
Node.js известна как невероятно быстрая серверная платформа с революционной однопоточной архитектурой, позволяющей более эффективно использовать серверные ресурсы. Но возможно ли на самом деле достичь такой потрясающей производительности, используя только один поток? Ответ может вас удивить.
В этой статье раскроем все секреты и магию Node.js в предельно простой форме.
Процесс против потока
Для начала необходимо понять, что такое процесс и поток, а также выявить их различия и сходства.
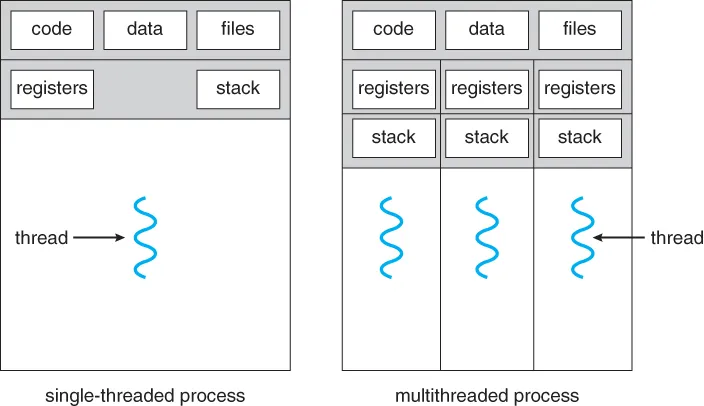
Процесс (process) — экземпляр программы, выполняемый в данный момент. Каждый процесс выполняется независимо от других. Процессы имеют несколько существенных ресурсов:
- код выполнения (execution code);
- сегмент данных (data segment) — область памяти, содержащая глобальные и статические переменные, которые должны быть доступны из любой части программы;
- кучу (heap) — область динамического выделения памяти;
- стек (stack) — область статического выделения памяти, содержащая локальные переменные, аргументы функций и вызовы функций;
- регистры (registers) — небольшие быстродействующие места хранения данных непосредственно в процессоре, используемые для временного хранения данных во время выполнения программ (например, указатель программы и указатель стека).
Поток (thread) — отдельная единица выполнения внутри процесса. В рамках процесса может быть несколько потоков, выполняющих различные операции одновременно. Стек и регистры выделяются отдельно для каждого потока, а код выполнения, данные и куча у всех потоков в процессе общие.
JavaScript не является поточным
Чтобы избежать недопонимания терминов, важно отметить, что сам JavaScript не является ни однопоточным, ни многопоточным. Язык не имеет никакого отношения к поточности. Это просто набор инструкций для платформы исполнения. Платформа обрабатывает эти инструкции по-своему — однопоточно или многопоточно.
Операции ввода/вывода
Операции ввода/вывода (или операции I/O) обычно считаются более медленными по сравнению с другими компьютерными операциями. Вот несколько примеров операций I/O:
- запись данных на диск;
- считывание данных с диска;
- ожидание ввода данных пользователем (например, щелчка мыши);
- отправка HTTP-запроса;
- выполнение операции с базой данных.
Вводы/выводы данных совершаются медленно
Возможно, вы задаетесь вопросом: почему чтение данных с диска считается медленным? Ответ кроется в физической реализации аппаратных компонентов.
Доступ к оперативной памяти занимает примерно наносекунду, в то время как доступ к данным на диске или в сети — примерно миллисекунду.
То же самое относится и к пропускной способности. Скорость передачи данных в оперативной памяти стабильно составляет порядка ГБ/с, в то время как на диске или в сети — от МБ/с до оптимально возможных ГБ/с.
Кроме того, необходимо учитывать человеческий фактор. Во многих случаях ввод данных в приложение выполняется реальным человеком (например, нажатие клавиши). Поэтому скорость и частота ввода-вывода зависит не только от технических аспектов.
Вводы/выводы данных блокируют поток
Ввод/вывод может значительно замедлить работу программы. Поток остается заблокированным, и никакие дальнейшие операции не будут выполняться до тех пор, пока ввод/вывод не будет завершен.
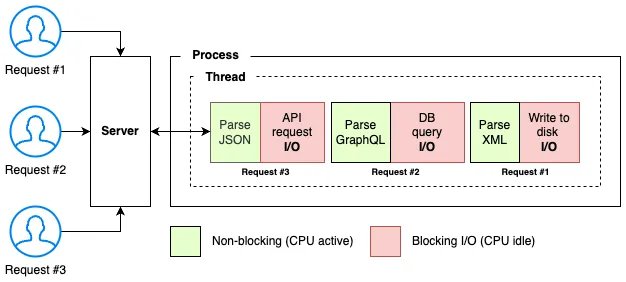
А что, если создать больше потоков?
