
Для тех, кто переходит из науки о данных в программную инженерию или инженерию данных, кривая обучения в этой новой сфере довольно крутая. Зато появляется возможность поработать с новыми инструментами, языками, фреймворками.
Одна из трудностей — быстро разрабатывать и тестировать различные технологии, понимать их взаимодействие. Сложны, например, проекты инженерии данных: для моделирования системы «от и до» здесь требуется много компонентов.
Продемонстрируем совместную работу технологий в небольшом проекте.
Проект
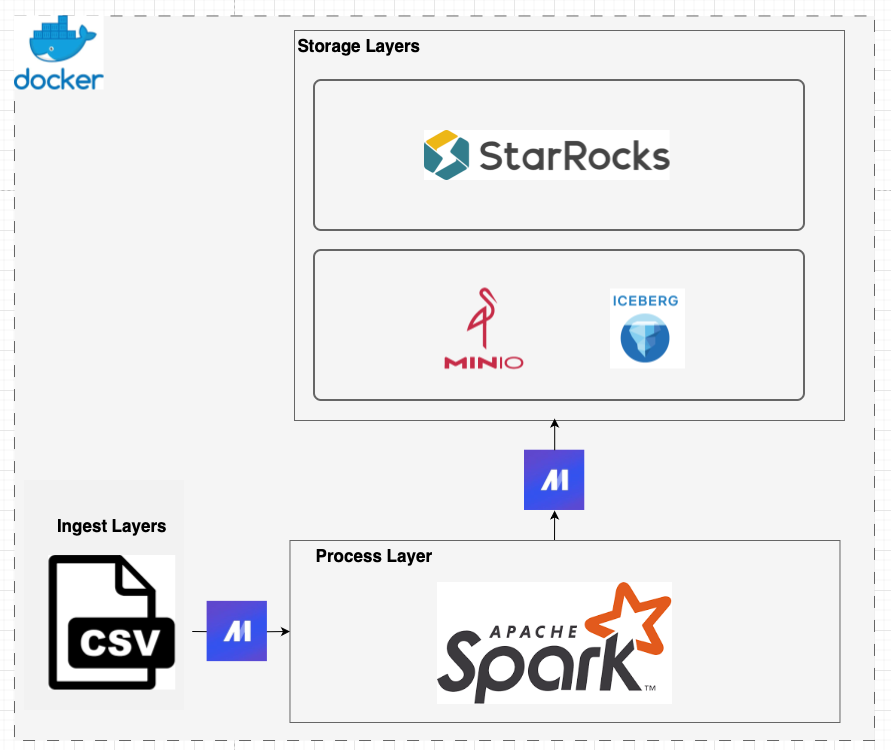
Цель проекта — создать систему, в которой данные извлекаются, преобразовываются, загружаются в локальное озеро данных и с помощью SQL-движка запрашиваются.
В озере данных сохраняются как реляционные данные бизнес-приложений, так и нереляционные данные из различных источников. В отличие от традиционных баз данных, этим озерам не требуется предопределенная схема, все данные сохраняются без предварительного проектирования. Такой гибкостью обусловлено разнообразие аналитики для получения ценной информации: SQL-запросы, аналитика больших данных и в режиме реального времени, полнотекстовый поиск, машинное обучение.
Воспользуемся такими технологиями/фреймворками:
- Docker — с ним сильно ускоряются сборка и тестирование приложений.
- Mage — отличный оркестратор конвейера данных для создания и запуска скриптов. Он не обязателен для проекта, но дата-инженеру необходимо освоить оркестрирование конвейеров.
- Spark — популярный унифицированный аналитический движок для крупномасштабной обработки данных, задействуем его в базовых преобразованиях.
- Minio — высокопроизводительное S3-совместимое хранилище объектов. В проекте это озеро данных, где будут храниться данные.
- Apache Iceberg и Delta Lake — форматы таблиц с усовершенствованным функционалом озер данных: эволюция схем, транзакции с соответствием ACID, переход во времени. В этих форматах повышены надежность данных, производительность запросов, масштабируемость, а значит, и эффективность озер данных для крупномасштабной аналитики. В проекте задействуем Iceberg.
- StarRocks — высокопроизводительная аналитическая база данных, которой поддерживается пакетный прием данных из разных источников в режиме реального времени. Благодаря ей, сохраняемые в озерах данные анализируются напрямую с нулевой миграцией данных. С помощью StarRocks в проекте запрашиваются данные из озера данных.
Этими технологиями и фреймворками закладывается прочная основа для озера данных. Технологии применяются разные, но основные принципы любого проекта инженерии данных одни и те же.
Настройка служб
Создадим репозиторий проекта вокруг Mage — оркестратора и объединителя служб. Воспользуемся его простотой и интуитивным подходом к построению надежных и масштабируемых конвейеров данных.
Сначала создаем пустой репозиторий и добавляем эти файлы/папки:
.env;Makefile;Dockerfile;docker-compose.yaml.
В файле .env сохранятся учетные данные для служб Minio, их всего две:
MINIO_ACCESS_KEY= choose_a_key
MINIO_SECRET_KEY= choose_a_secret
Чтобы упростить рабочий процесс и не запоминать Docker- и другие сложные команды, а каждый раз с легкостью вызывать их, добавляем этот Makefile:
# Название образа для контейнера Docker
IMAGE_NAME = mage_demo
# Название файла Docker Compose
COMPOSE_FILE = docker-compose.yaml
# Создаем образ Docker
build:
docker build -t $(IMAGE_NAME) .
