
Предлагаем вашему вниманию полную запись раунда технического собеседования на должность Java-разработчика в Cisco. Все это актуальные вопросы и ответы для желающих работать в Cisco Systems.
В этой расшифровке собеседования первый раунд проводился двумя старшими инженерами, которые оценивали знания по Java, Spring Boot, микросервисам, базам данных, Hibernate, Kafka и т. д.
Рекомендация профессионала: «За час собеседования всегда задаются только важные вопросы, и они постоянно повторяются. Подготовка к ним — ключ к успеху».
Фреймворк Spring и Spring Boot
Что такое ResponseEntity в Spring Boot?
Это класс всего возвращаемого клиенту HTTP-ответа. Не просто сами данные, в этом классе инкапсулируется три ключевых аспекта.
- Код состояния, им указывается на результат запроса: успех 200 ОК, не найден 404 или внутренняя ошибка сервера 500.
- Заголовки. Это необязательные пары «ключ-значение» с дополнительной информацией об ответе: тип содержимого, управление кэшем или данные аутентификации.
- Тело. Это фактические данные, возвращаемые клиенту: от JSON или XML до обычного текста, в зависимости от проектирования API.
С ResponseEntity обеспечивается детализированный контроль над построением ответа в Spring Boot. Задается код состояния, добавляются пользовательские заголовки, в тело включаются данные ответа, так создаются более информативные и гибкие API:
@RestController
public class ProductController {
@GetMapping("/products/{id}")
public ResponseEntity<Product> getProduct(@PathVariable Long id) {
// Моделируется логика извлечения продукта
Product product = getProductFromDatabase(id);
// Проверяется наличие продукта
if (product == null) {
return ResponseEntity.notFound().build(); // 404 Не найден
}
// Возвращается продукт со статусом «ОК» или «200»
return ResponseEntity.ok(product);
}
// Моделируется извлечение продукта из базы данных, заменяемое на фактическую логику
private Product getProductFromDatabase(Long id) {
// ... детали реализации
return new Product(id, "Sample Product", 10.0);
}
}
Как в приложении Spring Boot сконфигурировать базы данных?
Это очень интересный вопрос, на собеседовании он постоянно повторяется.
Со Spring Boot в приложении удобно конфигурировать базы данных. Делается это поэтапно.
1. Определяются свойства источников данных
- В Spring Boot источники данных конфигурируются с помощью свойств, определяемых в файле
application.ymlилиapplication.properties. - Каждому источнику данных необходим свой набор свойств, предваряемый уникальным идентификатором. Имеются общие свойства.
url: url-адрес подключения к базе данных.username: имя пользователя базы данных.password: пароль базы данных.driverClassName: название класса драйвера JDBC для базы данных.
Вот пример конфигурации для двух баз данных users и orders:
spring:
datasource:
users:
url: jdbc:mysql://localhost:3306/users
username: user
password: password
driverClassName: com.mysql.cj.jdbc.Driver
orders:
url: jdbc:postgresql://localhost:5432/orders
username: orders_user
password: orders_password
driverClassName: org.postgresql.Driver
2. Создаются компоненты DataSource
- В Spring Boot компоненты DataSource создаются аннотациями и утилитами.
- Определенные ранее свойства источников данных сопоставляются с компонентом при помощи
@ConfigurationProperties. - Вот пример класса конфигурации с
DataSourceBuilder, где для каждого источника данных создаются компоненты:
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.users")
public DataSource usersDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.orders")
public DataSource ordersDataSource() {
return DataSourceBuilder.create().build();
}
}
3. Дополнительно конфигурируются диспетчер сущностей и диспетчер транзакций
- Если применяете Spring Data JPA, для каждого источника данных конфигурируются отдельные диспетчеры сущностей и диспетчеры транзакций.
- Они создаются аналогично компонентам DataSource с указанием сущностей, связанных с каждым источником данных.
