
Раздел «RTK Query» в руководстве «Redux Essentials» («Основные сведения о Redux») поистине феноменален. Однако, являясь частью обширного пакета документов, он, как мне кажется, может не получить должного внимания разработчиков.
Что такое Redux
Многие разработчики считают Redux библиотекой управления состояниями, которой она и является. Для них главная ценность Redux заключается в предоставлении доступа к состоянию (и возможности изменить его) из любой точки приложения. На мой взгляд, для решения этих задач нет смысла использовать что-то вроде Redux. Предлагаю взглянуть на проблему с другой стороны и сократить ее масштаб.
Все вы видели эту диаграмму (или что-то похожее):
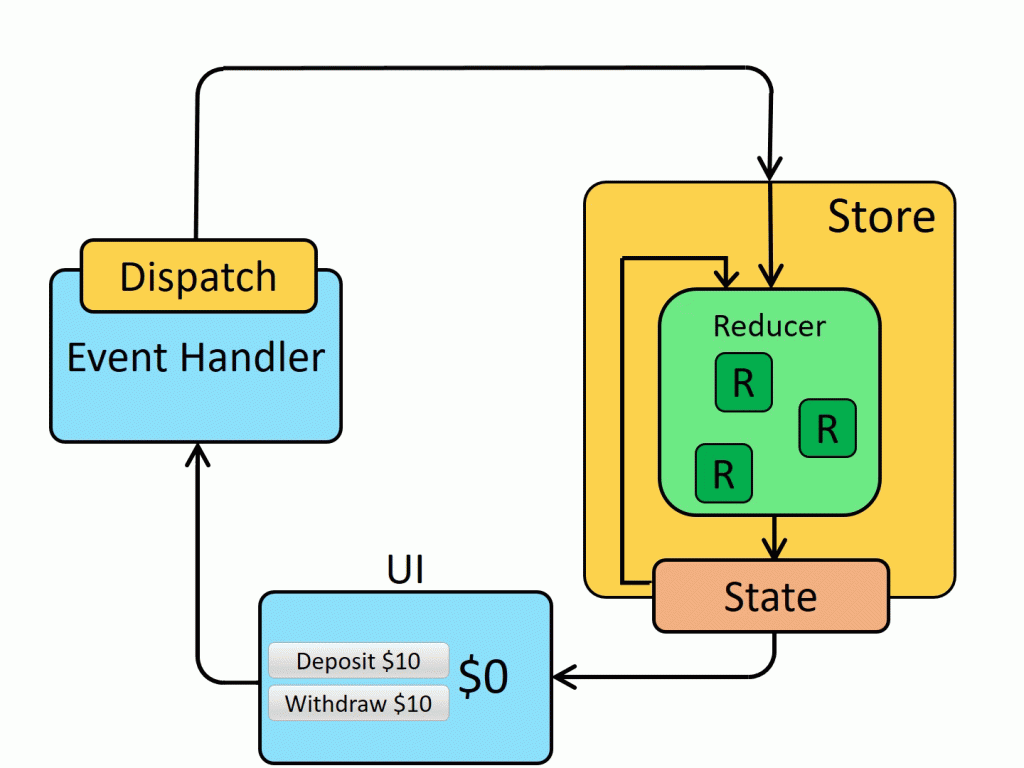
Как видите, в UI этой модели есть место для отображения текущего счета пользователя в магазине, а также кнопки, на которые он может нажать для внесения (deposit) или снятия (withdraw) денег. Как только одна из этих кнопок нажимается, происходит перемещение за пределы компонента, чтобы отправить действие, основанное на запросе пользователя. Обратите внимание: в данный момент состояние не изменяется. Когда действие поступает в хранилище (store), редьюсер (reducer) просматривает его и решает, что делать с запросом пользователя (и надо ли вообще что-то делать). Если редьюсер решит выполнить запрос пользователя, это изменение состояния будет передано в UI.