# Запускаем контейнеры в фоновом режиме
up:
docker-compose -f $(COMPOSE_FILE) up -d
# Останавливаем контейнеры
down:
docker-compose -f $(COMPOSE_FILE) down
# Открываем браузер
browse:
open http://localhost:6789
# Создаем новый проект
create:
docker run -it -p 6789:6789 -v path/to/your/project:/home/src mageai/mageai \
/app/run_app.sh mage start $(IMAGE_NAME)
Проект Mage, в котором запустятся конвейеры, создадим с помощью Dockerfile — предоставляемого в Mage — со Spark-командами, при желании применять Mage без Spark их легко удалить:
FROM mageai/mageai:0.9.72
ARG PROJECT_NAME=mage_demo #можно указать свое название
ARG MAGE_CODE_PATH=/home/mage_code
ARG USER_CODE_PATH=${MAGE_CODE_PATH}/${PROJECT_NAME}
WORKDIR ${MAGE_CODE_PATH}
COPY ${PROJECT_NAME} ${PROJECT_NAME}
ENV USER_CODE_PATH=${USER_CODE_PATH}
# Spark-команда
RUN echo 'deb http://deb.debian.org/debian bullseye main' > /etc/apt/sources.list.d/bullseye.list
#Spark-команды
# Устанавливаем «OpenJDK 11» и «wget»
RUN apt-get update -y && \
apt-get install -y openjdk-11-jdk wget
# Spark-команда
# Удаляем репозиторий «Debian Bullseye»
RUN rm /etc/apt/sources.list.d/bullseye.list
# Устанавливаем пользовательские библиотеки Python
RUN pip3 install -r ${USER_CODE_PATH}/requirements.txt
RUN python3 /app/install_other_dependencies.py --path ${USER_CODE_PATH}
ENV PYTHONPATH="${PYTHONPATH}:/home/src"
CMD ["/bin/sh", "-c", "/app/run_app.sh"]
В проекте появится автономный кластер Spark под управлением Mage, так что создавать отдельный образ Spark не понадобится, хотя можно сделать и это.
Создаем проект, поменяв путь к нему в Makefile и введя в интерфейсе командной строки такую команду:
make create
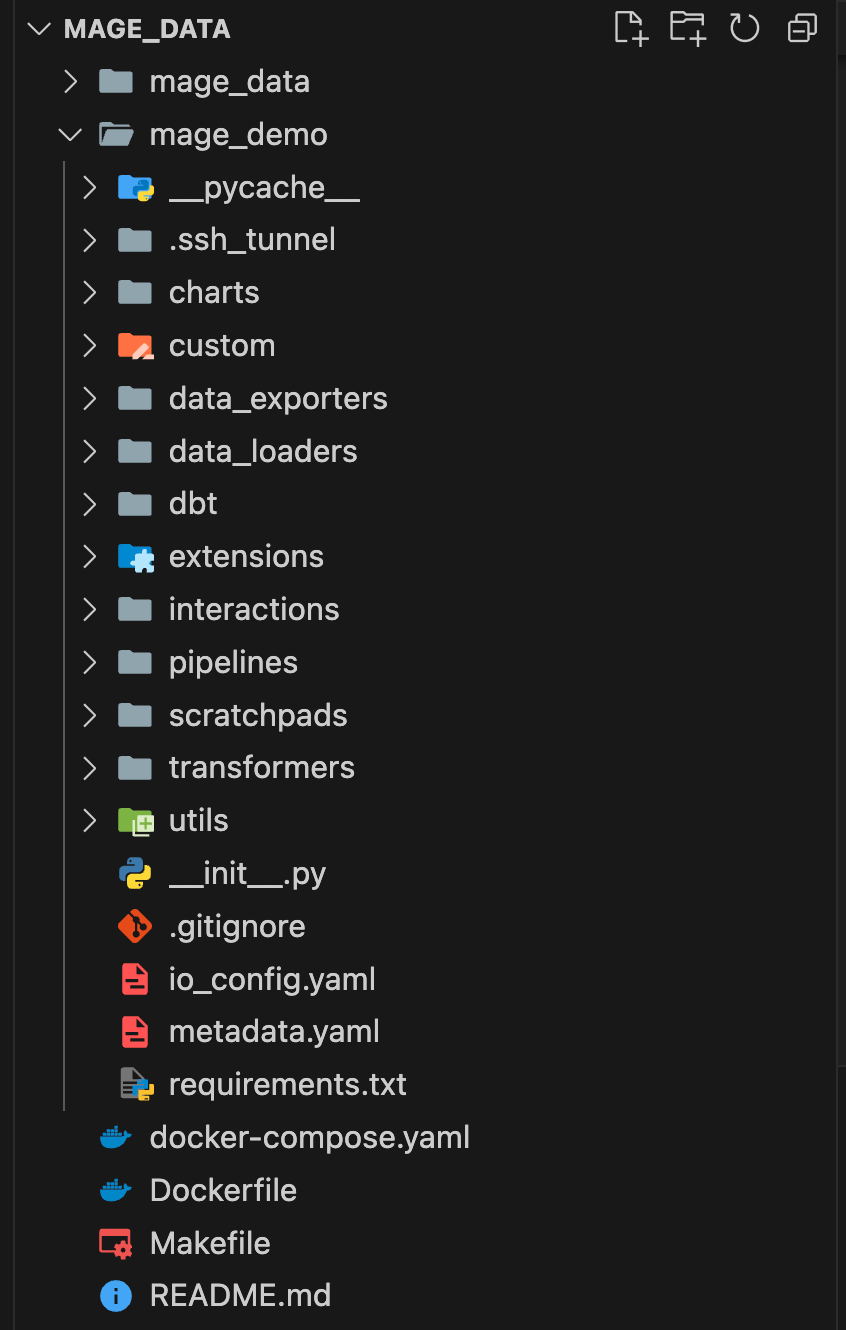
Mage настроен, а так должен теперь выглядеть репозиторий:
Заглянем также в пользовательский интерфейс:
make browse
Сейчас проект пуст и создан из образа mageai/mageai:latest. Начав добавлять конвейеры, настраивать требования и включать кластер Spark, создадим собственный образ:
make build
Собираем все вместе
Чтобы технологии проекта беспроблемно запускались все вместе в одной сети, создаем файл docker-compose.yaml, добавляемый в репозиторий последним:
version: '3'
services:
mage:
# Название образа в Makefile
image: mage_demo
container_name: mage
ports:
- "6789:6789"
volumes:
- .:/home/mage_code
environment:
MINIO_ACCESS_KEY: ${MINIO_ACCESS_KEY}
MINIO_SECRET_KEY: ${MINIO_SECRET_KEY}
starrocks-fe-0:
image: starrocks/fe-ubuntu:latest
hostname: starrocks-fe-0
container_name: starrocks-fe-0
command:
- /bin/bash
- -c
- |
/opt/starrocks/fe_entrypoint.sh starrocks-fe-0
environment:
- HOST_TYPE=FQDN
- TZ=Asia/Shanghai
- AWS_ACCESS_KEY_ID=${MINIO_ACCESS_KEY}
- AWS_SECRET_ACCESS_KEY=${MINIO_SECRET_KEY}
ports:
- "8030:8030"
- "9020:9020"
- "9030:9030"
volumes:
- singleton_fe0_data:/opt/starrocks/fe/meta
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9030"]
interval: 5s
timeout: 5s
retries: 30
starrocks-be-0:
image: starrocks/be-ubuntu:latest
hostname: starrocks-be-0
container_name: starrocks-be-0
command:
- /bin/bash
- -c
- |
/opt/starrocks/be_entrypoint.sh starrocks-fe-0
environment:
- HOST_TYPE=FQDN
- TZ=Asia/Shanghai
ports:
- "8040:8040"
depends_on:
- starrocks-fe-0
volumes:
- singleton_be0_data:/opt/starrocks/be/storage
minio:
container_name: minio
image: quay.io/minio/minio
ports:
- '9000:9000'
- '9001:9001'
volumes:
- './minio_data:/data'
environment:
- MINIO_ROOT_USER=${MINIO_ACCESS_KEY}
- MINIO_ROOT_PASSWORD=${MINIO_SECRET_KEY}
command: server --console-address ":9001" /data
volumes:
singleton_fe0_data:
singleton_be0_data:
minio_data:
Здесь содержатся все технологии для этой демоверсии. Кроме Spark, потому что задействуется автономный кластер. Для учетных данных MinIO создается файл .env — это всегда рекомендуется — либо они жестко задаются в файле YAML.
