
Шаблоны проектирования распределенных систем — это источник проверенных решений и рекомендуемых практик для проектирования и реализации распределенных приложений.
Этими шаблонами обобщается многолетний опыт архитекторов и разработчиков, упрощаются распределенные вычисления.
Рассмотрим шаблоны распределенных систем, микросервисов и просто интересные концепции.
Амбассадор-посредник
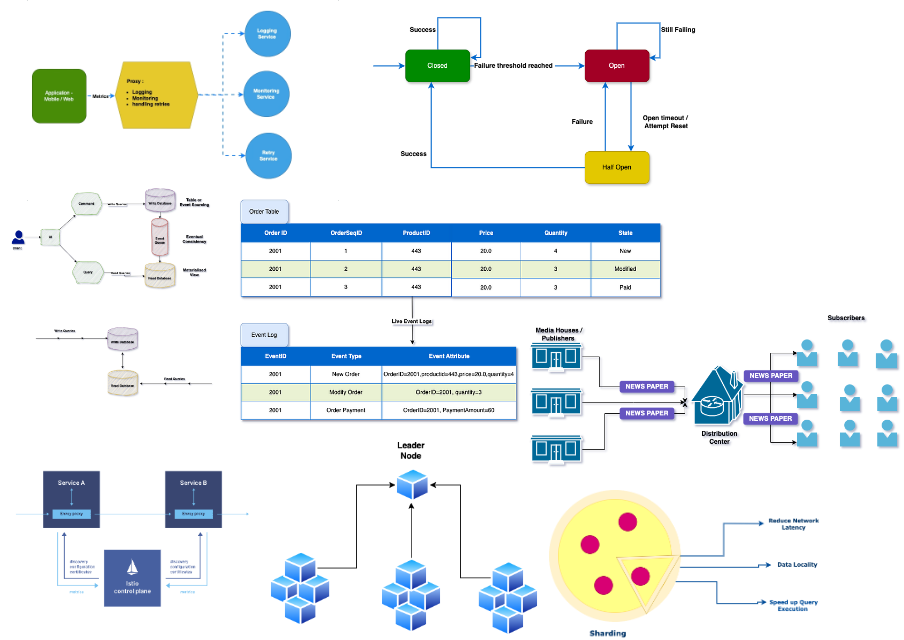
Шаблон «Амбассадор» оставляет приложениям, вдобавок к бизнес-логике, все основные и важные задачи. А себе, как посредник между приложениями и сервисами, забирает логирование, мониторинг или обработку повторов, ограничение скорости:
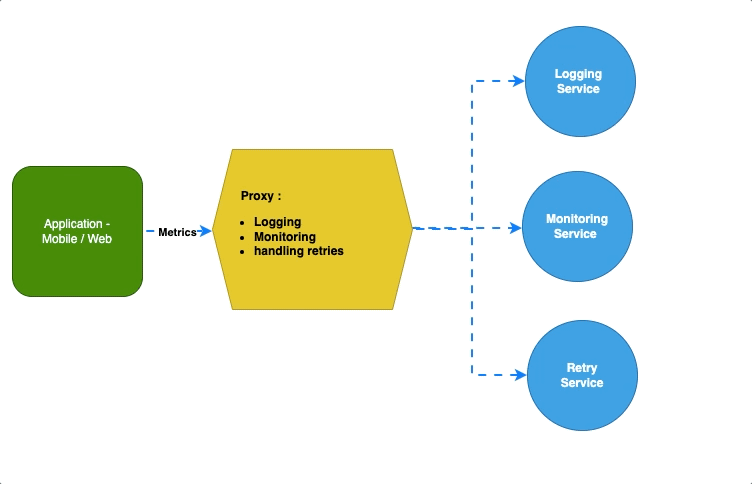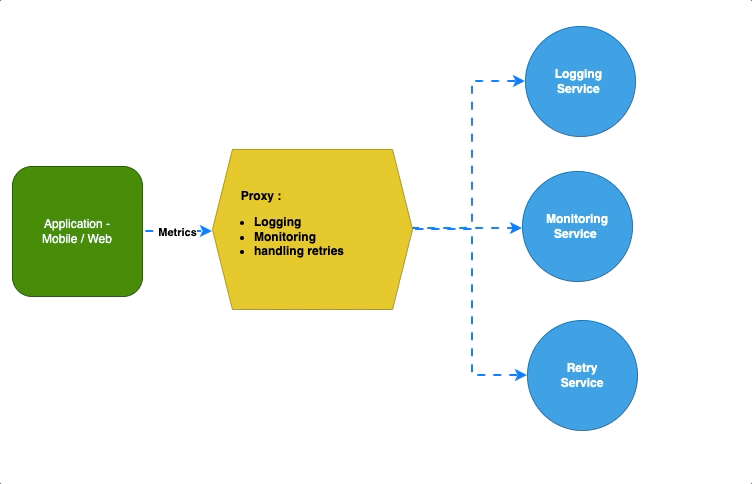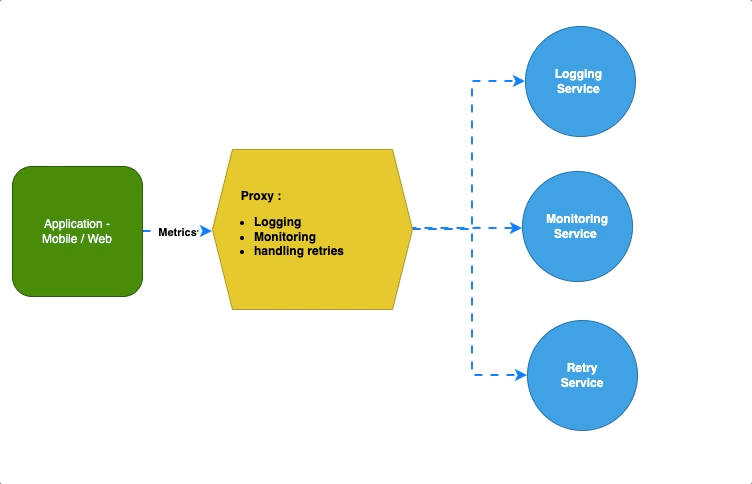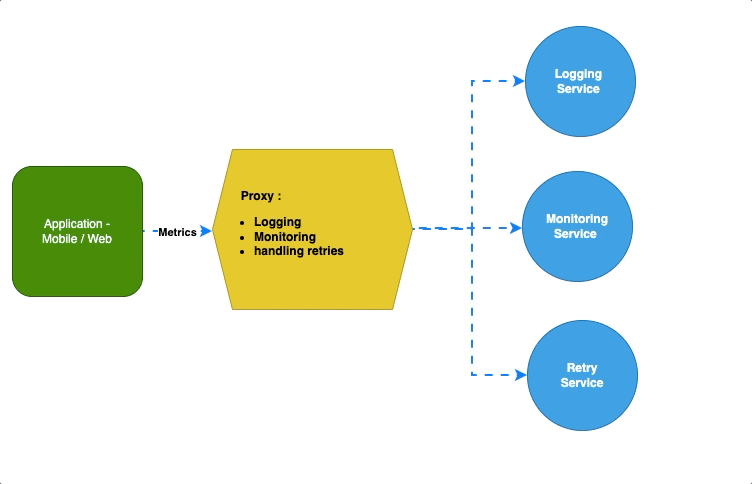
Например, в K8s этим посредником между сервисами выступает Envoy:
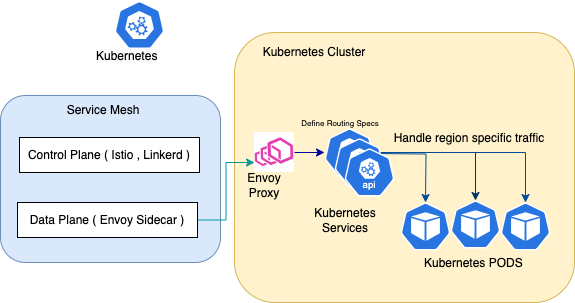
С обширным функционалом Istio разработка и выпуск ПО убыстряются, упрощаются, становятся безопаснее.
