
В самом начале, еще до моего прихода, в Urb-it основой облачной стратегии решили сделать Kubernetes. Это было обусловлено грядущим быстрым масштабированием и желанием получить более динамичную, отказоустойчивую, эффективную среду приложений, воспользовавшись возможностями оркестрации контейнеров. И Kubernetes хорошо вписался в нашу микросервисную архитектуру.
Преждевременное решение?
Не поторопились ли с решением, ведь его принятие предполагает большую зависимость и значительный объем знаний, необходимых стартапу или любой компании? Да и сталкивались ли мы на том этапе с проблемами, решаемыми Kubernetes? Вначале могли бы обойтись монолитом изменяемого размера, а с масштабированием и появлением проблем — перейти на Kubernetes или что-то еще. Тогда эта технология только начинала разрабатываться. Но об этом как-нибудь в другой раз.
8 лет в продакшене
За более чем восемь лет запуска Kubernetes в продакшене — отдельный кластер для каждой среды — мы принимали как хорошие решения, так и не очень хорошие. Одни ошибки были просто результатом неудачных решений, другие — отсутствия полного или даже частичного понимания самой этой технологии. Помимо мощи, Kubernetes отличается немалой сложностью.
Мы пошли напролом без какого-либо опыта ее запуска в условиях масштабирования.
Переход с самоуправляемого в AWS к управляемому в Azure AKS
В первые годы мы запускали самоуправляемый кластер в AWS. Насколько я помню, сначала у нас не было возможности использовать Azure Kubernetes Service AKS, Google Kubernetes Engine GKE, Amazon Elastic Kubernetes Service EKS, так как официального управляемого решения еще не предоставлялось. Именно на Amazon Web Services AWS, где кластеры размещаются на своих же хостингах, произошел первый, самый ужасный сбой кластера в истории Urb-it.
Небольшой команде трудно уследить за всеми новыми, нужными ей возможностями. В то же время для управления кластером, размещаемым на собственном хостинге, требовались постоянное внимание и тщательность, отчего увеличивалась рабочая нагрузка.
Когда же управляемые решения стали общедоступными, нам потребовалось время на оценку AKS, GKE и EKS. Все они оказались в разы лучше, нежели самостоятельное управление кластером, так что быстрый экономический эффект от перехода был очевиден.
В то время наша платформа на 50% состояла из .Net и на 50% из Python, и мы уже использовали Azure Service Bus, Azure SQL Server, другие службы Azure. Поэтому, перенося кластер на Azure, мы не только упрощали их интегрированное применение, но и извлекали пользу от использования базовой сетевой инфраструктуры Azure, избегая затрат, связанных с выходом/входом во внешние сети и виртуальные сети VNET, которые у нас были при смешанной настройке AWS и Azure. Кроме того, многим нашим инженерам знакома Azure с ее экосистемой.
Стоит также упомянуть об экономии на узлах: в первоначальной настройке AKS мы не платили за узлы плоскости управления/ведущие узлы, что было дополнительным бонусом.
Мы мигрировали зимой 2018-го и, хотя за эти годы проблемы с AKS случались, ни разу не пожалели о переходе.
Сбой кластера № 1
В период самостоятельного управления на AWS мы столкнулись с большим сбоем кластера, в результате чего произошло падение большинства наших систем и продуктов. Истек срок действия сертификатов: корневого центра сертификации, etcd и сервера API. Поэтому прекратилась работа кластера, управлять им стало невозможно. Поддержка для устранения этой проблемы в kube-aws тогда была ограниченной. Мы привлекли эксперта, но в итоге весь кластер пришлось воссоздавать с нуля.
Мы думали: в каждом гит-репозитории имеются все значения и чарты Helm. Оказалось, что это относится не ко всем службам. Кроме того, не сохранилось ни одной конфигурации для создания кластера. Времени на то, чтобы снова настроить его и заполнить всеми нашими сервисами и продуктами, было мало. Для некоторых из них, чтобы создать недостающие конфигурации, требовалось заново придумывать чарты Helm. Были моменты, когда мы спрашивали друг друга: «Помнишь, сколько ресурсов процессора или оперативной памяти должно использоваться этой службой?», «Какой у нее доступ к сети и порту?». И я еще не говорю о секретах, которые все исчезли.
Прошел не один день, прежде чем мы снова запустили кластер. Не лучший момент для гордости, мягко говоря.
Благодаря проактивной коммуникации, поддержанию прозрачности, честности и развитию отношений мы не потеряли ни бизнес, ни клиентов.