Затем все службы запускаются вместе:
make up
Открыв Docker Desktop или запустив в командной строке docker ps, увидим все контейнеры:
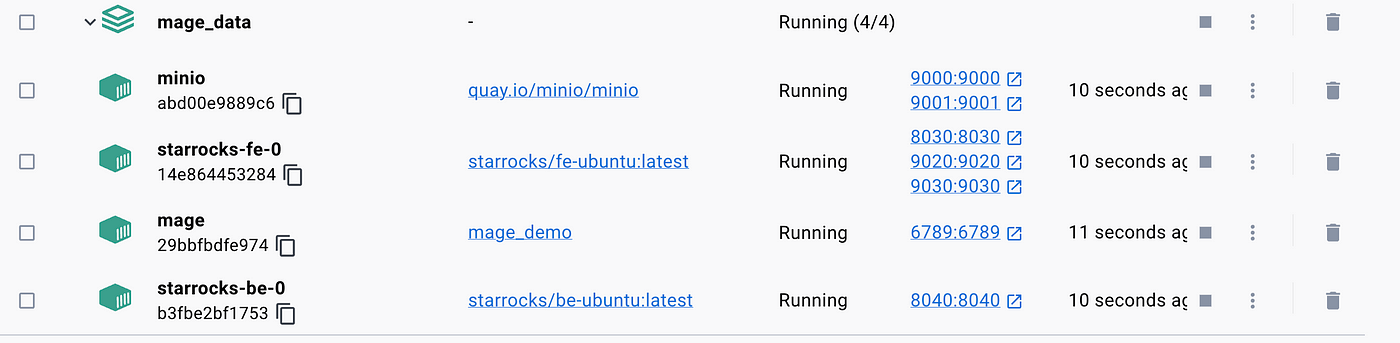
Образ для Mage создали мы, его название должно совпадать с указанным в Makefile: это название, данное образу в службе Mage.
Теперь проверим, все ли запускается корректно. Переходим на localhost:9001, это MinIO:

Вводим учетные данные, указанные в файле .env либо жестко заданные в YAML-файле, и оказываемся здесь:
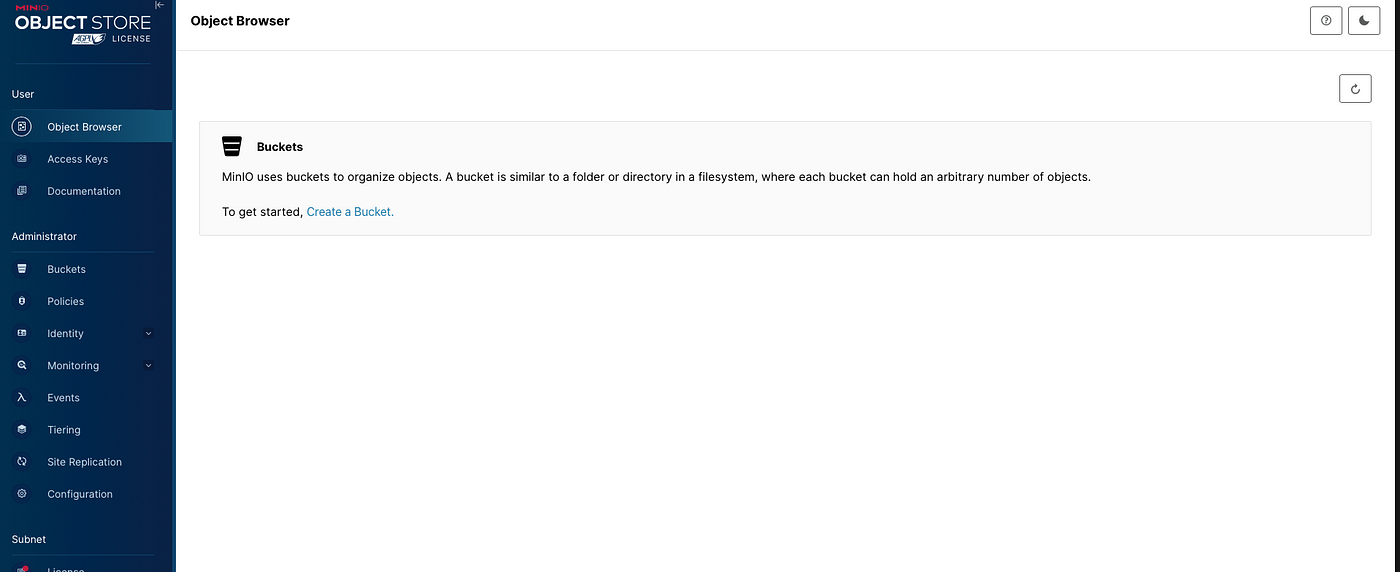
С хранилищем Minio все нормально.