Что получаем в результате? Для начала представим, что у пользователя на счету 5 долларов, и он нажимает кнопку «Withdraw $10» («Снять 10 долларов»). Редьюсер может просто проигнорировать этот запрос, чтобы не создавать отрицательный баланс, или направить ошибку в часть состояния, которая контролируется компонентом toast. Помещение данной логики в UI-компонент не только усложнило бы его, но и означало бы, что изменения, не имеющие отношения к этому компоненту, должны быть произведены в этом компоненте.
В то же время, если эта логика понадобится в другом компоненте, возникнет проблема. Да, считается, что хуки решают ее, но поскольку обычные хуки так тесно переплетены с логикой View, зачастую во View заключено довольно много логики для взаимодействия с логикой в хуке. Поэтому на практике обычно невозможно использовать хук где-то еще без большого количества логики, повторяющейся в компонентах.
И чем больше состояний ошибки и других ситуаций нужно обработать, тем сложнее будут компоненты. Мало того, сосредоточение всей логики в компонентах означает, что большая часть состояния находится в данном компоненте и состояние будет потеряно при переходе пользователя в другое место.
Выделение отдельного места для хранения состояния и добавление обмена сообщениями между различными частями системы обеспечивают гибкость и устойчивость системы, что соответствует основам реактивности React.
Анатомия API-вызова в Redux
Ситуация усложняется, когда дело доходит до API-вызовов, потому что в оригинальном варианте Redux, как и в React, не было естественного места для асинхронной логики. К счастью, Redux предоставил механизм для добавления промежуточного ПО поверх него, чтобы реагировать на каждое действие другими способами, а не просто отправлять его через все редьюсеры и выводить новое состояние.
Самыми популярными промежуточными слоями для работы с подобными вещами были redux-sagas и redux-thunk. Замечу, что моим фаворитом стал sagas, а сам я начал серьезно относиться к Redux Toolkit, когда обнаружил, что разработчики, предпочитающие sagas, используют промежуточное ПО для слушателей (listener middleware). Короче говоря, я выяснил, что большая часть того, для чего я использовал sagas, более эргономично решается с помощью RTK Query. Но не буду забегать вперед.
На самом высоком уровне эти промежуточные слои позволяют задать серию шагов, которые нужно выполнить в ответ на одно отправленное действие, включая отправку других действий, которые изменят состояние, пока шаги продолжаются. Это может выглядеть примерно так:

На диаграмме все выглядит довольно просто, но код для используемой здесь логики может оказаться многословным и часто трудно тестируемым. Мало того, он обычно повторяется для каждого API-вызова. А в довершение придется еще написать набор селекторов, чтобы получить состояние загрузки, состояние ошибки и данные для каждого API-вызова. И это только для достаточно простого приложения.
Относительно распространенным шаблоном является master/detail. Он позволяет получить ровно столько данных о наборе «элементов» («things»), чтобы отобразить их список, а пользователям предоставить больше данных путем их детализации.
Пользователи могут совершать действия Click-in и Click-out по отношению к одним и тем же детализированным данным. Поэтому очевидный способ повысить производительность — кэшировать результат каждого детализированного вызова, а затем проверять его наличие, прежде чем получить его снова. Но это, опять же, добавляет сложности, так как необходимо выяснить, как хранить результат, как проверять его, а затем запускать API-вызов только в том случае, если его еще нет. Выполнение вызова будет асинхронным, в то время как простое возвращение уже имеющегося результата может быть выполнено синхронно.
Когда дело доходит до редактирования данных, все становится еще сложнее. Внезапно при редактировании потребуется обновить основной список или каким-то образом вызвать его перезагрузку.
Тут не успеешь оглянуться, как столкнешься с путаницей в коде, пытаясь понять, что делать, когда и как получить или обновить данные в нужное время. Если в команде несколько человек, ситуация может оказаться еще хуже, ведь у каждого из членов команды может быть свой способ решения каждой из этих проблем.
