий, что вы получите тот же набор метаданных, даже в совместимых архиваторах. Давайте проверим это на примере:
sh$ ls -lsn data/team total 0 0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team
Central directory entry #5:
---------------------------
data/team
[...]
apparent file type: binary
Unix file attributes (100644 octal): -rw-r--r--
MS-DOS file attributes (00 hex): none
The central-directory extra field contains:
- A subfield with ID 0x5455 (universal time) and 5 data bytes.
The local extra field has UTC/GMT modification/access times.
- A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes:
01 04 e8 03 00 00 04 d0 07 00 00.
Как видите, в дополнительном поле хранится информация о владельце (UID/GID). Если вы умеете читать шестнадцатеричный код, то можно заметить, что в этом архиве используется порядок байтов little-endian(от младшего к старшему) для хранения метаданных. «e803» это «03e8», что означает «1000» ― UID файла. А «07d0» это «d007», что означает «2000» ― GID файла.
В этом конкретном случае инструмент info-ZIP, который я использую в системе Debian, сохранил некоторые полезные метаданные в дополнительном поле. Но это не значит, что любой архиватор запишет те же данные в дополнительном поле. И нет гарантий, что другой архиватор сможет прочитать эти данные.
Таким образом существует две причины, по которым до сих пор используют tarballs. Это либо просто старая привычка, либо те причины, о которых я говорил выше, когда zip не может полностью заменить tar. Особенно если для вас важно сохранить все стандартные метаданные файла.
Тест на эффективность: Tar vs Zip vs Gz
Здесь я сравниваю эффективность сжатия. Я учитываю только сэкономленное пространство, без учёта затраченного времени. Как правило, чем эффективней алгоритм сжатия, тем больше ресурсов ЦП он требует.
Чтобы сравнить эффективность алгоритмов, я использовал файлы в популярных форматах размером около 100Mb. В таблице результаты, которые я получил в системе Debian Stretch (все размеры я узнал командой du -sh):
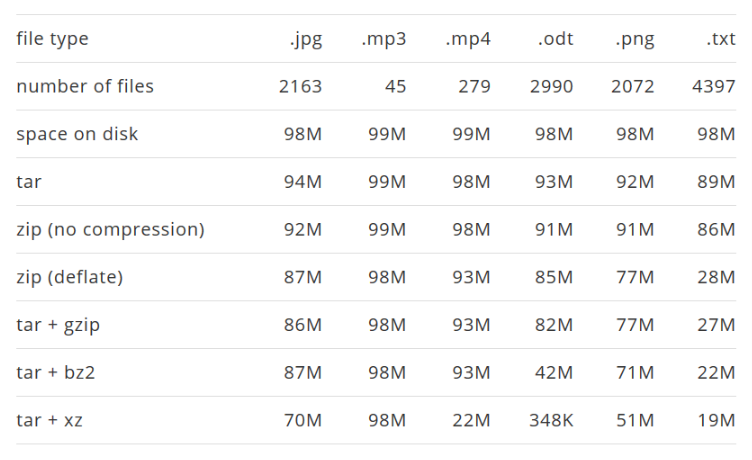
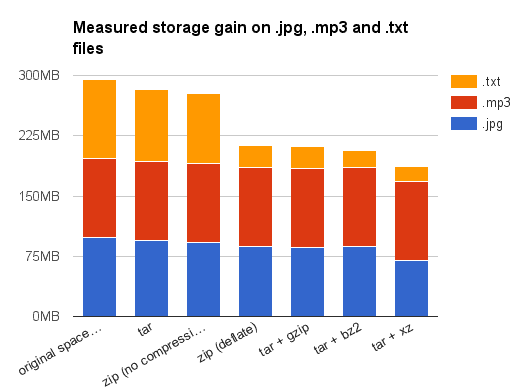
Во-первых, я призываю отнестись к этим результатам с осторожностью: все эти файлы были на моём жёстком диске, и я не утверждаю, что они являются эталоном для проведения тестов. Должен признаться, я не выбирал эти типы файлов случайным образом. Как уже упоминалось, файлы .odt сами по себе являются zip файлами. Поэтому результат их повторного сжатия был предсказуем (за исключением bzip2 и xz, я бы назвал это статистической аномалией, вызванной низкой неоднородностью моих файлов, содержащих несколько резервных копий или рабочих версий одних и тех же документов).
Что касается .jpg, .mp3 и .mp4 — это форматы, которые уже содержат сжатые данные. Более того, они используют деструктивное сжатие. Другими словами, вы не сможете полностью восстановить изображение после JPEG компрессии. Но вот что менее известно, так это то, что после фазы деструктивного сжатия, данные сжимаются во второй раз с использованием сжатия без потерь, для удаления избыточности данных, алгоритмом переменной длины слова Хаффмана.
Поэтому было предсказуемо, что сжатие JPEG, MP3/MP4 файлов не даст впечатляющих результатов. Обратите внимание, что обычный файл содержит, как сильно сжатые данные, так и не сжатые метаданные, поэтому мы можем ещё чего-то добиться. Это объясняет заметный результат для JPEG, так как их было много. Т.е. размер метаданных был существенным относительно общего размера файлов. Впечатляющие результаты показало сжатие MP4 с использованием xz. Вероятно, это связано с высоким сходством между файлами MP4, которые я использовал для тестов. Или нет?
Чтобы развеять сомнения, я рекомендую вам провести собственные тесты.
Перевод статьи Sylvain Leroux: Tar Vs Zip Vs Gz : Difference And Efficiency




