
Извлечение данных путем OCR (optical character recognition — оптическое распознавание символов) подразумевает преобразование текстовых данных из отсканированных документов и текстовых изображений для представления в компьютере.
Технологии OCR подвергаются финансовые документы, удостоверения личности, паспорта, медицинские карты и многое другое. Поскольку эти документы содержат персональную идентифицирующую информацию (PII), обеспечение безопасности извлечения данных путем OCR является обязательным условием.
Кроме того, региональные регулирующие органы могут вас обязать обеспечить безопасность данных в соответствии с такими нормативными актами, как GDPR (General Data Protection Regulation — Общеевропейский регламент по защите данных) или его американский аналог CCPA (California Consumer Privacy Act — Закон штата Калифорния о защите персональных данных потребителей).
В подобной ситуации может оказаться полезной биометрическая идентификация.
Биометрическая идентификация подразумевает подтверждение личности человека с помощью отпечатков пальцев, распознавания лица или сканирования радужной оболочки глаза. Она может служить эффективной технологией для обеспечения безопасности извлечения данных на основе OCR.
Если вы являетесь разработчиком Angular и хотите защитить функциональность извлечения данных на основе OCR, это руководство для вас. Оно поможет понять, как интеграция биометрической идентификации с OCR создает мощную систему для надежной защиты.
Оптимизация OCR с помощью биометрической идентификации в приложениях Angular
Повышение уровня безопасности
Интеграция биометрической идентификации с извлечением данных на основе OCR позволяет достичь дополнительного уровня безопасности. Такая интеграция в приложениях Angular может значительно улучшить процессы контроля доступа, проверки личности и аутентификации.
Например, в сфере здравоохранения OCR используется для извлечения дополнительных данных из записей пациентов и автоматизации ввода данных. Такая оцифровка документов пациентов помогает улучшить уход за ними и упростить административные процессы. Интегрируя биометрическую идентификацию, медицинские учреждения могут обеспечить безопасность конфиденциальной медицинской информации.
Повышение качества процедуры верификации
Интеграция биометрии с OCR значительно улучшила процедуру верификации в различных отраслях. К ним относятся здравоохранение, финансы, государственные службы и т. д.
Например, сочетание OCR с биометрией позволило усилить процесс обеспечения безопасности в аэропортах. OCR используется для точного извлечения информации из документов, таких как паспорта, визы или удостоверения личности. Эти данные могут включать имя путешественника, дату его рождения, номер паспорта и идентификационный номер. Такая информация помогает подтвердить личность человека. Кроме того, биометрия используется для подтверждения личности человека по его отпечаткам пальцев или распознаванию лица.
Таким образом, сочетая OCR с распознаванием лиц, системы безопасности аэропортов реализуют многоуровневую процедуру аутентификации. Она значительно повышает безопасность и снижает риск мошеннических действий, например кражи личности или подделки документов.
Аналогичным образом банковский/финансовый сектор использует биометрию и OCR для предотвращения мошенничества. Например, мошенник может получить доступ к чековой книжке подлинного клиента и подделать его подпись. В то время как OCR точно извлечет подпись человека, биометрическая аутентификация может предотвратить несанкционированные транзакции, подтвердив личность с помощью отпечатков пальцев или распознавания лица. Таким образом, OCR успешно извлекает точные данные из поддельных или украденных документов, а биометрическая аутентификация помогает обнаружить и предотвратить мошеннические действия.
Автоматизация и эффективность
Еще одно преимущество интеграции OCR с биометрической идентификацией — автоматизация и ускорение процедуры аутентификации. Процедура верификации в ручном режиме занимает много времени и подвержена человеческим ошибкам. Такая процедура неэффективна и приводит к задержкам.
Пользователи могут быстро аутентифицировать себя с помощью биометрических данных, а OCR извлекает необходимую информацию из документов в режиме реального времени.
Возьмем, к примеру, приложение для управления личными финансами. Пользователи могут сканировать квитанции с помощью OCR, а затем подтвердить подлинность транзакций посредством отпечатков пальцев или распознавания лица. Такая автоматизация избавляет от необходимости ввода и верификации данных в ручном режиме. В результате экономится время и повышается удобство работы.