Теперь незаменимым инструментом баз данных установим соединение для StarRocks:
- Выбираем новое подключение базы данных.
- Выбираем MySQL, плагин StarRocks тоже может быть доступен.
- Вводим хост
localhost, порт9030, имя пользователяroot. - Тестируем подключение:
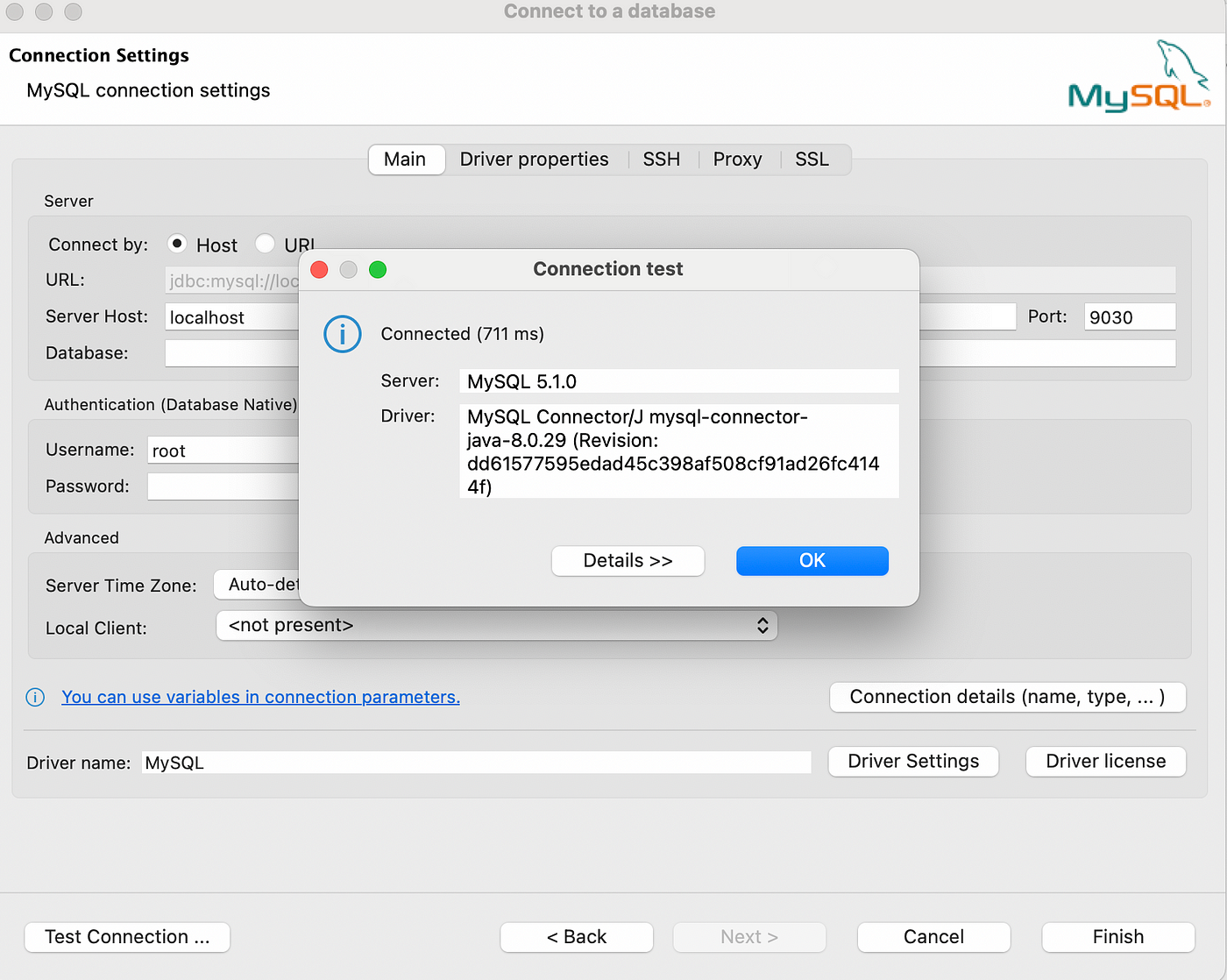
Нажимаем ОК, затем Finish. Вот и все. Соединение настроится, название mage_demo сменится на localhost.
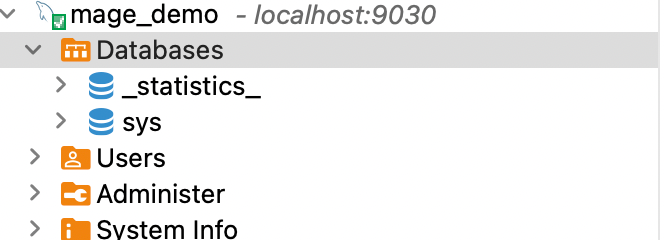
Все службы готовы, за исключением последней… Spark.
Самое сложное теперь — найти необходимые jar-файлы для S3, Iceberg и Delta. После продолжительных поисков путем проб и ошибок в .gitignore внутри каталога mage_demo создана папка spark-config с необходимыми jar-файлами:

Добавляем эти jar-файлы в раздел spark_config проектного файла metadata.yaml вместе с такой конфигурацией:
spark_config:
# Название приложения
app_name: 'MageSparkSession'
# Ведущий URL-адрес подключения,
# например spark_master «spark://host:port» или spark_master «yarn»
spark_master: "local"
# Переменные среды́ исполнителя,
# например executor_env: «{'PYTHONPATH': '/home/path'}»
executor_env: {}
# Jar-файлы, подгружаемые в кластер и добавляемые в «classpath»,
# например spark_jars: «['/home/path/example1.jar']»
spark_jars: [
#delta
'/home/mage_code/mage_demo/spark-config/hadoop-aws-3.3.4.jar',
'/home/mage_code/mage_demo/spark-config/aws-java-sdk-bundle-1.12.262.jar',
'/home/mage_code/mage_demo/spark-config/delta-storage-2.4.0.jar',
'/home/mage_code/mage_demo/spark-config/delta-core_2.12-2.4.0.jar',
#iceberg
'/home/mage_code/mage_demo/spark-config/bundle-2.26.15.jar',
'/home/mage_code/mage_demo/spark-config/url-connection-client-2.26.15.jar',
'/home/mage_code/mage_demo/spark-config/iceberg-spark-runtime-3.5_2.12-1.5.2.jar',]
# Путь, по которому Spark устанавливается на рабочих узлах,
# например spark_home: «/usr/lib/spark»
spark_home:
# Список задаваемых в «SparkConf» пар «ключ-значение»,
# например others: {«spark.executor.memory»: «4g»,«spark.executor.cores»: «2»}
others: {}
Поскольку задействуется автономный кластер Spark, воспользуемся локальным spark-master. Если бы применялся, например, образ Bitnami Spark, настроили бы spark-master на spark://spark:7077 или соответствующий адрес.