4. Добавляется корректный DataSource
- По умолчанию в Spring Boot автоматически конфигурируется один DataSource. Что касается конкретных источников данных:
- Для конкретных репозиториев или служб добавляются
@Qualifier("usersDataSource")или@Qualifier("ordersDataSource"). - В репозиториях JPA аннотацией
@Entityс атрибутомentityManagerFactoryRefтакже указывается EntityManager.
Не забываем адаптировать детали конфигурации к конкретным базам данных: тип БД, данные о подключении.
Как объявить глобальные исключения в приложении Spring Boot? [Вопрос с реализацией]
В Spring Boot имеется два способа объявления глобальных исключений.
1. @ControllerAdvice
Это рекомендуемый подход для централизованной обработки исключений.
- Создается класс, аннотированный как
@ControllerAdvice. - Для обработки конкретных исключений определяются методы, аннотированные как
@ExceptionHandler. - Этими методами:
- Возвращается пользовательский объект
errorResponseс данными об исключении. - С помощью
ResponseEntityзадается конкретный код состояния HTTP. - Исключение логируется для дальнейшего анализа.
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(ResourceNotFoundException.class)
public ResponseEntity<ErrorResponse> handleResourceNotFound(ResourceNotFoundException ex) {
ErrorResponse errorResponse = new ErrorResponse("Resource not found");
return ResponseEntity.status(HttpStatus.NOT_FOUND).body(errorResponse);
}
// Определяются методы для других, обрабатываемых глобально исключений
}
Что такое «жизненный цикл компонента Spring»?
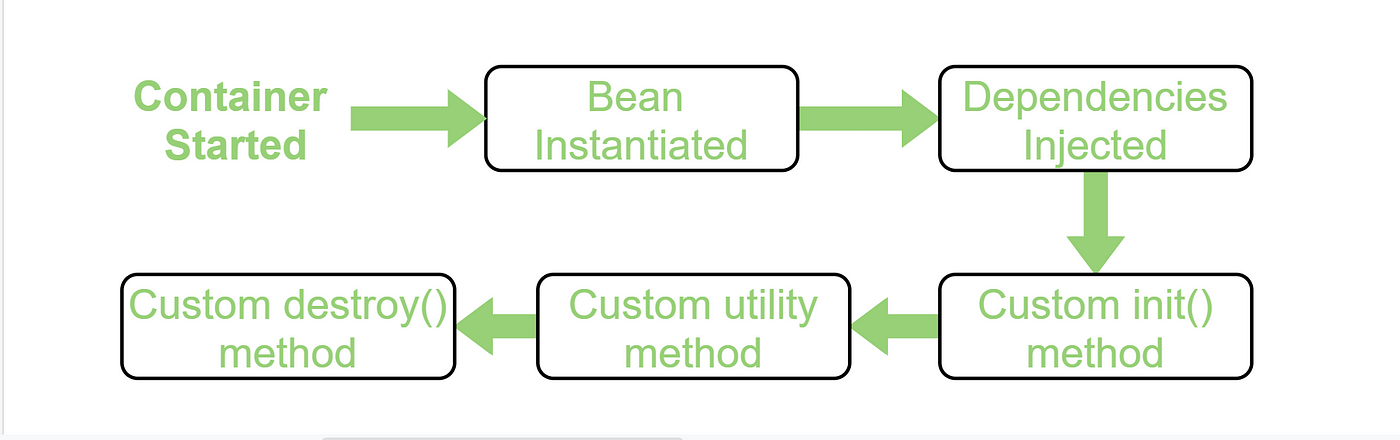
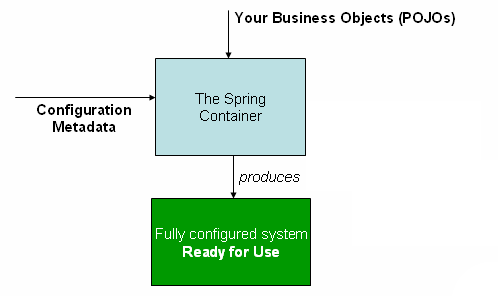
Что такое «IoC-контейнеры»?