Выбор решений для выполнения OCR и биометрии
При выборе программного OCR-решения и биометрической технологии для приложения Angular помогут следующие рекомендации.
- Оцените способность OCR-решения извлекать данные с высокой точностью. Учитывайте такие факторы, как алгоритмы, используемые OCR-движком (например, обнаружение признаков на основе МО), его способность эффективно работать с различными шрифтами и сложными документами и т. д.
- Оцените скорость обработки OCR-движка.
- Выберите масштабируемое OCR-решение.
- Оцените точность биометрического решения.
- Проверьте, поддерживает ли биометрическое решение необходимые вам функции. К ним могут относиться отпечатки пальцев или распознавание лица.
- Оцените безопасность OCR- и биометрических решений.
Популярные технологии OCR и биометрии для Angular
Решения OCR для Angular
Tesseract.js
Tesseract.js — один из самых популярных вариантов OCR для Angular. Это библиотека OCR с открытым исходным кодом для JavaScript, предназначенная для извлечения данных из текстовых изображений или документов. Tesseract.js поддерживает функциональность для обработки изображений и распознавания текстового содержимого, предоставляя извлеченный текст в машиночитаемом формате.
Tesseract.js легко интегрируется в приложения на JavaScript/Angular. Кроме того, эта библиотека основана на движке Tesseract OCR, широко известном своей высокой точностью.
AWS Textract
AWS Textract — это полностью управляемый сервис OCR от Amazon Web Services (AWS). Он использует алгоритмы машинного обучения для автоматического извлечения текста и данных из:
- отсканированных документов;
- PDF-файлов;
- отсканированных изображений.
Интегрировать AWS Textract в приложения Angular можно с использованием AWS SDK для JavaScript.
Биометрические решения
Crossmatch DigitalPersona SDK
Crossmatch DigitalPersona предоставляет SDK U.are.U. Этот инструментальный пакет позволяет разработчикам добавлять в приложения возможности захвата и распознавания отпечатков пальцев. Crossmatch также предлагает API JavaScript для интеграции идентификации по отпечаткам пальцев в веб-приложения. Приложения могут получать данные об отпечатках пальцев с совместимого считывателя отпечатков пальцев, подключенного к устройству пользователя.
Вот ключевые особенности Crossmatch DigitalPersona SDK:
- Поддержка автоматической идентификации отпечатков пальцев по принципу “один-ко-многим” (“one-to-many”).
- Поддержка различных форматов данных, включая отпечатки пальцев ISO.
Microsoft Azure Face API
Microsoft Azure Face API — это облачный сервис обнаружения и распознавания лиц, предоставляемый Microsoft Azure. Он позволяет обнаруживать, идентифицировать и сравнивать лица на изображениях и видео, обеспечивая биометрическую аутентификацию по чертам лица.
Filestack: облачное решение
Для оптимизации процессов управления файлами, их доставки, обработки изображений и OCR можно использовать облачные решения, например Filestack. Filestack предлагает широкий спектр мощных инструментов и API для:
- загрузки файлов;
- доставки файлов через CDN (content delivery network — сеть доставки контента);
- обработки и преобразования изображений;
- OCR, распознавания лиц, распознавания объектов и многого другого.
Filestack также предлагает специализированный Angular SDK, обновленный для Angular 14. Он позволяет разработчикам легко интегрировать в Angular-приложения Filestack-сервис и функциональность. “filestack-angular” — это обертка для filestack-js SDK. Компонент Angular поддерживает практически все, что поддерживает filestack-js.
OCR Filestack
Filestack предлагает надежные возможности OCR как часть своих интеллектуальных сервисов. Использовать OCR можно через API обработки Filestack.
Для распознавания и извлечения текста с высокой точностью в OCR Filestack используются современные модели машинного обучения и нейронные сети. Этот сервис, оснащенный передовой системой анализа цифровых изображений, посимвольно определяет особенности объектов с высокой точностью. Кроме того, OCR Filestack использует сложные решения для обнаружения и предварительной обработки документов. Это позволяет детектировать сложные документы, в том числе повернутые, сложенные и помятые.