Безопасность. В Istio разработчикам обеспечивается безопасность с нулевым доверием, возможностью определять и внедрять политики аутентификации, авторизации, контроля доступа.
Обнаружение сервисов. Высокая доступность приложения в продакшене — это насущная необходимость. С повышением нагрузки необходимо увеличивать число экземпляров сервиса, а при необходимости экономии затрат — уменьшать. Благодаря обнаружению сервисов в Istio отслеживаются все доступные узлы, готовые подхватить новые задачи. В случае недоступности узла он удаляется из списка доступных, отправка на этот узел новых запросов прекращается.
Управление трафиком. Гибким Istio делают прокси-серверы Envoy для детализированного контроля трафика между доступными сервисами. В Istio имеется функционал балансировки нагрузки, проверок работоспособности и стратегий развертывания. Нагрузка балансируется на основе алгоритмов: циклического перебора, случайного выбора, взвешенных алгоритмов и т. д. Постоянные проверки работоспособности экземпляров сервиса выполняются до отправки запроса трафика, так убеждаются в доступности этих экземпляров. В зависимости от типа развертывания в конфигурации, трафик направляется в новые узлы по взвешенной схеме.
Устойчивость. С Istio отпадает необходимость в написании кода выключателей внутри приложения. Разработчики платформ определяют механизмы вроде тайм-аутов сервиса, количества повторов и планируемой автоматической отработки отказа систем высокой доступности. А приложение, как говорится, ни сном ни духом.
Наблюдаемость. С Istio отслеживаются сетевые запросы и каждый вызов в многочисленных сервисах. Используя телеметрию: задержку, насыщенность, состояние трафика и ошибки — специалисты по обеспечению бесперебойной работы анализируют поведение высоконагруженных сервисов, устраняют неполадки, сопровождают и оптимизируют соответствующие приложения.
Выключатель
Если в доме прорвало трубу, во избежание дальнейших неприятностей мы первым делом перекрываем воду. Таков же принцип работы шаблона «Выключатель», только в роли неприятностей — каскадные отказы в распределенных системах.
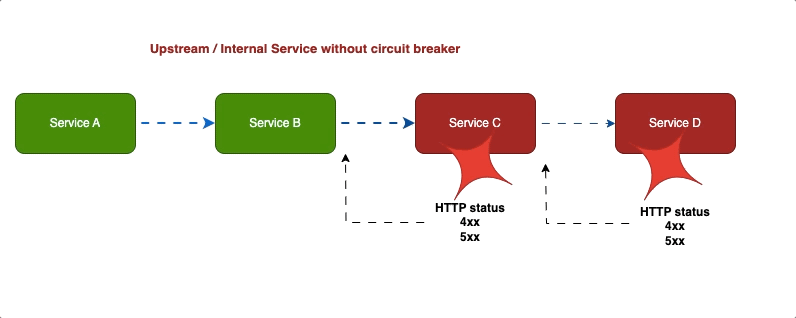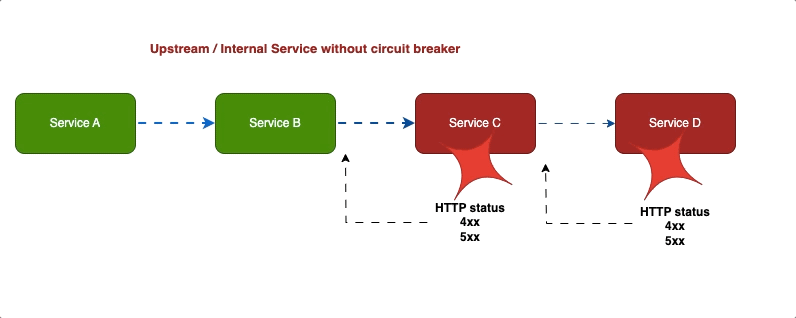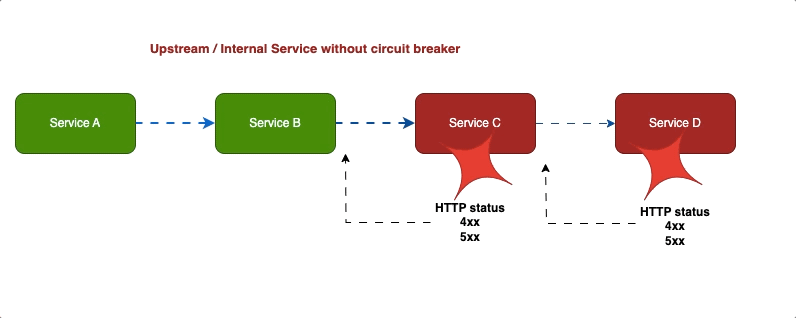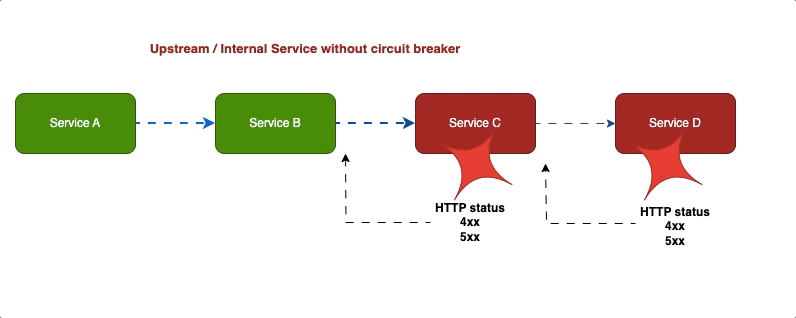
Когда сервис становится недоступным, для его восстановления выключатель останавливает запросы. Так шаблоном «Выключатель» предотвращаются дальнейшие отказы.