IoC-контейнер — это программный компонент, которым в приложении создаются, конфигурируются и собираются объекты-компоненты и их зависимости.
Принцип работы
- Создание объектов. Традиционно объекты создаются в коде вручную. С помощью файлов конфигурации — XML или аннотаций — или классов Java объекты-компоненты для приложения определяются IoC-контейнером, которым затем и инстанцируются.
- Внедрение зависимостей. Для корректного функционирования объектов в них часто применяются другие объекты, то есть зависимости. Чтобы не создавать и не передавать эти зависимости вручную, их объявляют в определениях объектов. Необходимые зависимости добавляются IoC-контейнером в создаваемые им объекты. Так обеспечивается слабая связанность между объектами, код становится более модульным и тестопригодным.
- Управление жизненным циклом объектов. IoC-контейнером также контролируется жизненный цикл объектов, в том числе инициализация и уничтожение. Поэтому писать стереотипный код для этих задач не нужно.
Что такое «внедрение зависимостей»?
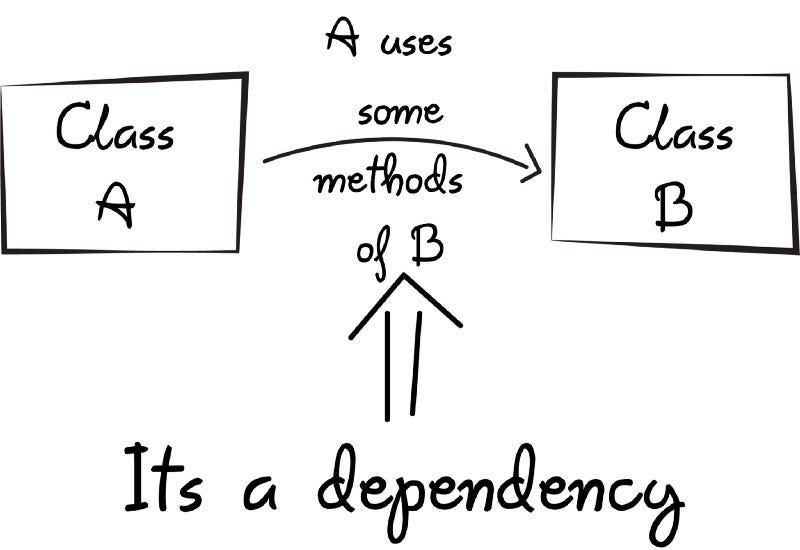
В разработке ПО внедрение зависимостей — это предоставление объекту других объектов, то есть зависимостей, необходимых ему для функционирования.
Разберем ключевые понятия.
Что такое «зависимости»?
- Зависимости — это объекты, применяемые классом или функцией для эффективной работы.
- Примеры:
- Работа автомобиля зависит от двигателя, колес, других деталей.
- Класс доступа к базе данных зависит от объекта подключения к БД для взаимодействия с ней.
Что такое ApplicationContext и как используется?
ApplicationContext в приложениях Spring Boot является центральным интерфейсом, важным для управления объектами-компонентами во всем приложении. Фактически это контейнер, вот его функциональность.
1. Управление компонентами
- Основная задача ApplicationContext — управление объектами-компонентами приложения, которые обычно определяются конфигурационными файлами аннотаций или XML.
- С помощью ApplicationContext эти компоненты создаются, конфигурируются и собираются в соответствии с указанной конфигурацией.
2. Внедрение зависимостей
- Для корректного функционирования объектов-компонентов в них часто применяются другие объекты-компоненты, называемые зависимостями.
- Внедрение зависимостей упрощается тем, что создаваемым с помощью ApplicationContext компонентам необходимые зависимости предоставляются автоматически. Поэтому создавать и контролировать зависимости вручную не нужно, код становится слабо связанным и более сопровождаемым.
3. Доступ к ресурсам
- С ApplicationContext у приложения появляется доступ к файлам свойств, файлам конфигурации, пакетам сообщений.