Почему бы просто не создать больше потоков внутри программы и не обрабатывать каждый запрос отдельно? Кажется, это хорошая идея. У каждого клиентского запроса будет свой поток, и сервер сможет обрабатывать несколько запросов одновременно.
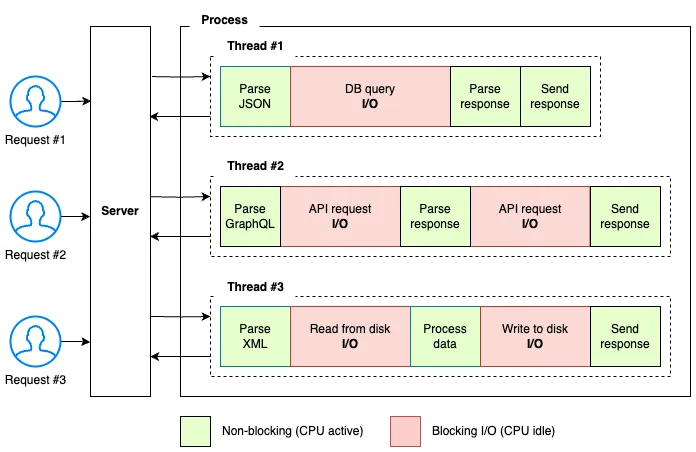
Программа должна выделять дополнительную память и ресурсы процессора для каждого потока. Это звучит разумно. Однако при выполнении потоками операций ввода-вывода возникает серьезная проблема — процессор простаивает и большую часть времени использует 0% ресурсов, ожидая завершения операции. Чем больше потоков, тем больше ресурсов используется неэффективно.
Кроме того, управление потоками — сложная задача, приводящая к потенциальным проблемам, таким как условия гонки, мертвые и живые блокировки. Операционная система должна переключаться между потоками, что может привести к дополнительным накладным расходам и снижению эффективности многопоточности.
Каково решение?
К счастью, человечество уже изобрело умные механизмы для эффективного выполнения подобных операций.
Один из них — демультиплексор событий (Event Demultiplexer). Он включает процесс, называемый мультиплексированием — метод, с помощью которого сигналы объединяются в один сигнал через общий ресурс. Цель состоит в том, чтобы сделать дефицитный ресурс совместно используемым (в нашем случае это процессор и оперативная память). Например, в телекоммуникациях по одному проводу может передаваться несколько телефонных звонков.

В обязанности демультиплексора событий входят следующие действия:
- идентификация источников событий: каждый источник может генерировать события;
- регистрация источников событий: включает указание событий, которые необходимо отслеживать для каждого источника;
- ожидание событий;
- отправление уведомлений о событиях.
Важно! Демультиплексор событий — это не компонент или устройство, которое существует в реальном мире. Это скорее теоретическая модель, используемая для объяснения того, как эффективно обрабатывать множество одновременных событий.
Чтобы понять этот сложный процесс, вернемся в прошлое. Представьте старый телефонный коммутатор: он идентифицирует и регистрирует источники событий (телефоны) и ожидает новых событий (звонков). Как только происходит новое событие (звонок), коммутатор выдает уведомление (зажигает лампочку). Затем оператор коммутатора реагирует на уведомление, проверяя номер целевого телефона и перенаправляя звонок по назначению.

Компьютеры работают по тому же принципу. Однако роль источников событий играют дескрипторы файлов, сетевые сокеты, таймеры или устройства ввода пользователя. Каждый источник может генерировать такие события, как данные, доступные для чтения, место, доступное для записи, или запросы на подключение.
В каждой операционной системе уже реализован механизм демультиплексора событий: epoll (Linux), kqueue (macOS), порты событий (Solaris), IOCP (Windows).
Но Node.js является кроссплатформенным. Чтобы управлять всем этим процессом, поддерживая кроссплатформенный ввод-вывод, существует слой абстракции, который инкапсулирует все эти межплатформенные и внутриплатформенные сложности и предоставляет обобщенный API для верхних уровней Node.
Libuv — ключевая библиотека Node.js

Добро пожаловать в libuv — кроссплатформенную библиотеку (написанную на C), изначально разработанную для Node.js, чтобы обеспечить согласованный интерфейс для неблокирующего ввода-вывода в различных операционных системах. Libuv не только взаимодействует с системным демультиплексором событий, но и включает два важных компонента: очередь событий (Event Queue) и цикл событий (Event Loop). Эти компоненты работают вместе для эффективной обработки одновременно выполняемых неблокирующих ресурсов.