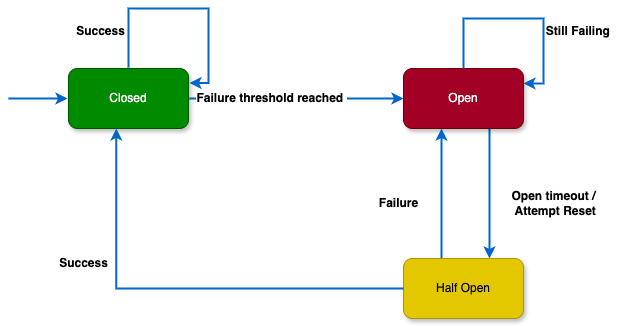
Закрыто.
В этом состоянии выключателем разрешается обычное взаимодействие сервисов, запросы в сервис поступают.
В ответах сервиса выключателем выявляются ошибки: HTTP-код 4XX, 5XX. Если в ответах выдается 200 ОК без каких-либо ошибок, выключатель остается в закрытом состоянии.
Открыто.
Когда количество отказов достигает порогового значения, выключатель переводится в открытое состояние: HTTP-код 4XX, 5XX со счетчиком пороговых значений < 30. Запросы в сервис не попадают, и выдается ответ при отказе.
Пороговое значение, например, 30 отказов за 10 секунд.
Полуоткрыто.
Когда истекает время ожидания или интервал сброса, выключатель переводится в полуоткрытое состояние.
Так в сервис поступает ограниченное количество тестовых запросов, и проверяется, восстановился он или нет.
Если на тестовые запросы выдается 200 ОК, сервис восстановился, и выключатель возвращается в закрытое состояние.
Если какой-либо из тестовых запросов не выполняется, у сервиса остаются проблемы, для блокирования дальнейших запросов выключатель переводится в открытое состояние.
Шаблон «Выключатель» реализуется такими инструментами и фреймворками.
- Netflix Hystrix
Это библиотека Java с открытым исходным кодом для реализации шаблона «Выключатель» с обеспечением отказоустойчивости и задержки в распределенных системах и микросервисных архитектурах.
Примечание. Netflix официально переведен в режим обслуживания, и пользователи переходят на альтернативы: resilience4j или Sentinel.
Ключевые особенности Resilience4j:
Повтор. Определяются стратегии повторов для невыполненных операций, указывается количество повторов.
Ограничитель скорости. Чтобы предотвратить перегрузку некоторых частей приложения, трафик в них контролируется ограничением количества запросов к сервису.
Аварийный режим. Для невыполненных операций определяются резервные функции или ответы, работа завершается корректно, совершенствуется пользовательское взаимодействие.
2. Resilience4j
Это легковесная, простая библиотека для мощной реализации шаблона «Выключатель» по примеру Netflix Hystrix, но с применением подхода функционального программирования.
3. Istio
Это платформа сетки сервисов для управления трафиком между микросервисами. Среди ее функционала выделяется шаблон обеспечения отказоустойчивости «Выключатель», которым трафик перенаправляется от неработоспособных микросервисов и автоматически повторяются невыполненные запросы.
4. Sentinel
Это Open Source библиотека для мониторинга сервисов и контроля трафика, применяется для остановки запросов, их ограничения. Sentinel применяется на Java и других языках.
5. Amazon App Mesh
Это управляемая сетка сервисов для мониторинга и контроля сервисов, запускаемых на AWS. В Amazon App Mesh имеется функционал для повышения надежности микросервисов: остановка запросов, повторы и т. д.
CQRS, или разделение ответственности на команды и запросы
В CQRS операции считывания и записи разделяются на разные базы данных, командами выполняется изменение данных, запросами — считывание.
На платформе электронной коммерции много запросов на считывание листинга товаров, меньше — на запись для размещения заказов.
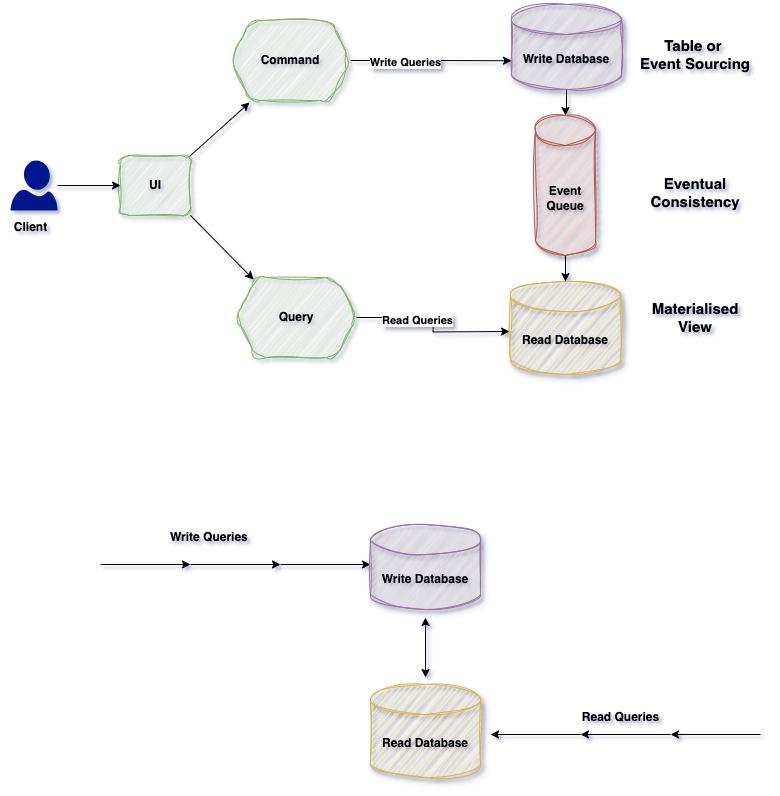
В монолитных приложениях одной базой данных обычно обрабатываются операции запросов и изменений, выполняются сложные объединения и CRUD-задачи. По мере усложнения приложений эти операции становятся неуправляемыми.
Например, запрос с объединением более 10 таблиц чреват блокировкой базы данных из-за задержки, и CRUD-операции со сложными проверками также чреваты блокировками.
В CQRS эта проблема решается разделением операций считывания и записи на разные базы данных, то есть применением принципа разделения обязанностей. Например, нереляционная база данных используется для операций считывания, а реляционная — для операций записи.
Важно понимать поведение приложения. Если это приложение интенсивного считывания, притом что соотношение считываний и записей не является функциональным требованием, архитектурой приоритизируется оптимизация операций считывания.
В примере приложения для электронной коммерции:
Команды — это действия с операциями на основе задач вроде «добавить товар в корзину» или «оформить и оплатить заказ». Поэтому команды управляются системами брокеров сообщений с асинхронной обработкой.