- Упрощается извлечение данных из ресурсов, обеспечивается согласованный доступ во всем коде.
В чем разница между фильтрами и перехватчиками Spring?
Это хороший вопрос для проверки знания концепций, связанных с фреймфорком Spring MVC.
HandlerInterceptor отличается от сервлетного Filter наличием пользовательских постобработки и предобработки с возможностью запрета выполнения самого обработчика. Фильтры мощнее: они позволяют обмениваться передаваемыми по цепочке объектами запроса и ответа. Фильтр конфигурируется в web.xml, a HandlerInterceptor — в контексте приложения.
Для реализаций HandlerInterceptor годятся связанные с обработчиком детализированные задачи предобработки, особенно если исключить общий код обработчика и проверки авторизации. Filter же хорош для обработки содержимого запроса и представления, например multipart form и сжатие в GZIP. Обычно это проявляется при сопоставлении фильтра с типами содержимого вроде изображений или со всеми запросами.
А чем Interceptor#postHandle() отличается от Filter#doFilter()?
postHandle вызывается после метода обработчика, но до отображения представления. То есть в представление добавляются объекты модели, но HttpServletResponse не изменяется, поскольку уже зафиксирован.
doFilter гораздо универсальнее: здесь запрос или ответ изменяются и передаются в цепочку или даже блокируется обработка запроса.
Кроме того, в методах preHandle и postHandle имеется доступ к HandlerMethod, которым запрос обработан. Поэтому логика пред- и постобработки добавляется на основе самого обработчика, например для методов обработчика с аннотациями.
Согласно документации, для реализаций HandlerInterceptor годятся связанные с обработчиком детализированные задачи предобработки, особенно если исключить общий код обработчика и проверки авторизации. Filter же хорош для обработки содержимого запроса и представления, например multipart form и сжатие в GZIP. Обычно это проявляется при сопоставлении фильтра с типами содержимого вроде изображений или со всеми запросами.
В чем преимущества аннотации @Transactional?
Вопрос об этой аннотации всегда задается на собеседовании по Spring.
Применяемой к методам или классам аннотацией @Transactional указывается, что аннотированный код выполняется внутри транзакции. Когда встречается аннотация @Transactional, вокруг аннотированного кода в Spring автоматически создается транзакция и осуществляется управление ее жизненным циклом.
По умолчанию при помощи @Transactional создаются транзакция со стандартным уровнем изоляции — обычно это READ_COMMITTED — и поведение распространения по умолчанию REQUIRED. Но эти настройки можно персонализировать, передав параметры в аннотацию.
Вот пример использования @Transactional в классе Spring service:
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional
public void createUser(String name, String email) {
User user = new User(name, email);
userRepository.save(user);
}
}
Здесь метод createUser() аннотирован как @Transactional, значит, метод save() в UserRepository выполнится внутри транзакции.
Преимущества @Transactional
- Упрощается управление транзакциями. С
@Transactionalне нужно писать стереотипный код, чтобы вручную создавать и контролировать транзакции. Об управлении ими позаботится Spring, остается написать бизнес-логику. - Обеспечиваются согласованность и целостность данных: благодаря транзакциям операции в базе данных выполняются атомарно.
- С транзакциями повышается производительность баз данных, так как сокращается количество циклов обмена данными между приложением и БД.
- Поддерживается декларативное программирование, с помощью которого указываются правила управления транзакциями. В итоге код получается более лаконичным и удобным для восприятия.
В чем основное отличие HashTable от ConcurrentHashmap?
Синхронизация
- В Hashtable на всю таблицу одна блокировка. Таблица единовременно доступна только одному потоку даже для чтения, в сценариях с высокой конкурентностью это чревато проблемами.
- В ConcurrentHashMap применяется блокировка на уровне сегментов с параллельными считываниями и ограниченными параллельными записями, чем значительно повышается производительность в многопоточных средах.
В чем основное отличие HashTable от Hashmap?