Вот пример из руководства Redux Essentials:
export const fetchPosts = createAsyncThunk('posts/fetchPosts', async () => {
const response = await client.get('/fakeApi/posts')
return response.data
});
const postsSlice = createSlice({
name: 'posts',
initialState,
// эти редьюсеры не относятся к thunk
reducers: {
reactionAdded(state, action) {
const { postId, reaction } = action.payload
const existingPost = state.posts.find((post) => post.id === postId)
if (existingPost) {
existingPost.reactions[reaction]++
}
},
postUpdated(state, action) {
const { id, title, content } = action.payload
const existingPost = state.posts.find((post) => post.id === id)
if (existingPost) {
existingPost.title = title
existingPost.content = content
}
},
},
// эти в основном обрабатывают состояние thunk
extraReducers(builder) {
builder
.addCase(fetchPosts.pending, (state, action) => {
state.status = 'loading'
})
.addCase(fetchPosts.fulfilled, (state, action) => {
state.status = 'succeeded'
// Добавьте любые полученные сообщения в массив
state.posts = state.posts.concat(action.payload)
})
.addCase(fetchPosts.rejected, (state, action) => {
state.status = 'failed'
state.error = action.error.message
})
},
});По сравнению с тем, что нам приходилось писать до появления Redux Toolkit, этот код довольно упрощен, но все равно его слишком много. Заметьте, это даже не обработка информации о кэшировании, которая у нас уже есть, — это просто выполнение одного API-вызова и отслеживание его статуса. И как только вы напишете весь этот код, придется дописать еще код, который позволит вам добраться до информации, хранящейся в состоянии.
export const selectAllPosts = (state) => state.posts.posts;
export const selectPostById = (state, postId) =>
state.posts.posts.find((post) => post.id === postId);К сожалению, многие разработчики перестают читать руководства, когда у них появляется достаточно способов для решения своей насущной проблемы. Поэтому многие так никогда и не узнают, насколько больше возможностей им доступно.
Использование RTK Query
Redux Toolkit Query, или RTK Query, как следует из названия, создан на основе Redux Toolkit (который здесь не будет подробно рассмотрен). В RTK Query логика API находится в специальном слайсе (API slice), предназначенном только для конечных API-точек. Существует два типа конечных точек: запросы (queries) и мутации (mutations). Запросы возвращают только одну или несколько записей, в то время как мутации создают, редактируют или каким-то образом обновляют данные, возможно, возвращая обновленное состояние.
Внутри этого слайса RTK Query создает «хэш» не только для каждой конечной точки, но и для каждой конечной точки и аргументов, с которыми она была вызвана. Это позволяет легко и дешево хранить результат только что выполненного запроса в течение некоторого времени на случай, если пользователь снова нажмет на эту информацию для ее детализации.
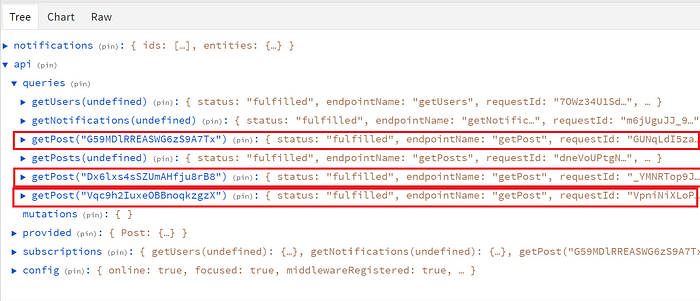
А состояние, содержащееся в каждой части хэша, содержит те части, для управления которыми раньше приходилось писать много логики:

Как видите, это состояние дает все то, чем ранее приходилось управлять через thunks. Предоставление этого по умолчанию в RTK Query избавляет от необходимости писать дополнительный код. О коде, который мы пишем, расскажу позже, но думаю, что вы с большей вероятностью попробуете новый подход, если сначала увидите его преимущества.
Хуки RTK Query
Я неоднократно высказывал свое мнение о React-хуках, но хуки RTK Query — сродни магии. Они автоматически генерируются из конечных точек приложения. Добавить их в компонент можно следующим образом:
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
} = useGetPostsQuery();Вот и все дела.
