
«Каждый человек — гений. Но если судить о рыбе по ее способности лазать по деревьям, можно всю жизнь считать ее бездарностью», — А. Эйнштейн (авторство цитаты точно не установлено)
Бенчмарки вносят большой вклад в продвижение такой области, как обработка естественного языка (NLP), предоставляя стандартные наборы данных для обучения и оценки моделей. Эти наборы данных развивались с течением времени и по мере совершенствования моделей. Они выросли как по масштабу, так и по количеству задач, которые можно протестировать. Изначально наборы данных для NLP-задач проверялись вручную, поскольку маркировка экспертами явно предпочтительнее. Однако с увеличением объема этих наборов данных повышается затратность экспертной аннотации, что делает ее все более нецелесообразной. В то же время спрос на аннотацию остается (более того, он постоянно растет), поэтому исследователи обращаются к краудсорсингу.
Позволяя снизить стоимость и время получения наборов данных, краудсорсинг приводит к увеличению количества ошибок. Ни один набор данных не является идеальным, поскольку речь идет о достижении компромисса между масштабом, эффективностью и опытом. С одной стороны, даже эксперты допускают ошибки (возникающие из-за таких факторов, как субъективность при решении задачи, усталость аннотатора, невнимательность, недостаточное количество инструкций и т. д.). С другой стороны, когда наборы данных аннотируются неспециалистами, ошибок гораздо больше.

Эти ошибки чреваты рядом неожиданных последствий. Они могут повредить обобщению модели, обученной на этих ошибках, или привести к неправильной оценке модели. Большие языковые модели (LLM) продемонстрировали ряд достижений, включая способность изучать задачу в контексте. Поэтому некоторые исследователи решили попробовать использовать их для аннотирования наборов данных вместо краудсорсинга.
Оказалось, что по всем четырем наборам данных доля правильных ответов при обучении без примеров (zero-shot accuracy) у ChatGPT в большинстве задач выше, чем у MTurk. Во всех задачах степень согласованности различных экспертных оценок (intercoder agreement) у ChatGPT превышает таковую как у MTurk, так и у обученных аннотаторов. Более того, ChatGPT значительно дешевле MTurk (источник).
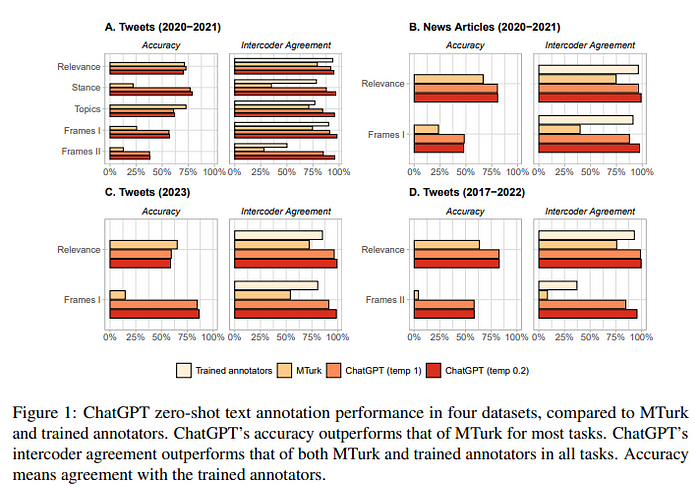
Особенно перспективным использование LLM обещает стать для языков с низким уровнем ресурсов. LLM могут стать подходящим вариантом в случаях, когда трудно найти аннотаторов или при необходимости улучшить имеющийся набор данных, обнаруживая и исправляя ошибки (выступая в качестве эксперта для повторного аннотирования и исправления).
Остаются вопросы:
- Как много ошибок в бенчмарках?
- Могут ли LLM выявить их?
- Как соотносятся по качеству и эффективности аннотации экспертов, краудсорсинга и аннотации на основе LLM?
- Как эти ошибки влияют на производительность модели и можно ли смягчить их влияние?
И самый главный вопрос, который поставили перед собой авторы данного исследования: работают ли LLM эффективнее, чем заявлено?