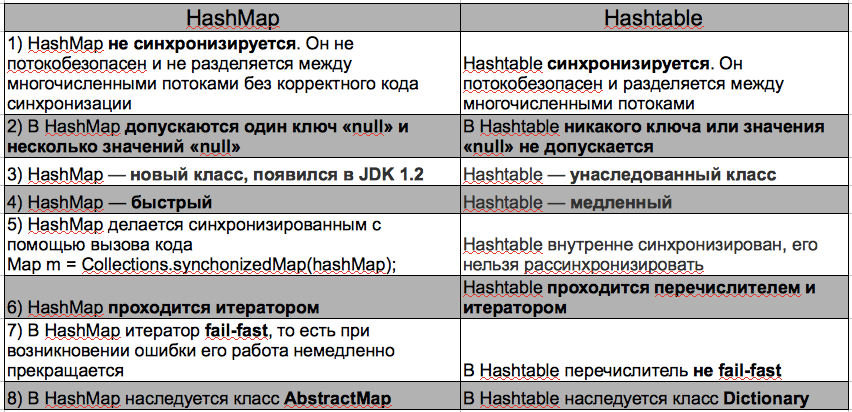
Как обнаружить утечку памяти в приложении?
Симптомы утечки памяти
- Серьезное снижение производительности при непрерывной долгой работе приложения.
- Ошибка динамической памяти OutOfMemoryError в приложении.
- Спонтанные, странные сбои приложений.
- В приложении иногда заканчиваются объекты подключения.
Для чего нужен Stringtokenizer?
Этим классом строка в приложении разбивается на токены. Такая токенизация намного проще, чем в классе StreamTokenizer, в методах которого не различаются идентификаторы, числа и закавыченные строки, не распознаются и опускаются комментарии.
Набор разделителей — символов, которыми разделяются токены, — задается во время создания либо для каждого токена в отдельности.
Поведение экземпляра StringTokenizer зависит от значения флага returnDelims, с которым он создавался.
- Если
false, этими символами токены разделяются. Токен — максимальная серия последовательных символов, которые не являются разделителями. - Если
true, сами символы-разделители считаются токенами. То есть токен — это символ-разделитель либо максимальная серия последовательных символов-неразделителей.
В разбиваемой на токены строке внутри объекта StringTokenizer сохраняется текущая позиция, которая некоторыми операциями перемещается дальше обработанных символов.
Из строки, использованной для создания объекта StringTokenizer, берется подстрока, и возвращается токен.
Вот пример кода с токенизатором:
StringTokenizer st = new StringTokenizer("this is a test");
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
Что такое SecurityContext в Spring?
В SecurityContext, получаемой от SecurityContextHolder, содержится Authentication уже аутентифицированного пользователя. Authentication — это учетные данные, введенные пользователем при аутентификации в AuthenticationManager или текущим пользователем из SecurityContext.
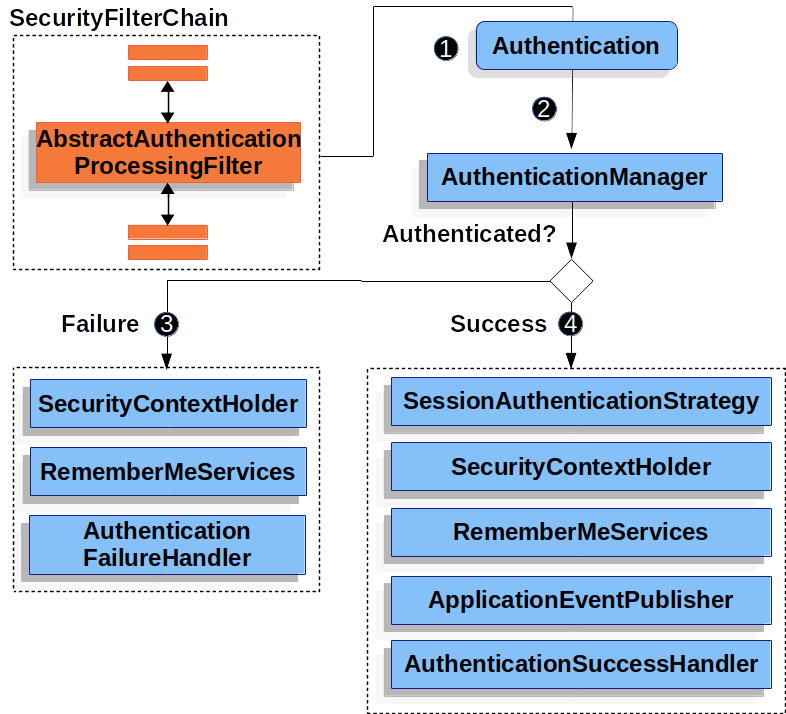
Чем отличается блокировка уровня объектов от блокировки уровня классов?