Сбой кластера № 2
Уроки первого сбоя были учтены, так что второй не мог произойти из-за сертификата? И да, и нет. Когда после первого сбоя воссоздавали кластер, в конкретной версии применявшегося нами kube-aws возникла проблема. При создании этим инструментом новых кластеров вместо того, чтобы задать предусмотренную дату истечения срока действия сертификата etcd, оставлено значение по умолчанию — один год. Поэтому ровно через год срок действия сертификата истек, и произошел еще один сбой кластера. На этот раз восстановиться было легче, не пришлось создавать все заново. Но мы пережили адские выходные.
Примечание 1: другие компании пострадали от этого бага так же, как и мы, но нашим клиентам это не помогло…
Примечание 2: мы планировали обновить все сертификаты через год и, предусмотрев запас времени, установили срок действия два года. Поэтому, не случись этого бага, они были бы обновлены.
С 2018-го сбоев кластера больше не было… И быть не должно.
Извлеченные уроки
Kubernetes сложен
Нужны инженеры, желающие работать с инфраструктурными и операционными аспектами Kubernetes. В нашем случае это пара инженеров, которые, помимо исполнения своих прямых обязанностей, при необходимости привлекались бы как эксперты по Kubernetes. В разных задачах Kubernetes рабочая нагрузка разная. В одни недели делать было почти нечего, в другие, например во время обновления кластера, требовалось больше внимания.
Распределить работу с поочередным ее выполнением всей командой было невозможно: технология слишком сложна, чтобы на неделю «включаться» в работу и на неделю «выключаться» из нее. Конечно, каждый должен знать, как ею пользоваться — развертывание, отладка и т. д., — но аспектам посложнее необходимо выделять определенное время. Кроме того, важен руководитель со своим видением и стратегией развития кластера.
Сертификаты Kubernetes
Важно вникать в детали внутренних сертификатов Kubernetes, следить за датами истечения срока их действия, ведь оба сбоя кластера произошли из-за истечения срока действия сертификатов.
Поддержание Kubernetes и Helm в актуальном состоянии
Отставание становится дорогим и утомительным. Прежде чем переходить на последнюю версию, мы всегда выжидали пару месяцев, чтобы с любыми проблемами новой версии первыми сталкивались другие. Но даже при поддержании в актуальном состоянии приходилось иметь дело со множеством времязатратных переписываний конфигурационных файлов и чартов из-за новых версий Kubernetes и Helm: переход API Kubernetes с альфа на бету, с бета-версии на 1.0 и т. д. Знаю, что Саймону и Мартину все изменения Ingress очень понравились.
Централизованные чарты Helm
Когда дело дошло до Helm, нам надоело при каждом изменении версии обновлять все 70 с лишним чартов, поэтому мы применили более универсальный подход, при котором «все они управляются одним чартом». Помимо достоинств, у такого подхода с централизованными чартами Helm имеются и недостатки. Тем не менее для наших задач он в итоге оказался оптимальнее.
План аварийного восстановления
Не могу не обратить на это внимание: обязательно обзаведитесь способами воссоздать кластер в случае такой необходимости. Да, вы можете создавать новые кластеры, щелкая по пользовательскому интерфейсу, но такой подход в условиях масштабирования или в установленные сроки ни разу не рабочий.
Имеются различные способы воссоздания кластеров: от простых скриптов оболочки до продвинутых методов вроде Terraform. Применяется также Crossplane для управления инфраструктурой как кодом и другие.
Из-за ограниченной пропускной способности команды мы остановились на хранении и использовании скриптов оболочки.
Какой бы способ вы ни выбрали, время от времени обязательно тестируйте поток, обеспечивая возможность при необходимости воссоздать кластер.
Резервное копирование секретов
Обзаведитесь стратегией резервного копирования и хранения секретов. Если кластер исчезнет, пропадут все секреты. И поверьте, мы узнали это на собственном опыте: чтобы все исправить, требуется много времени, когда у вас различные микросервисы и внешние зависимости.
Несколько поставщиков или один
Вначале, после перехода на AKS, мы старались сохранить кластер независимым от поставщика, продолжая пользоваться другими сервисами для реестра контейнеров, аутентификации, хранилищ ключей и т. д. и имея возможность легко перейти на другое управляемое решение. Хотя независимость от поставщика — отличная идея, для нас это высокие альтернативные издержки. Вскоре мы решили поставить все на продукты Azure, связанные с AKS: реестр контейнеров, сканирование безопасности, аутентификация и т. д. В итоге усовершенствовался процесс разработки, благодаря централизованному управлению доступом с Azure Entra Id стала проще безопасность, сократились время вывода продукта на рынок и затраты — за счет объема.