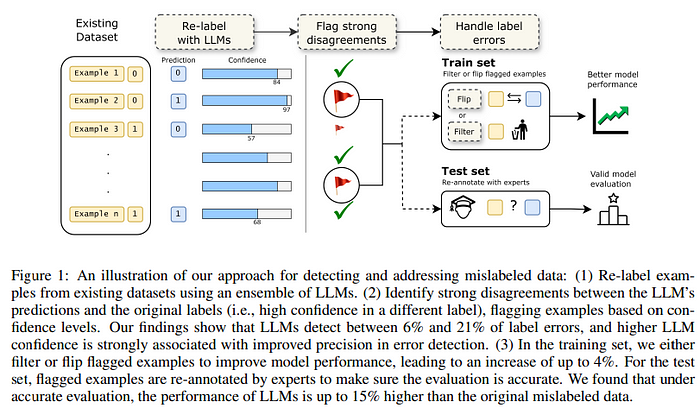
Исследователи взяли набор данных, используемый для оценки LLM, — бенчмарк TRUE (состоит из 11 наборов данных для различных NLP-задач, таких как обобщение и диалог, основанный на знаниях). Преимущество этого набора в том, что метки являются бинарными (0/1). Были выбраны 4 из 11 поднаборов данных.
После этого они использовали различные LLM для выполнения задачи аннотатора: GPT-4, PaLM2, Mistral 7B и Llama 3 8B. Одновременно на краудсорсинговой интернет-площадке Amazon Mechanical Turk (MTurk) набрали команду сотрудников для аннотирования 100 примеров из каждого поднабора данных (каждый пример аннотировался тремя разными аннотаторами).
Чтобы ответить на первый вопрос, исследователи использовали свой LLM-ансамбль для выявления ошибок. Обнаружили высокий процент примеров, которые можно считать ошибками (разногласиями). Попросили членов набранной команды аннотировать эти примеры и подтвердить, что процент ошибок высок.
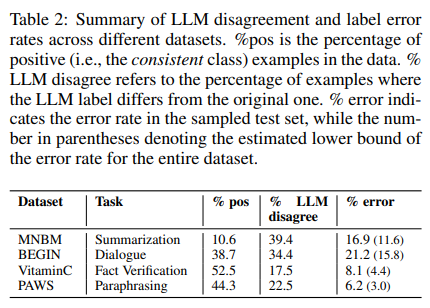
LLM-аннотации ценны для выявления неправильно помеченных данных, предлагая больше, чем просто бинарные метки. Учитывая баллы уверенности моделей наряду с их предсказаниями, можно повысить точность автоматического обнаружения ошибок (источник).
Другими словами, авторы исследования решили проверить, может ли LLM автоматически идентифицировать ошибки. Для определения наличия ошибок использовали степень уверенности LLM. Авторы проанализировали степень уверенности модели и провели проверку по каждому сегменту (бакету), использовавшему LLM или метки.
Некоторые экземпляры пометились с меньшей степенью уверенности, что указывает на то, что модель распознает потенциальную проблему, но не уверена в предложенной метке. С другой стороны, когда LLM с высокой степенью уверенности присваивает метку, противоположную исходной, это служит более сильным сигналом о возможной ошибке в метке (источник).