На иллюстрации ниже показано, как работает OCR Filestack:
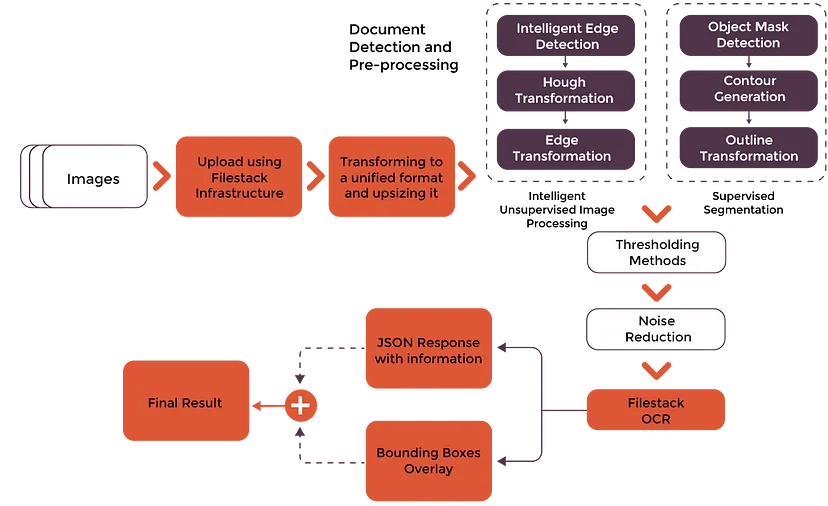
Расширенная обработка изображений
Filestack поддерживает широкий спектр передовых технологий обработки и улучшения изображений. К ним относятся:
- Преобразование изображений, такое как обрезка, поворот, изменение размера, сжатие и т. д.
- Различные фильтры и способы улучшения изображений.
- Метод распознавания лиц, который можно использовать в качестве основы для создания собственных систем биометрической верификации.
Функции предварительной обработки Filestack могут быть использованы для улучшения изображений и повышения точности OCR и биометрического анализа. Кроме того, Filestack использует надежную сеть доставки контента, которая позволяет быстро и эффективно предоставлять изображения пользователям со всего мира.
Безопасность Filestack
В Filestack реализованы надежные механизмы безопасности, обеспечивающие высокий уровень защиты пользовательских данных. Вот ключевые особенности безопасности Filestack:
- Сквозное шифрование для защиты данных на протяжении всего их жизненного цикла.
- Соответствие требованиям GDPR.
- Мощные механизмы аутентификации и авторизации для API-вызовов, обеспечивающие безопасный доступ к сервисам.
- Использование “подписи” и “политики” для повышения безопасности OCR.
- Шифрование HTTPS для API-обработки данных.
Интеграция OCR и биометрии в приложения Angular
- Интегрируйте OCR-библиотеку или API, например Tesseract.js или OCR Filestack, в приложение Angular.
- Настройте OCR-библиотеку для предварительной обработки изображений и извлечения необходимого текста из заданных областей интереса.
- Реализуйте основную логику для извлечения текста из изображений с помощью OCR-библиотеки.
- Эффективно обрабатывайте ошибки и несоответствия при извлечении текста. Обеспечьте обратную связь с пользователями в случае неудачного распознавания текста.
- Интегрируйте биометрическую функциональность в приложение Angular с помощью биометрического API или библиотеки.
- Используйте в Angular такие биометрические данные, как отпечатки пальцев и изображения лиц пользователей.
- При создании биометрической функциональности с нуля, реализуйте алгоритмы сопоставления биометрических данных, чтобы сравнивать полученные биометрические данные (отпечатки пальцев или лица) с сохраненными биометрическими шаблонами.
Фрагменты кода
Теперь посмотрим, как интегрировать Filestack File Uploader — ПО для управления загрузкой файлов — в приложения Angular и использовать OCR Filestack.