Запросами база данных никогда не изменяется. Ими всегда возвращаются данные JSON с объектами переноса данных DTO. Так можно изолировать команды и запросы.
Чтобы изолировать команды и запросы, рекомендуется одну базу данных для считывания и записи физически разделить на две. Так, для приложения интенсивного считывания — где считываний больше, чем записей — определяется пользовательская схема данных, оптимизируемая для запросов.
Шаблон материализованного представления — хороший пример реализации баз данных для считывания. С его помощью избегают сложных объединений и сопоставлений с предопределенными детализированными данными для операций запросов.
При такой изоляции используются даже разные типы баз данных для считывания и записи, например нереляционная документная БД для считывания и реляционная для crud-операций.
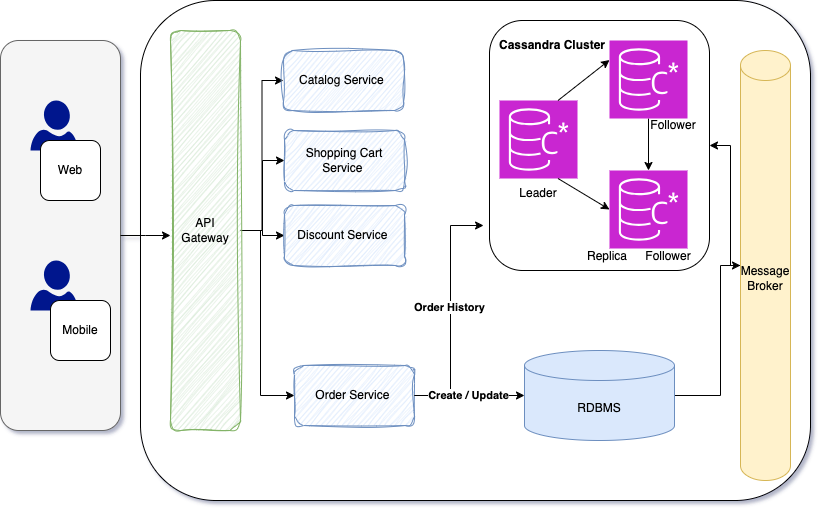
Спроектируем базы данных микросервисов для заказов.
Разделяем две базы данных микросервисов для заказов:
одна база данных записей для реляционных задач;
другая — считываний для запросных задач.
Поэтому, когда пользователь создает или меняет заказ, применяется реляционная база данных для записи, а когда запрашивает заказ или историю заказов — нереляционная база данных для считываний. Они приводятся в соответствие при синхронизации двух баз данных системой брокера сообщений с применением шаблона «издатель-подписчик».
Рассмотрим технологический стек этих баз данных.
SQL Server: PostgreSQL или MySQL для реляционной базы данных записей и Cassandra для нереляционной БД считываний. А синхронизируются эти две базы данных обменом темами публикации/подписки Kafka.
Порождение событий
Порождение событий — это не сохранение текущего состояния данных, а скорее ведение журнала интерактивных событий. Этим шаблоном записывается последовательность событий, приведшая к текущему состоянию.
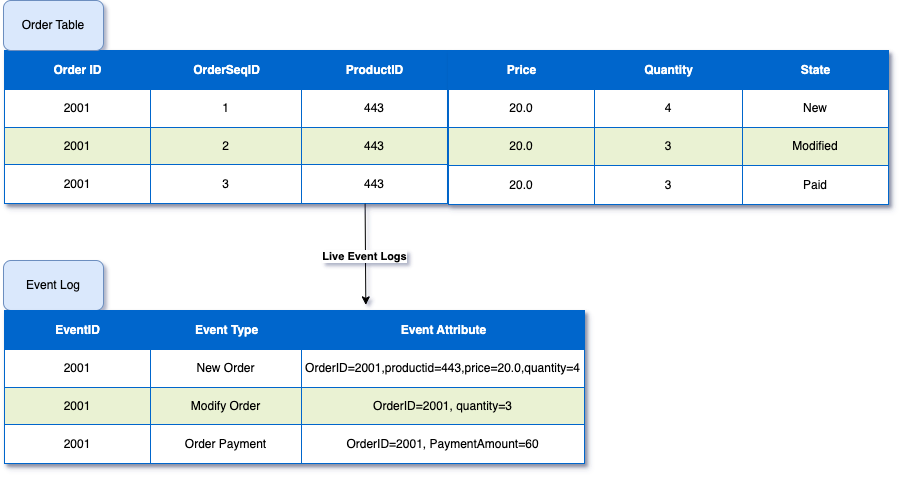
Преимущества: благодаря предоставлению полного контрольного журнала обрабатываются сложные события, повышается согласованность, выполняется отладка с возможностью двигаться по ходу работы программы в обратном направлении или воспроизведение событий для целей аналитики.
Трудности: для восстановления состояния требуется тщательно спроектировать схемы событий и обработку воспроизведения событий.
Шаблон «Люлька»
Для управления сквозной функциональностью — логированием, мониторингом и конфигурацией — этим шаблоном рядом с основными контейнерами сервисов, как мотоциклетные люльки, развертываются вспомогательные компоненты.

Концепция люльки становится популярной в Kubernetes. Контейнеры концентрируются на одной задаче и хорошо ее выполняют. В шаблоне «Люлька» это поддерживается отделением основной бизнес-логики от дополнительных задач.
Здесь в одном узле имеется два контейнера: первый — основной контейнер приложения с основной логикой, второй — запускаемый параллельно в том же поде контейнер-«люлька», которым основной дополняется. Ими разделяются ресурсы вроде файловой системы, диска и сети.
Кроме того, шаблоном «Люлька» в изолированных контейнерах развертываются различные компоненты одного и того же приложения. Это совместно используемые компоненты микросервисной архитектуры: свойства логирования, мониторинга и конфигурации.