Определения клиентских ресурсов
Да, мы поставили все на продукты Azure, но нашим принципом стало: иметь как можно меньше определений клиентских ресурсов и использовать встроенные ресурсы Kubernetes. Но были и исключения вроде Traefik, поскольку API Ingress соответствовал не всем нашим задачам.
Безопасность
См ниже.
Наблюдаемость
См ниже.
Предварительное масштабирование во время известных пиков
Даже со средством автомасштабирования мы иногда масштабировались слишком медленно. Мы логистическая компания, и в праздничные дни у нас бывают пики. Используя данные трафика и общеизвестные факты, за день до наступления пика мы масштабировали кластер вручную с помощью ReplicaSet, а на следующий день уменьшали его, но медленно, чтобы справиться со второй волной пиков.
Drone внутри кластера
Мы хранили систему сборки Drone в промежуточном кластере, у которого, помимо преимуществ, имелись и недостатки. Ее было легко масштабировать и использовать, поскольку она находилась в том же кластере. Однако при слишком масштабной одновременной сборке потреблялись почти все ресурсы, в итоге в Kubernetes стремительно развертывались новые узлы. Вероятно, лучше было бы использовать ее как чисто SaaS-решение, не беспокоясь о размещении и сопровождении самого продукта.
Выбор правильного типа узла
Это в значительной степени определяется контекстом, но в зависимости от типа узла в AKS для внутренних служб резервируется от 10 до 30% доступной памяти. То есть нам было выгодно использовать меньшее количество типов узлов, но покрупнее. Кроме того, поскольку мы запускали .Net во многих службах, нужно было выбрать типы узлов с эффективным и изменяемым по размеру вводом-выводом. В .Net часто выполняются записи на диск для JIT