
Рост популярности Node.js впечатляет. И в этом нет ничего удивительного, ведь это быстрый фреймворк с внушительной экосистемой пакетов и доказанной на практике эффективностью, а использование JavaScript позволяет компаниям перейти на полнофункциональный стек и оптимизировать жизненный цикл разработки.
Однако с большими возможностями приходит и большая ответственность. Поразмыслив о последних 8 годах использования Node.js, я решил опубликовать статью о четырех распространенных ошибках, допускаемых разработчиками Node.js.
Большинство из них не являются специфическими для Node, а скорее общими для бэкенд-разработки. Тем не менее я буду ссылаться на конкретные примеры Node.js, которые актуальны для любого разработчика экосистемы.
Ошибка №1. Запуск в эксплуатацию без четко определенных уровней логирования
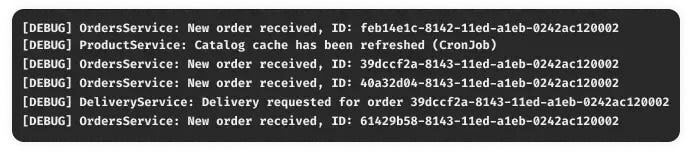
Полагаю, что большинство из вас знакомы с концепцией уровней логирования (DEBUG, INFO, WARN, ERROR и т. д.).
Мне не раз приходилось видеть, как команда разработчиков спешит выпустить новый микросервис и забывает о четком определении уровней логирования.
В результате могут возникнуть две проблемы.
- Вам и вашим коллегам будет гораздо сложнее выявлять и устранять проблемы во время этапа производства, если логи переполнятся нерелевантными сообщениями. Прежде всего речь идет о низкоуровневых
DEBUG-логах, которые неэффективны при производственных рабочих нагрузках. - Значительно увеличится счет за систему логирования. Я убедился в этом на собственном опыте: задействование в работе нового лог-сервиса обычно сопровождается резким увеличением расходов. Сервисы логирования взимают плату за пропускную способность и/или хранение данных.
Чтобы избежать этих последствий, следует использовать логгер с четко определенными уровнями логирования. Есть множество отличных библиотек логирования для Node.js (winston, pino, morgan), которые предоставляют простой API для создания логов различных типов.
Кроме того, убедитесь в том, что можете настроить уровень логирования приложения во время выполнения с помощью переменной среды (обычно LOG_LEVEL). Это обеспечит настройку уровня логирования в соответствии с вашими потребностями, независимо от того, работаете ли вы локально (задается в файле .env) или в облачных средах (индексация, производство и т.д.).
Ошибка №2. Необдуманный выбор базового образа Dockerfile
Приложения Node.js часто развертываются в виде контейнеров, и в этом есть много преимуществ. При определении Dockerfile вы объявляете базовый образ для использования в начале файла. Например:
FROM node:18
Это означает, что образ будет создан на основе официального образа Node.js 18. Однако разработчики часто не обращают внимания на потенциальные негативные последствия такого выбора.
Остановимся на примере с Node 18. Приведенный выше образ основан на операционной системе Debian. Это полноценная операционная система, которая связана с многими затратами для типичного API-бэкенда, написанного на Node.js. Размер образа будет слишком большим, на его создание уйдет много времени, хранение обойдется дороже, и больше ресурсов будет использоваться контейнером, что повлияет на масштабируемость и производительность.
Решить эту проблему довольно просто — используйте альтернативный образ. Довольно часто можно встретить образы alpine и slim. В двух словах, это операционные системы на базе Linux. Они очень легковесны и не содержат многих двоичных файлов и библиотек, предустановленных в полнофункциональной операционной системе.
Просматривая теги Node.js-образов на Docker Hub, можно заметить, что доступны как alpine, так и slim. Просто внесите это изменение:
FROM node:18-alpine
Вы сэкономите значительное количество времени на создание образа и минимизируете расходы операционной системы, тем самым оптимизировав общую производительность контейнеров. Кроме того, размер результирующего образа будет значительно меньше, что делает его более быстрым при сборке и пушинге, а также более дешевым при хранении в удаленном реестре контейнеров.
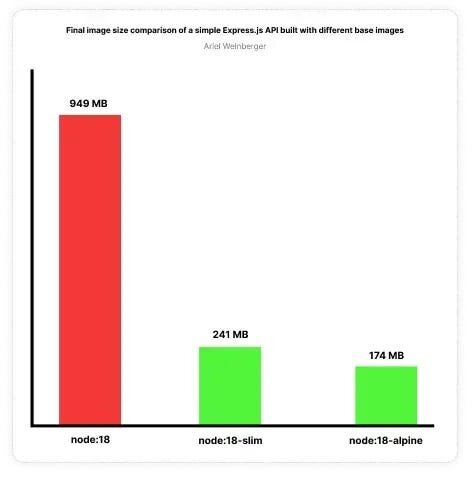
Размер образа уменьшился в целых 5 раз. Только представьте, как это повлияет на производительность команды, которая ежедневно запускает несколько конвейеров CI для множества сервисов!