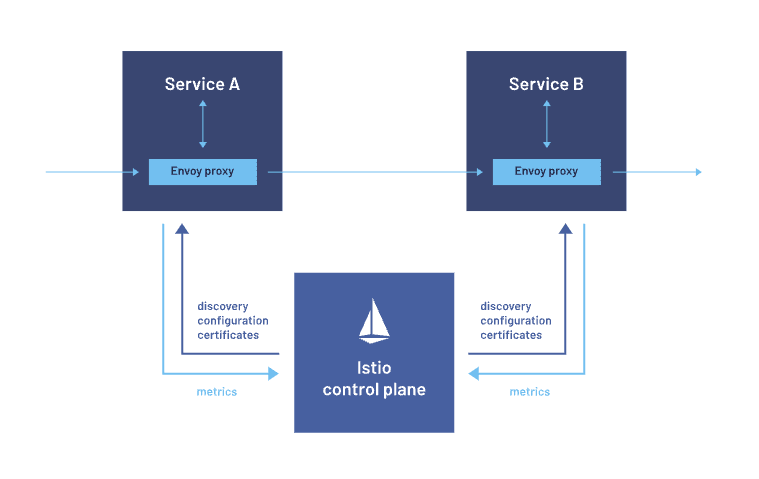
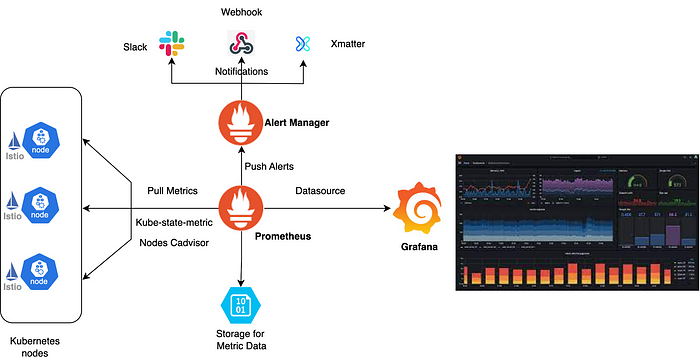
Преимущества: совершенствуются модульность и сопровождаемость.
Примеры: Istio для сетки сервисов, Envoy как дополнительный прокси-контейнер.
Выбор лидера
В распределенных системах некоторым задачам алгоритмами выбора лидера назначается узел-лидер.
За конкретную задачу или ресурс ответствен только один узел.
Если случается сбой узла-лидера, оставшимися выбирается новый. В Zookeeper и etcd с помощью этого шаблона управляют распределенными конфигурациями.
Благодаря назначению лидера в распределенной системе избегаются конфликты, обеспечивается согласованное принятие решений.
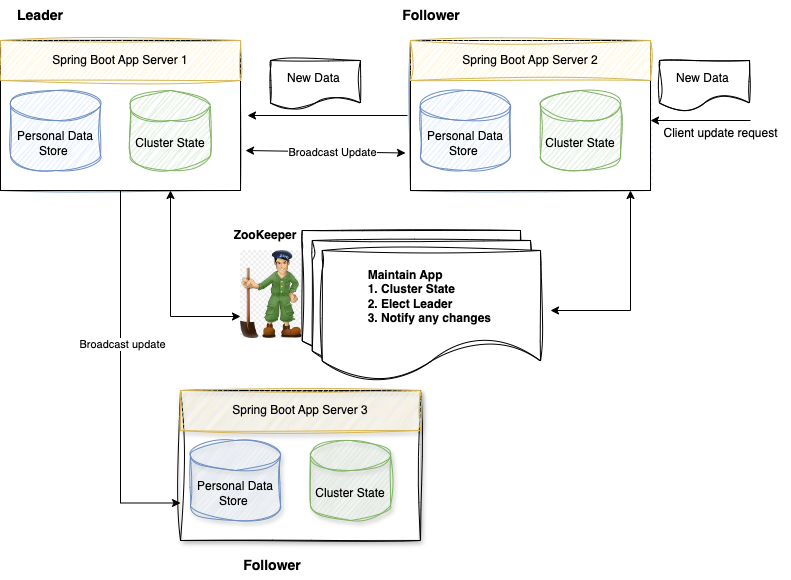
На этой схеме:
- Три сервера приложений Spring Boot, запускаемые на портах 8081, 8082 и 8083 в качестве баз данных, где хранятся персональные данные.
- Каждый сервер Spring Boot при запуске подключается к автономному серверу Zookeeper.
- В памяти каждого сервера приложений Spring Boot поддерживается и сохраняется информация о кластере, передаваемая текущим активным серверам, актуальному лидеру кластера и всем узлам этого кластера.
- Для получения информации о кластере и персональных данных создадим два API-интерфейса GET, а для сохранения персональных данных — API-интерфейс PUT.
- Любой поступающий на сервер приложения запрос изменения персональных данных отправляется лидеру, откуда пересылается всем рабочим/ведомым серверам.
- В любом нерабочем сервере, ставшем рабочим, персональные данные синхронизируются от лидера.
Преимущества: обеспечиваются скоординированность действий, согласованность.
Примеры: Zookeeper, etcd.
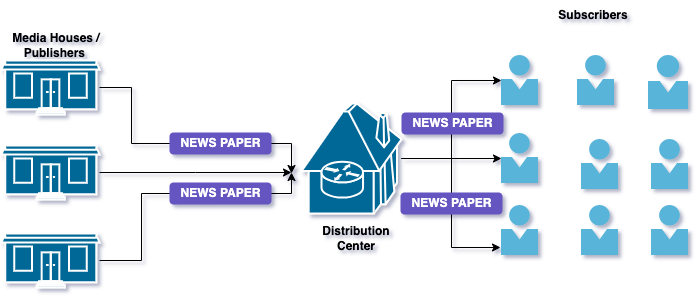
Издатель/подписчик
Благодаря этому шаблону сервисы взаимодействуют асинхронно. Издатели отправляют сообщения, не зная подписчиков, а подписчики получают интересующие их сообщения.
Шаблон «Издатель-подписчик» похож на службу доставки газет: издатели выдают события, не зная, сколько подписчиков их получают, а подписчики прослушивают интересные им события.
Этим шаблоном совершенствуются масштабируемость и модульность. Например, благодаря асинхронному обмену сообщениями между сервисами, в Google Cloud Pub/Sub упрощаются сопровождение и масштабирование сложных приложений.
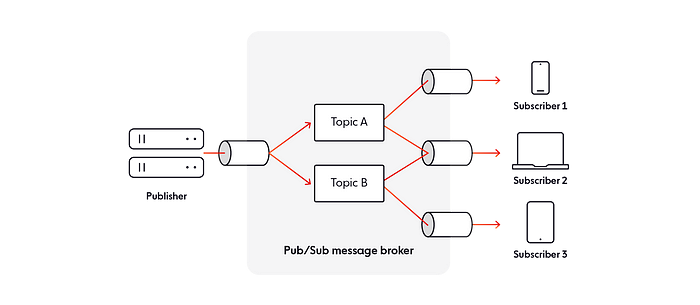
- Согласно шаблону «Издатель-подписчик» сообщения перемещаются между компонентами системы, не «знающими» о существовании друг друга, эти компоненты отделены.
- Шаблоном предоставляется фреймворк для обмена сообщениями между издателями — компонентами, которыми создаются и отправляются сообщения — и подписчиками — компонентами, которыми сообщения получаются и используются.
Преимущества: отправители сообщений отделяются от получателей, повышаются масштабируемость и гибкость.
Примеры: Kafka, RabbitMQ, AWS SNS, Google Cloud Pub/Sub.
Сегментирование
Сегментирование — это способ распределения данных по узлам системы для повышения производительности и масштабируемости.
Похоже на разделение большой пиццы на куски, чтобы было проще с ней управиться.