Мало того, при добавлении хука RTK Query в компонент, он автоматически создает подписку на запрос с аргументом, если таковой имеется (помните, результаты API-вызовов хранятся в состоянии Redux как комбинация endpoint + argument), а затем запускает API-вызов, отправляя действие «initiate». Он автоматически отслеживает состояние загрузки и автоматически возвращает данные в конце всего этого.
По мере того как пользователь просматривает различные части UI, которые запускают запросы с различными аргументами, эти запросы могут накапливаться в кэше. Но RTK Query позволяет установить тайм-аут либо глобально для всего API-слайса, либо для каждой конечной точки. В результате запросы, которые не отображаются на экране, будут удалены из кэша по истечении этого времени.
Хуки мутации возвращают метод, чтобы произвести изменение. Они также предоставляют небольшой пакет состояния, как это делают запросы, и обрабатывают кэширование.
const [updatePost, { isLoading, /* etc. */ }] = useEditPostMutation();В фоновом режиме можно соединить запросы и мутации таким образом, что при запуске мутации, приводящей к изменению результата запроса, запрос автоматически запустится снова, обновив свои результаты без дополнительного кода. Можно также напрямую обновлять кэшированные данные, но только в том случае, если повторный запуск всего запроса требует больших затрат.
Представляю код
После настройки API-слайса вам остается написать довольно простой код. Метод createApi принимает аргумент объекта конфигурации. Свойство этого объекта, которое чаще всего используется, — это свойство endpoint, которое задаем, предоставляя объект конфигурации функции builder. Звучит сложно, но может быть так же просто, как приведенный ниже код.
API-слайс с RTK Query
// Определяем объект API-слайса
export const apiSlice = createApi({
// Редьюсер кэша ожидает добавления в `state.api` (уже по умолчанию - это необязательно)
reducerPath: 'api',
// Все наши запросы будут иметь URL, начинающийся с '/fakeApi'.
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// endpoints представляют собой операции и запросы к данному серверу.
endpoints: builder => ({
// Конечная точка `getPosts` - это операция "запрос", которая возвращает данные
getPosts: builder.query({
// URL-адрес запроса - '/fakeApi/posts'.
query: () => '/posts'
})
})
});
// Экспорт автогенерируемого хука для конечной точки запроса `getPosts`.
export const { useGetPostsQuery } = apiSlice;Да, этот небольшой фрагмент кода в конечной точке getPosts выдает состояние получения/загрузки, состояние ошибки, если таковая имеется, и данные, возвращаемые из запроса. И все это связано в цепочку хуком useGetPostsQuery, который сгенерирован для вас!
Добавление мутации
Чтобы добавить мутацию, нужно добавить код в объект конфигурации endpoints, который выглядит следующим образом:
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
// Включите весь объект post в тело запроса
body: initialPost
})
});Это сгенерирует хук под названием useAddNewPostMutation.
Теги
Для связки мутации с запросом, чтобы выполнение мутации вызывало повторное выполнение запроса, добавляем, как показано ниже, следующие теги: tagTypes — в слайс, providesTags — в запрос, invalidatesTags — в мутацию:
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: ['Post']
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
});Интерпретация: при запуске любой мутации, содержащей массив invalidatesTags, включающий «Post», будет выполнен повторный запрос getPosts, и все компоненты, использующие этот хук, автоматически обновятся.
Это только начало
Сверхпростой код, приведенный выше, поможет вам далеко продвинуться. Но имейте в виду: RTK Query отлично справляется с более сложными случаями с помощью функций трансформации и дополнительных опций, таких как onQueryStarted, которые позволяют отслеживать запрос во время его выполнения на предмет различных проблем, а также настраивать кэшированные данные с помощью результатов мутации. Подробнее о возможностях RTK Query читайте в руководстве Redux Essentials.
Читайте также:
- Детальное исследование 3 подводных камней React, с которыми сталкиваются разработчики
- 9 оптимальных библиотек компонентов React на 2025 год
- Почему useMemo — не просто кэширование
Читайте нас в Telegram, VK и Дзен
Перевод статьи Amy Blankenship: Why I Use RTK Query for API Calls in React