Обратите внимание на следующий нюанс: хотя описанное выше работает в большинстве случаев, пакеты некоторых приложений могут потребовать определенных низкоуровневых библиотек, не включенных в легковесные образы по умолчанию. Вам придется установить их в качестве оператора RUN в Dockerfile. Однако преимущества, которые вы получите, того стоят!
Ошибка №3. Неиспользование асимметричного шифрования при подписании JSON Web Tokens (JWT)
Открытый стандарт JSON Web Tokens (JWT) действительно меняет мир. Это фантастический инструмент, который необходимо иметь под рукой при разработке микросервисов для достижения распределенной авторизации.
Механизм довольно прост: вы подписываете и верифицируете токены с помощью криптографии.
Простейшая форма реализации позволяет использовать для подписи токенов секретный ключ (например, verySecret123). Затем вы будете использовать тот же секретный ключ для проверки этих токенов. Это симметричное шифрование, поскольку одно и то же значение используется как для подписи токена, так и для его проверки.
В распределенной архитектуре доступ к каждой из служб потребует использования секретного ключа для проверки токенов. Это увеличивает вероятность кражи секретного ключа, которая может привести к подписанию злоумышленником поддельных токенов, что позволит ему повысить уровень доступа или выдать себя за другое лицо и выполнять операции от его имени. Подобный риск часто упускается из виду, хотя несет в себе серьезную угрозу безопасности!

Лучшим способом JWT-шифрования является асимметричный алгоритм. Вместо необработанного секретного значения для подписи и проверки токенов, вы используете пару ключей (например, сгенерированную с помощью openssl).
В результате закрытый ключ используется для подписания токенов, а открытый ключ — для их проверки.
Этот метод значительно более безопасен, поскольку он позволяет подписывающей службе (например, Auth Service) обладать только закрытым ключом и использовать его для подписания токенов.
Любая другая служба в архитектуре, принимающая API-запросы, может обладать открытым ключом и использовать его для проверки токенов.
Это значительно снижает риск кражи закрытого ключа и использования его для создания токенов с фальшивой идентификацией и/или повышенными привилегиями благодаря ограничению числа служб, имеющих к нему доступ.
Ошибка № 4. Хранение паролей без уникального “подсаливания”
В целом, я категорически против хранения паролей в системах, если только это не связано с вашей основной бизнес-деятельностью (что влечет за собой жесткое регулирование и аудит). Многие не обращают на это внимания, пока не возникнут проблемы.
Тем не менее есть компании, которые предпочитают хранить пароли в своих системах. Это также важная тема, с которой должны быть знакомы бэкенд-разработчики.
Прежде, чем говорить об этой ошибке, небольшая справка о проверке подлинности паролей.
Помните, что проверка пароля — это не операция “шифрование-дешифрование”. Вы берете необработанный пароль, пропускаете его через алгоритм хэширования и сохраняете, так что myPassword123 становится чем-то вроде 487753b945871b5b05f854060de151d8, который хранится в базе данных. Потом при входе в систему вы берете данные пользователя и хэшируете их. Затем сравниваете полученный хэш с хэшем, хранящимся в базе данных, и если он совпадает — аутентифицируете пользователя.
Существует четыре уровня безопасности при хранении паролей.
- Хранение необработанных паролей. Этого делать ни в коем случае нельзя. Если злоумышленник взломает базу данных, то получит доступ к необработанным паролям всех пользователей.
- Хэширование паролей (без соли). Вы берете пароль пользователя, пропускаете его через алгоритм хэширования, как описано выше, и сохраняете в базе данных. Это предотвратит доступ злоумышленников к необработанным паролям, что очень хорошо. Однако, поскольку вы просто хэшировали пароль, злоумышленник может использовать атаку радужной таблицей, при которой можно сравнить хэшированные пароли с соответствующими необработанными паролями и выявить совпадения. Помните, что прогон
myPassword123через простой алгоритм хэширования всегда даст один и тот же результат! - Хэширование паролей + глобальная соль. Этот метод очень похож на описанный выше, за исключением того, что вы добавляете немного “соли” к паролю перед хэшированием. Таким образом, вы хэшируете не
myPassword123, аmyPassword123+СОЛЬ. Это означает, что обычный пароль, такой какmyPassword123, будет выглядеть по-разному в виде хэша в базе данных и защитит вас от атак радужными таблицами. Однако, если глобальная соль раскрыта, злоумышленнику будет легче определить общие пароли, хранящиеся в базе данных. - Хэширование паролей + уникальная соль для каждого пароля. Это самый надежный и стандартный метод хранения паролей на сегодняшний день. Каждый пароль, хранящийся в базе данных, хэшируется уникальной солью. Это значительно снижает вероятность того, что злоумышленник получит необработанные пароли пользователей, даже в случае взлома базы данных. Реализовать это очень просто, используя такой пакет, как Bcrypt.
Храните пароли пользователей ответственно! Используйте для этого надежный сертифицированный сервис, чтобы сосредоточиться на создании основного продукта.
Читайте также:
- Управление Node.js 19 и NPM 9 с помощью NVM
- Как создать простой API с помощью Express и MongoDB
- Как выбрать подходящую версию Node.js?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Ariel Weinberger: 4 Common Mistakes Made by Node.js Developers