После конфигурирования всех служб — при запуске проекта это обычно самая трудоемкая часть — построим конвейеры и продемонстрируем совместную работу всех компонентов.
Создаем конвейеры
Завершив все предыдущие этапы, продолжим добавлением в файл requirements.txt таких пакетов:
pyspark==3.4.0
minio
delta-spark==2.4.0 #если используете delta
Затем собираем образ Mage:
make build
И поднимаем контейнеры:
make up
Наконец, открываем пользовательский интерфейс Mage для параллельной работы с IDE:
make browse
Сконфигурируем сеанс Spark и добавим в фабрику, сделав его применяемым для других сеансов, таких как Delta. С этой spark_session_factory легко переключаться между конфигурациями, а сеансы становятся доступными из всех конвейеров — их не нужно создавать каждый раз заново.
SparkSession — это единая точка входа приложений Spark для подключения ко всему основному функционалу: RDD, DataFrame и Dataset. Ею обеспечивается согласованный интерфейс обработки структурированных данных. Это один из первых объектов, создаваемых при разработке приложения Spark SQL.
Продемонстрируем этот процесс только для Iceberg, хотя фабричная концепция при необходимости распространяется и на другие сеансы:
from pyspark.sql import SparkSession
from abc import ABC, abstractmethod
from delta import configure_spark_with_delta_pip
class SparkSessionFactory(ABC):
@abstractmethod
def create_spark_session(self):
pass
@abstractmethod
def configure_s3(self):
pass
class IcebergSparkSession:
def __init__(self, app_name, warehouse_path, s3_endpoint, s3_access_key, s3_secret_key):
self.app_name = app_name
self.warehouse_path = warehouse_path
self.s3_endpoint = s3_endpoint
self.s3_access_key = s3_access_key
self.s3_secret_key = s3_secret_key
self.spark = self.create_spark_session()
self.configure_s3()
def create_spark_session(self):
packages = [
"hadoop-aws-3.3.4",
'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12-1.5.2',
'aws-java-sdk-bundle-1.12.262'
]
builder = SparkSession.builder.appName(self.app_name) \
.config("spark.jars.packages", ",".join(packages)) \
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \
.config("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.local", "org.apache.iceberg.spark.SparkCatalog") \
.config("spark.sql.catalog.local.type", "hadoop") \
.config("spark.sql.catalog.local.warehouse", self.warehouse_path)
return builder.getOrCreate()
def configure_s3(self):
sc = self.spark.sparkContext
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", self.s3_access_key)
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", self.s3_secret_key)
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", self.s3_endpoint)
sc._jsc.hadoopConfiguration().set("fs.s3a.path.style.access", "true")
sc._jsc.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "false")
sc._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
# Бонусный сеанс... Delta
class DeltaSparkSession(SparkSessionFactory):
def __init__(self, app_name, s3_endpoint, s3_access_key, s3_secret_key):
self.app_name = app_name
self.s3_endpoint = s3_endpoint
self.s3_access_key = s3_access_key
self.s3_secret_key = s3_secret_key
self.spark = self.create_spark_session()
self.configure_s3()
def create_spark_session(self):
extra_packages = [
"org.apache.hadoop:hadoop-aws:3.3.4",
"io.delta:delta-core_2.12:2.4.0",
"aws-java-sdk-bundle-1.12.262",
'delta-storage-2.4.0'
]
builder = SparkSession.builder.appName(self.app_name) \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
return configure_spark_with_delta_pip(builder, extra_packages=extra_packages).getOrCreate()
def configure_s3(self):
sc = self.spark.sparkContext
sc._jsc.hadoopConfiguration().set("fs.s3a.access.key", self.s3_access_key)
sc._jsc.hadoopConfiguration().set("fs.s3a.secret.key", self.s3_secret_key)
sc._jsc.hadoopConfiguration().set("fs.s3a.endpoint", self.s3_endpoint)
sc._jsc.hadoopConfiguration().set("fs.s3a.path.style.access", "true")
sc._jsc.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "false")
sc._jsc.hadoopConfiguration().set("fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
def get_spark_session(session_type, **kwargs):
if session_type == "iceberg":
return IcebergSparkSession(**kwargs)
elif session_type == "delta":
return DeltaSparkSession(**kwargs)
else:
raise ValueError("Invalid session type")
Создадим первый конвейер. Самое важное сейчас — это данные. Скачиваем случайные данные, например, отсюда и сохраняем в файле проектного каталога. Обязательно добавляем этот файл в .gitignore.