В конкурентном программировании, когда потокам доступны общие ресурсы, для поддержания согласованности данных необходима синхронизация. Она обеспечивается механизмами блокировки путем ограничения доступа к этим ресурсам, так что единовременно с ними работает только один поток. В объектно-ориентированных языках, таких как Java, имеется два основных подхода к блокировке: на уровне объектов и классов.
Блокировка на уровне объектов
- Применяется к отдельным объектам, с каждым объектом в Java связана уникальная блокировка.
- Достигается при помощи ключевого слова
synchronizedс нестатическими методами или блоками кода. - Метод
synchronizedв конкретном объекте единовременно выполняется только одним потоком. - Другие потоки при попытке получить доступ к тому же методу
synchronizedв том же объекте блокируются, пока блокировка не освободится. - Пригодна для синхронизации доступа к переменным экземпляра и методам объекта.
- Поддерживается детализация, становится возможным параллельный доступ к объектам одного и того же класса.
Блокировка на уровне классов
- Применяется ко всему классу, достигается при помощи ключевого слова
synchronizedсо статическими методами. - Статический метод класса
synchronizedвыполняется только одним потоком независимо от экземпляра объекта. - Все остальные потоки при попытке получить доступ к статическим методам
synchronizedблокируются. - Пригодна для синхронизации доступа к статическим переменным и методам класса.
- Шире уровень контроля, но намного выше и накладные расходы на производительность по сравнению с блокировкой на уровне объектов.
Где памяти расходуется больше: int или Integer?
В большинстве языков программирования int расходуется меньше памяти, чем Integer. И вот почему.
int— это примитивный тип данных и базовое целое значение, которым число напрямую сохраняется в памяти. Размер обычно фиксированный: в большинстве современных систем 4 байта, или 32 бита.Integer— это класс или объект, в языках вроде Java этим классом оборачивается значениеint. Кроме сохранения числа, им предоставляется дополнительная функциональность, например методы преобразования или операции из высшей математики. Отсюда и увеличенный расход памяти.
Что такое WeakHashMap?
Это специальная реализация интерфейса Map в Java. От обычной HashMap она отличается работой с ключами.
- Сохранение ключей. В WeakHashMap они сохраняются с помощью WeakReferences. То есть сами ключи не считаются сильными ссылками, которыми предотвращается сборка мусора.
- Автоматическое удаление. Когда единственная ссылка на ключ в WeakHashMap — слабая ссылка в самой карте, а других сильных ссылок на ключ нигде в программе нет, сборщиком мусора занимаемая ключом память высвобождается. В результате соответствующая пара «ключ-значение» автоматически удаляется из WeakHashMap.
Варианты применения WeakHashMap
- Реализация кэширования. WeakHashMap полезна для создания кэшей, откуда не используемые активно записи автоматически удаляются сборщиком мусора. Так совершенствуется управление памятью.
- Слабые ссылки. Связать данные с объектом, оставив сборку мусора, можно с помощью WeakHashMap.
В чем разница между интерфейсами Predicates, Supplier, Consumer и Function?
Популярный вопрос на собеседованиях с разработчиками Java.
Оставляем этот вопрос по базам данных и Hibernate без ответа — его нахождение будет вашим домашним заданием.