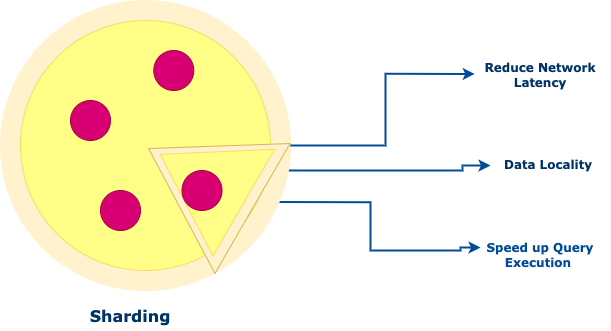
Набор данных разделяется на мелкие, более управляемые части — сегменты, распределяемые по базам данных или узлам.
В каждом сегменте содержится поднабор данных, благодаря чему нагрузка на любой одиночный узел снижается.
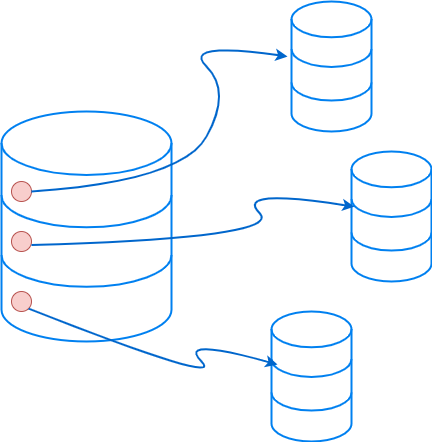
В базах данных вроде MongoDB и Cassandra сегментированием эффективно обрабатываются большие объемы данных, повышается локальность данных, благодаря чему сокращается сетевая задержка, ускоряется выполнение запросов.
Сегментирование существенно отличается от секционирования, разберем их подробнее:
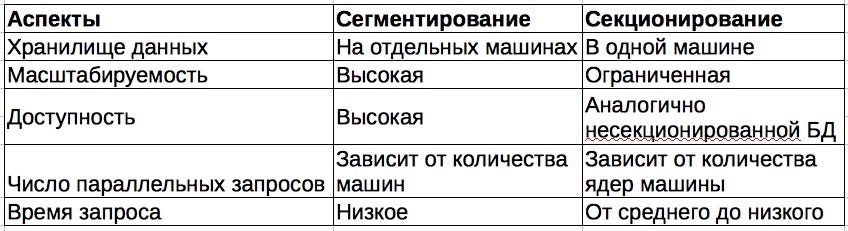
Секционирование
Секционирование — общий термин, которым обозначается разделение базы данных вдоль определенной оси:
- по вертикали на базы данных поменьше с теми же строками, но другими столбцами;
- по горизонтали на базы данных поменьше с теми же столбцами или схемой, но другими строками.
Сегментирование
Сегментирование — это разновидность секционирования. Прежде чем переходить к сегментированию и его уникальности, разберемся с масштабированием данных. По мере увеличения их объема требуется увеличить и емкость хранилища базы данных. При этом выполняется вертикальное масштабирование — добавляются процессор, ОЗУ, хранилище и т. д. — или горизонтальное — в сервер добавляются узлы или машины.
Типы сегментирования:
Алгоритмическое, когда база данных той или иной секции определяется клиентом без посторонней помощи. При динамическом сегментировании секции отслеживаются среди узлов отдельным сервис-локатором.
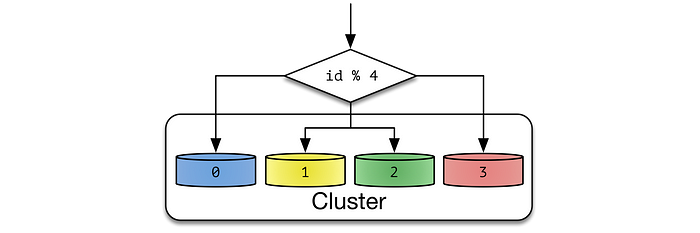
Динамическое, когда местоположение записей определяется внешним сервис-локатором. Это реализуется по-разному. Если количество секционных ключей относительно невелико, локатор назначается каждому ключу. В противном случае за каждым локатором закрепляется диапазон ключей.
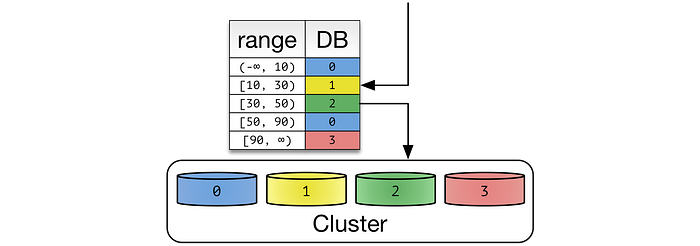
Группы сущностей: когда связанные сущности хранятся в одной секции, в ней появляются дополнительные возможности.
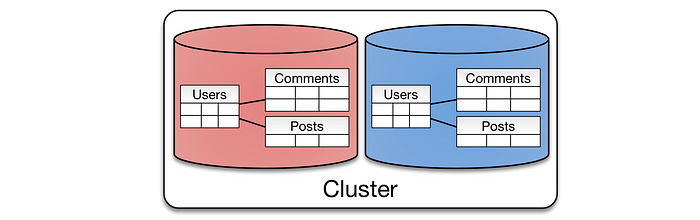
Примеры
- На сайте электронной коммерции с информацией о заказах/клиентах/товарах данные секционируются или сегментируются по странам или регионам, так как по большинству запросов информация получается, исходя из конкретного местоположения.
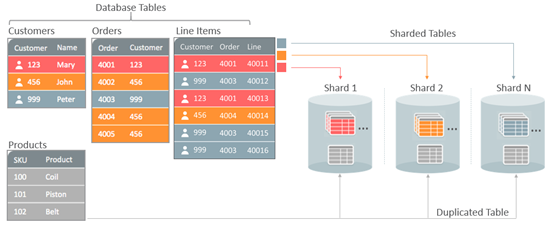
- Фирмой-аналитиком фондового рынка данные секционируются по компаниям, а если выполняется детальный технический анализ, то и по дням.