Установите Filestack SDK:
npm install filestack-js npm install @filestack/angular
Включите FilestackModule в app.module.ts:
import { BrowserModule } from '@angular/platform-browser';
import { NgModule } from '@angular/core';
import { AppComponent } from './app.component';
import { FilestackModule } from '@filestack/angular';
@NgModule({
declarations: [
AppComponent ],
imports: [
BrowserModule,
FilestackModule.forRoot({ apikey: YOUR_APIKEY, options: ClientConfig })
],
bootstrap: [AppComponent] }) export class AppModule {}
Используйте в файле .html:
<ng-picker-overlay apikey="YOUR_API_KEY"> </ng-picker-overlay>
Выполнять OCR на загруженных изображениях можно, используя следующий URL CDN:
https://cdn.filestackcontent.com/security=p:<POLICY>,s:<SIGNATURE>/ocr/<HANDLE>
Можно также интегрировать библиотеку OCR с биометрическим модулем в компонент Angular.
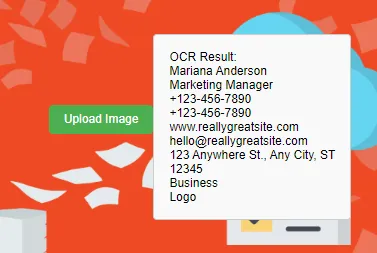
Вот пример того, как работает извлечение данных с помощью OCR Filestack.
Входное изображение:

Вывод:
Рекомендации по созданию масштабируемых и безопасных приложений с помощью Angular
- Используйте компонентную архитектуру Angular, чтобы создавать модульные и многократно используемые компоненты для обработки изображений и документов, OCR и биометрических задач.
- Реализуйте ленивую загрузку, чтобы динамически загружать модули и компоненты Angular по мере необходимости.
- Эффективно управляйте состоянием приложения, что особенно важно для сложных рабочих процессов и задач обработки больших объемов данных. Для успешного управления состоянием используйте библиотеки управления состоянием, такие как NgRx и Akita.
- Внедряйте лучшие практики безопасности для защиты конфиденциальных данных. К ним можно отнести HTTPS для безопасной связи, шифрование данных, а также надлежащие механизмы аутентификации и авторизации для контроля доступа. Это критически важно для OCR и биометрических рабочих процессов, поскольку они работают с персональной информацией.
- Внедряйте надежные механизмы обработки ошибок для их эффективного устранения.
Заключение
Технология OCR позволяет извлекать текстовую информацию или структурированные данные из различных документов, таких как финансовые деловые бумаги, удостоверения личности и паспорта. Эти извлеченные данные часто используются для проверки личности. Однако процедура верификации может быть подвержена риску из-за мошеннических действий, таких как подделка документов или кража личных данных. К счастью, можно повысить безопасность извлекаемых данных с помощью интеграции OCR с биометрией. Это гарантирует обнаружение и предотвращение мошеннических действий биометрической аутентификацией, в то время как OCR точно извлекает информацию из украденных или поддельных документов.
FAQ
Что означает извлечение данных путем OCR?
Извлечение данных путем OCR означает автоматическое извлечение текста из отсканированных документов (печатных или рукописных) и текстовых изображений.
В чем разница между традиционным извлечением данных и OCR?
При традиционном извлечении данных человек извлекает информацию из документов вручную. OCR автоматизирует этот процесс с помощью алгоритмов извлечения признаков и распознавания текста на основе ИИ и МО.
Как OCR и биометрия могут улучшить процедуру верификации личности?
Сочетание биометрической идентификации и извлечения данных путем OCR может значительно улучшить процедуру верификации личности и бизнес-процессы. Извлечение данных путем OCR может использоваться для проверки личности по отсканированному документу, такому как паспорт или удостоверение личности. Биометрия подтверждает личность человека с помощью отпечатков пальцев или распознавания лица. Таким образом, вводится механизм многофакторной аутентификации.
Читайте также:
- Пора отказаться от “@Input” и “@Output” в Angular
- Аутентификация и авторизация пользователей в Angular 16 с помощью JWT
- Angular: как с функцией inject() сэкономить 1000 строк кода
Читайте нас в Telegram, VK и Дзен
Перевод статьи Idera Dev Tools: Secure OCR and Biometrics Integration in Angular