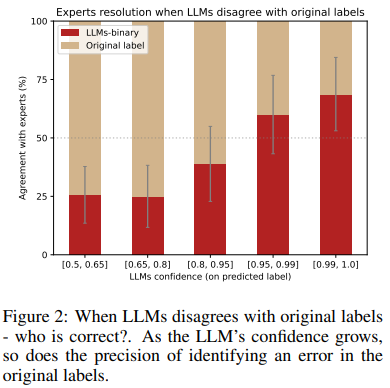
растет и точность определения ошибок в
исходных метках. Источник изображения: здесь
Таким образом, чем выше степень уверенности LLM, тем выше точность выявления потенциальных ошибочных меток в исходном наборе данных. При использовании более одного ансамбля больше шансов выявить ошибки (когда одна модель может преуспеть, а другая — потерпеть неудачу, или наоборот). Тогда можно использовать больше моделей (и больше промптов), а усреднение всех их вероятностей позволяет быть более уверенными в окончательном ответе. Авторы увеличивают количество элементов в таком ансамбле и сравнивают его с золотыми метками (gold labels — безопасными метками для проверки качества меток, полученных ансамблем) и способностью обнаруживать ошибки. Чем больше количество ансамблей, тем выше производительность:
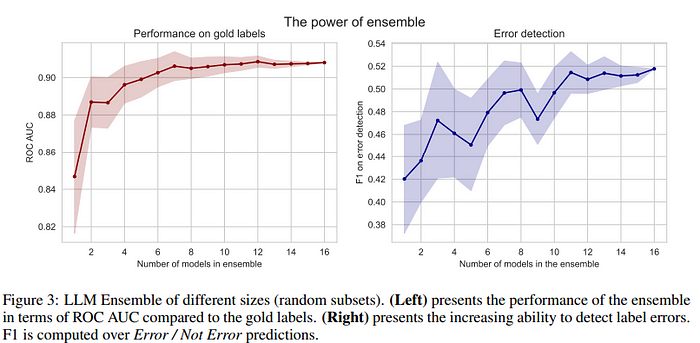
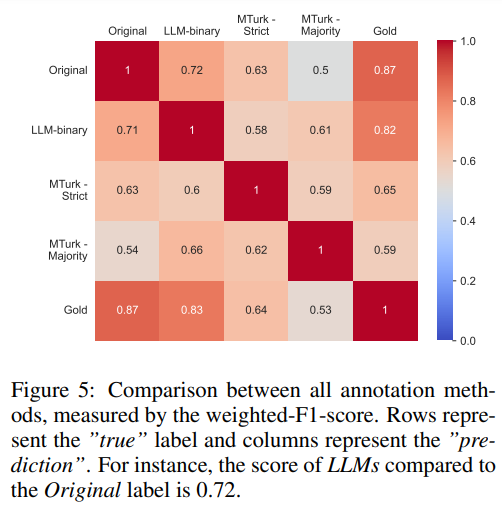
LLM «не согласны» с исходными метками (которые содержат ошибки), но имеют более высокое совпадение с золотыми метками (что свидетельствует о хорошем качестве). Наиболее впечатляющим результатом является то, что аннотирование на основе LLM работает лучше, чем MTurk (даже при применении более строгих критериев к требованиям платформенных аннотаторов).
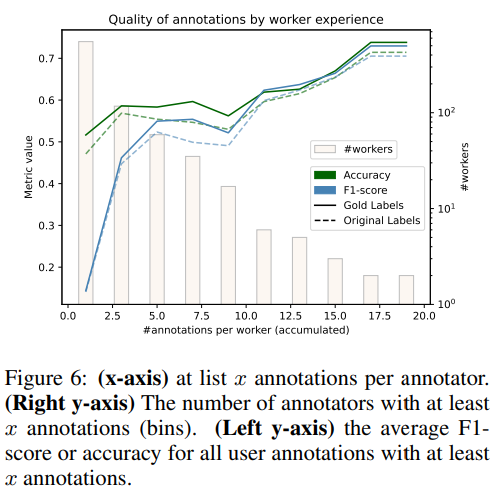
Более глубокий анализ показывает, что аннотаторы с большим опытом работают лучше. Этому также способствует предоставление аннотаторам большего количества примеров, что дает им время на обучение. Однако подавляющее количество аннотаторов предоставляет некачественные аннотации.
Авторы обобщают полученные результаты:
Аннотирование на основе LLM значительно дешевле и быстрее, чем на платформах краудсорсинга, таких как MTurk, особенно если учесть дополнительное время, необходимое для циклов проверки человеком. По оценкам, это в 100-1000 раз экономичнее, чем использование человеческих аннотаторов, в т.ч. экспертов. Такая масштабируемость и скорость делают LLM высокоэффективной альтернативой для решения масштабных задач аннотирования (Источник).