В Mage очень легко создать конвейер. В пользовательском интерфейсе нажимаем New Pipeline («Новый конвейер»), из выпадающего меню выбираем Standard Batch («Стандартный, пакетный») и оказываемся в интерфейсе разработки конвейера:
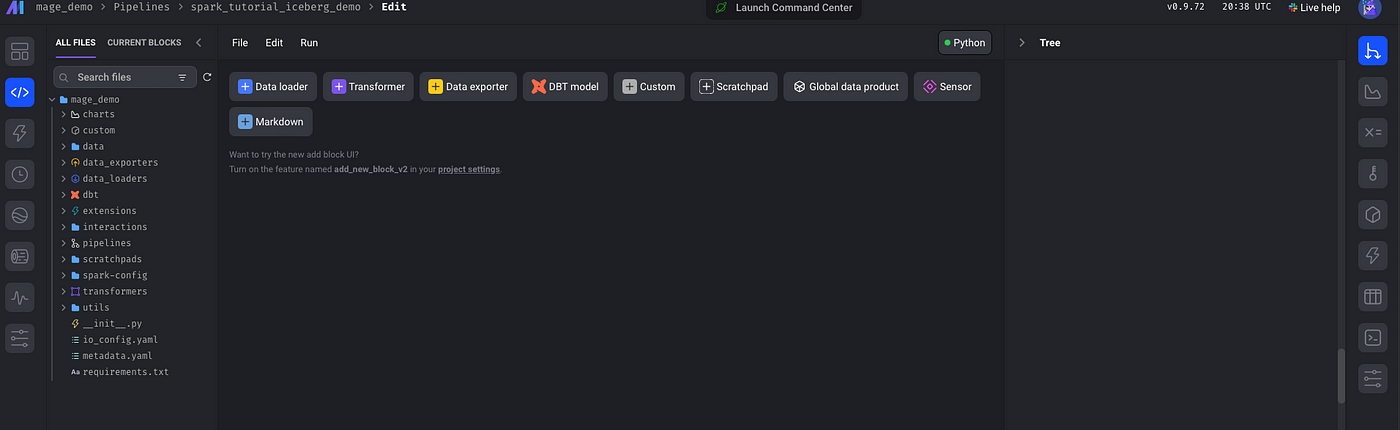
Классический ETL-процесс обычно начинается с загрузчика данных, продолжается преобразователем, а затем экспортером данных. Но, поскольку проект демонстрационный, начнем с добавления пользовательского блока, где с помощью формата Apache Iceberg запишем данные в корзину S3:
from minio import Minio
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
import os
from mage_demo.utils.spark_session_factory import get_spark_session
# Функция для остановки любого имеющегося сеанса Spark
def stop_existing_spark_session():
try:
existing_spark = SparkSession.builder.getOrCreate()
if existing_spark:
existing_spark.stop()
except Exception as e:
print(f"No existing Spark session to stop: {e}")
stop_existing_spark_session()
MINIO_ACCESS_KEY = os.environ.get('MINIO_ACCESS_KEY')
MINIO_SECRET_KEY = os.environ.get('MINIO_SECRET_KEY')
iceberg_spark_session = get_spark_session(
"iceberg",
app_name="MageSparkSession",
warehouse_path="s3a://iceberg-demo-bucket/warehouse",
s3_endpoint="http://minio:9000",
s3_access_key=MINIO_ACCESS_KEY,
s3_secret_key=MINIO_SECRET_KEY
)
client = Minio(
"minio:9000",
access_key=MINIO_ACCESS_KEY,
secret_key=MINIO_SECRET_KEY,
secure=False
)
minio_bucket = "iceberg-demo-bucket"
found = client.bucket_exists(minio_bucket)
if not found:
client.make_bucket(minio_bucket)
@custom
def iceberg_table_write(*args, **kwargs):
data_folder = "mage_demo/data" # Меняем этот путь согласно структуре каталогов
for filename in os.listdir(data_folder):
if filename.endswith(".csv"):
file_path = os.path.join(data_folder, filename)
# Считываем CSV-файл в DataFrame Spark
df = iceberg_spark_session.spark.read.csv(file_path, header=True, inferSchema=True)
# Записываем в Minio с помощью Iceberg
table_name = f"local.iceberg_demo.{os.path.splitext(os.path.basename(file_path))[0]}"
if table_name.split('.')[-1] == 'listings':
print('process listings')
split_cols = F.split(df['name'], '·')