и логирования. Если для этого требуется доступ к сети, все замедляется. Мы также позаботились о том, чтобы размер дискового кэша узла был не меньше общего размера сконфигурированного диска узла, чтобы, опять же, предотвратить необходимость сетевых скачков.
Зарезервированные экземпляры
Да, такой подход немного расходится с таким свойством облака, как гибкость. Но для нас резервирование экземпляров ключей на год-два обернулось значительной экономией. Во многих случаях мы экономили 50–60% по сравнению с подходом «плати по мере использования». Для команды это немало.
k9s
https://k9scli.io/ — отличный инструмент для тех, кто хочет абстракцию на уровень выше, чем чистый kubectl.
Наблюдаемость
Мониторинг
Отслеживайте использование памяти, процессора и т. д. с течением времени, наблюдая за работой кластера и определяя, увеличивается или уменьшается его производительность с применением новых возможностей. Благодаря этому легче находить и устанавливать «корректные» ограничения для разных подов. Важно найти правильный баланс, поскольку под уничтожается, если у него заканчивается память.
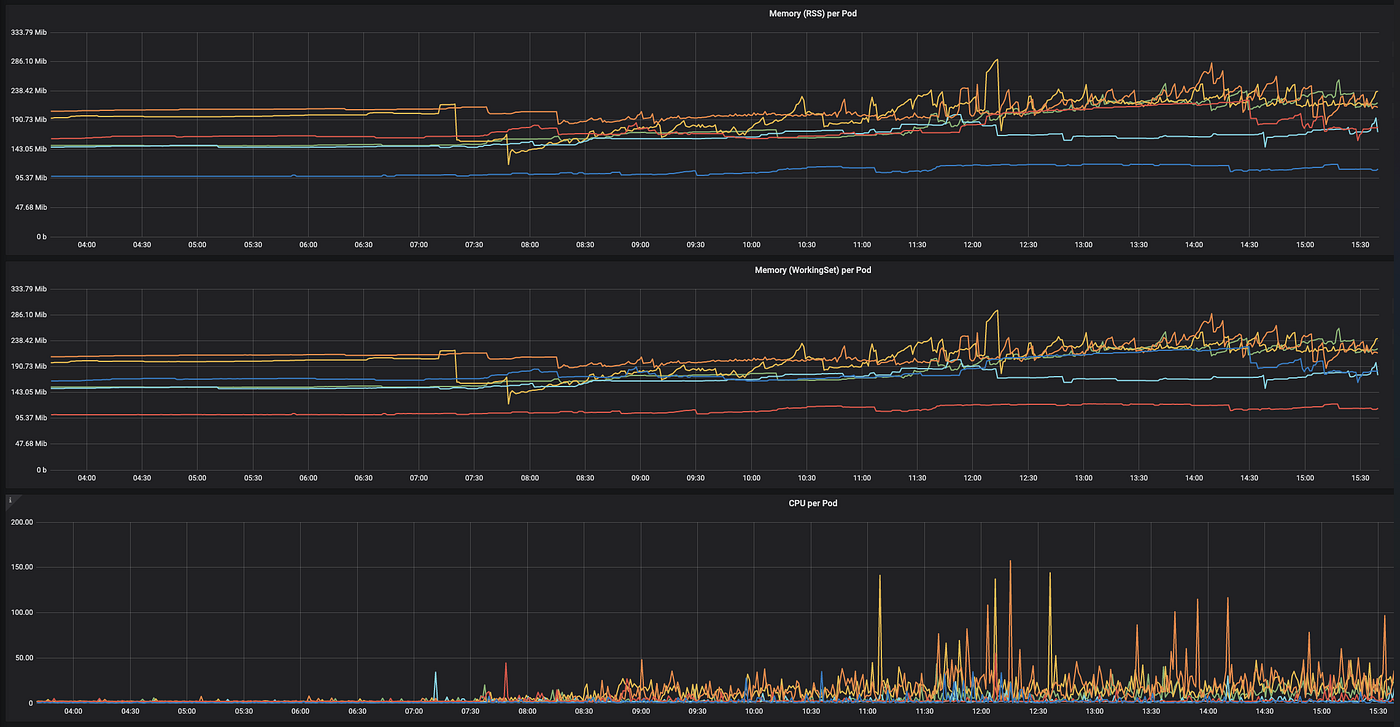
Предупреждения
Настройка системы предупреждения была процессом, но в итоге мы направили все предупреждения в наши каналы Slack. При таком подходе стало удобно получать уведомления всякий раз, когда в работе кластера возникали неожиданности или непредвиденные проблемы.

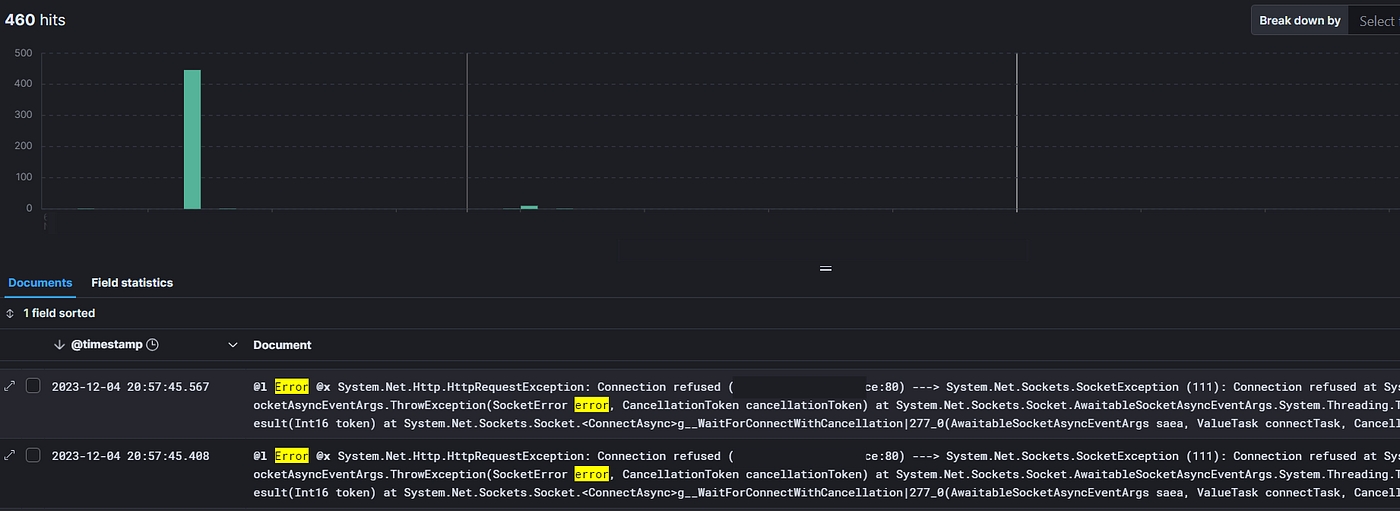
Логирование
Объединение всех логов в одном месте и надежная стратегия идентификации трассировок, например OpenTelemetry, важны для любой микросервисной архитектуры. Мы разобрались с этим за два-три года. Реализовав это пораньше, мы сэкономили бы очень много времени.