Что произойдет с моделью, если ее обучить на неправильно маркированных данных?
Авторы проверяют, как использование этих наборов данных с ошибками влияет на производительность и стабильность модели. Они наблюдают за тем, что произойдет, если обучить трансформер на наборе данных с ошибками независимо от того, будут ли они отфильтрованы или исправлены. Результаты показывают, что использование ансамбля для исправления ошибок (в зависимости от степени уверенности ансамбля) значительно повышает производительность.
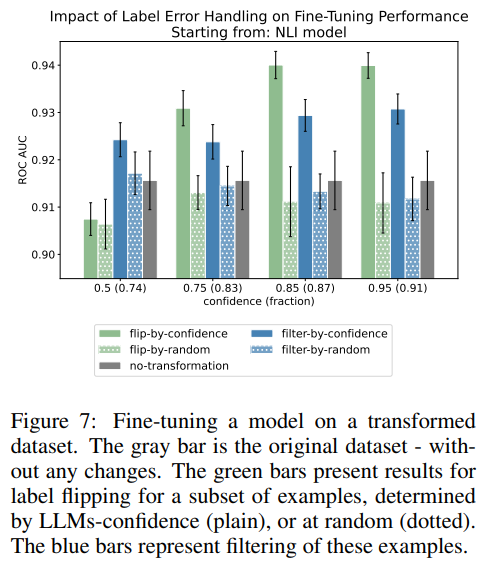
Как быть с оценкой при использовании дефектных наборов данных?
Ошибки в маркировке могут ввести в заблуждение процесс оценки, что приведет к неточным показателям эффективности и в некоторых случаях к ошибочным сравнениям моделей, которые приведут к неправильным выводам (источник).
Особенно интересные результаты: некоторые модели работают гораздо лучше, и наблюдается общее повышение производительности. Таким образом, LLM работают лучше, чем считалось ранее, из-за ошибок в метках (вероятно, многие наборы данных полны ошибок).
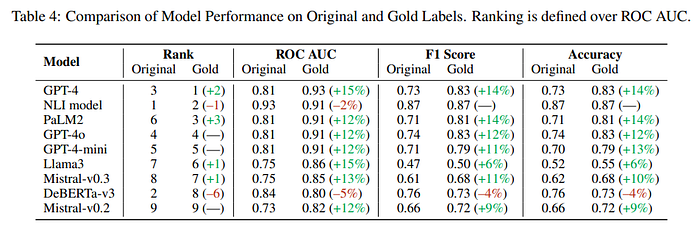
Ошибки маркировки — постоянная проблема в наборах данных NLP, негативно влияющая на тонкую настройку и оценку моделей. Наши результаты показывают, что LLM, особенно при высокой степени уверенности, могут эффективно обнаруживать эти ошибки, превосходя команды краудсорсинга в плане точности, согласованности и экономичности (источник).
Авторы данного исследования показывают, как ошибки в бенчмарках влияют на производительность LLM (как во время обучения, так и во время оценки). Более того, эти ошибки могут быть исправлены автоматически с помощью ансамбля LLM.
Это исследование также показывает, что краудсорсинговые команды могут создавать проблемы и нуждаются в перепроверке. К тому же хорошо известно, что наборы данных бенчмарков полны ошибок, но эта информация часто игнорируется. Необходимо всегда проверять используемые бенчмарки и устанавливать стандарты. Кроме того, работа с наборами данных, в которых много ошибок, теряет свою полезность и не учитывает возможности LLM.
Читайте также:
- Создание LLM-приложений: четкое пошаговое руководство
- Путешествие c LLM: от PoC к производству
- Навигация по ландшафту ИИ в 2024 году: тренды, прогнозы, возможности. Часть 2
Читайте нас в Telegram, VK и Дзен
Перевод статьи Salvatore Raieli: What if LLMs Are Better Than We Think? Or Is It Our Judgement That’s Flawed?