is_review_present = F.trim(split_cols.getItem(1)).startswith('★')
# Извлекаем, очищаем и присваиваем новые столбцы
df = df.withColumn('description', F.trim(split_cols.getItem(0))) \
.withColumn('reviews', F.when(is_review_present, F.trim(F.regexp_replace(split_cols.getItem(1), '★', ''))).otherwise(None)) \
.withColumn('bedrooms', F.when(is_review_present, F.trim(split_cols.getItem(2))).otherwise(F.trim(split_cols.getItem(1)))) \
.withColumn('beds', F.when(is_review_present, F.trim(split_cols.getItem(3))).otherwise(F.trim(split_cols.getItem(2)))) \
.withColumn('baths', F.when(is_review_present, F.trim(split_cols.getItem(4))).otherwise(F.trim(split_cols.getItem(3))))
df = df.drop('name', 'neighbourhood_group', 'license')
df.writeTo(table_name) \
.createOrReplace()
return "Iceberg tables created successfully"
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Скрипт выполняется из пользовательского интерфейса — в сценариях посложнее запускается на регулярной основе настраиваемыми триггерами — в течение пары минут и в первый раз сопровождается предупреждениями, вероятно, из-за автономного кластера Mage:
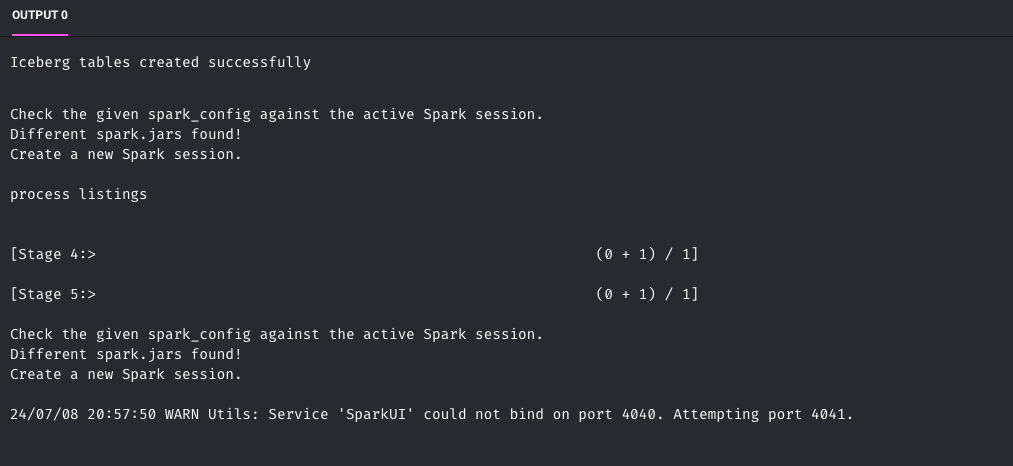
По завершении блока проверяем, вставлены ли данные в MinIO, должна появиться корзина со всеми данными и метаданными:
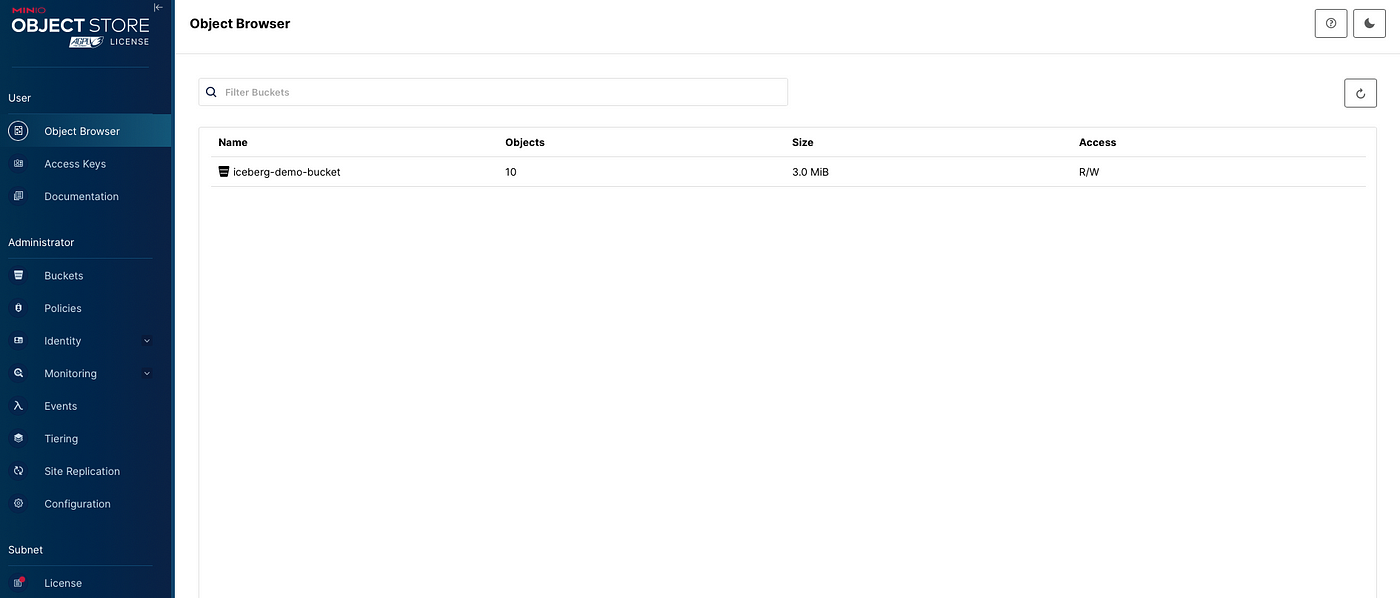
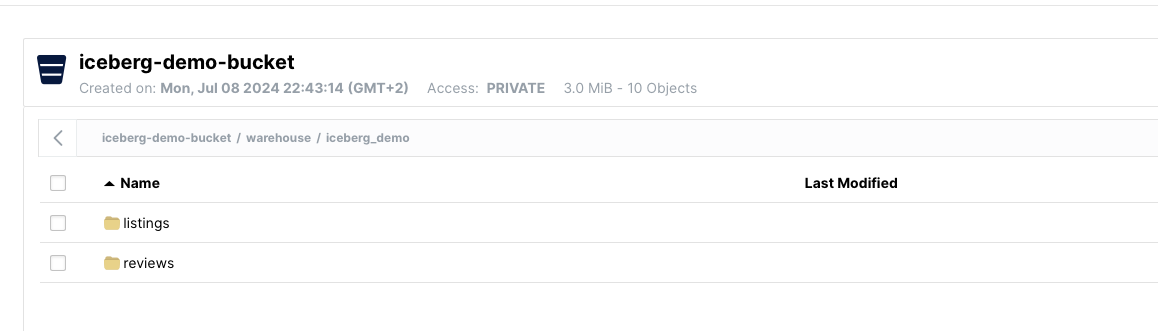
С Mage создаются и конвейеры посложнее с промежуточными этапами.
Чтобы считать данные в Mage Python-скриптом, создается другой пользовательский блок или блок преобразования и добавляется такой код:
from mage_demo.utils.spark_session_factory import get_spark_session
import os
MINIO_ACCESS_KEY = os.environ.get('MINIO_ACCESS_KEY')
MINIO_SECRET_KEY = os.environ.get('MINIO_SECRET_KEY')
# Инициализируем сеанс Spark и клиент MinIO
iceberg_spark_session = get_spark_session(
"iceberg",
app_name="MageSparkSession",
warehouse_path="s3a://iceberg-demo-bucket/warehouse",
s3_endpoint="http://minio:9000",
s3_access_key=MINIO_ACCESS_KEY,
s3_secret_key=MINIO_SECRET_KEY
)
@custom
def iceberg_table_read(*args, **kwargs):
"""
Read data from a MinIO bucket using either Iceberg .