Разница между Callable и Runnable?
Runnable и Callable — интерфейсы Java для классов, экземпляры которых выполняются в потоке. Вот основные различия между ними.
Runnable
- Единственным методом
run()интерфейсаRunnableаргументы не принимаются, результаты не возвращаются.
public interface Runnable {
void run();
}
- Чтобы из объекта
Runnableвернулся результат или выбросилось проверяемое исключение, используется обходное решение: меняется переменная, видимая внеRunnable.
Callable
- Единственным методом
call()интерфейсаCallableвозвращается значение, выбрасывается исключение.
public interface Callable<V> {
V call() throws Exception;
}
Callableприменяется сExecutorService, которым возвращаетсяFuture— результат компиляции.
С Runnable в потоке выполняется вычисление без возвращения результата. Если нужно вернуть результат или при вычислении выбрасывается исключение, следует использовать Callable.
Разница между первичным и уникальным ключами?
Первичный ключ
Уникальность: первичный ключ — это столбец или набор столбцов в таблице, которым однозначно идентифицируется каждая строка. Для каждой строки в нем содержатся уникальные и отличные от null значения.
Значения null в столбцах первичного ключа не содержатся, в каждой строке таблицы должно быть значение первичного ключа.
Ограничения: в каждой таблице содержится только один первичный ключ для однозначной идентификации ее строк, используемый как отправная точка для связей с другими таблицами.
Автоматическая индексация: по умолчанию столбцы первичного ключа индексируются автоматически, отчего повышается производительность запросов.
Уникальный ключ
Уникальность значений в столбце или наборе столбцов обеспечивается ограничением уникального ключа. В отличие от первичного ключа, уникальным допускаются значения null. Если столбец помечен как уникальный, допускается только одно значение null.
Значения null в столбцах уникального ключа могут содержатся, но только по одному на каждый столбец.
Ограничения: в каждой таблице содержится несколько уникальных ключей, каждым из которых обеспечивается уникальность в пределах своего столбца или столбцов.
Автоматическая индексация: столбцы уникального ключа не индексируются автоматически, производительность запросов обычно повышается созданием индекса в этих столбцах вручную.
Для чего в базе данных триггеры?
Триггеры в базах данных — это как мини-программы, запускаемые автоматически в ответ на события вставки, обновления, удаления в таблице и используемые для:
- Проверки допустимости и целостности данных, их соответствия определенным правилам.
- Автоматизации задач, активации действий вроде уведомлений или вычислений, исходя из изменений данных.
- Контроля данных, отслеживания: кем, какие и когда внесены изменения.
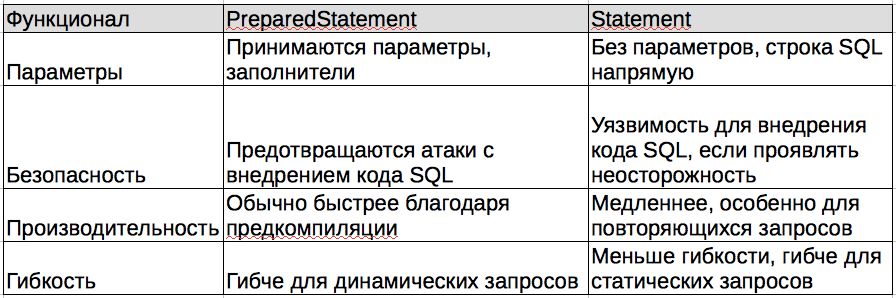
Разница между подготовленным оператором и оператором?
Разница между реляционной и нереляционной базами данных?
Вот основные их отличия.
Реляционная БД
- Данные хранятся в таблицах со связями между ними.
- Язык структурированных запросов SQL для доступа к данным и работы с ними.
- Предопределенная схема, структура данных для надежной целостности данных.
- Вертикально масштабируемая с добавлением более мощного аппаратного обеспечения.
- Хороша для сложных запросов и связанных данных.
Нереляционная БД
- Данные хранятся в различных форматах: документы, пары «ключ-значение», графы.