Чтобы получить цену акций за период с апреля по декабрь 2010 года, запрашивается сегмент 1. Для повышения производительности запросов данные в каждом сегменте хранятся в отсортированном порядке. Это проиллюстрировано на диаграмме ниже:
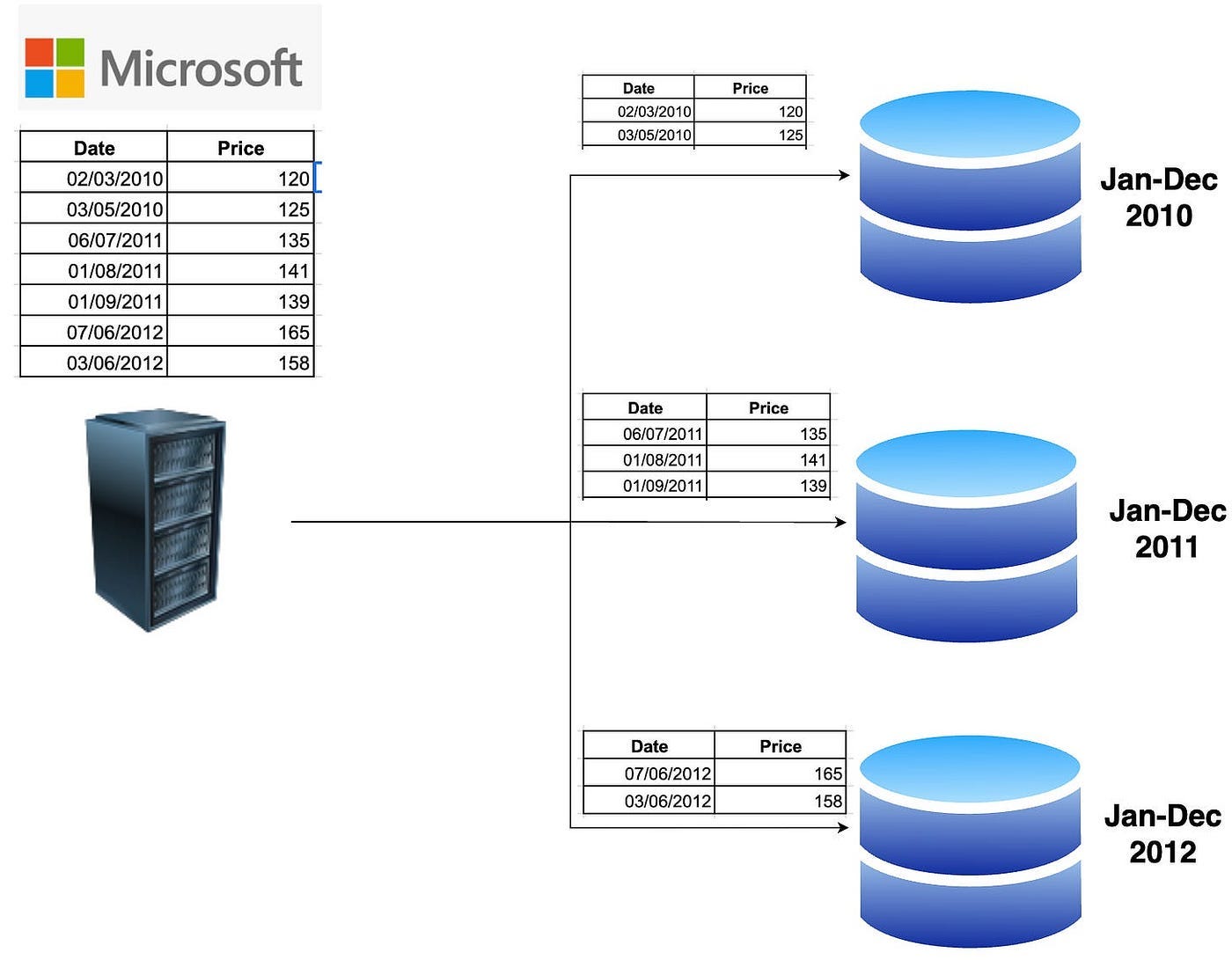
Преимущества: повышаются масштабируемость и производительность.
Трудности: осложняются маршрутизация запросов и управление сегментами.
Перегородка
Чтобы сбой в одном из компонентов не сказался на всей системе, компоненты изолируются.
Шаблон «Перегородка» приходится кстати в таких сценариях.
- Изоляция ресурсов: чтобы предотвратить конфликты из-за ресурсов, используемых бэкенд-сервисами получателей, эти ресурсы изолируются.
- Изолирование важных получателей: чтобы оградить важные сервисы-получатели от обычных, обеспечивая доступность и респонсивность важных сервисов даже при пиковых нагрузках или отказах.
- Защита от каскадных сбоев: чтобы обезопасить приложение от возможных каскадных сбоев, когда проблемы в одном сервисе сказываются на других.
Связанные шаблоны
Перегородка неплохо сочетается с такими облачными шаблонами проектирования, как:
- «Выключатель»: отказоустойчивость обеспечивается предотвращением безостановочных вызовов проблемного сервиса.
- «Повтор»: чтобы корректно обрабатывать временные сбои, внутри перегородок реализуются стратегии повторов.
- «Троттлинг»: для контроля и ограничения скорости входящих запросов, предотвращения перегрузки перегородки.
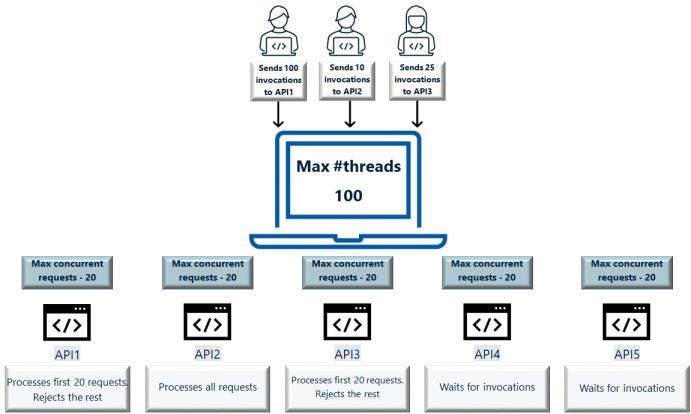
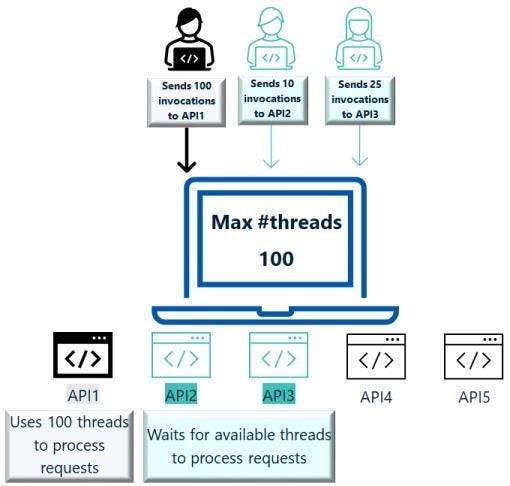
Где реализуется перегородка?
Конфигурацией перегородки в API-шлюзе указывается максимум одновременных запросов, обрабатываемых API-интерфейсом.
Ограничение перегородки для API на уровне API. Указывается максимальный предел одновременных запросов для API, при превышении которого запросы отклоняются.
В это число не включаются получаемые в API обратные вызовы. Поэтому максимум одновременных обратных вызовов, обрабатываемых API, указывается отдельно.