Безопасность
Безопасность в Kubernetes — обширная тема, настоятельно рекомендую тщательно изучить все ее нюансы, например ознакомиться с Руководством по укреплению безопасности Kubernetes, выпущенным NSA и CISA. Ниже приводим ключевые моменты из нашего опыта, но это далеко не все нюансы.
Контроль доступа
Если вкратце, Kubernetes не является чрезмерно ограничительной по умолчанию. Поэтому мы потратили значительное время на ужесточение доступа, внедрив принципы наименьших привилегий для подов и контейнеров. Кроме того, из-за специфических уязвимостей непривилегированный злоумышленник потенциально мог повысить свои привилегии до root, обходя ограничения пространства имен Linux, а в некоторых случаях, чтобы получить доступ с правами root к узлу хоста, даже выйти из контейнера. Нехорошо, мягко говоря.
Нужно установить корневую файловую систему только для чтения, отключить автоматическое монтирование токена учетной записи службы, отключить повышение привилегий, удалить все ненужные возможности и т. д. Конкретно в нашей настройке, чтобы не развертывались небезопасные контейнеры, мы используем политику Azure и привратник Gatekeeper.
Чтобы дополнительно усовершенствовать безопасность и контроль доступа нашей настройки Kubernetes в AKS, мы применили надежность управления доступом на основе ролей.
Уязвимость контейнера
Для сканирования и проверки контейнеров и других частей Kubernetes имеется много хороших инструментов. Для части наших задач мы использовали Azure Defender и Azure Defender для контейнеров.
Примечание: вместо того чтобы застревать в аналитическом параличе, пытаясь найти идеальный инструмент со всевозможными излишествами, просто выберите что-нибудь и начинайте изучение.
Какой была и стала наша настройка
- Развертывание. Как и многие другие, для управления и оптимизации развертывания и упаковывания приложений в Kubernetes мы используем Helm. Начали делать это давно и с сочетанием .Net, Go, Java, Python и PHP, поэтому переписывали чарты Helm много раз.
- Наблюдаемость. Для централизованного логирования мы начали применять Loggly вместе с FluentD, но через пару лет перешли на Elastic и Kibana стека ELK: с ними было проще работать, поскольку они популярнее, к тому же в нашей установке так было дешевле.
- Реестры контейнеров. Мы начали с Quay, неплохим продуктом. Но с переходом на Azure стало естественным использовать вместо него реестр контейнеров Azure, поскольку он интегрирован, а значит, это решение было «нативнее». Потом мы также получили контейнеры под Azure Security Advisor.
- Конвейеры. С самого начала для сборки контейнеров использовался Drone. Тогда было не много систем непрерывной интеграции, поддерживающих контейнеры и Docker, и они не предлагали конфигурации как код. Drone зарекомендовал себя многолетней исправной работой. Когда его приобрели Harness, немного все запуталось, но после перехода на премиум-версию у нас появились все необходимые функции.
Прорывная технология
За последние несколько лет Kubernetes стал для нас прорывной технологией, открыв возможности эффективнее масштабироваться при меняющихся объемах трафика, оптимизировать затраты на инфраструктуру, совершенствовать процесс разработки, упрощать тестирование новых идей и, таким образом, значительно сократить время вывода на рынок/окупаемости новых продуктов и сервисов.
Мы начали использовать Kubernetes слишком рано, прежде чем у нас возникли решаемые им проблемы. Но в долгосрочной перспективе, особенно в последние годы, он оказался очень полезным для нас.
Заключение
Размышляя об этих восьми годах, можно поведать немало историй, многие из которых уже стерлись из памяти. Надеюсь, вам понравилось читать о нашей настройке, допущенных ошибках и усвоенных уроках.
Читайте также:
- Kube-Proxy и CNI: скрытые компоненты сети Kubernetes
- K8s: топология подов
- Развертывание фронтенда и бэкенда приложения на Kubernetes
Читайте нас в Telegram, VK и Дзен
Перевод статьи Anders Jönsson: Lessons From Our 8 Years Of Kubernetes In Production — Two Major Cluster Crashes, Ditching Self-Managed, Cutting Cluster Costs, Tooling, And More