Очередь событий — структура данных, в которую демультиплексор событий помещает все события, готовые к постановке в очередь и последовательной обработке циклом событий до тех пор, пока очередь не опустеет.
Цикл событий — непрерывно выполняющийся процесс, который ожидает сообщения в очереди событий и затем отправляет их соответствующим обработчикам.
Проблема решена?
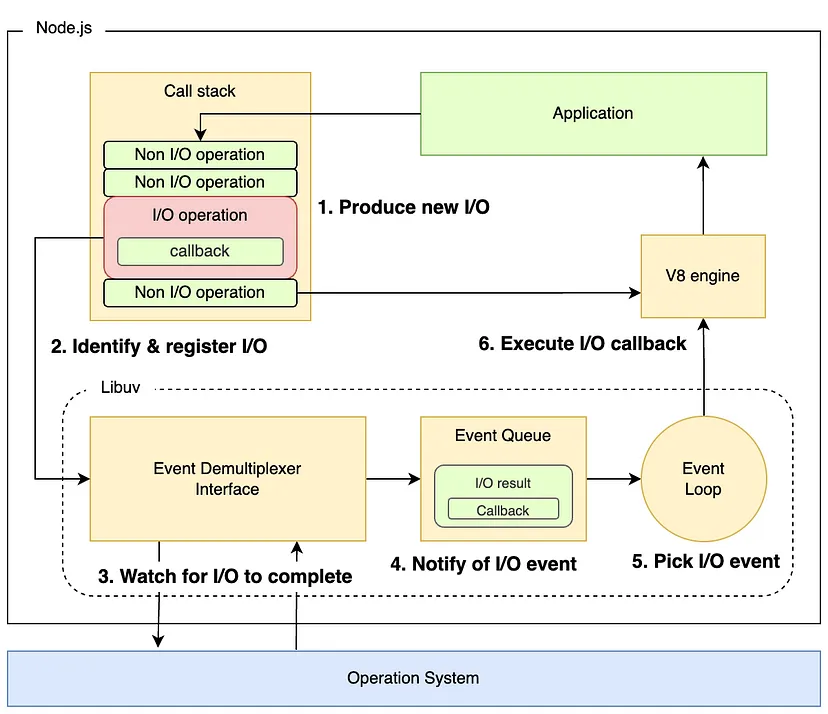
Вот что происходит при вызове операции ввода-вывода:
- libuv инициализирует соответствующий демультиплексор событий в зависимости от операционной системы;
- интерпретатор Node.js сканирует код и помещает каждую операцию в стек вызовов;
- Node.js последовательно выполняет операции в стеке вызовов, однако для операций ввода-вывода Node.js отправляет их в демультиплексор событий неблокирующим способом — такой подход гарантирует, что операция ввода/вывода не блокирует поток, позволяя другим операциям выполняться параллельно;
- демультиплексор событий идентифицирует источник операции ввода-вывода и регистрирует ее с помощью средств ОС;
- демультиплексор событий непрерывно отслеживает источник (например, сетевые сокеты) на предмет событий (например, когда данные доступны для чтения);
- когда событие происходит (например, данные становятся доступными для чтения), демультиплексор событий подает сигнал и добавляет событие с соответствующим обратным вызовом в очередь событий;
- цикл событий постоянно проверяет очередь событий и обрабатывает обратный вызов события.
Node.js делает так: пока один запрос ожидает, он может обрабатывать другой запрос. Node.js не ждет завершения запроса перед обработкой всех остальных запросов. По умолчанию все запросы в Node.js выполняются одновременно: ни один из них не ждет завершения других запросов перед выполнением.
Похоже, проблема решена. Node.js может эффективно работать в один поток, поскольку большинство сложностей блокировки операций ввода-вывода были решены разработчиками ОС.
Проблема не решена
Но если присмотреться к структуре libuv, обнаружится интересный аспект:
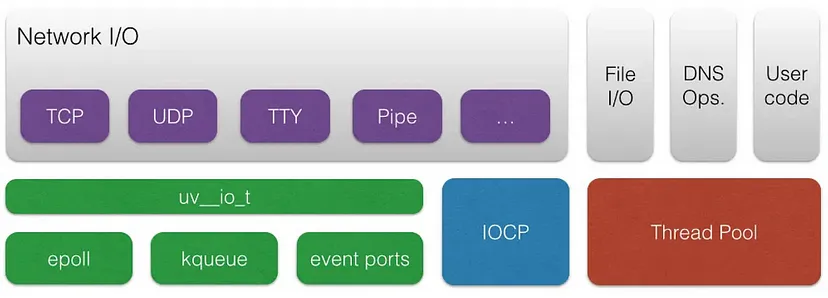
Что это? Пул потоков (Thread Pool)? Да, теперь мы погрузились достаточно глубоко, чтобы ответить на главный вопрос: почему Node.js не является (полностью) однопоточным?