При отклонении запросов в клиентский сервис отправляется код ошибки «503» Service unavailable, то есть сервис недоступен.
Код ошибки и конструкция состояния конфигурируются в расширенных настройках, а код состояния и сообщение — в расширенных настройках pg.bulkhead.statusCode и pg.bulkhead.statusMessage соответственно.
Ограничение перегородки для всех API, глобальная политика. Указывается максимальный предел одновременных запросов для всех API.
Аналогично конфигурации уровня API, указывается максимум одновременных обратных вызовов и выбирается, повторять ли отклоненные запросы.
Если одно ограничение перегородки для API-интерфейсов настроили на глобальном уровне, а другое — на уровне API, приоритет за первым.
Чтобы это переопределить, из глобальной политики с помощью фильтров исключаются нужные API. Фильтры применяются при создании или редактировании глобальной политики перегородки.
Преимущества: повышаются способность восстанавливаться и отказоустойчивость.
Примеры: изоляция различных сервисов в архитектуре микросервисов.
Кэширование на стороне
В этом шаблоне данные явно загружаются из хранилища в кэш и через кэш записываются в хранилище.
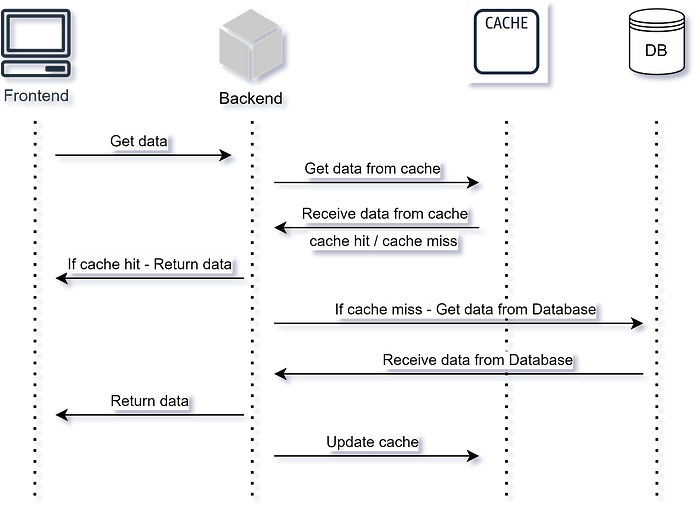
Шаблоном «Кэширование на стороне», известном как отложенная загрузка, подразумевается непосредственное взаимодействие кода приложения с кэшем.
Когда запрашиваются данные, приложением первым делом проверяется кэш. Если данные найдены, возвращаются пользователю. Если нет, то извлекаются приложением из основного источника данных, сохраняются в кэше, а затем возвращаются пользователю.
Шаблон хорош для сценариев кэша, в котором содержатся часто запрашиваемые данные: отклик убыстряется, снижается нагрузка на основной источник данных.
Сквозное и упреждающее кэширование при записи
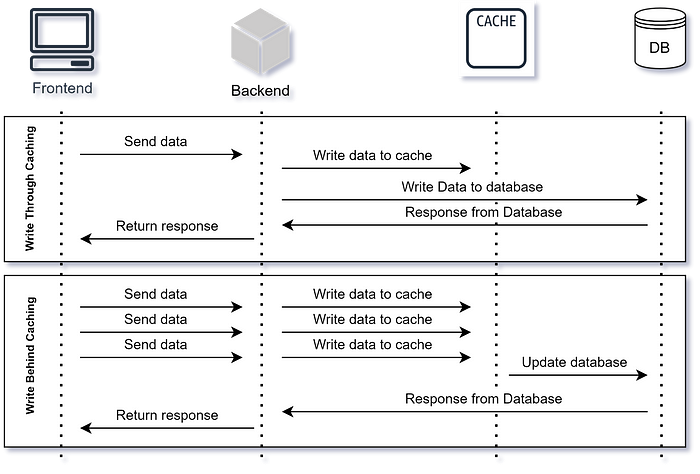
Сквозное кэширование — это запись в кэш и в основной источник данных одновременно. Кэш и основной источник данных остаются согласованными, но операция двойной записи чревата задержкой.
При упреждающем же кэшировании сначала в кэш записываются данные, затем асинхронно обновляется основной источник данных. Задержка сокращается, зато увеличивается риск несогласованности данных в случае системных сбоев или аварийного завершения работы.
Сквозное и упреждающее кэширование при считывании
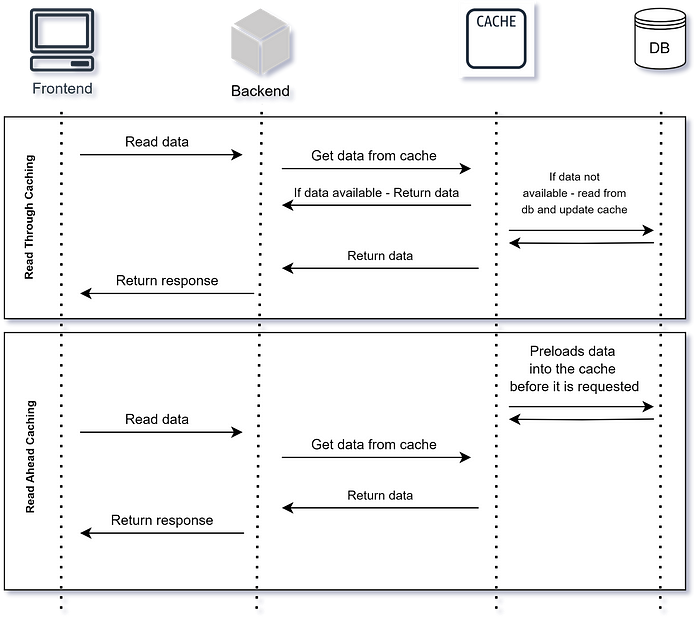
Сквозное кэширование — это считывание данных из кэша. Если они не найдены, то извлекаются из основного источника данных, сохраняются в кэше и возвращаются пользователю.
Этот шаблон хорош для рабочих нагрузок с интенсивным считыванием: кэшированием часто запрашиваемых данных здесь повышается производительность.
Благодаря же упреждающему кэшированию при считывании, предвосхищаются будущие схемы доступа к данным, и данные загружаются в кэш еще до запрашивания. Так сокращается задержка, и обеспечивается, что нужные данные в случае необходимости уже доступны.
Преимущества: снижается нагрузка на базу данных, повышается эффективность считывания.
Примеры: Redis, Memcached.
Читайте также:
- Практическое предметно-ориентированное проектирование
- Чему может научить авиация в области дизайн-систем
- Один за всех и все за одного: 8 принципов командной разработки
Читайте нас в Telegram, VK и Дзен
Перевод статьи Anil Gudigar: Most-Used Distributed System Design Patterns