"""
# Создаем полный путь к таблице в корзине MinIO
table_name = "local.iceberg_demo.listings"
# Считываем таблицу в DataFrame Spark
df = iceberg_spark_session.spark.table(table_name)
# TODO: Сюда добавляются дальнейшие очистка и обработка
return df
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Если скрипт выполнится, отобразится DataFrame:
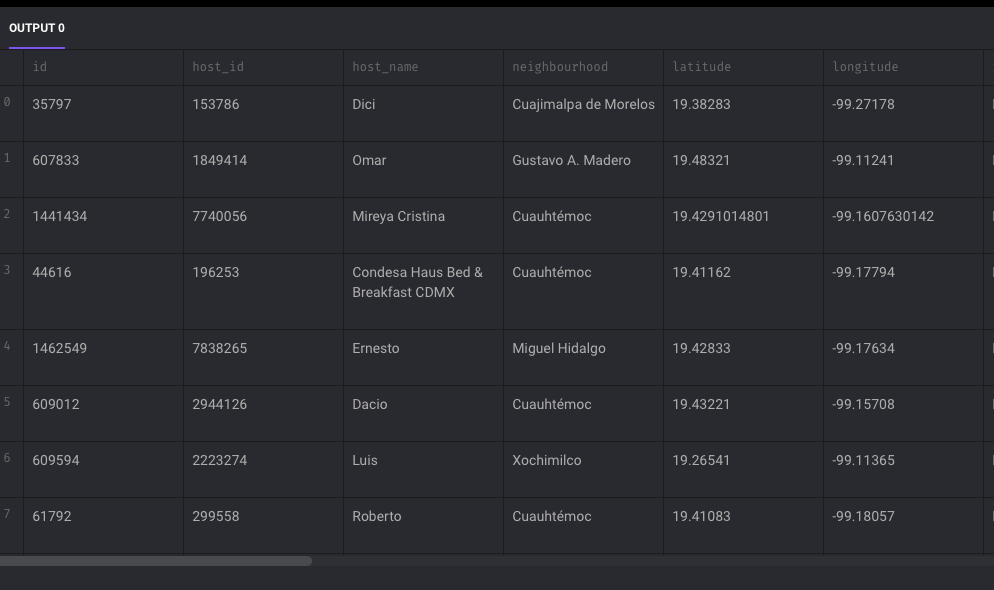
Но не гибче ли запрашивать данные с помощью SQL в SQL-движке? Будучи надежным и быстрым хранилищем данных, StarRocks используется и для этого.
С помощью SQL данные запрашиваются в StarRocks так:
- Создается каталог, это первый этап настройки среды для запрашивания данных:
CREATE EXTERNAL CATALOG iceberg_catalog
PROPERTIES (
"type"="iceberg",
"iceberg.catalog.type"="hadoop",
"iceberg.catalog.warehouse"="s3a://iceberg-demo-bucket/warehouse",-- то же, что в конфигурации Spark-config
"aws.s3.endpoint"="http://minio:9000",
"aws.s3.access_key"="your access key",
"aws.s3.secret_key"="your secret key",
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true"
);
Проверяем, что каталог создан:
SHOW CATALOGS;

2. Каталог Iceberg задается и указывается в текущем сеансе:
SET CATALOG iceberg_catalog;
Просматриваем базы данных в каталоге:
SHOW DATABASES FROM iceberg_catalog;

Искомая база данных — iceberg_demo, та же обозначена на изображении MinIO выше.
3. С помощью USE указывается активная база данных, у нас это iceberg_demo:
USE iceberg_demo;
Теперь видим таблицы, те же, что в MinIO:
SHOW tables;
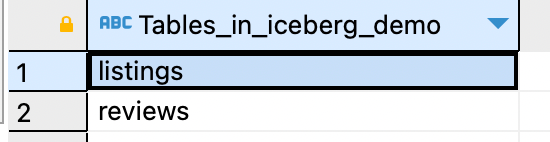
Таблицы на месте, теперь начнем изучать данные гибче, чем в скрипте Python.
Например, выполним проверку районов с наибольшим числом 5-звездочных обзоров:
SELECT
neighbourhood,
count(*) as no_reviews
FROM listings
WHERE reviews ='5.0'
GROUP BY 1
ORDER BY COUNT(*) DESC
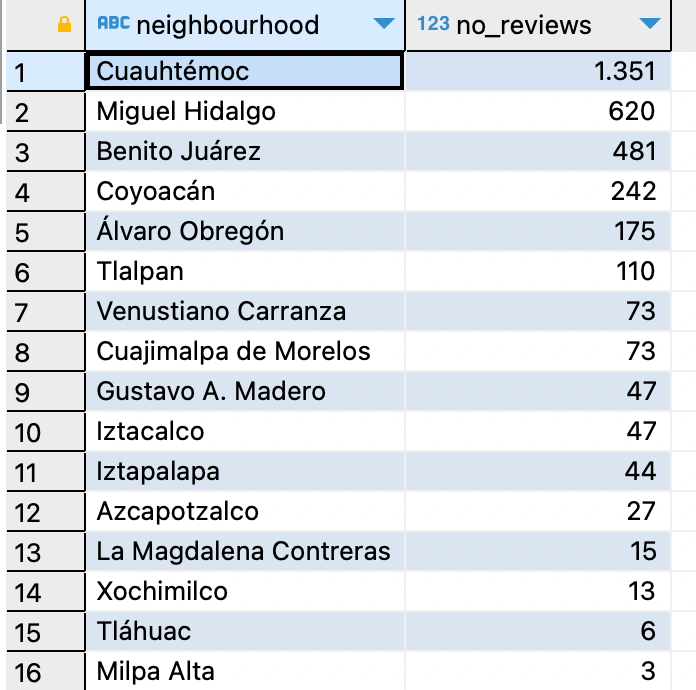
Так получилось локальное озеро данных со всеми основными компонентами, необходимыми для проекта инженерии данных. Что касается озера Delta, процесс аналогичен, отличается преобразованиями. Подробнее — в репозитории. Для интеграций со StarRocks она чуть сложнее, чем Iceberg. Подробнее — в официальной документации.
Заключение
При создании проекта инженерии данных, прежде чем приступать к построению самих конвейеров передаваемых в экосистеме данных, требуется обеспечить совместную работу многих служб. Их конфигурирование, настройка и понимание важны для постановки работоспособной системы.
Мы настроили все необходимые службы для локального озера данных, в том числе оркестратор конвейера данных и SQL-движок, инициировали сеанс Spark для Apache-форматов Iceberg и Delta и выполнили простой ETL-процесс. Несмотря на простоту, заложен важный фундамент для создания более сложных конвейеров.
Читайте также:
- Лучший способ эффективно управлять неструктурированными данными
- 5 советов аналитикам и их менеджерам
- Алгоритмы машинного обучения простым языком. Часть 3
Читайте нас в Telegram, VK и Дзен
Перевод статьи George Zefkilis: Building a Local Data Lake from scratch with MinIO, Iceberg, Spark, StarRocks, Mage, and Docker





