
Node очень универсальная платформа, однако именно создание сетевых процессов одно из основных её применений. В этой статье мы сосредоточимся на профилировании наиболее распространённого из них: веб-сервера HTTP.
Если вы достаточно долго работали с Node.js, тогда вы наверняка сталкивались с неожиданными проблемами быстродействия. JavaScript событийный, асинхронный язык. Это затрудняет рассуждения о производительности, позже мы в этом убедимся. Растущая популярность Node.js выявила необходимость в инструментах, методах и мышлении, подходящих для ограничений серверного JavaScript.
Если говорить о производительности, то, что работает в браузере, не всегда подходит для Node.js. Так, как же нам убедиться, что реализация Node.js быстра и соответствует задаче? Давайте рассмотрим практический пример.
Нам понадобится инструмент, который сможет нагрузить сервер большим количеством запросов для измерения производительности. Например, мы можем использовать AutoCannon:

Apache Bench (ab) и wrk2 также хорошие инструменты для подобных целей, но AutoCannon написан на Node. Он обеспечивает аналогичную (или иногда большую) нагрузку и очень прост в установке на Windows, Linux и Mac OS X.
После того, как мы измерили базовую производительность, и решили, что процесс можно ускорить, нам понадобится какой-то способ диагностики проблем с процессом. Отличным инструментом для диагностики различных проблем производительности является Node Clinic, который также может быть установлен с помощью npm:

Эта команда установит пакет инструментов. А мы в примере будем использовать Clinic Doctor и Clinic Flame (wrapper 0x).
Примечание: для этого практического примера нам понадобится Node 8.11.2 или выше.
Код
В нашем примере это простой REST-сервер с одним ресурсом: большим JSON файлом с полезной нагрузкой, вызываемый запросом GET из /seed/v1. Наш сервер в папке app, в ней находятся файлы package.json (зависит от restify 7.1.0), index.js и util.js.
index.js файл для нашего сервера выглядит так:

Этот типичный сервер для обслуживания динамического контента, который кэшируется на стороне клиента. Это достигается с помощью etaggermiddleware, который вычисляет ETag загаловок для последнего состояния содержимого.
Файл util.js предоставляет исполняющие части, которые обычно используются в подобных сценариях, функцию для извлечения релевантного контента из бэкенда, etag middleware и функцию timestamp, которая выдаёт тайм метки поминутно:

Однако этот код не лучший вариант для практики! В этом коде есть несколько проблем, мы найдем их по ходу измерений и профилирования приложения.
Чтобы получить полный исходный код для нашей отправной точки, «медленный» сервер можно найти здесь.
Профилирование
Чтобы начать профилировать, нам нужны 2 терминала, один для запуска приложения, а другой для тестирования нагрузкой.
На одном терминале, из папки app мы можем запустить:

На другом терминале профилировать его так:

Это откроет 100 одновременных соединений и бомбардирует сервер запросами в течение десяти секунд.
Результаты должны быть примерно такими (запуск теста 10сек @ http://localhost:3000/seed/v1–100 соединений):
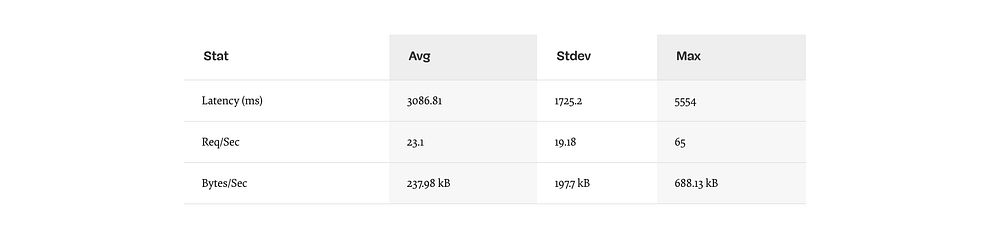
231 запрос за 10 секунд, 2,4 МБ чтения
Результаты будут отличаться в зависимости от машины. Однако, учитывая, что “Hello World” Node.js сервер легко обработает и тридцать тысяч запросов в секунду на этой машине, 23 запроса в секунду со средней задержкой, превышающей 3 секунды — это печально.
Диагностируем
Обнаруживаем проблемные места
Мы можем провести диагностику приложения всего одной командой -on-port, благодаря Clinic Doctor. Из папки app мы запускаем:

Это создаст HTML-файл, который автоматически откроется в нашем браузере после завершения профилирования.
Результаты должны выглядеть примерно так:
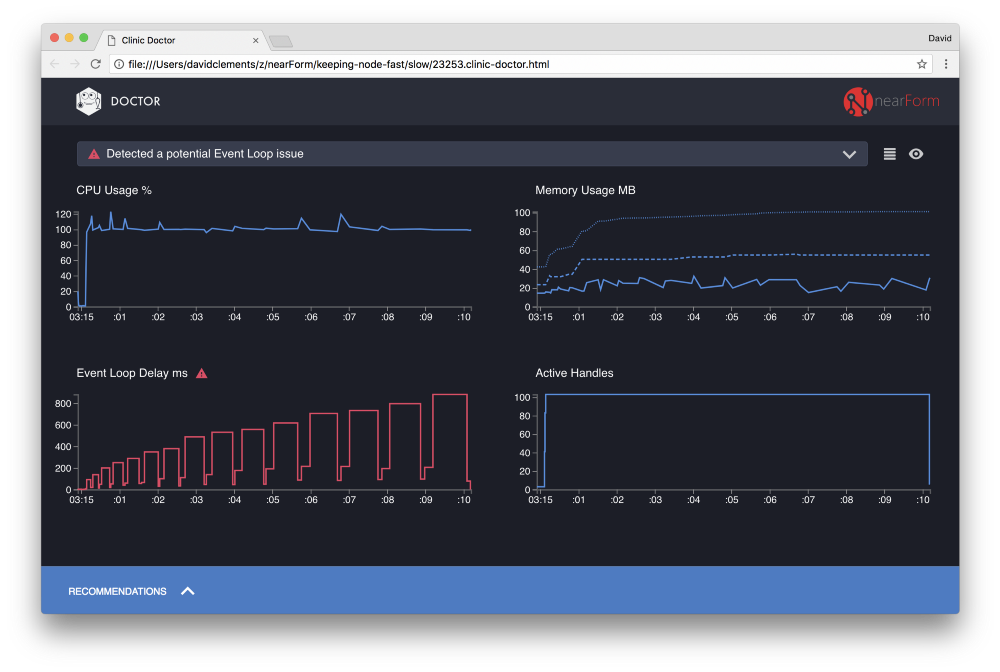
«Доктор» говорит нам, что у нас, вероятно, была проблема с циклом событий (Event Loop).
Вместе с сообщением в верхней части UI, мы также можем видеть, что диаграмма Event Loop красного цвета, и показывает постоянно увеличивающуюся задержку. Прежде чем мы углубимся в значение этого показателя, давайте сначала разберемся какой эффект оказывает эта проблем на остальные метрики.
Мы видим, что процессор стабильно находится на уровне или выше 100%, пока процесс упорно обрабатывает запросы из очереди. JavaScript движок Node.js (V8) в этом случае фактически использует два ядра процессора, потому что машина многоядерная и V8 использует два потока. Один для цикла обработки событий, а другой для «сбора мусора». Там, где мы видим пики нагрузки вплоть до 120% — это процесс собирает объекты, связанные с обработанными запросами.
Мы видим эту корреляцию на графике Memory. Сплошная линия на диаграмме Memory — это метрика Heap Used. Каждый раз, когда есть всплеск ЦП, мы видим проседание Heap Used, это показывает, что память освобождается.
Задержки Event Loop не повлияли на график Active Handles. Active Handle — это объект, представляющий ввод-вывод (например сокет или file handle) или таймер (например, setInterval). Мы поручили AutoCannon открыть 100 соединений (-c100). Active Handles постоянно остаётся на уровне 103. Остальные три — это дескрипторы STDOUT, STDERR и дескриптор самого сервера.
Если щелкнуть панель Recommendations в нижней части экрана, мы увидим примерно следующее:
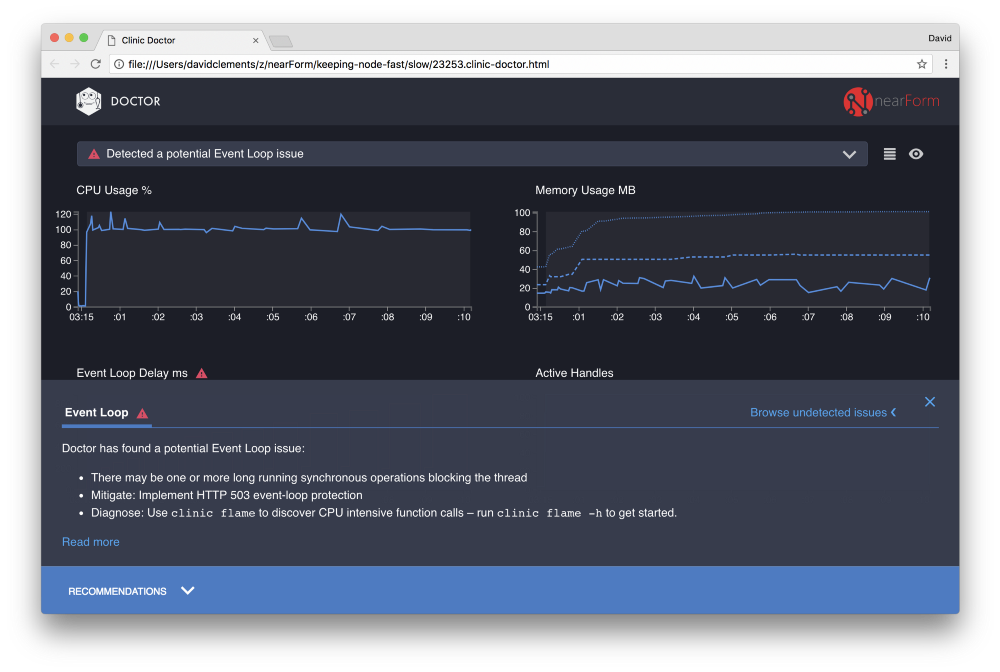
Временный меры
Анализ основных причин, серьезных проблем с производительностью, может занять некоторое время. В случае уже развернутого проекта стоит добавить защиту от перегрузки на серверы или службы. Идея защиты от перегрузки состоит в том, чтобы контролировать задержку Event Loop (помимо прочего) и отвечать ошибкой “503 Service Unavailable”, если порог пройден. Это позволяет балансировщику нагрузки переключаться на другие инстансы или в худшем случае пользователям придется обновлять страницу. Модуль защиты от перегрузки может обеспечить это с минимальным оверхедом для Express, Koa, и Restify. Фреймфорк Hapi может обеспечить такую же защиту с помощью настройки конфигурации.
В продолжении статьи, после диагностики производительности с помощью Clinic Doctor, мы приступим к анализу метрик используя flame graph. Найдём проблемные места в нашем коде и начнём его исправлять.
Перевод статьи: David Mark Clements Keeping Node.js Fast: Tools, Techniques, And Tips For Making High-Performance Node.js Servers