- Менее жесткая схема для гибких структур данных.
- Горизонтально масштабируемая с добавлением серверов.
- Большие неструктурированные наборы данных обрабатываются быстрее.
Что такое «индексирование баз данных»?
Это что-то вроде организованной системы расположения таблиц БД — специальная структура данных, с которой благодаря быстрому доступу к конкретной информации выборка данных значительно ускоряется.
В библиотеке, чтобы найти книгу, без индекса пришлось бы обыскать одну за другой все полки. Индекс в базе данных аналогичен библиотечному каталогу — им прямо указывается местоположение нужных данных, и без сканирования всей таблицы.
Что такое «сегментирование в базе данных»?
Это метод разделения базы данных на мелкие, более управляемые части — сегменты, которые затем распределяются по серверам или узлам. Вот как это делается.
- Представьте себе огромную книжную полку. Это база данных, заполненная книгами, то есть данными.
- Сегментирование все равно что разделение книжной полки — данные разбиваются на маленькие разделы по выбранным критериям: жанру, автору, дате публикации. Каждый раздел становится сегментом.
- Распределение сегментов. Затем каждый сегмент помещается на отдельный сервер, подобно распределению книг по категориям на разных полках в разных комнатах.
Разница между кэшем первого и второго уровней Hibernate?
В Hibernate производительность приложений повышается сокращением обращений к базе данных благодаря кэшу первого и второго уровней. Разберем их ключевые отличия.
Область действия
- Существование кэша первого уровня ограничивается одним сеансом Hibernate. Данные, загруженные одним запросом, доступны для последующих запросов в том же сеансе без повторного обращения к базе данных.
- Кэш второго уровня — дополнительный в рамках всего приложения и общий для всех сеансов Hibernate, связанных с одной и той же фабрикой сеансов. Загруженные в одном сеансе данные переиспользуются в других, чем значительно сокращается взаимодействие с базой данных.
Разница между Get и Load в Hibernate?
Стратегия извлечения данных
- get: для извлечения объекта, обнаруженного по идентификатору, выполняется немедленный запрос к базе данных.
- Имеющийся в базе данных объект возвращается как полностью заполненный.
- Если объекта нет, в
getвозвращаетсяnull. - load: обнаруженная сущность возвращается как объект-посредник.
- Фактические данные из базы данных извлекаются только при обращении к свойству или методу объекта, это называется отложенной загрузкой.
- Если объекта в базе данных нет, при попытке обращения к его свойствам в
loadвыбрасываетсяObjectNotFoundException.
Взаимодействие с базой данных
- get: всегда запускается запрос к базе данных, даже если объект уже в кэше первого уровня Hibernate.
- load: если объект в кэше, запрос к базе данных запускается не сразу, а только при обращении к данным объекта.
Разница между Save и Persist в Hibernate?
save
- Осуществляется попытка вставить в базу данных новую запись.
- Если объекту уже присвоен идентификатор — первичный ключ, в рамках операции обновления выполняется запрос на обновление.
- При необходимости сгенерированный идентификатор возвращается.
persist
- Объект помечается как управляемый в Hibernate для сохранения.
- Фактическая операция вставки происходит при фиксировании транзакции, не обязательно сразу же.
- Ничего не возвращается, void.
Контекст транзакции
- save: вызывается внутри или вне транзакции. Если вне, вставка выполняется сразу в зависимости от конфигурации Hibernate.
- persist: требуется вызывать внутри транзакции. Так обеспечивается согласованность данных, избегаются потенциальные проблемы.
Читайте также:
- Собеседование Java разработчика. Наиболее Часто Задаваемые Вопросы
- Эффективное ведение журнала для приложений Spring Boot
- Как определить цели разработчику программного обеспечения
Читайте нас в Telegram, VK и Дзен
Перевод статьи Ajay Rathod: Cisco Java Developer Interview Transcript 2024(Java,Spring-Boot,Hibernate)
 на Go. С Python в люльке")