Раскрываем секрет
Итак, мощный инструмент и утилиты ОС позволяют запускать асинхронный код в одном потоке.
Но есть проблема с демультиплексором событий. Поскольку его реализация в каждой ОС своя, некоторые операции ввода-вывода не полностью поддерживаются с точки зрения асинхронности. Сложно поддерживать все типы ввода-вывода во всех типах платформ ОС. Эти проблемы особенно касаются реализации файлового ввода/вывода. Они также оказывают влияние на некоторые функции DNS в Node.js.
Более того, есть и другие типы операций ввода/вывода, которые не могут быть выполнены асинхронно, например:
- операции DNS, такие как
dns.lookup, подвержены блокировке, потому что им требуется запрос к удаленному серверу;
- задачи, связанные с процессором, например криптография;
- сжатие ZIP-файлов.
Для таких случаев используется пул потоков, чтобы выполнять операции ввода-вывода в отдельных потоках (обычно по умолчанию их 4). Поэтому полная схема архитектуры Node.js будет выглядеть следующим образом:
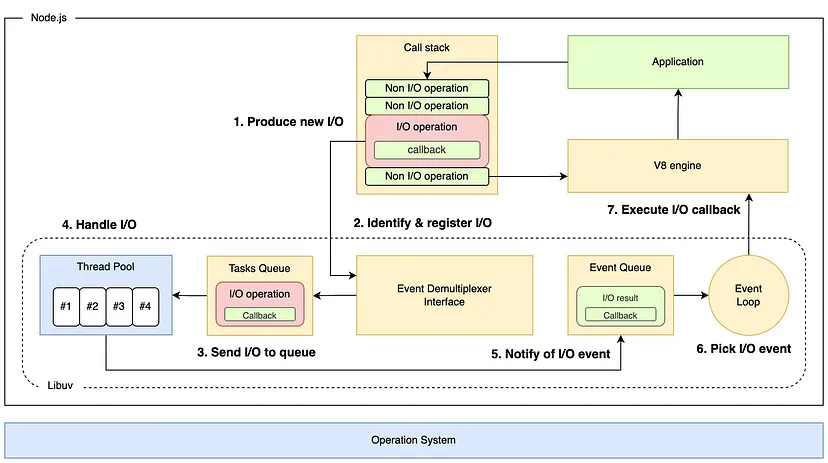
Да, сам Node.js однопоточный, но библиотеки, которые он использует, такие как libuv с ее пулом потоков для некоторых операций ввода-вывода, не являются таковыми.
Пул потоков (Thread Pool) в сочетании с очередью задач (Tasks Queue) используется для обработки блокирующих операций ввода-вывода. По умолчанию пул потоков включает 4 потока, но это поведение можно изменить, задав дополнительную переменную среды:
UV_THREADPOOL_SIZE=8 node my_script.js
Вот что происходит, когда операция ввода-вывода не может быть выполнена асинхронно, но ключевые отличия заключаются в следующем:
- когда демультиплексор событий определяет источник операции ввода-вывода, он регистрирует ее в очереди задач;
- пул потоков постоянно отслеживает очередь задач на предмет появления новых задач;
- когда новая задача помещается в очередь задач, пул потоков реагирует на нее, асинхронно обрабатывая ее одним из заранее определенных потоков;
- после завершения операции пул потоков подает сигнал и добавляет событие с соответствующим обратным вызовом в очередь событий.
Здесь нет никакой магии. Фактически, ввод-вывод не может быть не блокирующим, и способа изменить это не существует (по крайней мере, пока). Данные не могут передаваться быстрее, чем это продиктовано физическими ограничениями. Нет ничего идеального, поэтому, пока мы не найдем способов увеличить скорость передачи данных на аппаратном уровне, будем использовать набор оптимизированных алгоритмов для выполнения асинхронных операций наиболее эффективным способом.
Читайте также:
- Комплексное руководство по Node.js для разработчиков всех уровней
- Загрузка больших видео с помощью Node.js
- Делаем Node.js быстрым: инструменты, техники и советы для создания эффективных серверов на Node.js Часть первая.
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tkachenko Evgeny: Node.js is Not Single-Threaded





